Deep Object Detection » 深度目标检测(六)——Tiny-YOLO, One-stage vs. Two-stage, R-FCN, FPN, RetinaNet
2018-12-21 :: 5432 WordsYOLOv3(续)
https://mp.weixin.qq.com/s/-Ixqxx6QGJDTM4g50y6LyA
进击的YOLOv3,目标检测网络的巅峰之作
https://zhuanlan.zhihu.com/p/46691043
YOLO v1深入理解
https://zhuanlan.zhihu.com/p/47575929
YOLOv2 / YOLO9000深入理解
https://zhuanlan.zhihu.com/p/49556105
YOLO v3深入理解
https://mp.weixin.qq.com/s/0lyDv9b-mpvSFYXqyngT-w
实用教程!使用YOLOv3训练自己数据的目标检测
https://mp.weixin.qq.com/s/PkFtZ0Iqf7PBGyE5a_IJ4Q
YOLO v3的TensorFlow实现,GitHub完整源码解析
https://mp.weixin.qq.com/s/Vuuca3A7luCyCQ-jBKMIcw
YOLO v3目标检测的PyTorch实现,GitHub完整源码解析!
https://mp.weixin.qq.com/s/2aeBBjCbWdweYmNrTaWqqw
一文看尽目标检测:从YOLO v1到v3的进化之路
https://mp.weixin.qq.com/s/fDOskKqG-fsJmhT0-tdtTg
SlimYOLOv3:更窄、更快、更好的无人机目标检测算法
https://zhuanlan.zhihu.com/p/50595699
揭秘YOLOv3鲜为人知的关键细节
https://mp.weixin.qq.com/s/EElv2Tc73JKS8jpejEGB1w
YOLO v3实战之钢筋数量AI识别(一)
https://mp.weixin.qq.com/s/HEBO9uZMD2CZW_Y-8eBK1A
YOLOv1/v2/v3简述
https://mp.weixin.qq.com/s/5IfT9cWVbZq4cwHPLes5vA
你对YOLOV3损失函数真的理解正确了吗?
https://mp.weixin.qq.com/s/biPLPaunfkQtpywaHbBfLg
YOLOV3损失函数再思考
https://mp.weixin.qq.com/s/Cws-3Cni-_v3AED918eB4A
高斯YoloV3目标检测
Tiny-YOLO
YOLO系列还包括了一个速度更快但精度稍低的嵌入式版本系列——Tiny-YOLO。
到了YOLOv3时代,Tiny-YOLO被改名为YOLO-LITE。
此外,还有使用其他轻量级骨干网络的YOLO变种,如MobileNet-YOLOv3。
参考:
https://mp.weixin.qq.com/s/xNaXPwI1mQsJ2Y7TT07u3g
YOLO-LITE:专门面向CPU的实时目标检测
https://zhuanlan.zhihu.com/p/50170492
重磅!YOLO-LITE来了
https://zhuanlan.zhihu.com/p/52928205
重磅!MobileNet-YOLOv3来了
https://mp.weixin.qq.com/s/LhXXPyvxci1d4xLzT0XFaw
xYOLO:最新最快的实时目标检测
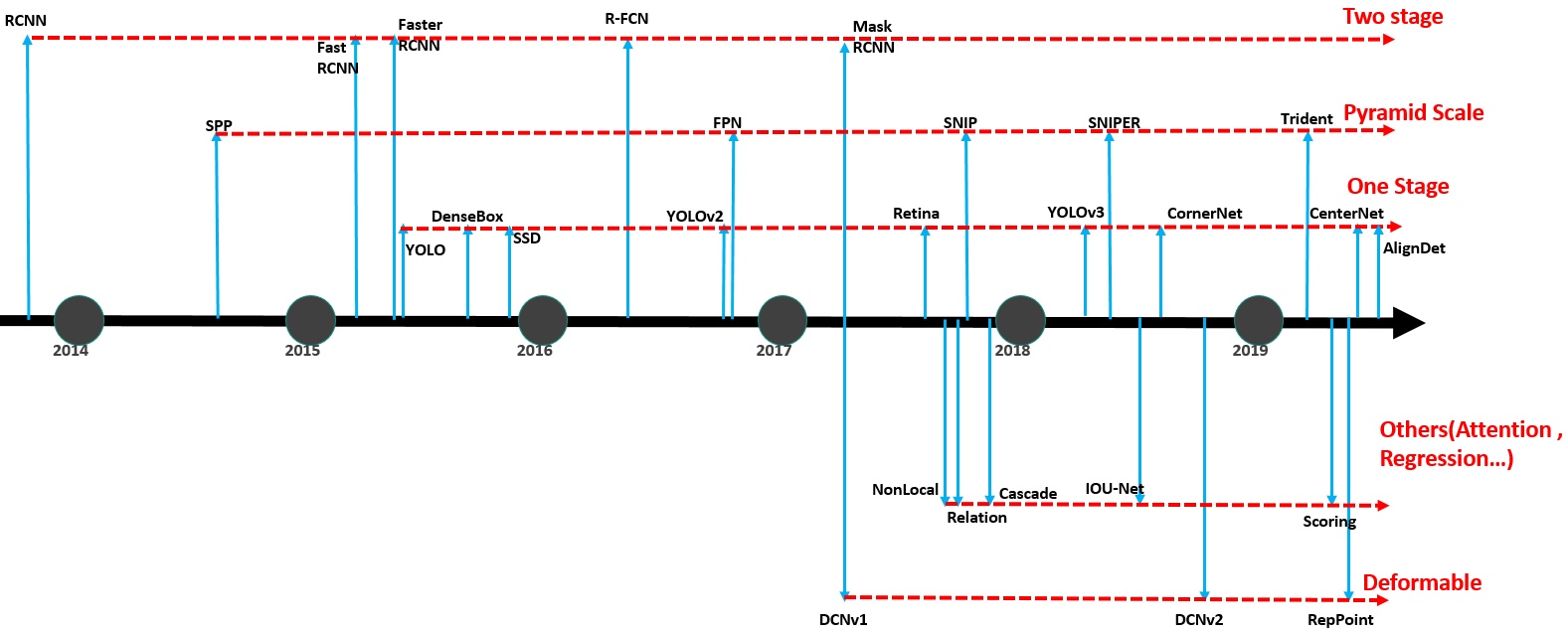
One-stage vs. Two-stage
虽然我们在概述一节已经提到了One-stage和Two-stage的概念。但鉴于这个概念的重要性,在介绍完主要的目标检测网络之后,很有必要再次总结一下。
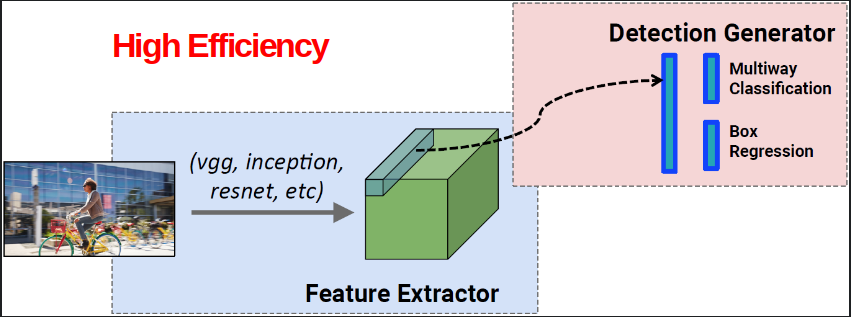
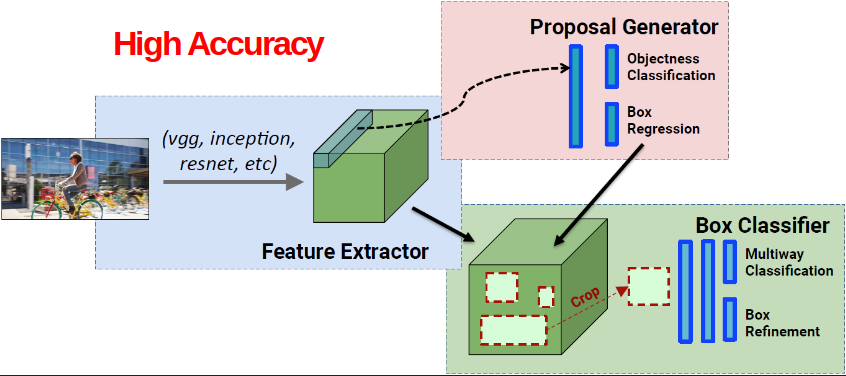
上两图是One-stage(YOLO)和Two-stage(Faster R-CNN)的网络结构图。
One-stage一步搞定分类和bbox问题。
而Two-stage则分为两步:
1.根据区域是foreground,还是background,生成bbox。
2.对bbox进行分类和细调。
论文:
《Speed/accuracy trade-offs for modern convolutional object detectors》
通常来说,One-stage模型运算速度比Two-stage模型快,但精度略有不足。究其原因主要是“类别不平衡”问题。
- 什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
- “类别不平衡”又如何会导致检测精度低呢?
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
- 为什么two-stage系可以避免这个问题呢?
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是从“类别极不平衡”变成了“类别较不平衡”。
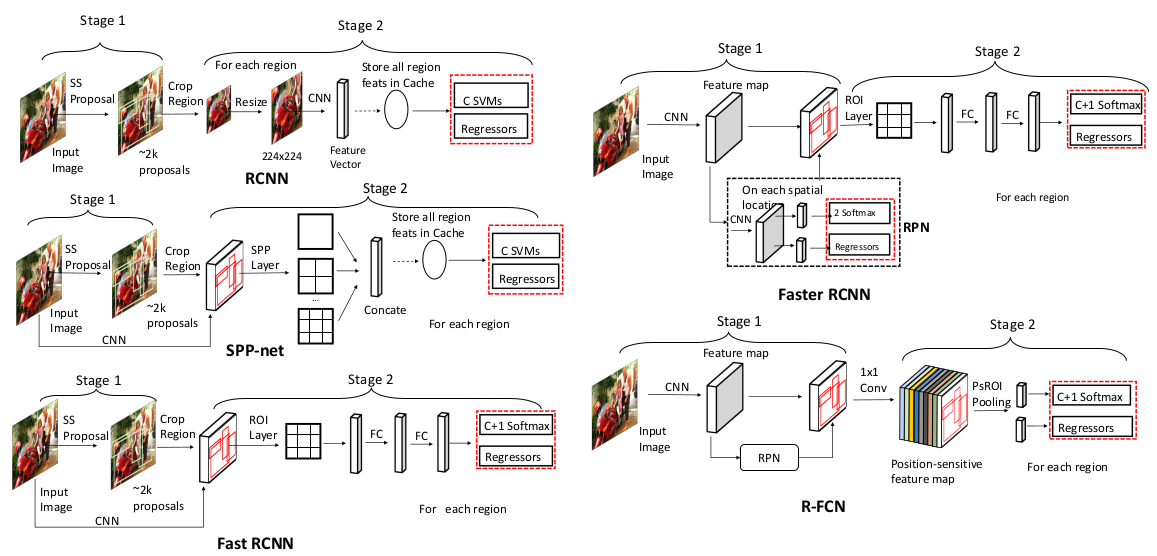
R-FCN
R-FCN是何恺明/孙剑小组的Jifeng Dai于2016年提出的。
论文:
《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
代码:
https://github.com/PureDiors/pytorch_RFCN
faster R-CNN对卷积层做了共享(RPN和Fast R-CNN),但是经过RoI pooling后,却没有共享,如果一副图片有500个region proposal,那么就得分别进行500次卷积,这样就太浪费时间了,于是作者猜想,能不能把RoI后面的几层建立共享卷积,只对一个feature map进行一次卷积?
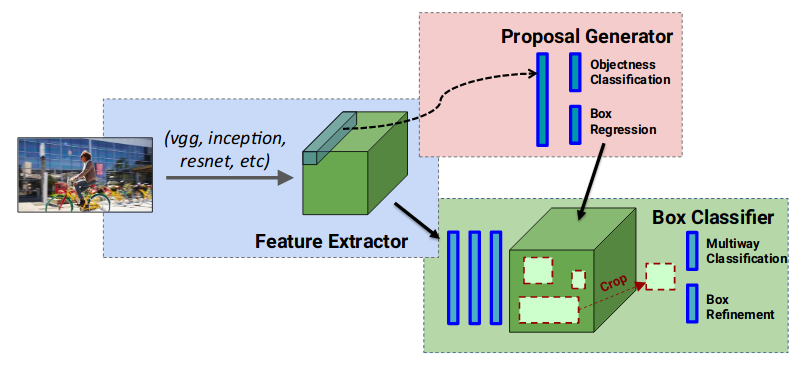
上图是R-FCN的网络结构图。和上一节的Faster R-CNN相比,我们可以看出如下区别:
1.Faster R-CNN是特征提取之后,先做ROI pooling,然后再经过若干层网络,最后分类+bbox。
2.R-FCN是特征提取之后,先经过若干层网络,然后再做ROI pooling,最后分类+bbox。
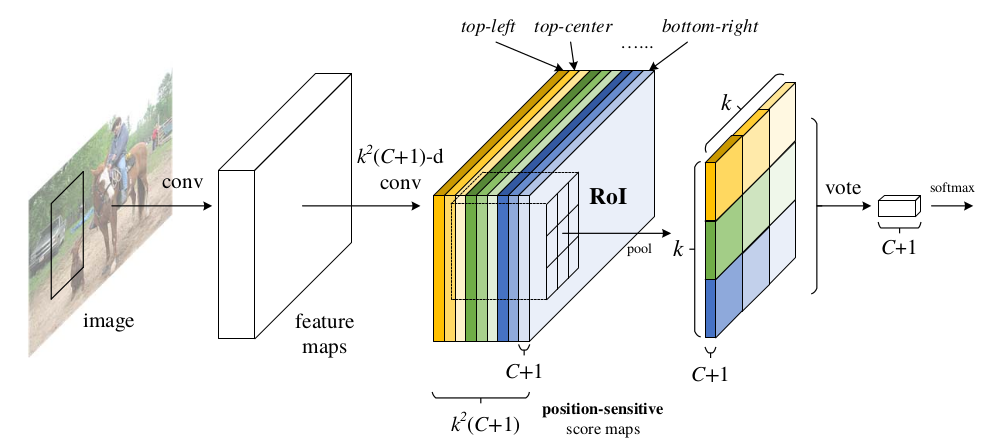
FC layer在近来的CV实践中,越来越不受欢迎,因此R-FCN在最后的分类+bbox阶段,也做了一些针对性的改进(如上图所示):
1.直接将roi pooling生成的feature map连接到最后的分类和回归层效果很差。这主要是因为:基CNN本身是对图像分类设计的,具有图像移动不敏感性;而对象检测领域却是图像移动敏感的,所以二者之间产生了矛盾。
2.因此R-FCN专门设计了一个position-sensitive score maps。在feature map上通过卷积运算生成一个等大但通道数为\(k^{2}(C+1)\)的feature map X。
3.对这个feature map进行特殊的ROI pooling。
标准的ROI pooling:将ROI在空间上分成kxk部分,对每个部分进行pooling操作。
R-FCN的ROI pooling:将ROI在通道上分成kxk部分,对每个部分进行pooling操作,得到一个尺寸为kxkx(C+1)的tensor。上图中各种颜色部分之间的对应关系,展示了该ROI pooling操作的实现方式。
从中可以看出,feature map X不仅在空间维度上对位置敏感,在通道维度上也对位置敏感。因此也被称作position-sensitive score maps。
4.对上一步结果的每个C+1部分进行分类,这样可以得到kxk个分类结果。对所有的分类结果进行vote,得到最终结果。
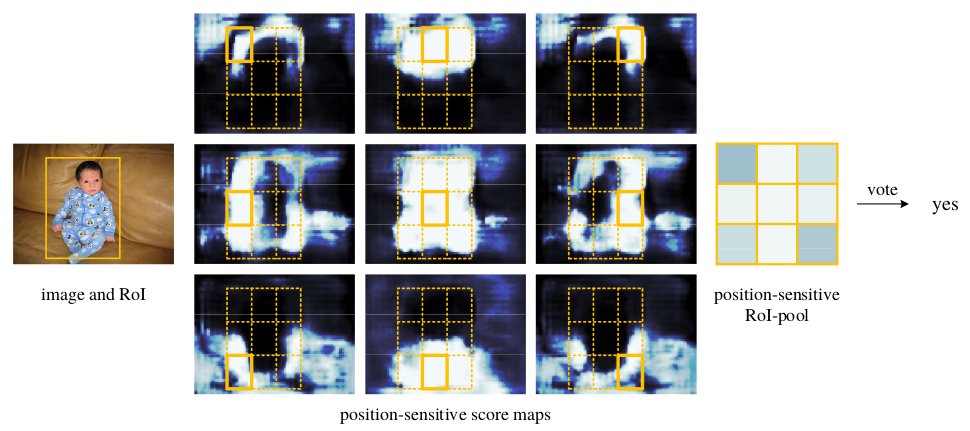

从上面两图可以看出,vote的规则就是简单多数,因此k需要是奇数才行。
5.bbox也是类似的操作,只需将上面的C+1换成4(bbox位置的坐标)即可。
参考:
http://blog.csdn.net/zijin0802034/article/details/53411041
R-FCN: Object Detection via Region-based Fully Convolutional Networks
https://blog.csdn.net/App_12062011/article/details/79737363
R-FCN
https://mp.weixin.qq.com/s/HPzQST8cq5lBhU3wnz7-cg
R-FCN每秒30帧实时检测3000类物体,马里兰大学Larry Davis组最新目标检测工作
https://mp.weixin.qq.com/s/AddHG_I00uaDov0le4vdvA
R-FCN和FPN
FPN
FPN(Feature Pyramid Network)是Tsung-Yi Lin(Ross Girshick和何恺明小组成员)的作品(2016.12)。
论文:
《Feature Pyramid Networks for Object Detection》
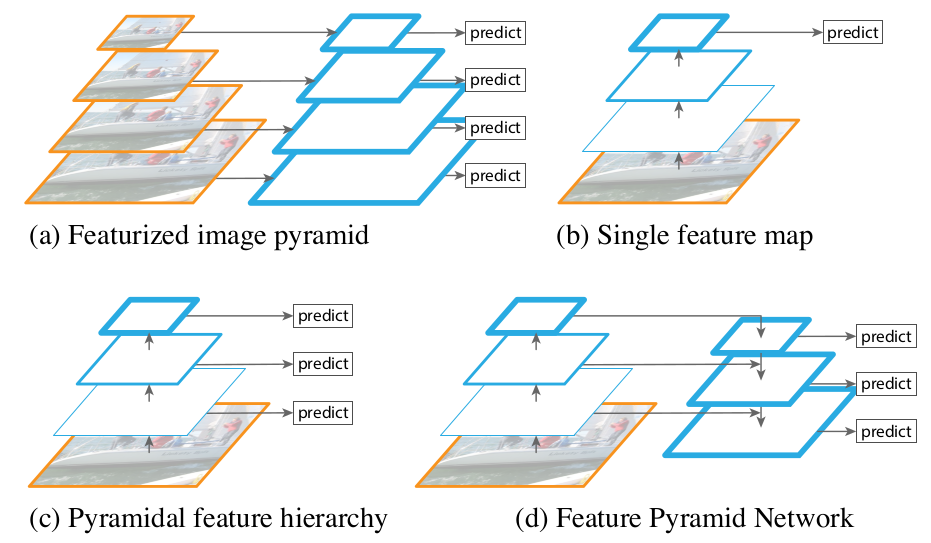
-
图(a)为手工设计特征描述子(Sift,HoG,Harr,Gabor)时代的常见模型,即对不同尺寸的图片提取特征,以满足不同尺度目标的检测要求,提高模型性能;
-
图(b)则是深度卷积网的基本结构,通过不断的卷积抽取特征同时逐渐增加感受野,最后进行预测;
-
图(c)则是融合深度网络的特征金字塔模型,众所周知深度网在经过每一次卷积后均会获得不同尺度的feature map,其天然就具有金字塔结构。但是由于网络的不断加深其图像分别率将不断下降,感受野将不断扩大,同时表征的特征也更叫抽象,其语义信息将更加丰富。SSD则采用图c结构,即不同层预测不同物体,让top层预测分辨率较高,尺寸较大的目标,bottom则预测尺寸较小的目标。然而对于小目标的检测虽然其分辨率提高了但是其语义化程度不够,因此其检测效果依旧不好。
-
图(d)则是FPN的网络结构,该网络结构大体上分为三个部分,即buttom-up自底向上的特征抽取,自顶向下的upsampling,以及侧边融合通道(lateral coonnection)。通过这三个结构网络的每一层均会具有较强的语义信息,且能很好的满足速度和内存的要求。
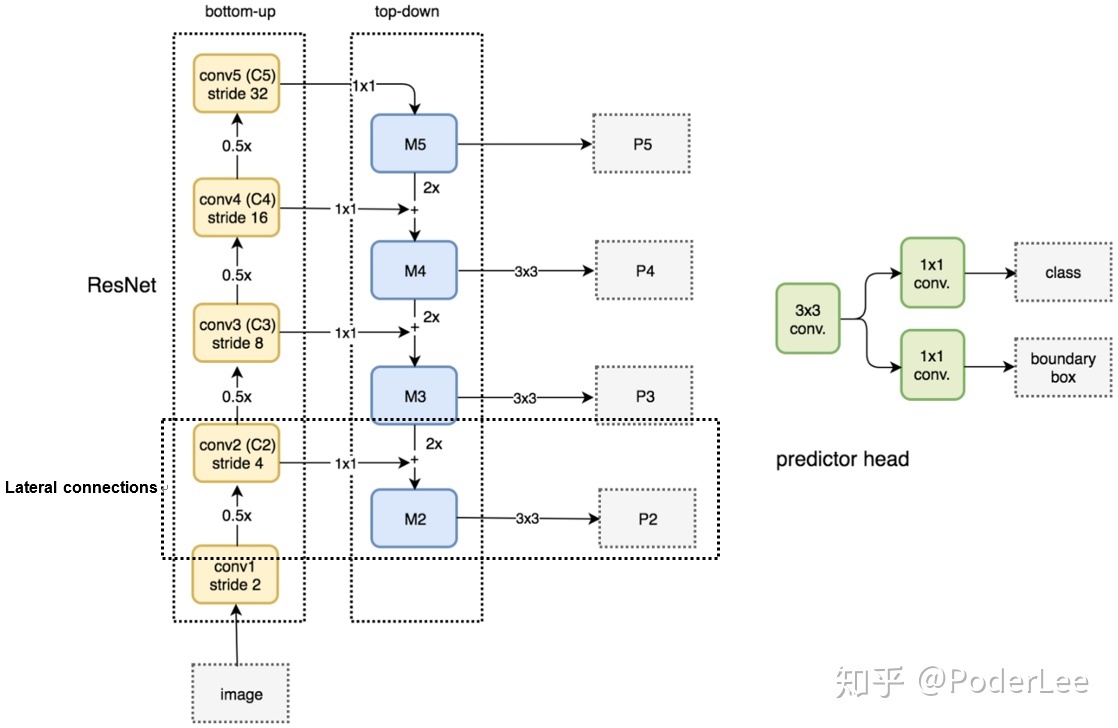
上图是加了FPN之后的ResNet,其中的虚线框表示的是通道融合的方法。U-Net采用了concat模式融合下采样和上采样通道,而这里则是沿用了ResNet的融合方法:Tensor Add。
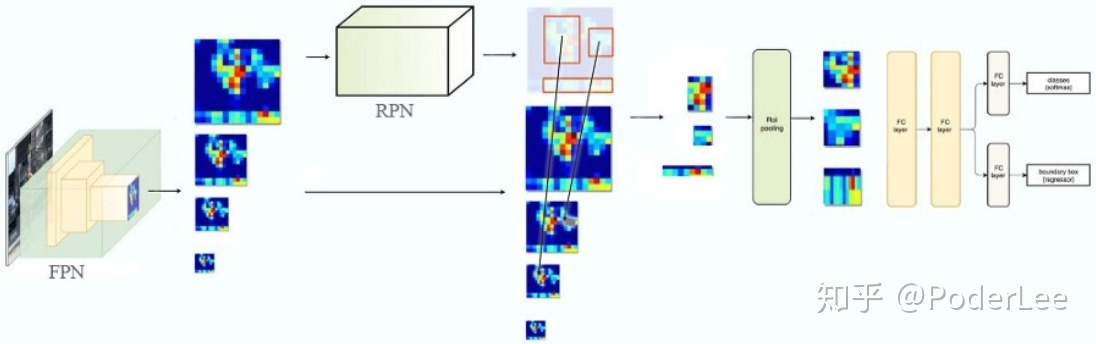
上图是Faster R-CNN+FPN。原始的Faster R-CNN的RoI pooling是从同一个feature map中获得ROI,而这里是根据目标尺度大小,从不同尺度的feature map中获得ROI。
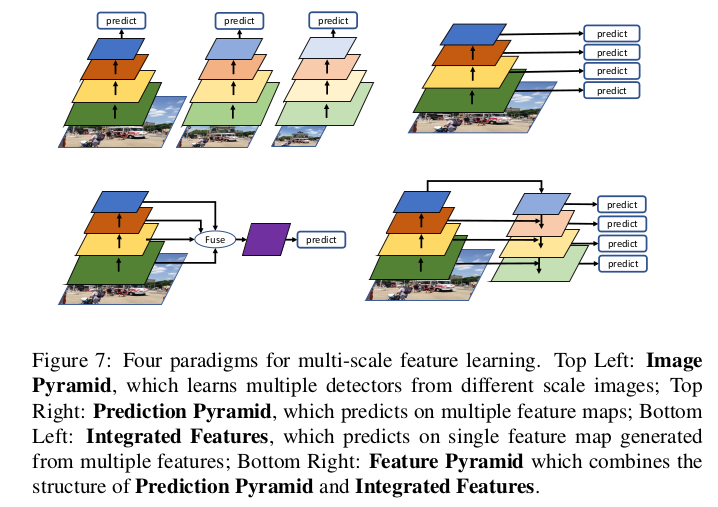
FPN是从上到下的提取特征,后来的PAN在此基础上又来了一些从下而上的套路:
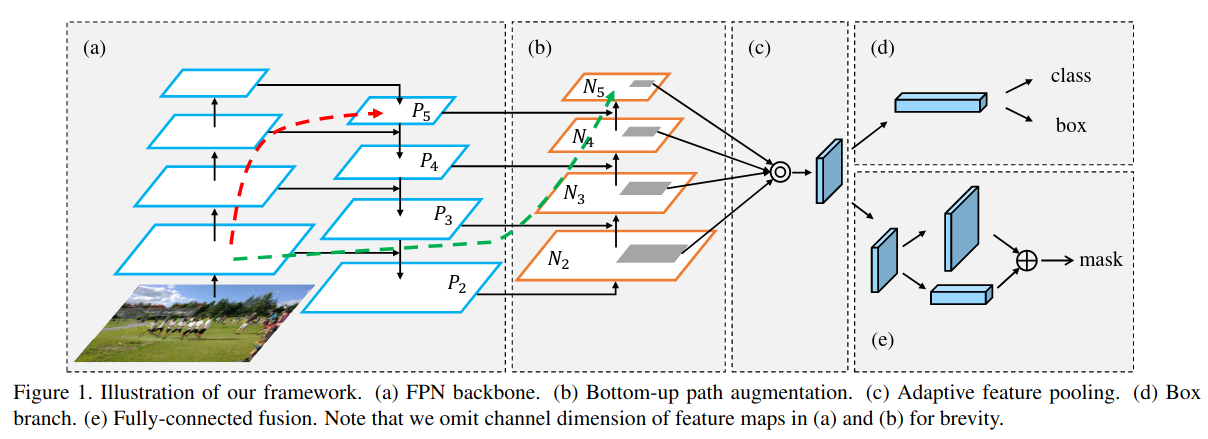
参考:
https://mp.weixin.qq.com/s/mY_QHvKmJ0IH_Rpp2ic1ig
目标检测FPN
https://mp.weixin.qq.com/s/TelGG-uVQyxwQjiDGE1pqA
特征金字塔网络FPN
https://zhuanlan.zhihu.com/p/58603276
FPN-目标检测
https://zhuanlan.zhihu.com/p/70523190
总结-CNN中的目标多尺度处理
https://mp.weixin.qq.com/s/xMQA97k0USl69v1MC86HKA
多尺度特征金字塔结构用于目标检测
https://mp.weixin.qq.com/s/rMR98woa1y_sjSFgG24cGQ
常见特征金字塔网络FPN及变体
https://mp.weixin.qq.com/s/ZqNRxexEFRxVXI7-bGPx0A
Feature Pyramid Network详解特征金字塔网络FPN的来龙去脉
RetinaNet
RetinaNet也是Tsung-Yi Lin的作品(2017.8)。
论文:
《Focal Loss for Dense Object Detection》
在《深度目标检测(五)》中,我们已经指出“类别不平衡”是导致One-stage模型精度不高的原因。那么如何解决这个问题呢?
答案是:Focal Loss。(参见《机器学习(二十二)》)
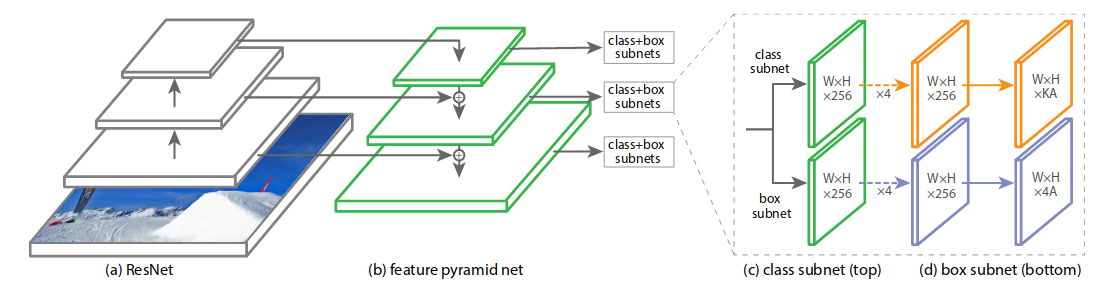
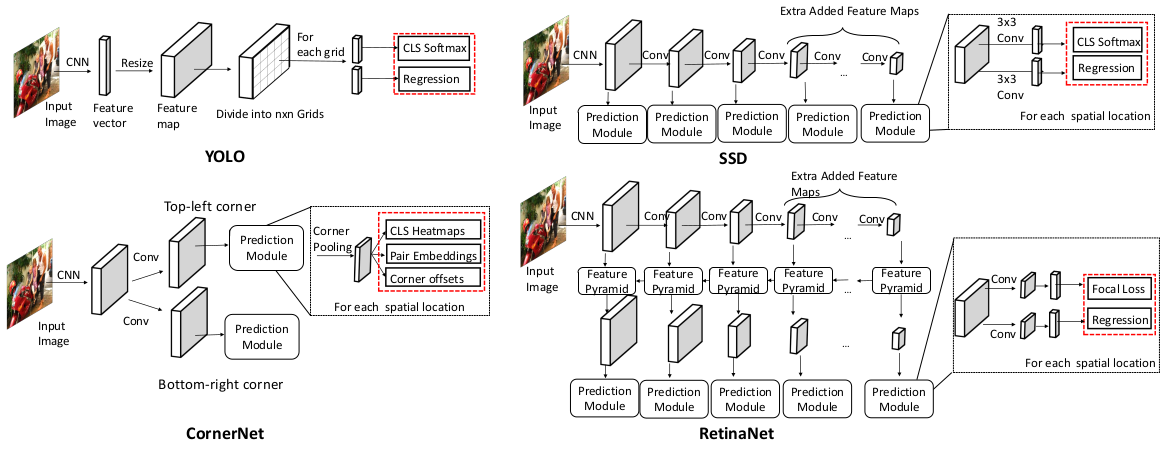
上图是RetinaNet的网络结构图,可以看出它是一个One-stage模型。基本相当于:ResNet+FPN+Focal loss。
参考:
https://blog.csdn.net/jningwei/article/details/80038594
论文阅读: RetinaNet
https://zhuanlan.zhihu.com/p/68786098
再谈RetinaNet

您的打赏,是对我的鼓励
