ML » 机器学习(九)——规则化和模型选择
2016-09-02 :: 5680 Words规则化和模型选择
对于多项回归模型\(h_\theta(x)=g(\theta_0+\theta_1x_1+\dots+\theta_kx_k)\)来说,如何选择合适的k值呢?
或者,我们是选择局部权重回归(locally weighted regression),还是SVM呢?
我们定义算法模型的集合为\(\mathcal{M}=\{M_1,\dots,M_d\}\)。其中的\(M_i\)为不同的算法模型,比如SVM、神经网络等等。
交叉验证
回想之前讨论的过拟合和ERM算法,如果我们针对多项回归模型使用ERM算法,几乎必然会选择高方差的高维多项回归模型,因为它的训练误差最小。但这显然不是个好选择。
因此,我们改进算法如下:
1.从全部的训练数据S中随机选择70%的样例作为训练集\(S_{train}\),剩余的30%作为测试集\(S_{CV}\)。
2.在\(S_{train}\)上训练每一个\(M_i\),得到预测函数\(h_i\)。
3.在\(S_{CV}\)上测试每一个\(h_i\),得到相应的经验误差\(\hat\varepsilon_{S_{CV}}(h_i)\)。
4.选择具有最小\(\hat\varepsilon_{S_{CV}}(h_i)\)的\(h_i\),作为最佳模型。
这种方法被称为hold-out交叉验证(cross validation),或者称为简单(simple)交叉验证。
由于\(S_{train}\)和\(S_{CV}\)是随机选取的,因此我们可以认为这里的经验误差\(\hat\varepsilon_{S_{CV}}(h_i)\)是\(h_i\)的泛化误差的一个很好的估计值。测试集一般占所有样本数的1/4~1/3,这里的30%是一个典型值。
还可以对模型作改进,当选出最佳的模型\(M_i\)后,再在全部数据S上做一次训练,显然训练数据越多,模型参数越准确。
简单交叉验证方法的缺点在于得到的最佳模型是在70%的训练数据上选出来的,不代表在全部训练数据上是最佳的。还有当训练数据本来就很少时,再分出测试集后,训练数据就太少了。
我们对简单交叉验证方法再做一次改进,如下:
1.将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作\(\{S_1,\dots,S_k\}\)。
2.每次从模型集合\(\mathcal{M}\)中拿出来一个\(M_i\),然后在S中选择出k-1个子集\(S_1\cup\dots\cup S_{j-1}\cup S_{j+1}\cup\dots\cup S_k\),在这个集合上训练\(M_i\)得到预测函数\(h_{ij}\)。在\(S_j\)上测试\(h_{ij}\),得到相应的经验误差\(\hat\varepsilon_{S_j}(h_{ij})\)。
3.使用\(\frac{1}{k}\sum_{j=1}^k\hat\varepsilon_{S_j}(h_{ij})\)作为\(M_i\)泛化误差的估计值。
4.选出泛化误差估计值最小的\(M_i\),在S上重新训练,得到最终的预测函数\(h_i\)。
这个方法被称为k-折叠(k-fold)交叉验证。一般来说k取值为10,这样训练数据稀疏时,基本上也能进行训练,缺点是训练和测试次数过多。
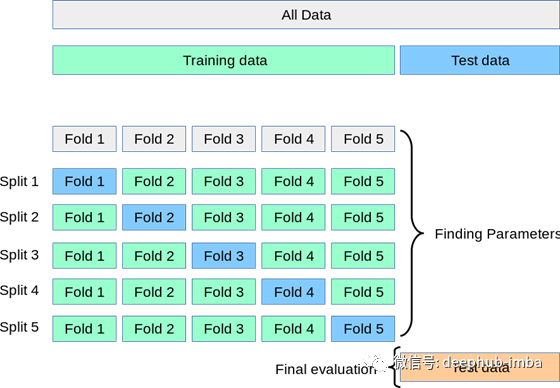
更极端的,如果\(k=m\),则该方法又被称为leave-one-out交叉验证。
参考:
https://mp.weixin.qq.com/s/OmSxnVL6pYYzB9_jDV4Lqg
模型评估方法基础总结
https://mp.weixin.qq.com/s/lrNvC8EWcq6cT16FU8nUbQ
5种常用的交叉验证技术,保证评估模型的稳定性
https://mp.weixin.qq.com/s/B7jIE8W3jHT_YS4psLJZCw
交叉验证和超参数调整:如何优化你的机器学习模型
https://mp.weixin.qq.com/s/PQKVSUnNa1SUwWIxo38_lw
8种交叉验证类型的深入解释和可视化介绍
特征选择
特征选择(Feature Selection)严格来说也是模型选择中的一种。
假设我们想对维度为n的样本点进行回归,如果,n远远大于训练样例数m,且你认为其中只有很少的特征起关键作用的话,就可以对整个特征集进行特征选择,以减少特征的数量。
对于n个特征的\(\mathcal{M}\)来说,根据特征是否包含在最终结果中,可以写出\(2^n\)个不同的\(M_i\)。直接使用上面的交叉验证方法,计算量过大。这时可以采用如下启发式算法:
1.初始化特征集\(\mathcal{F}=\emptyset\)。
2.Repeat {(a)for 特征i=1 to n, {
如果\(i\notin\mathcal{F}\),则\(\mathcal{F}_i=\mathcal{F}\cup\{i\}\)。
在\(\mathcal{F}_i\)上使用交叉验证方法评估它的泛化误差。}
(b)将第(a)步中最优的\(\mathcal{F}_i\)设为新的\(\mathcal{F}\)。}
3.选择并输出搜索过程中得到的最优子集。
这个算法被称为前向搜索(forward search)。其外部循环的终止条件为\(\lvert\mathcal{F}\rvert\)达到n或者事先设定的门限值。
前向搜索属于wrapper model特征选择方法的一种。 Wrapper这里指不断地使用不同的特征子集来测试学习的算法。
除了前向搜索之外,还有后向搜索(backward search)算法。它和前者的区别在于,它的初始集合为全集,然后每次删除一个特征,并评价,直到\(\lvert\mathcal{F}\rvert\)达到阈值或者为空,然后选择最佳的\(\mathcal{F}\)即可。
可以看出无论前向搜索,还是后向搜索,其算法复杂度都是\(O(n^2)\)。
参考:
https://mp.weixin.qq.com/s/lbku7wQK1k8nuC2QqIJrug
基于非负谱学习和稀疏回归的双图特征选择算法
https://mp.weixin.qq.com/s/6JberaY4H7it_UQiBls8wg
为你介绍7种流行的线性回归收缩与选择方法
https://mp.weixin.qq.com/s/7u0Jf5HR4N6G-6Sol3PyVA
一款功能强大的特征选择工具(Feature Selector)
https://mp.weixin.qq.com/s/2cBTzaIrPuG3oHVM_niYGQ
机器学习中特征选择怎么做?这篇文章告诉你
https://mp.weixin.qq.com/s/JM5ny8JPumXoL6wLD4-rpg
数据维度爆炸怎么办?详解5大常用的特征选择方法
https://mp.weixin.qq.com/s/FJWtQjL741Ff4sr1SBPkVA
这3个Scikit-learn的特征选择技术,能够有效的提高你的数据预处理能力
https://mp.weixin.qq.com/s/aqnbUutDZWux-WT8O9FdQg
为什么要停止过度使用置换重要性来寻找特征
https://mp.weixin.qq.com/s/aWGznmxMV7oFjvGhnZg2Aw
特征选择的通俗讲解
KL散度
KL散度(Kullback–Leibler divergence)是两个随机分布间距离的度量。其定义如下:
\[D_{KL}(P\|Q)=\sum_iP(i)\log\frac{P(i)}{Q(i)}\]其中,P和Q是离散概率分布,\(P(i)\)和\(Q(i)\)是相应分布的概率密度函数。如果P和Q是连续随机变量的话,将上式中的累加符号换成积分符号即可。
KL散度越小,两个分布之间的匹配就越好。
但KL散度并不是真正的度量(metric)。它既不满足三角不等式(两边之和\(\ge\)第三边),也不满足对称性(即\(D_{KL}(P\|Q)\neq D_{KL}(Q\|P)\))。
Solomon Kullback,1907~1994,美国数学家和密码学家。乔治·华盛顿大学博士。NSA首任首席科学家。二战期间,参与破解德国的Enigma机器。
Richard Leibler,1914~2003,美国数学家和密码学家。伊利诺伊大学博士。NSA高级主管,入选NSA名人堂。
参考:
https://mp.weixin.qq.com/s/e7YQfG578vWxApD-4gsWIg
如何理解KL散度的不对称性
https://mp.weixin.qq.com/s/PPz5iKY5Kb0vGqlfHvCJHA
初学机器学习:直观解读KL散度的数学概念
https://www.zhihu.com/question/345907033
KL散度衡量的是两个概率分布的距离吗?
https://zhuanlan.zhihu.com/p/139084847
理解Kullback–Leibler散度的近似
过滤特征选择方法
过滤特征选择(Filter feature selection)方法,是另一种启发式的特征选择算法,计算量比较小。它的思路是计算特征\(x_i\)和类别标签y之间的相关度的评分\(S(i)\)。
可以使用\(x_i\)和y之间的互信息量(mutual information),作为评分依据。
\[MI(x_i,y)=\sum_{x_i\in X_i}\sum_{y\in Y}p(x_i,y)\log\frac{p(x_i,y)}{p(x_i)p(y)}\]其中,\(p(x_i,y)\)是\(x_i\)和y的联合概率密度,\(p(x_i)\)和\(p(y)\)是相应的边缘概率密度。
和KL散度类似,如果x和y是连续随机变量的话,将上式中的累加符号换成积分符号即可。
MI也可以用KL散度来表示:
\[MI(x_i,y)=KL(p(x_i,y)\|p(x_i)p(y))\]过滤特征选择方法的算法复杂度为\(O(n)\)。
最后一个问题,选择多少个特征合适呢?按照\(S(i)\)从高到低的顺序,依次选择1到n个特征进行交叉验证,直到效果达到预期为止。
交叉验证与融合
前面提到的交叉验证的过程,一般如下图所示:
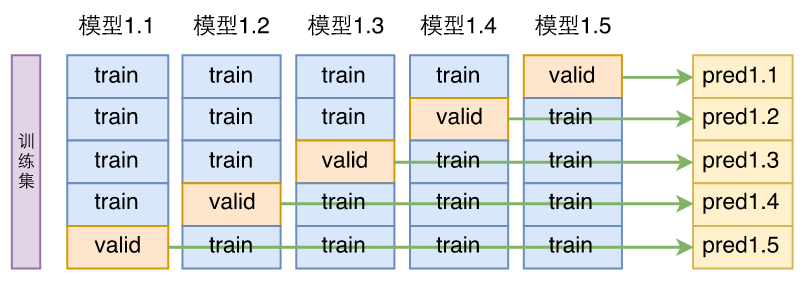
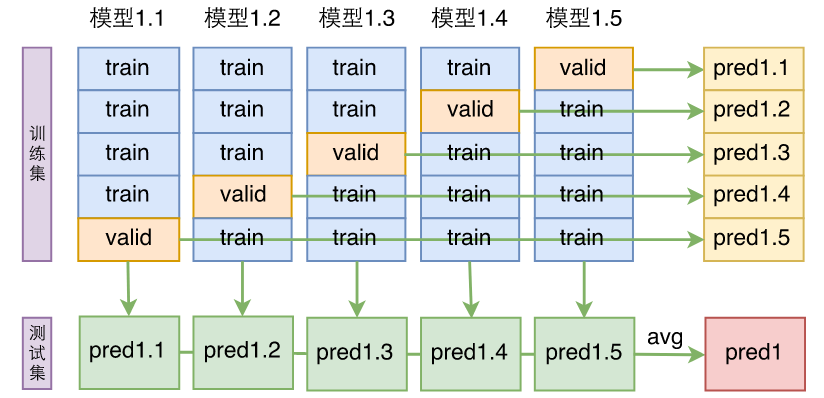
模型融合能大幅提升准确率,是打比赛的“杀器”。把交叉验证训练的n个模型直接求一下平均,就是最简单的模型融合方案。
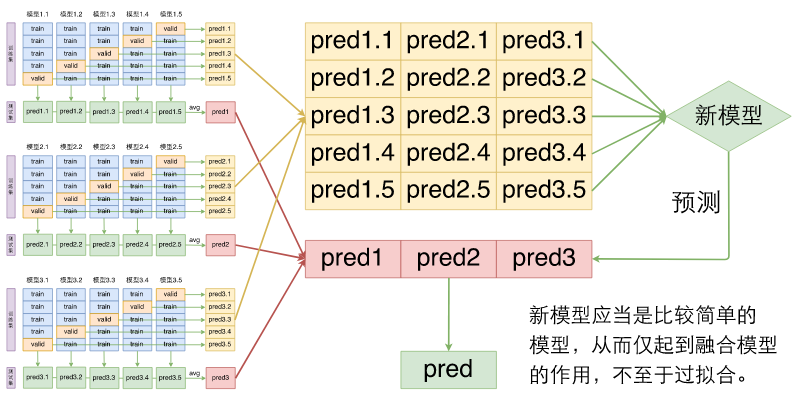
假如有m种不同的模型,每种模型做n划分交叉验证,可以得到mn个不同的模型,通过一个新模型来融合这mn个模型。
贝叶斯统计和规则化ML
前面提到最大似然(maximum likelihood)估计方法的公式如下:
\[\theta_{ML}=\arg\max_\theta\prod_{i=1}^mp(y^{(i)}\mid x^{(i)};\theta)\]从频率统计(frequentist statistic)学派的观点来看,这里的\(\theta\)是一个未知的常数,我们的任务就是求出这个常数。然而从贝叶斯学派的观点来看,\(\theta\)是一个未知的随机变量。
也就是说似然函数,对于前者来说,是这样的:\(\prod_{i=1}^mp(y^{(i)}\mid x^{(i)};\theta)\);但对于后者来说,却是这样的:\(\prod_{i=1}^mp(y^{(i)}\mid x^{(i)},\theta)\)
我们首先假定\(\theta\)的分布为\(p(\theta)\),这种假定由于没有事实根据,通常被称作先验分布(prior distribution)。
我们针对训练集\(S=\{(x^{(i)},y^{(i)})\}_{i=1}^m\),训练得到预测函数。并按照如下公式计算后验分布(posterior distribution):
\[p(\theta\mid S)=\frac{p(S\mid\theta)p(\theta)}{p(S)}\tag{1}\]由全概率公式可得:
\[p(S)=p(S\mid\theta_1)p(\theta_1)+\dots+p(S\mid\theta_n)p(\theta_n)\]上式的\(\theta_i\)表示\(\theta\)的各个取值区间,然而由于\(\theta\)是连续随机变量,根据微积分原理可得:
\[p(S)=\int_\theta p(S\mid\theta)p(\theta)\mathrm{d}\theta\tag{2}\]将公式2代入公式1可得:
\[p(\theta\mid S)=\frac{p(S\mid\theta)p(\theta)}{\int_\theta p(S\mid\theta)p(\theta)\mathrm{d}\theta}=\frac{\left(\prod_{i=1}^mp(y^{(i)}\mid x^{(i)},\theta)\right)p(\theta)}{\int_\theta\left(\prod_{i=1}^mp(y^{(i)}\mid x^{(i)},\theta)\right)p(\theta)\mathrm{d}\theta}\]当我们针对新的样本x进行预测时,和上面的推导类似,可得:
\[p(y\mid x,S)=\int_\theta p(y\mid x,\theta,S)p(\theta\mid S)\mathrm{d}\theta\]
您的打赏,是对我的鼓励
