speech » 深度语音识别(一)——概述, CTC
2019-02-26 :: 4884 Words概述
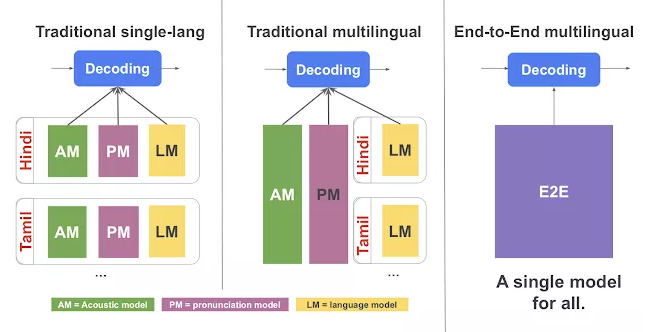
end-to-end(E2E)
《exploring neural transducers for end-to-end speech recognition》
| CTC | Transducer | Attention | |
|---|---|---|---|
| 输出语言模型 | 无 | 有 | 有 |
| 对齐 | 单调,硬 | 单调,硬 | 不单调,软 |
| 解码所需步数 | 输入长度 | 输入长度+输出长度 | 输出长度 |
最近还有一些基于Transformer的E2E方案。
CTC
概述
Connectionist Temporal Classification,是一种改进的RNN模型。它主要解决的是时序模型中,输入数大于输出数,输入输出如何对齐的问题。它由Alex Graves于2006年提出。
论文:
《Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks》
Alex Graves,瑞士IDSIA研究所博士,DeepMind研究员。
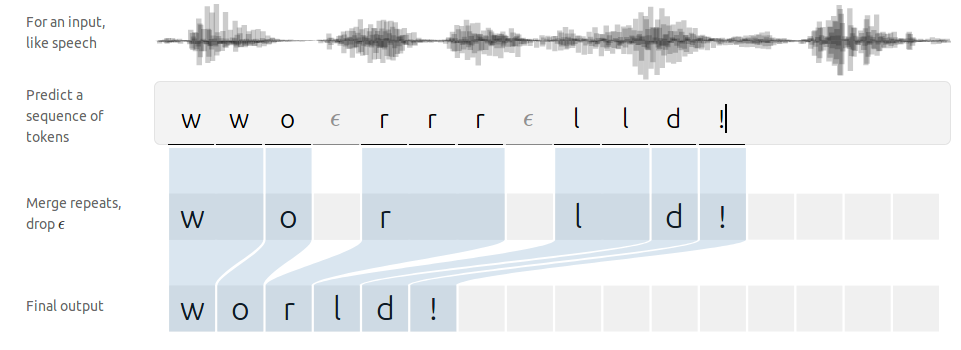
上图展示了音频数据被识别的过程:
1.将音频数据均分成若干段,每段匹配一个音节。
2.合并重复的音节,并去掉分割音节(即上图中的\(\epsilon\))。
相比于图像识别,人类语音的音节种类要少的多。但麻烦的是,一个音节的长短,会由于语速等因素的改变,而有较大差异。因此如何将数据段和音节匹配,成为了语音识别的难点。
这个问题不只是在语音识别中出现,我们在其他许多地方也能看到它。比如手写体识别、视频行为标注等。

我们首先用数学的方式定义对齐问题。假设输入序列为\(X=[x_1,x_2,\dots,x_T]\),输出序列为\(Y=[y_1,y_2,\dots,y_U]\),所谓对齐问题就是将X映射到Y。
这里的主要问题在于:
1.X和Y的长度可以变。
2.X和Y的长度比例可变。
3.我们没有一个X和Y之间的准确的对齐(对应元素)。
CTC算法可以克服这些挑战。对于一个给定的X,它给我们一个所有可能Y值的输出分布。我们可以使用这个分布来推断可能的输出或者评估一个给定输出的概率。
并不是所有的计算损失函数和执行推理的方法都是易于处理的。我们要求CTC可以有效地做到这两点。
损失函数:对于给定的输入,我们希望训练模型来最大化分配到正确答案的概率。 为此,我们需要有效地计算条件概率\(p(Y \mid X)\)。 函数\(p(Y \mid X)\)也应该是可微的,可以使用梯度下降。
推理:在我们训练好模型后,我们希望使用它来推断给定X的最可能的Y。即:
\[Y^*=\mathop{\text{argmax}}_{Y} p(Y \mid X)\]算法推导
为了推导CTC对齐的具体形式,我们首先考虑一种初级的做法:假设输入长度为6,Y=[c,a,t],对齐X和Y的一种方法是将输出字符分配给每个输入步骤并折叠重复的部分。
这种方法存在两个问题:
1.通常,强制每个输入步骤与某些输出对齐是没有意义的。例如在语音识别中,输入可以具有无声的延伸,但没有相应的输出。
2.我们没有办法产生连续多个字符的输出。考虑这个对齐[h,h,e,l,l,l,o],折叠重复将产生“helo”而不是“hello”。
为了解决这些问题,CTC为一组允许的输出引入了一个新的标记。这个新的标记有时被称为空白标记。我们在这里将其称为\(\epsilon\),\(\epsilon\)标记不对应任何东西,可以从输出中移除。
CTC允许的对齐是与输入的长度相同。 在合并重复并移除\(\epsilon\)标记后,我们允许任何映射到Y的对齐方式。
如果Y在同一行中有两个相同的字符,那么一个有效的对齐必须在它们之间有一个\(\epsilon\)。有了这个规则,我们就可以区分“hello”和“helo”了。
CTC对齐有一些显著的特性:
首先,X和Y之间允许的对齐是单调的。如果我们前进到下一个输入,我们可以保持相应的输出相同或前进到下一个输入。
第二个属性是X到Y的对齐是多对一的。一个或多个输入元素可以对齐到一个输出元素,但反过来不成立。
这意味着第三个属性:Y的长度不能大于X的长度。

上图是CTC对齐的一般步骤:
1.输入序列(如音频的频谱图)导入一个RNN模型。
2.RNN给出每个time step所对应的音节的概率\(p_t(a \mid X)\)。上图中音节的颜色越深,其概率p越高。
3.计算各种时序组合的概率,给出整个序列的概率。
4.合并重复并移除空白之后,得到最终的Y。
严格的说,一对(X,Y)的CTC目标函数是:
\[p(Y\mid X)=\sum_{A\in A_{X,Y}}\prod_{t=1}^Tp_t(a_t\mid X)\]这里的模型通常使用一个RNN来估计每个time step的概率,但是也可以自由使用任何学习算法,在给定一个固定尺寸输入片段的情况下产生一个输出类别的分布。
在实际训练中,针对训练集\(\mathcal{D}\),一般采用最小化log-likelihood的方式计算CTC loss:
\[\sum_{(X,Y)\in \mathcal{D}}-\log p(Y\mid X)\]采用穷举法计算上述目标函数,计算量是非常巨大的。我们可以使用动态规划算法更快的计算loss。关键点是,如果两个对齐在同一步已经达到了相同的输出,可以合并它们。如下图所示:
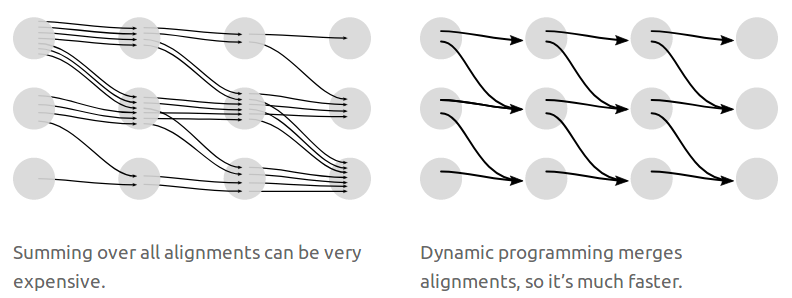
这里如果把音节匹配换成掷骰子的例子,就可以看出这实际上和《机器学习(三十)》中HMM所解决的第二个问题是类似的,而HMM的前向计算正是一种动态规划算法。动态规划算法可参见《强化学习(三)》。
下面我们来介绍一下具体的计算方法。
首先使用\(\epsilon\)分隔Y中的符号,就得到了序列Z:
\[Z=[\epsilon,y_1,\epsilon,y_2,\dots,\epsilon,y_U,\epsilon]\]用\(\alpha_{s,t}\)表示子序列\(Z_{1:s}\)在t步之后的CTC值。显然,我们需要计算的目标\(P(Y\mid X)\)和最后一步的\(\alpha\)有关,但只有计算出了上一步的\(\alpha\),我们才能计算当前的\(\alpha\)。
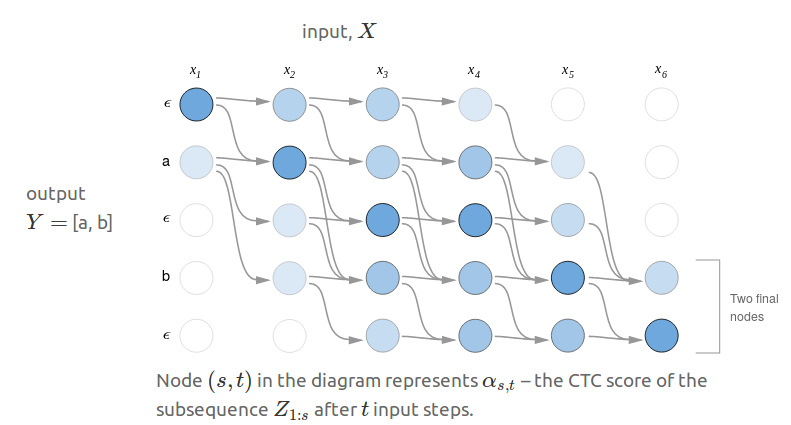
不同于掷骰子过程中,骰子的每种状态都有可能出现的情况,语音由于具有连续性,因此有些情况实际上是不可能的。比如上图的\(x_1\)就不大可能是后三个符号。
所以,可能的情况实际上只有两种:
Case 1
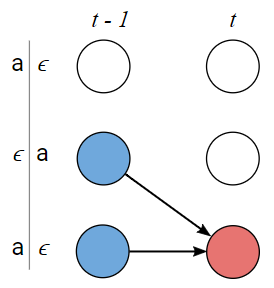
上图表示的是语音在两个相同token之间切换的情况。(这种情况也就是上面提到的hello例子中,语音在两个l之间过渡的情况。)
在这种情况下,\(\alpha\)的计算公式如下:
\[\alpha_{s,t}=(\alpha_{s-1,t-1}+\alpha_{s,t-1})\cdot p_t(Z_s \mid X)\]Case 2
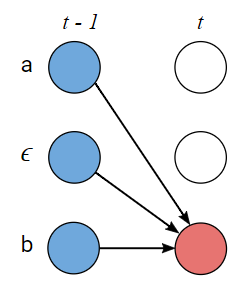
上图表示的是语音在两个不同token之间切换的情况。
在这种情况下,\(\alpha\)的计算公式如下:
\[\alpha_{s,t}=(\alpha_{s-2,t-1}+\alpha_{s-1,t-1}+\alpha_{s,t-1})\cdot p_t(Z_s \mid X)\]推断计算
我们首先看看CTC的正向推断(Inference)是如何计算的。
在前面的章节我们已经指出,由于对齐有很多种可能的情况,采用穷举法是不现实的。
另一个比较容易想到的方法是:每步只采用最大可能的token。这种启发式算法,实际上就是A*算法。
A*算法计算速度快,但不一定能找到最优解。
一般采用改良的Beam Search算法,在准确率和计算量上取得一个trade off。
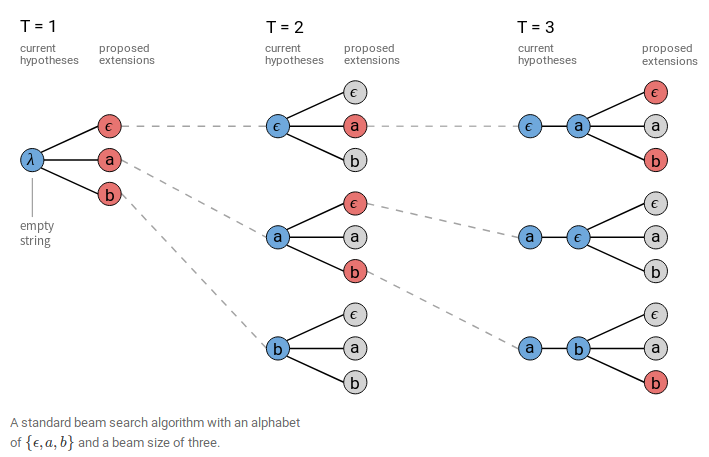
上图是一个Beam Width为3的Beam Search。Beam Search的细节可参见《机器学习(二十五)》。
由于语音的特殊性,我们实际上用的是Beam Search的一个变种:
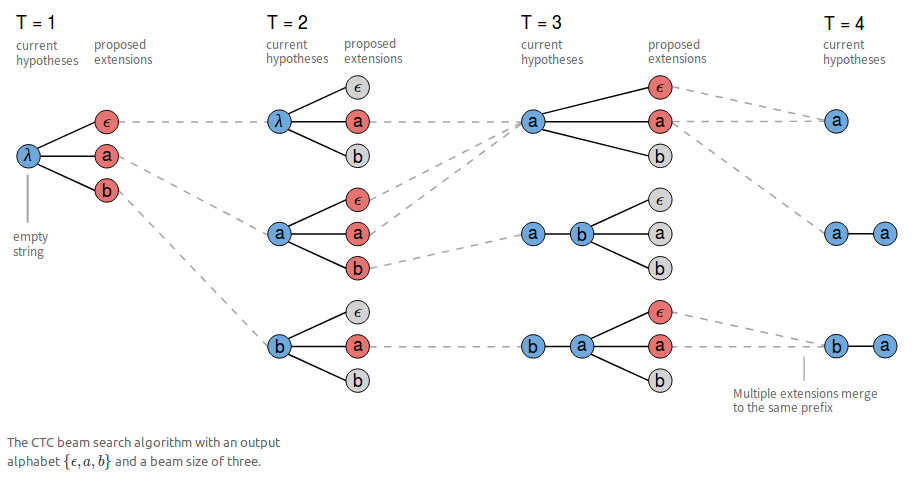
如上图所示,所有在合并规则下,能够合并为同一前缀的分支,在后续计算中,都被认为是同一分支。其概率值为各被合并分支的概率和。
此外,如果在语音识别中,能够结合语言模型的话,将可以极大的改善语音识别的准确率。这种情况下的CTC loss为:
\[Y^*=\mathop{\text{argmax}}_{Y} p(Y \mid X)\cdot p(Y)^{\alpha}\cdot L(Y)^{\beta}\]其中,\(p(Y)^{\alpha}\)是语言模型概率,而\(L(Y)^{\beta}\)表示词嵌入奖励。
CTC的特性
CTC是条件独立的。
缺点:条件独立的假设太强,与实际情况不符,因此需要语言模型来改善条件依赖性,以取得更好的效果。
优点:可迁移性比较好。比如朋友之间的聊天和正式发言之间的差异较大,但它们的声学模型却是类似的。
CTC是单调对齐的。这在语音识别上是没啥问题的,但在机器翻译的时候,源语言和目标语言之间的语序不一定一致,也就不满足单调对齐的条件。
CTC的输入/输出是many-to-one的,不支持one-to-one或one-to-many。比如,“th”在英文中是一个音节对应两个字母,这就是one-to-many的案例。
最后,Y的数量不能超过X,否则CTC还是没法work。
CTC应用
HMM
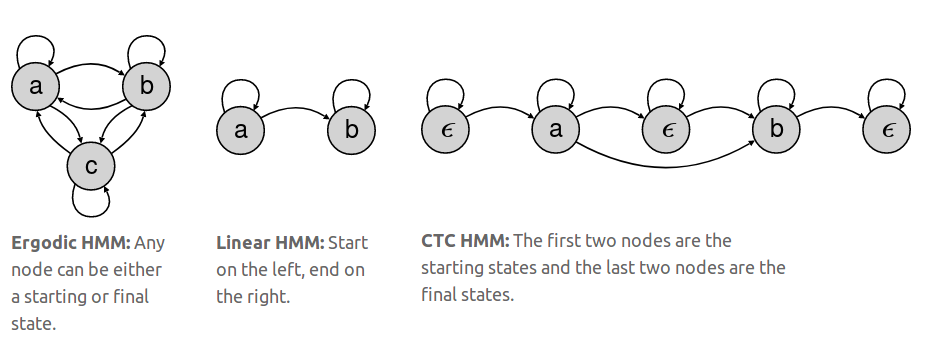
如上图所示,CTC是一种特殊的HMM。CTC的状态图是单向的,这也就是上面提到的单调对齐特性,这相当于给普通HMM模型提供了一个先验条件。因此,对于满足该条件的情况,CTC的准确度要超过HMM。
最重要的是,CTC是判别模型,它可以直接和RNN对接。
Encoder-Decoder模型
Encoder-Decoder模型是sequence问题最常用的框架,它的数学形式为:
\[\begin{array}\\ H=encode(X)\\ p(Y\mid X)=decode(H) \end{array}\]这里的H是模型的hidden representation。
CTC模型可以使用各种Encoder,只要保证输入比输出多即可。CTC模型常用的Decoder一般是softmax。
参考
https://distill.pub/2017/ctc/
Sequence Modeling With CTC
http://blog.csdn.net/laolu1573/article/details/78791992
Sequence Modeling With CTC中文版
https://mp.weixin.qq.com/s?__biz=MzIzNDQyNjI5Mg==&mid=2247483834&idx=1&sn=3a92eb19858d2cec709af28d2eb69c4a
时序分类算法之Connectionist Temporal Classification
http://blog.csdn.net/u012968002/article/details/78890846
CTC原理
https://www.zhihu.com/question/47642307
语音识别中的CTC方法的基本原理

您的打赏,是对我的鼓励
