Deep Object Detection » 深度目标检测(三)——Fast R-CNN, Faster R-CNN
2018-11-17 :: 5313 WordsSPPNet(续)
参见:
https://zhuanlan.zhihu.com/p/24780433
原始图片中的ROI如何映射到到feature map?
http://www.cnblogs.com/objectDetect/p/5947169.html
卷积神经网络物体检测之感受野大小计算
Problem 2:ROI的在特征图上的对应的特征区域的维度不满足全连接层的输入要求怎么办(又不可能像在原始ROI图像上那样进行截取和缩放)?
对于Problem 2我们分析一下:
这个问题涉及的流程主要有: 图像输入->卷积层1->池化1->…->卷积层n->池化n->全连接层。
引发问题的原因主要有:全连接层的输入维度是固定死的,导致池化n的输出必须与之匹配,继而导致图像输入的尺寸必须固定。
解决办法可能有:
1.想办法让不同尺寸的图像也可以使池化n产生固定的输出维度。(打破图像输入的固定性)
2.想办法让全连接层(罪魁祸首)可以接受非固定的输入维度。(打破全连接层的固定性,继而也打破了图像输入的固定性)
以上的方法1就是SPPnet的思想。
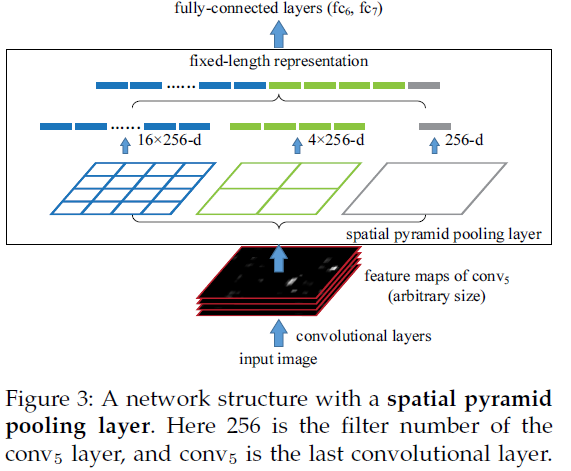
Step 1:为图像建立不同尺度的图像金字塔。上图为3层。
Step 2:将图像金字塔中包含的feature映射到固定尺寸的向量中。上图为\((16+4+1)\times 256\)维向量。
总结:
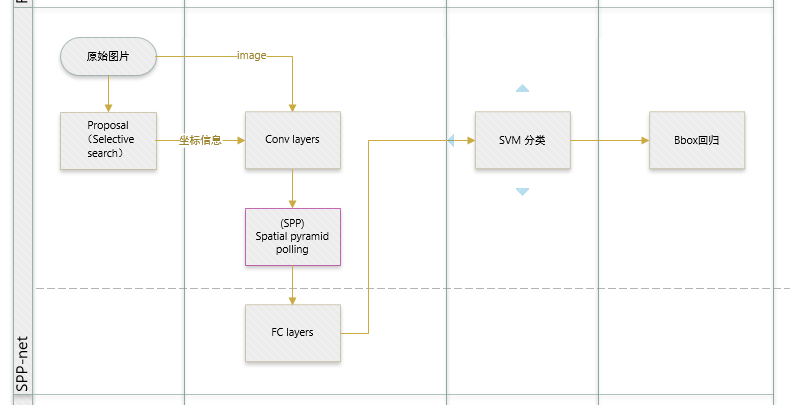
从上图可以看出,由于卷积策略的不同,SPPnet的流程和RCNN也有一点微小的差异:
1.RCNN是先选择区域,然后对区域进行卷积,并检测。
2.SPPnet是先统一卷积,然后应用选择区域,做区域检测。
参考:
https://zhuanlan.zhihu.com/p/24774302
SPPNet-引入空间金字塔池化改进RCNN
http://kaiminghe.com/iccv15tutorial/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
何恺明:Convolutional Feature Maps
Fast R-CNN
Fast R-CNN是Ross Girshick于2015年祭出的又一大招。
论文:
《Fast R-CNN》
代码:
https://github.com/rbgirshick/fast-rcnn
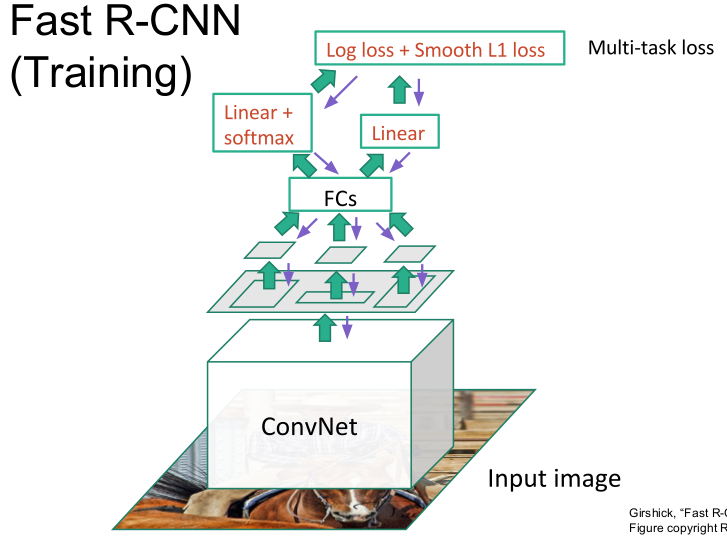
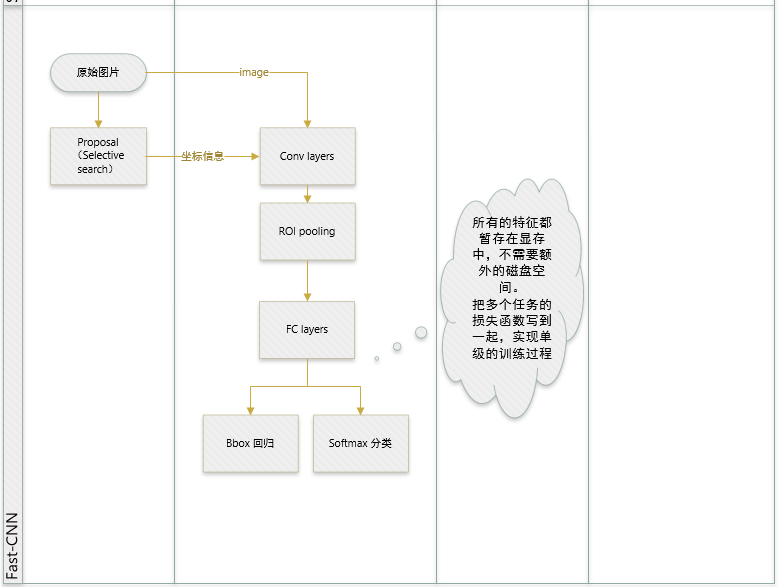
上图是Fast R-CNN的结构图。从该图可以看出Fast R-CNN和SPPnet的主要差异在于:
1.使用ROI(Region of interest) Pooling,替换SPP。
2.去掉了SVM分类。
以下将对这两个方面,做一个简述。
ROI Pooling
SPP将图像pooling成多个固定尺度,而RoI只将图像pooling到单个固定的尺度。(虽然多尺度学习能提高一点点mAP,不过计算量成倍的增加。)
普通pooling操作中,pooling区域的大小一旦选定,就不再变化。
而ROI Pooling中,为了将ROI区域pooling到单个固定的目标尺度,我们需要根据ROI区域和目标尺度的大小,动态计算pooling区域的大小。
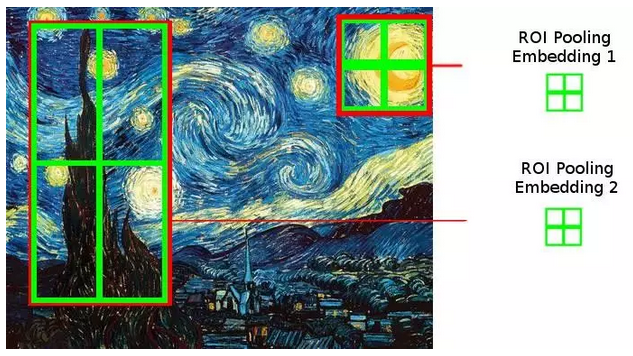
ROI Pooling有两个输入:feature map和ROI区域。Pooling方式一般为Max Pooling。Pooling的kernel形状可以不为正方形。
参考:
https://mp.weixin.qq.com/s/pH-Eea6Gz5jYnVD5Psp8ZA
在TensorFlow+Keras环境下使用RoI池化一步步实现注意力机制
Bounding-box Regression
从Fast R-CNN的结构图可以看出,与一般的CNN不同,它在FC之后,实际上有两个输出层:第一个是针对每个ROI区域的分类概率预测(上图中的Linear+softmax),第二个则是针对每个ROI区域坐标的偏移优化(上图中的Linear)。
然后,这两个输出层(即两个Task)再合并为一个multi-task,并定义统一的loss。
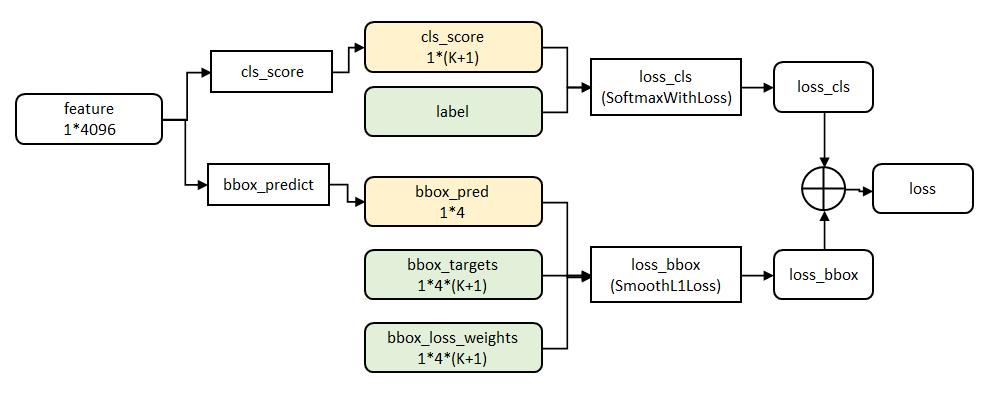
由于两个Task的信息互为补充,使得分类预测任务的softmax准确率大为提升,SVM也就没有存在的必要了。
上图中提到的smooth L1 Loss可参见:
http://pages.cs.wisc.edu/~gfung/GeneralL1/L1_approx_bounds.pdf
Fast Optimization Methods for L1 Regularization: A Comparative Study and Two New Approaches Suplemental Material
全连接层提速
Fast R-CNN的论文中还提到了全连接层提速的概念。这个概念本身和Fast R-CNN倒没有多大关系。因此,完全可以将之推广到其他场合。
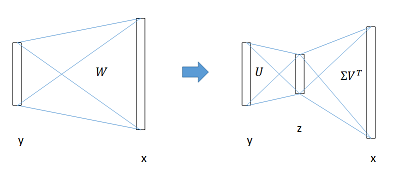
它的主要思路是,在两个大的FC层(假设尺寸为u、v)之间,利用SVD算法加入一个小的FC层(假设尺寸为t),从而减少了计算量。
\[u\times v\to u\times t+t\times v\]总结
参考:
https://zhuanlan.zhihu.com/p/24780395
Fast R-CNN
http://blog.csdn.net/shenxiaolu1984/article/details/51036677
Fast RCNN算法详解
Faster R-CNN
Faster-RCNN是任少卿2015年在MSRA提出的新算法。Ross Girshick和何恺明也是论文的作者之一。
任少卿,中科大本科(2011年)+博士(2016年)。Momenta联合创始人+技术总监。
个人主页:
http://shaoqingren.com/
论文:
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
代码:
https://github.com/ShaoqingRen/faster_rcnn
https://github.com/rbgirshick/py-faster-rcnn
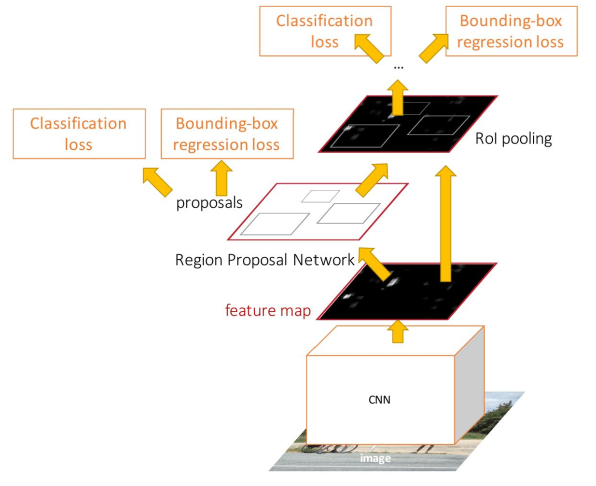
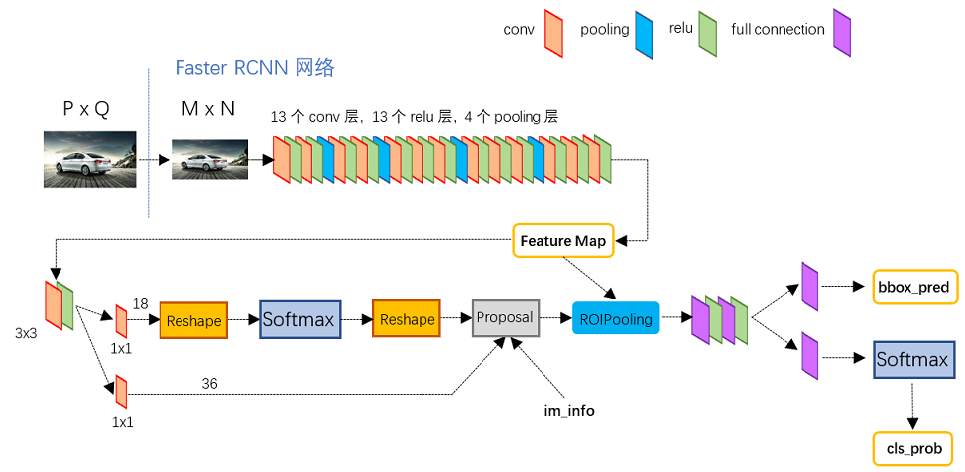
上图是Faster R-CNN的结构图。
Fast R-CNN尽管已经很优秀了,然而还有一个最大的问题在于:proposal阶段没有整合到CNN中。
这个问题带来了两个不良影响:
1.非end-to-end模型导致程序流程比较复杂。
2.随着后续CNN步骤的简化,生成2k个候选bbox的Selective Search算法成为了整个计算过程的性能瓶颈。(无法利用GPU)
Region Proposal Networks
Faster R-CNN最重要的改进就是使用区域生成网络(Region Proposal Networks)替换Selective Search。因此,faster RCNN也可以简单地看做是“RPN+fast RCNN”。
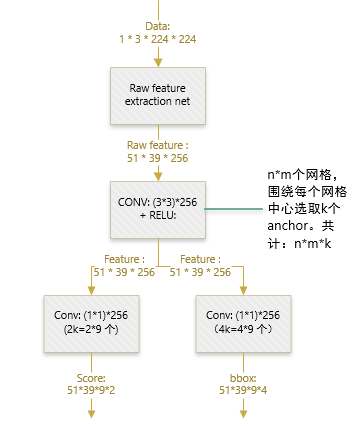
上图是RPN的结构图。和SPPNet的ROI映射做法类似,RPN直接在feature map,而不是原图像上,生成区域。
由于Faster R-CNN最后会对bbox位置进行精调,因此这里生成区域的时候,只要大致准确即可。
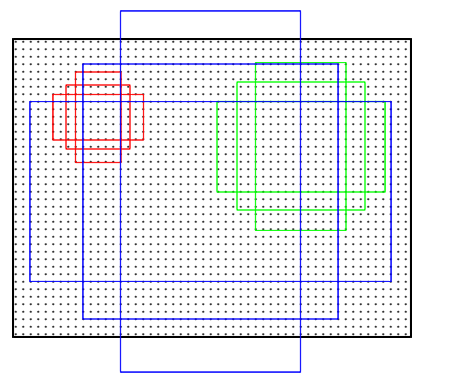
由于CNN所生成的feature map的尺寸,通常小于原图像。因此将feature map的点映射回原图像,就变成了上图所示的稀疏网点。这些网点也被称为原图感受野的中心点。
把网点当成基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。论文中用了3个scale(三种面积\(\left\{ 128^2, 256^2, 521^2 \right\}\),如上图的红绿蓝三色所示),3个aspect ratio({1:1,1:2,2:1},如上图的同色方框所示)。
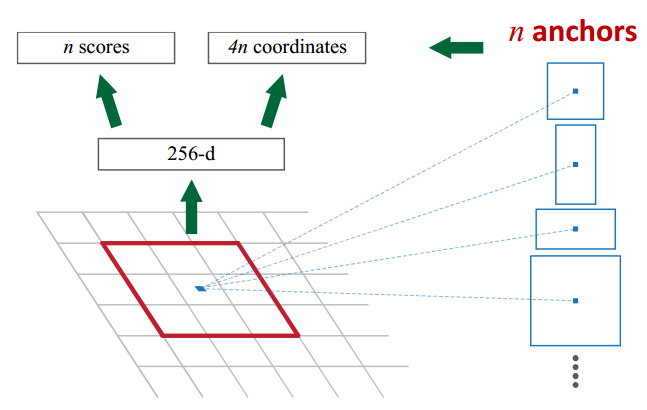
anchor的后处理如上图所示。

上图展示了Image/Feature Pyramid、Filter Pyramid和Anchor Pyramid的区别。
定义损失函数
对于每个anchor,首先在后面接上一个二分类softmax(上图左边的Softmax),有2个score输出用以表示其是一个物体的概率与不是一个物体的概率 (\(p_i\))。这个概率也可以理解为前景与后景,或者物体和背景的概率。
然后再接上一个bounding box的regressor输出代表这个anchor的4个坐标位置(\(t_i\)),因此RPN的总体Loss函数可以定义为 :
\[L(\{p_i\},\{t_i\})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\lambda \frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*)\]该公式的含义和计算都比较复杂,这里不做过多解释,而仅对检测框的坐标位置(\(t_i\))的计算步骤做一个简要的概述。
1.生成anchor坐标。这里由于是按照固定的规则生成的,因此可以预先生成。它的值与图片内容无关,而仅与图片大小相关。
2.bounding box修正。如果把anchor坐标看作A,那么bounding box修正就是\(\Delta A\)。
3.im_info修正。对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[W, H, scale_W, scale_H]则保存了此次缩放的所有信息。
上图中,二分类softmax前后各添加了一个reshape layer,是什么原因呢?
这与caffe的实现的有关。bg/fg anchors的矩阵,其在caffe blob中的存储形式为[batch size, 2x9, H, W]。这里的2代表二分类,9是anchor的个数。因为这里的softmax只分两类,所以在进行计算之前需要将blob变为[batch size, 2, 9xH, W]。之后再reshape回复原状。
RPN和Fast R-CNN协同训练
我们知道,如果是分别训练两种不同任务的网络模型,即使它们的结构、参数完全一致,但各自的卷积层内的卷积核也会向着不同的方向改变,导致无法共享网络权重,论文作者提出了几种可能的方式。
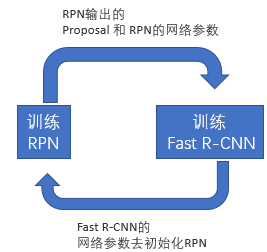
Alternating training
此方法其实就是一个不断迭代的训练过程,既然分别训练RPN和Fast-RCNN可能让网络朝不同的方向收敛:
a) 我们可以先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN。
b) 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。
Approximate joint training or Non-approximate training
这两种方式,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内训练。融合方式和上面的Faster R-CNN结构图类似。细节不再赘述。
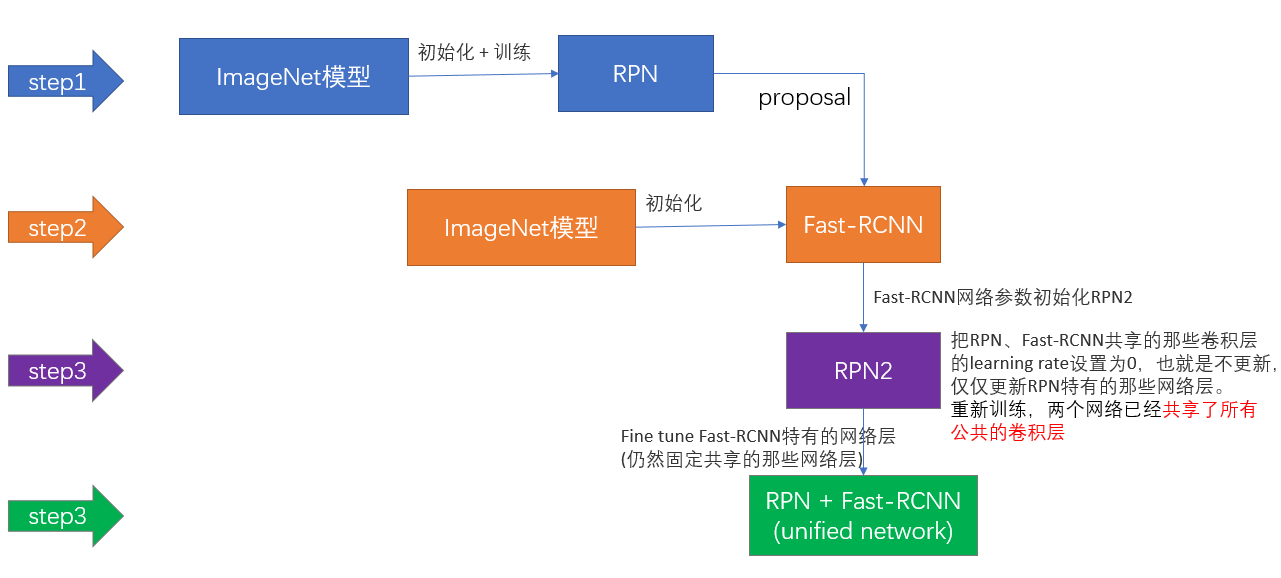
4-Step Alternating Training
这是作者发布的源代码中采用的方法。
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。

您的打赏,是对我的鼓励
