RL » 强化学习(四)——Monte-Carlo
2019-03-02 :: 6020 Words动态规划(续)
DP的一些扩展
异步动态规划(Asynchronous Dynamic Programming)
采样更新(Sample Backups)
近似动态规划(Approximate Dynamic Programming)
参考
http://www.cppblog.com/Fox/archive/2008/05/07/Dynamic_programming.html
动态规划算法(Wikipedia中文翻译版)
https://www.zhihu.com/question/23995189
什么是动态规划?动态规划的意义是什么?
http://www.cnblogs.com/steven_oyj/archive/2010/05/22/1741374.html
动态规划算法
http://www.cppblog.com/menjitianya/archive/2015/10/23/212084.html
动态规划
https://segmentfault.com/a/1190000004454832
动态规划
http://www.cnblogs.com/jmzz/archive/2011/06/26/2090702.html
动态规划
http://www.cnblogs.com/jmzz/archive/2011/07/01/2095158.html
DP之Warshall算法和Floyd算法
http://www.cnblogs.com/jmzz/archive/2011/07/02/2096050.html
DP之最优二叉查找树
http://www.cnblogs.com/jmzz/archive/2011/07/02/2096188.html
DP之矩阵连乘问题
http://www.cnblogs.com/jmzz/archive/2011/07/05/2098630.html
DP之背包问题+记忆递归
http://www.cs.upc.edu/~mmartin/Ag4-4x.pdf
Bellman equations and optimal policies
https://mp.weixin.qq.com/s/a1C1ezL59azNfdM3TFGaGw
递推与储存,是动态规划的关键
http://www.cnblogs.com/SDJL/archive/2008/08/22/1274312.html
通过金矿模型介绍动态规划
https://mp.weixin.qq.com/s/fTQbatHpZFxxU6VGhJNVrg
0-1背包问题的动态规划算法
https://mp.weixin.qq.com/s/1yAnUVhzbckCqG2_ie07wg
什么是动态规划(Dynamic Programming)?
https://zhuanlan.zhihu.com/p/81819678
矩阵特征分解求动态规划的终极解法
https://mp.weixin.qq.com/s/630VEIh0Cbu7i8imE7L39w
回溯算法和动态规划,到底谁是谁爹?
https://mp.weixin.qq.com/s/-_DqyBIG3aSDWIYtkD7xuA
看动画轻松理解“递归“与“动态规划”
Monte-Carlo
概率算法
概率算法是和确定性算法相对的概念。概率算法的一个基本特征是对所求解问题的同一实例用同一概率算法求解两次,可能得到完全不同的效果。这两次求解问题所需的时间甚至所得到的结果,可能会有相当大的差别。
常见的概率算法主要有:数值概率算法,舍伍德(Sherwood)算法,蒙特卡罗(Monte Carlo)算法和拉斯维加斯(Las Vegas)算法。
在《数学狂想曲(三)》中我们已经提到了“统计模拟”的概念,这实际上就是数值概率算法的应用,它主要利用了大数定律与强大数定律。
这里有两个容易混淆的概念:Monte Carlo method和Monte Carlo algorithm。
Monte Carlo method这个概念的范围非常广,它实际上就是概率算法的别名。诸如用随机投针计算圆周率之类的算法,都可以看作是Monte Carlo method。
Monte Carlo algorithm就要狭义的多了,详情见下文。
舍伍德(Sherwood)算法
设A是一个确定算法,\(f(x)\)是解某个实例x的执行时间,设n是一整数,\(X_n\)是大小为n的实例的集合.假定\(X_n\)中每一个实例是等可能出现的,则算法A解\(X_n\)中一个实例的平均执行时间是:
\[\overline{f(x)}=\sum_{x\in X_n}f(x)/n\]假如存在一个实例\(x_0\)使得\(f(x_0)\gg \overline{f(x)}\),比如快速排序在最坏情况下的复杂度\(O(n)\gg O(n\log n)\)。这时使用sherwood对原始算法进行改进是有价值的。
Sherwood算法通过增加一个较小的额外开销从而使得算法的复杂度与具体实例x无关。例如,在快速排序中,我们是以第一个元素为基准开始排序时,为了避免这样的情况,可以用舍伍德算法解决,也就是使第一个基准元素是随机的。
蒙特卡罗(Monte Carlo)算法
举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的。
拉斯维加斯(Las Vegas)算法
假如有一把锁,给我100把钥匙,只有1把是对的。于是我每次随机拿1把钥匙去试,打不开就再换1把。我试的次数越多,打开(最优解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯算法——尽量找最好的,但不保证能找到。
比如N皇后的排列问题,除了顺序枚举法之外,随机枚举也是一种策略。
Monte Carlo method与RL
MDP的缺点在于model是已知的,但在实际应用中,更多的是Model未知(或部分未知)或者建模困难的情况,这种情况下就需要使用MC method来生成相应的Model。
MC method在RL中主要有两种使用方式:
model-free:完全不依赖Model。
Simulated:简单的模拟,而不需要完整的Model。
MC method用experience替代了MDP中的transitions/rewards(也可以说是用empirical mean替代了expected),但需要注意这些experience不能是重复采样的,而且它只适用于周期性的MDP。
Monte Carlo Policy Evaluation
Monte Carlo Policy Evaluation的目标是对状态s进行估值。它的步骤是:
当s被访问到(visited)时:
增加计数:\(N(s)\leftarrow N(s) + 1\)
增加总奖励:\(S(s)\leftarrow S(s) + G_t\)
\(V(s) = S(s)/N(s)\)
反复多次:\(N(s)\to \infty,V(s)\to v_{\pi}(s)\)
根据Visit的策略不同,Monte Carlo Policy Evaluation又可分为:First-visit MC和Every-Visit MC。
两者的差别在于:First-visit MC的每次探索,一旦抵达状态s,就结束了,Every-Visit MC到达状态s之后还可以继续探索。
Incremental Monte-Carlo Updates
借用《强化学习(二)》中,求均值的小技巧,我们可以得到Incremental Mean。
用Incremental Mean进行更新,被称作Incremental Monte-Carlo Updates:
\[V(S_t)\leftarrow V(S_t)+\frac{1}{N(S_t)}(G_t-V(S_t))\]对于非平稳(non-stationary)问题,我们也可采用如下公式更新:
\[V(S_t)\leftarrow V(S_t)+\alpha(G_t-V(S_t))\]参考
https://mp.weixin.qq.com/s/F9VlxVV4nXELyKxdRo9RPA
强化学习——蒙特卡洛
https://www.zhihu.com/question/20254139
蒙特卡罗算法是什么?
http://www.cnblogs.com/2010Freeze/archive/2011/09/19/2181016.html
概率算法-sherwood算法
http://www.cnblogs.com/chinazhangjie/archive/2010/11/11/1874924.html
概率算法
https://mp.weixin.qq.com/s/h9S5HZQwQKstDAKth-9Qeg
蒙特卡洛算法(MC)
https://mp.weixin.qq.com/s/wfCyii6bS-GxMZPg2TPaLA
蒙特卡洛树搜索是什么?如何将其用于规划星际飞行?
https://www.zhihu.com/question/39916945
蒙特卡洛树是什么算法?
https://mp.weixin.qq.com/s/tqhPGG2Djl4gnd09RdHsUA
一个彻底改变世界的思想
https://mp.weixin.qq.com/s/vKVX-aJ7n7VVDXOpoTo1GQ
通过Python实现马尔科夫链蒙特卡罗方法的入门级应用
https://mp.weixin.qq.com/s/HlDRI1s16k2k8RDh0GoXcw
详解蒙特卡洛方法:这些数学你搞懂了吗?
https://mp.weixin.qq.com/s/yGQSihfBDcXgqBnvvpQDog
蒙特卡罗方法入门
https://mp.weixin.qq.com/s/fAxDlrumUjc_6eqwGtcSxQ
详解蒙特卡洛方法:这些数学你搞懂了吗?
https://mp.weixin.qq.com/s/b1k9uDrq5_1-ArWBvphtgA
一个彻底改变世界的思想
Temporal-Difference Learning
TD
时序差分学习和蒙特卡洛学习一样,它也从Episode学习,不需要了解模型本身;但是它可以学习不完整的Episode,通过bootstrapping,猜测Episode的结果,同时持续更新这个猜测。
最简单的TD算法——TD(0)的更新公式如下:
\[V(S_t)\leftarrow V(S_t)+\alpha(R_{t+1}+\gamma V(S_{t+1})-V(S_t))\]其中,\(R_{t+1}+\gamma V(S_{t+1})\)被称作TD target,而\(\delta_t=R_{t+1}+\gamma V(S_{t+1})-V(S_t)\)被称作TD error。
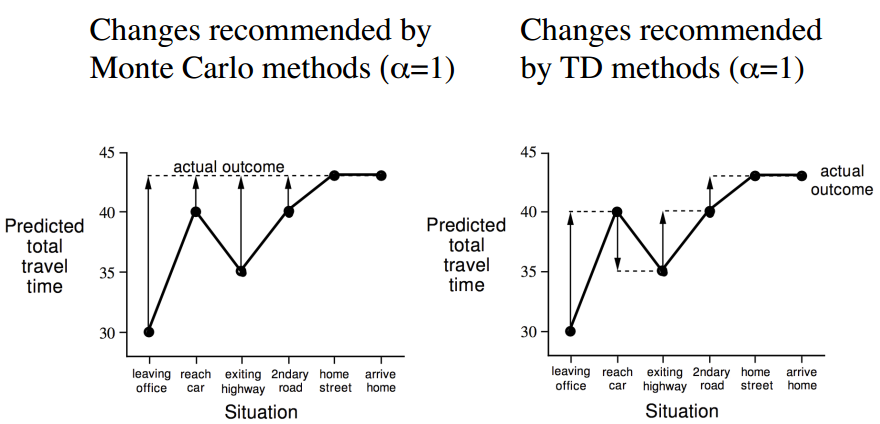
下面用驾车返家的例子直观解释蒙特卡洛策略评估和TD策略评估的差别。
想象一下你下班后开车回家,需要预估整个行程花费的时间。假如一个人在驾车回家的路上突然碰到险情:对面迎来一辆车感觉要和你相撞,严重的话他可能面临死亡威胁,但是最后双方都采取了措施没有实际发生碰撞。
如果使用蒙特卡洛学习,路上发生的这一险情可能引发的负向奖励不会被考虑进去,不会影响总的预测耗时;
但是在TD学习时,碰到这样的险情,这个人会立即更新这个状态的价值,随后会发现这比之前的状态要糟糕,会立即考虑决策降低速度赢得时间,也就是说你不必像蒙特卡洛学习那样直到他死亡后才更新状态价值。实际上那种情况下,也无法更新状态价值了。。。囧
TD算法相当于在整个返家的过程中(一个Episode),根据已经消耗的时间和预期还需要的时间来不断更新最终回家需要消耗的时间。
| 状态 | 已消耗时间 | 预计仍需耗时 | 预测总耗时 |
|---|---|---|---|
| 离开办公室 | 0 | 30 | 30 |
| 取车,发现下雨 | 5 | 35 | 40 |
| 离开高速公路 | 20 | 15 | 35 |
| 被迫跟在卡车后面 | 30 | 10 | 40 |
| 到达家所在街区 | 40 | 3 | 43 |
| 到家 | 43 | 0 | 43 |
基于上表所示的数据,下图展示了蒙特卡洛学习和TD学习两种不同的学习策略来更新价值函数(各个状态的价值)。这里使用的是从某个状态预估的到家还需耗时来间接反映某状态的价值:某位置预估的到家时间越长,该位置价值越低,在优化决策时需要避免进入该状态。
对于蒙特卡洛学习过程,驾驶员在路面上碰到各种情况时,他不会更新对于回家的预估时间,等他回到家得到了真实回家耗时后,他会重新估计在返家的路上着每一个主要节点状态到家的时间,在下一次返家的时候用新估计的时间来帮助决策。
而对于TD学习,在一开始离开办公室的时候你可能会预估总耗时30分钟,但是当你取到车发现下雨的时候,你会立刻想到原来的预计过于乐观,因为既往的经验告诉你下雨会延长你的返家总时间,此时你会更新目前的状态价值估计,从原来的30分钟提高到40分钟。同样当你驾车离开高速公路时,会一路根据当前的状态(位置、路况等)对应的预估返家剩余时间,直到返回家门得到实际的返家总耗时。这一过程中,你会根据状态的变化实时更新该状态的价值。

您的打赏,是对我的鼓励
