speech » 深度语音识别(二)——Deep Speech, 语音合成
2019-03-01 :: 5994 WordsCTC(续)
参考
https://www.zhihu.com/question/55851184
基于CTC等端到端语音识别方法的出现是否标志着统治数年的HMM方法终结?
https://zhuanlan.zhihu.com/p/23308976
CTC——下雨天和RNN更配哦
https://zhuanlan.zhihu.com/p/23293860
CTC实现——compute ctc loss(1)
https://zhuanlan.zhihu.com/p/23309693
CTC实现——compute ctc loss(2)
http://blog.csdn.net/xmdxcsj/article/details/70300591
端到端语音识别(二)ctc。这个blog中还有5篇《CTC学习笔记》的链接。
https://blog.csdn.net/luodongri/article/details/77005948
白话CTC(connectionist temporal classification)算法讲解
https://zhuanlan.zhihu.com/p/339612348
CTC总结
Warp-CTC
Warp-CTC是一个可以应用在CPU和GPU上的高效并行的CTC代码库,由百度硅谷实验室开发。
官网:
https://github.com/baidu-research/warp-ctc
非官方caffe版本:
https://github.com/xmfbit/warpctc-caffe
Deep Speech
Deep Speech是吴恩达领导的百度硅谷AI Lab 2014年的作品。
论文:
《Deep Speech: Scaling up end-to-end speech recognition》
代码:
https://github.com/mozilla/DeepSpeech
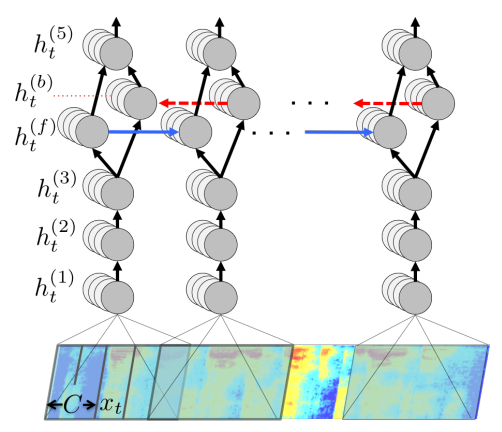
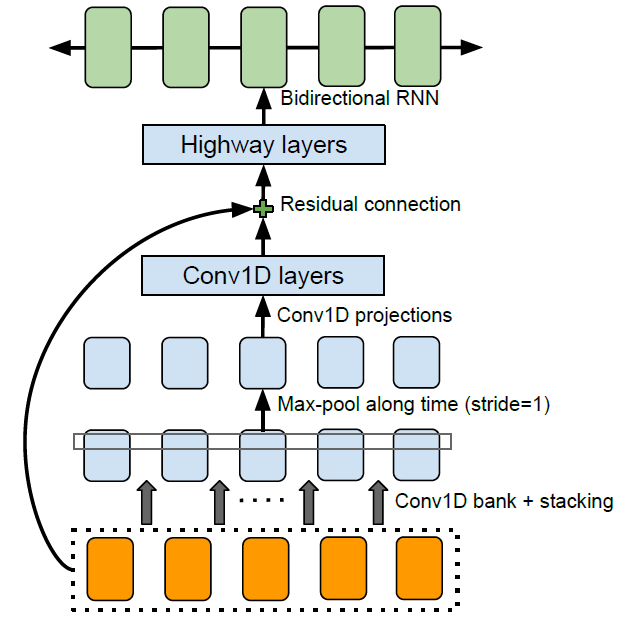
上图是Deep Speech的网络结构图。网络的前三层和第5层是FC,第4层是双向RNN,Loss是CTC。
主要思路:
1.这里的FC只处理部分音频片段,因此和CNN有异曲同工之妙。
2.论文解释了不用LSTM的原因是:很难并行处理。
参考:
http://blog.csdn.net/xmdxcsj/article/details/54848838
Deep Speech笔记
Deep speech 2
Deep speech 2是Deep speech原班人马2015年的作品。
论文:
《Deep speech 2: End-to-end speech recognition in english and mandarin》
代码:
https://github.com/PaddlePaddle/DeepSpeech
这个官方代码是PaddlePaddle实现的,由于比较小众,所以还有非官方的代码:
https://github.com/ShankHarinath/DeepSpeech2-Keras
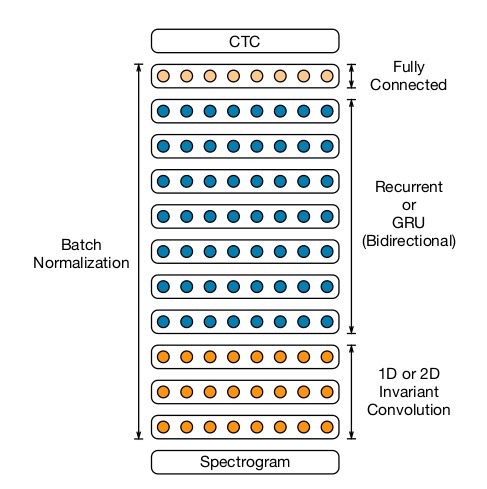
不出所料,这里使用CNN代替了FC,音频数据和图像数据一样,都是局部特征很明显的数据,从直觉上,CNN应该要比FC好使。
至于多层RNN或者GRU都是很自然的尝试。论文的很大篇幅都是各种调参,也就是俗称的“深度炼丹”。
论文附录中,如何利用集群进行分布式训练,是本文的干货,这里不再赘述。
EESEN
论文:
《EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-based Decoding》
苗亚杰,南京邮电大学本科(2008)+清华硕士(2011)+CMU博士(2016)。
个人主页:
http://www.cs.cmu.edu/~ymiao/
官网:
https://github.com/srvk/eesen
eesen是基于Tensorflow开发的,苗博士之前还有个用Theano开发的叫PDNN的库。
ESPnet
ESPnet是日本的研究人员2018年的作品。
论文:
《ESPnet: End-to-End Speech Processing Toolkit》
代码:
https://github.com/espnet/espnet
参考:
https://mp.weixin.qq.com/s/Disa8tS398J1mjwXkz5jrg
Advanced Methods for Neural End-to-End Speech Processing
whisper
https://zhuanlan.zhihu.com/p/678406937
openai开源的语音识别whisper部署教程
语音合成
语音合成(Speech synthesis),有时也叫做text-to-speech (TTS)。
早在12世纪,人们就尝试建造机器来合成人类语言。在18世纪下半叶,匈牙利科学家Wolfgang von Kempelen用一系列的风箱、弹簧、风笛和共振箱制造出一些简单的单词和句子,制造出了一个会说话的机器。
1930年,Bell实验室发明了声码器(Vocoder),将人的声音分解成声带振动和口唇调制两部分,改变口唇部分的调制函数后,就可以合成出不同的声音。这种合成方式物理学基础明确,系统简单,在80年代很受欢迎。著名物理学家霍金的轮椅就是采用这种方式发声的。这种合成方式的缺点在于发音的机器味道很浓,流畅度也不够。
90年代,人们采用更粗暴的方式来合成声音。研究者让播音员录制一个大规模声音库,然后从声音库中选出声音片段来,拼接成所要的句子。比如要合成“我想回家”,就在声音库里找到“我”、“想”、“回”、“家”这四个字对应的发音,再把他们拼成一句话。
这种拼接法里最重要的事是选择合适的发音片段,因为同一个音节在不同环境下的真正发音是不太一样的,要选出最合适的发音片段并不容易。同时,为了拼出的声音更自然,质量更高,声音库自然是越大越好,因此需要大量录制工作。
研究者提出统计模型方法来解决这个问题。和拼接法不同,统计模型方法对每个发音构造一个统计模型,这样只要调整模型参数就可以得到新的发音,而这种参数调整只需要很少的数据。
近年来,深度学习方法成为主流。和统计模型方法相比,深度神经网络对发音过程有更精细的刻画,因此可以合成非常自然逼真的声音。
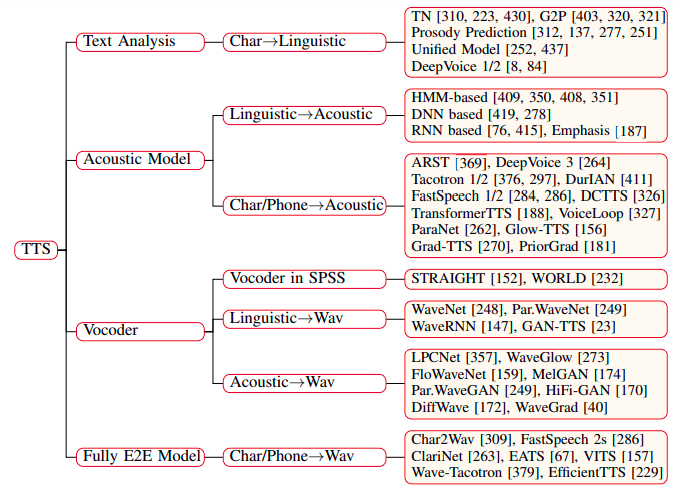
开源项目
Festival
Festival是CMU的Rob Clark和Alan Black发起的项目。
官网:
http://www.cstr.ed.ac.uk/projects/festival/
eSpeak NG
官网:
https://github.com/espeak-ng/espeak-ng/
gnuspeech
官网:
https://www.gnu.org/software/gnuspeech/
其他
其他的开源项目还有Gnopernicus、Orca、FreeTTS和Automatik Text Reader,但是这些项目目前基本处于不更新的状态了。
Tacotron
Tacotron是DeepMind提出的TTS模型。
论文:
《Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model》
代码:
https://github.com/keithito/tacotron
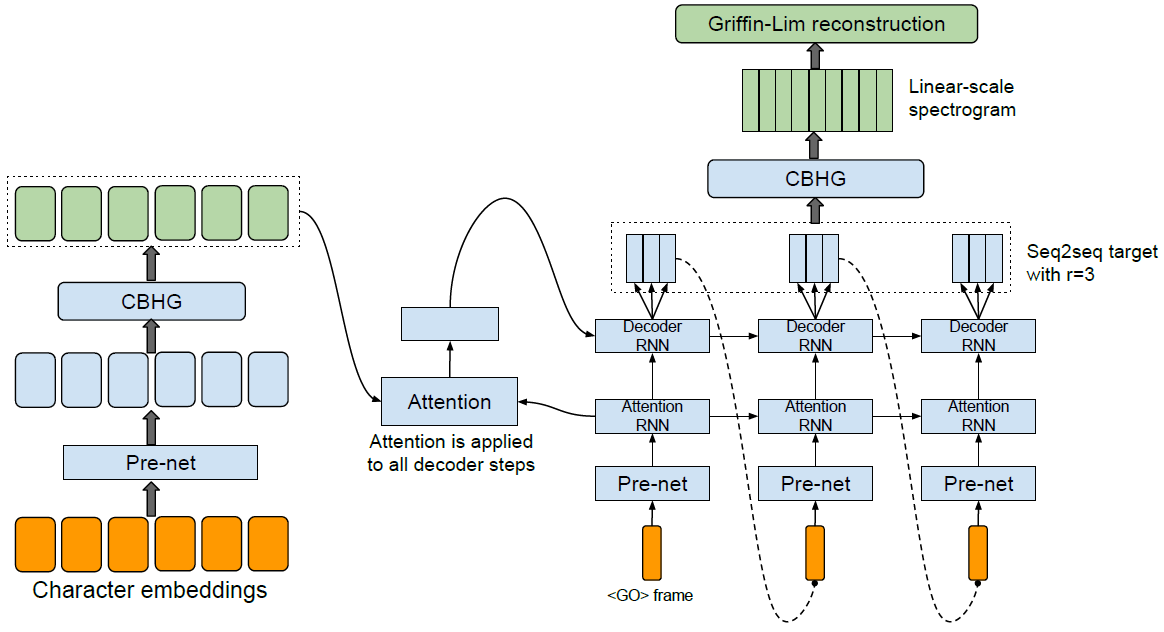
图中的Griffin-Lim reconstruction所使用的算法,是由Daniel W. Griffin和Jae S. Lim于1984年提出的。当然了,这是一种传统的信号处理算法,一般作为新的DL替代品的baseline使用。
Jae S. Lim,1950年生,韩裔美国人。MIT本硕博(1978)。MIT教授,IEEE Fellow。信号处理领域专家。
Griffin-Lim Algorithm(GLA)的论文:
《Signal Estimation from Modified Short-Time Fourier Transform》
参考:
https://mp.weixin.qq.com/s/MJE2JRYU7KakNKmHkD42CA
谷歌发布TTS新系统Tacotron 2:直接从文本生成类人语音
https://mp.weixin.qq.com/s/uh-Gh8BSxBi-jjG6-d7-UQ
Tacotron一种端到端的Text-to-Speech合成模型
https://www.jiqizhixin.com/articles/2017-03-31-5
谷歌全端到端语音合成系统Tacotron:直接从字符合成语音
https://mp.weixin.qq.com/s/Jzu2CLAiDjVFW5qICrE9Hw
基于Tacotron模型的语音合成实践
https://mp.weixin.qq.com/s/1A0oOMa2qKqbDNBCpaoZmA
我和欧阳娜娜一起搞研发
Tacotron-2
Tacotron2是Tacotron的升级版,也是DeepMind提出的。
论文:
《Natural TTS synthesis by conditioning Wavenet on MEL spectogram predictions》
代码:
https://github.com/Rayhane-mamah/Tacotron-2
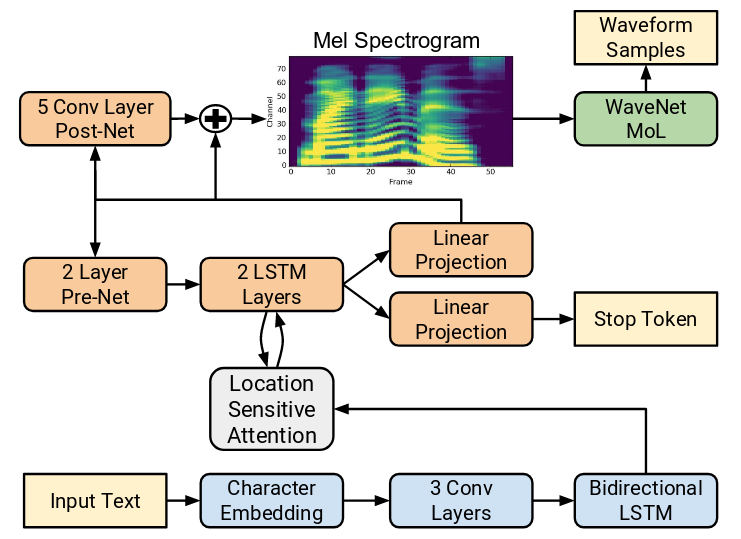
上图是Tacotron-2的体系结构图。除了标明Tacotron-2的网络结构之外,还给出了后续处理的pipeline:
1.Tacotron-2模型负责将Text转换为Mel Spectrum。
2.WaveNet模型负责将Mel Spectrum转换成wave pcm data。
WaveNet
WaveNet是DeepMind 2016年的作品,主要用于语音合成,也可用于语音识别。
DeepMind在WaveNet方面,按照时间顺序有3篇论文:
《WaveNet: A Generative Model For Raw Audio》
《Neural Machine Translation in Linear Time》
《Parallel WaveNet: Fast High-Fidelity Speech Synthesis》
代码:
https://github.com/ibab/tensorflow-wavenet
一个Tensorflow实现
https://github.com/buriburisuri/speech-to-text-wavenet
这个Tensorflow实现,利用WaveNet实现了语音识别。
https://github.com/usernaamee/keras-wavenet
keras版本的实现
除了RNN之外,CNN也经常被用于分析时间序列。为了表明序列之间的因果关系,人们通常采用一种叫做Causal Convolution的结构来进行数据采样。
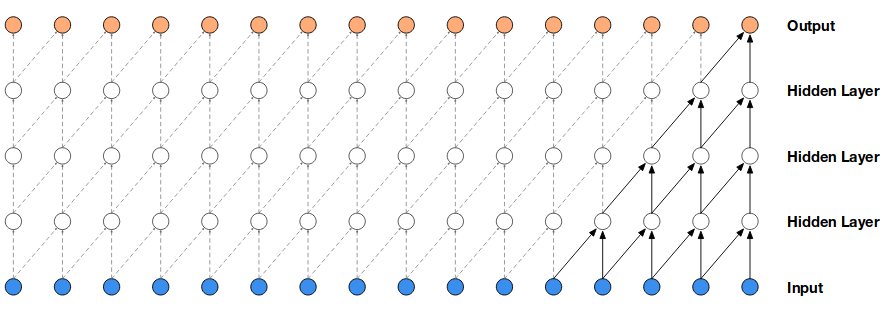
上图是Causal Convolution的结构图。从中可以很明显的看出它的局限性:
1.感受野较小。
2.为了增大感受野,需要添加更多的层,从而导致计算复杂和训练困难。

针对Causal Convolution的不足,WaveNet采用了Dilated Convolution的方式进行采样。具体的步骤如上图所示。
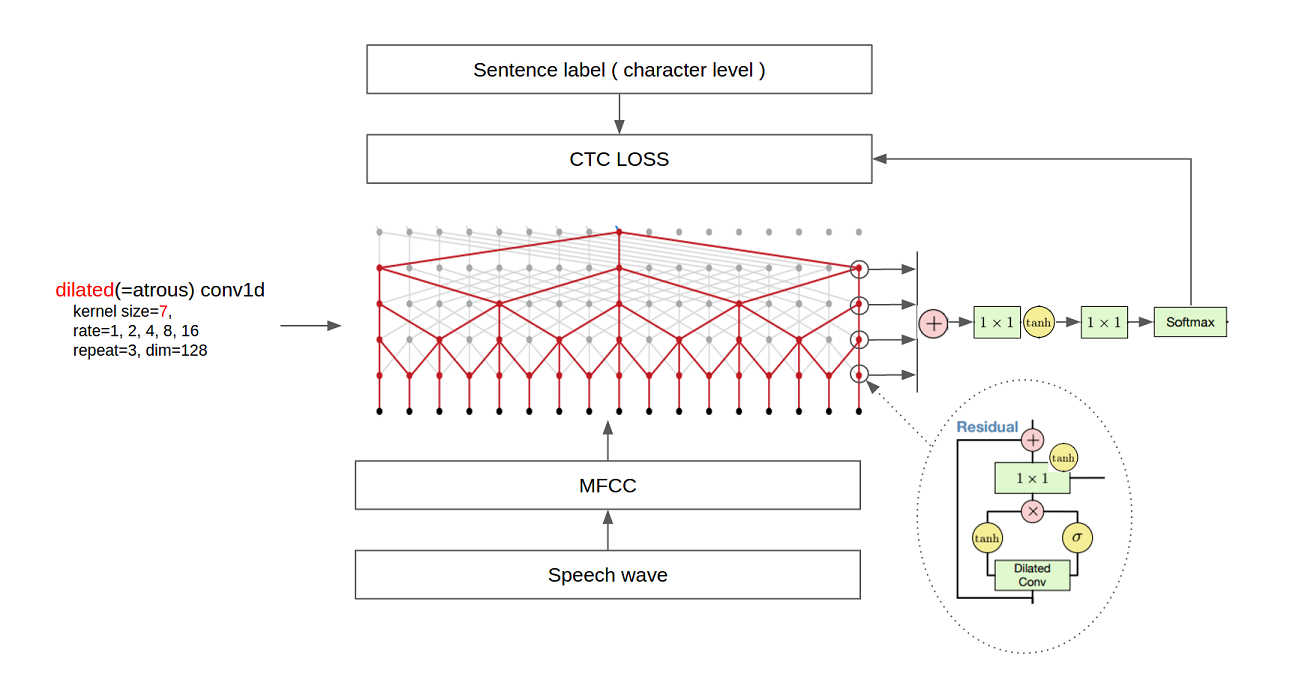
上图是WaveNet用于语音识别时的网络结构图。
参考:
https://www.leiphone.com/news/201609/ErWGa8fs7yR1zn2L.html
DeepMind发布最新原始音频波形深度生成模型WaveNet,将为TTS带来无数可能
https://zhuanlan.zhihu.com/p/27064536
用Wavenet做中文语音识别
https://mp.weixin.qq.com/s/-NTQG7_-GqGQWrRhiGgAQQ
详述DeepMind wavenet原理及其TensorFlow实现
http://mp.weixin.qq.com/s/0Xg_acbGG3pTIgsRQKJjrQ
历经一年,DeepMind WaveNet语音合成技术正式产品化
https://mp.weixin.qq.com/s/u1UnAuGllcWn8Ik5wDPY6w
可视化语音分析:深度对比Wavenet、t-SNE和PCA等算法
https://blog.csdn.net/tonygsw/article/details/81280364
因果卷积(causal)与扩展卷积(dilated)
https://zhuanlan.zhihu.com/p/161667958
NLP模型也能用来解决时间序列问题?WaveNet详解
WaveRNN
WaveRNN是WaveNet的升级版。
论文:
《Efficient Neural Audio Synthesis》
非官方代码:
https://github.com/fatchord/WaveRNN
WaveRNN没有沿用Dilated Convolution,而是采用了另外一种方式加速RNN运算。
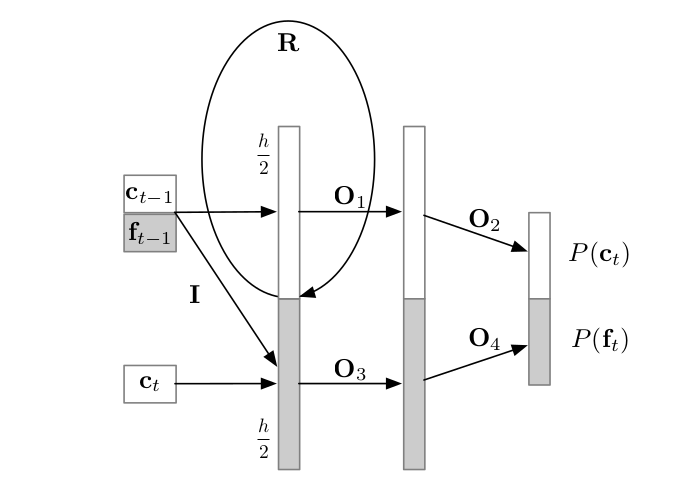
上图是WaveRNN的网络结构图。它将生成16bit采样点的任务,分解为生成高8bit和低8bit两个子任务。(这两者在论文中被称作coarse parts和fine parts。)这样最终生成样本的softmax层的大小就由\(2^{16}\)变成了\(2\times 2^8\)了。
这篇论文的另一个重要贡献是提出了Subscale WaveRNN。它的流程如下图所示:
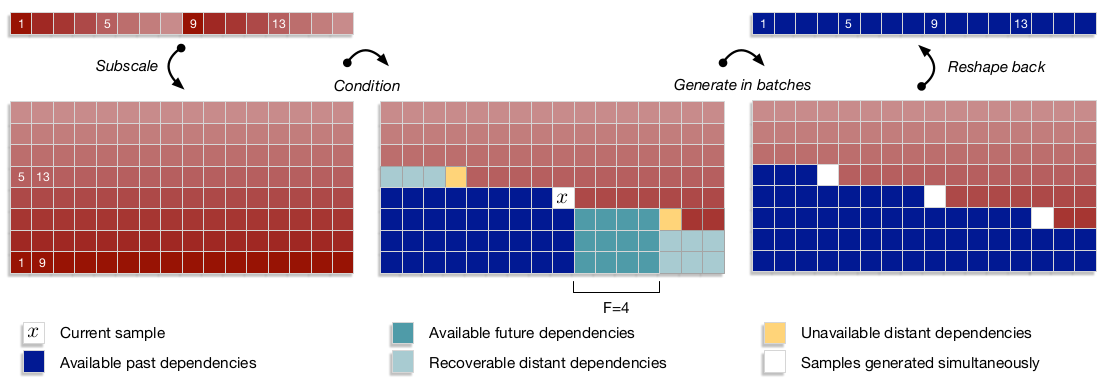
1.将原始序列重组为B组(B表示Batch Size,这里为8)。上图中的序号表示在原始序列中的序号。因此上图的含义显然就是:每隔8个样本进行一次采样,采样所得编为一组。总共有8个这样的组。
2.作者发现直接分组并行生成,虽然简单,但效果不好。其原因在于只用到了过去的序列数据,而缺少对整个序列信息的把握。但直接采用全局信息,又不是RNN的做法。为此论文提出了提前量的概念,即上图中的F。

您的打赏,是对我的鼓励
