ML » 机器学习(十九)——关联规则挖掘
2017-01-18 :: 5165 Words关联规则挖掘
基本概念(续)
定义三:对于项集X,设定\(count(X\subseteq T)\)为交易集D中包含X的交易的数量,则项集X的支持度为:
\[support(X)=\frac{count(X\subseteq T)}{\mid D\mid }\]引例中\(X=\{bread, milk\}\)出现在T1,T2,T5,T9和T10中,所以支持度为0.5。
定义四:最小支持度是项集的最小支持阀值,记为\(SUP_{min}\),代表了用户关心的关联规则的最低重要性。支持度不小于\(SUP_{min}\)的项集称为频繁集,长度为k的频繁集称为k-频繁集。如果设定\(SUP_{min}\)为0.3,引例中\(\{bread, milk\}\)的支持度是0.5,所以是2-频繁集。
定义五:关联规则是一个蕴含式:
\[R:X\Rightarrow Y\]其中\(X\subset I\),\(Y\subset I\),并且\(X\cap Y=\varnothing\)。表示项集X在某一交易中出现,则导致Y以某一概率也会出现。用户关心的关联规则,可以用两个标准来衡量:支持度和可信度。
定义六:关联规则R的支持度是交易集同时包含X和Y的交易数与\(\mid D\mid\)之比。即:
\[support(X\Rightarrow Y)=\frac{count(X\cap Y)}{\mid D\mid }\]支持度反映了X、Y同时出现的概率。关联规则的支持度等于频繁集的支持度。
定义七:对于关联规则R,可信度是指包含X和Y的交易数与包含X的交易数之比。即:
\[confidence(X\Rightarrow Y)=\frac{support(X\Rightarrow Y)}{support(X)}\]可信度反映了如果交易中包含X,则交易包含Y的概率。一般来说,只有支持度和可信度较高的关联规则才是用户感兴趣的。
定义八:设定关联规则的最小支持度和最小可信度为\(SUP_{min}\)和\(CONF_{min}\)。规则R的支持度和可信度均不小于\(SUP_{min}\)和\(CONF_{min}\),则称为强关联规则。关联规则挖掘的目的就是找出强关联规则,从而指导商家的决策。
这八个定义包含了关联规则相关的几个重要基本概念,关联规则挖掘主要有两个问题:
1.找出交易数据库中所有大于或等于用户指定的最小支持度的频繁项集。
2.利用频繁项集生成所需要的关联规则,根据用户设定的最小可信度筛选出强关联规则。
其中,步骤1是关联规则挖掘算法的难点,下文介绍的Apriori算法和FP-growth算法,都是解决步骤1问题的算法。
参考:
http://blog.csdn.net/OpenNaive/article/details/7047823
关联规则挖掘(一):基本概念
Apriori算法
Apriori算法的思路如下:
1.第一次扫描交易数据库D时,产生1-频繁集。在此基础上经过连接、修剪产生2-频繁集。以此类推,直到无法产生更高阶的频繁集为止。
2.在第k次循环中,也就是产生k-频繁集的时候,首先产生k-候选集,k-候选集中每一个项集都是对两个只有一个项不同的属于k-1频繁集的项集连接产生的。
3.k-候选集经过筛选后产生k-频繁集。
从频繁集的定义,我们可以很容易的推导出如下结论:
如果项目集X是频繁集,那么它的非空子集都是频繁集。
如果k-候选集中的项集Y,包含有某个k-1阶子集不属于k-1频繁集,那么Y就不可能是频繁集,应该从候选集中裁剪掉。Apriori算法就是利用了频繁集的这个性质。
参考:
http://zhan.renren.com/dmeryuyang?gid=3602888498023976650
小白学数据分析—->关联分析学习算法篇Apriori
http://blog.csdn.net/lizhengnanhua/article/details/9061755
Apriori算法详解之:一、相关概念和核心步骤
https://mp.weixin.qq.com/s/W1Bu_I3p2DO_sT2Nl0582w
Apriori算法原理总结
http://blog.csdn.net/u013250416/article/details/52701633
关联规则DHP算法详解
https://www.jianshu.com/p/1ccf4d450da0
频繁模式挖掘-DHP算法详解
FP-growth算法
Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除都需要扫描一次所有数据记录,造成整个算法在面临大数据集时显得无能为力。
FP-Growth算法是韩家炜等人在2000年提出的关联分析算法。它通过构造一个树结构来压缩数据记录,使得挖掘频繁项集只需要扫描两次数据记录,而且该算法不需要生成候选集合,所以效率会比较高。
韩家炜,中国科学技术大学本科(1979)+中科院硕士+威斯康辛大学博士(1985)。美国伊利诺伊大学香槟分校计算机系教授,IEEE和ACM院士。
FpGrowth算法的平均效率远高于Apriori算法,但是它并不能保证高效率,它的效率依赖于数据集,当数据集中的频繁项集的没有公共项时,所有的项集都挂在根结点上,不能实现压缩存储,而且Fptree还需要其他的开销,需要存储空间更大,使用FpGrowth算法前,对数据分析一下,看是否适合用FpGrowth算法。
参考:
http://www.cnblogs.com/fengfenggirl/p/associate_fpgowth.html
数据挖掘系列(2)–关联规则FpGrowth算法
https://mp.weixin.qq.com/s/zD5hwBmMmSxzTj-3YzZKdg
频繁集挖掘FP Tree详解
https://mp.weixin.qq.com/s/ahmVB0ktJ2PG37ErO-vIiQ
FP-growth算法:高效频繁项集挖掘
幸存者偏差
二战期间,盟军需要对战斗机进行装甲加厚,以提高生还率,但由于军费有限,只能进行局部升级。那么问题来了,究竟哪个部位最关键,最值得把装甲加厚来抵御敌方炮火呢?人们众口不一,最后一致决定采用统计调查的方式来解决,即:仔细检查每一驾战斗机返回时受到的损伤程度,计算出飞机整体的受弹状况,然后根据大数据分析决定。
不久,统计数据很快出炉:盟军飞机普遍受弹最严重的地方是机翼,有的几乎被打成了筛子;相反,受弹最轻的地方是驾驶舱及尾部发动机,许多飞机的驾驶舱甚至连擦伤都没有。
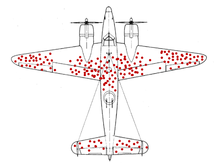
正当所有人拿着这份确凿无疑的报告准备给机翼加厚装甲时,统计学家Abraham Wald阻拦了他们,同时提出了一个完全相反的方案:加厚驾驶舱与尾部。理由非常简单:这两个位置中弹的飞机,都没有回来。换言之,它们是一份沉默的数据——“死人不会说话”。
最后,盟军高层纷纷听取了这个建议,加固了驾驶舱与尾部,果然空中战场局势得以好转,驾驶员生还率也大大提高。事实证明,这是一个无比英明的措施。
这个事例也被称作“幸存者偏差”(Survivorship bias)。它是一种典型的由于模型不当,导致的“数据说谎”。
Abraham Wald,1902~1950,生于奥匈帝国,维也纳大学博士。1938年为躲避纳粹,移民美国,哥伦比亚大学教授。Herman Chernoff的导师。其子Robert M. Wald,为著名理论物理学家,芝加哥大学教授,黑洞理论的提出者之一。
记者在列车上采访:这位乘客,您买到火车票了吗?
乘客甲:买到了!旁边这位呢?
乘客乙:买到了。
记者随机采访了十几个人,高兴地发现大家都买到了回家的火车票。
参考:
https://mp.weixin.qq.com/s/49YCWbmyoMW-0NyK_aK4Tg
大师告诉你,学习数学有什么用
https://mp.weixin.qq.com/s/5WYSbh-CBBhIy7ZnWrTFrA
从数学的角度看,为什么会有这么多渣男?
关联规则评价
“数据说谎”的问题很普遍。再看这样一个例子,我们分析一个购物篮数据中购买游戏光碟和购买影片光碟之间的关联关系。交易数据集共有10,000条记录,如表1所示:
| 表1 | 买游戏 | 不买游戏 | 行总计 |
|---|---|---|---|
| 买影片 | 4000 | 3500 | 7500 |
| 不买影片 | 2000 | 500 | 2500 |
| 列总计 | 6000 | 4000 | 10000 |
假设我们设置得最小支持度为30%,最小自信度为60%。从上面的表中,可以得到:
\[support(买游戏光碟\to 买影片光碟)=4000/10000=40\%\] \[confidence(买游戏光碟\to 买影片光碟)=4000/6000=66\%\]这条规则的支持度和自信度都满足要求,因此我们很兴奋,我们找到了一条强规则,于是我们建议超市把影片光碟和游戏光碟放在一起,可以提高销量。
可是我们想想,一个喜欢的玩游戏的人会有时间看影片么,这个规则是不是有问题,事实上这条规则误导了我们。在整个数据集中买影片光碟的概率p(买影片)=7500/10000=75%,而买游戏的人也买影片的概率只有66%,66%<75%恰恰说明了买游戏光碟抑制了影片光碟的购买,也就是说买了游戏光碟的人更倾向于不买影片光碟,这才是符合现实的。
从上面的例子我们看到,支持度和自信度并不总能成功滤掉那些我们不感兴趣的规则,因此我们需要一些新的评价标准,下面介绍几种评价标准:
相关性系数
相关性系数的英文名是Lift,这就是一个单词,而不是缩写。
\[\mathrm{lift}(X\Rightarrow Y) = \frac{ \mathrm{supp}(X \cup Y)}{ \mathrm{supp}(X) \times \mathrm{supp}(Y) }\] \[\mathrm{lift}(X\Rightarrow Y)\begin{cases} >1, & 正相关 \\ =1, & 独立 \\ <1, & 负相关 \\ \end{cases}\]实际运用中,正相关和负相关都是我们需要关注的,而独立往往是我们不需要的。显然:
\[\mathrm{lift}(X\Rightarrow Y)=\mathrm{lift}(Y\Rightarrow X)\]卡方系数
卡方系数是与卡方分布有关的一个指标。参见:
https://en.wikipedia.org/wiki/Chi-squared_distribution
\[\chi^2 = \sum_{i=1}^n \frac{(O_i - E_i)^2}{E_i}\]上式最早是Pearson给出的。
公式中的\(O_i\)表示数据的实际值,\(E_i\)表示期望值,不理解没关系,我们看一个例子就明白了。
| 表2 | 买游戏 | 不买游戏 | 行总计 |
|---|---|---|---|
| 买影片 | 4000(4500) | 3500(3000) | 7500 |
| 不买影片 | 2000(1500) | 500(1000) | 2500 |
| 列总计 | 6000 | 4000 | 10000 |
表2的括号中表示的是期望值。以第1行第1列的4500为例,其计算方法为:7500×6000/10000。
经计算可得表2的卡方系数为555.6。基于置信水平和自由度\((r-1)*(c-1)=(行数-1)*(列数-1)=1\),查表得到自信度为(1-0.001)的值为6.63。
555.6>6.63,因此拒绝A、B独立的假设,即认为A、B是相关的,而\(E(买影片,买游戏)=4500>4000\),因此认为A、B呈负相关。

您的打赏,是对我的鼓励
