Generative Model » VAE(二)——Vanilla VAE(2)
2019-04-29 :: 5187 WordsVanilla VAE(续)
VAE初现
其实,在整个VAE模型中,我们并没有去使用p(Z)(先验分布)是正态分布的假设,我们用的是假设\(p(Z\mid X)\)(后验分布)是正态分布!!
具体来说,给定一个真实样本\(X_k\),我们假设存在一个专属于\(X_k\)的分布\(p(Z\mid X_k)\)(学名叫后验分布),并进一步假设这个分布是(独立的、多元的)正态分布。为什么要强调“专属”呢?因为我们后面要训练一个生成器\(X=g(Z)\),希望能够把从分布\(p(Z\mid X_k)\)采样出来的一个\(Z_k\)还原为\(X_k\)。如果假设p(Z)是正态分布,然后从p(Z)中采样一个Z,那么我们怎么知道这个Z对应于哪个真实的X呢?现在\(p(Z\mid X_k)\)专属于\(X_k\),我们有理由说从这个分布采样出来的Z应该要还原到\(X_k\)中去。
这样有多少个X就有多少个正态分布了。我们知道正态分布有两组参数:均值\(\mu\)和方差\(\sigma^2\)(多元的话,它们都是向量),那我怎么找出专属于\(X_k\)的正态分布\(p(Z\mid X_k)\)的均值和方差呢?好像并没有什么直接的思路。那好吧,就用神经网络拟合出来吧!
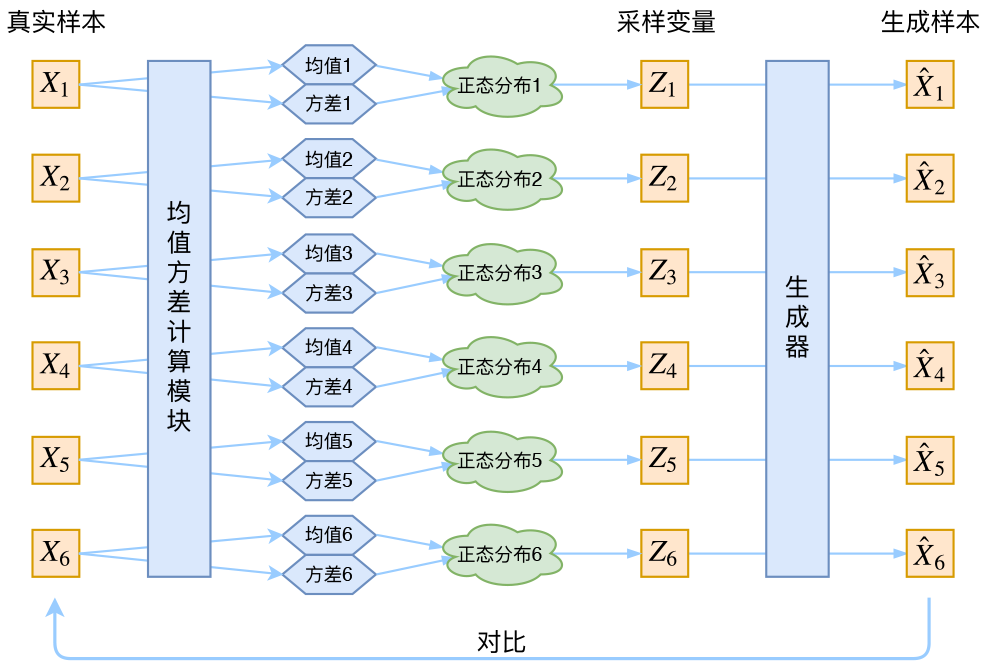
于是我们构建两个神经网络\(\mu_k = f_1(X_k),\log \sigma^2 = f_2(X_k)\)来算它们了。我们选择拟合\(\log \sigma^2\)而不是直接拟合\(\sigma^2\),是因为\(\sigma^2\)总是非负的,需要加激活函数处理,而拟合\(\log \sigma^2\)不需要加激活函数,因为它可正可负。到这里,知道专属于\(X_k\)的均值和方差,也就知道它的正态分布长什么样了,然后从这个专属分布中采样一个\(Z_k\)出来,经过一个生成器得到\(\hat{X}_k=g(Z_k)\),现在我们可以放心地最小化\(\mathcal{D}(\hat{X}_k,X_k)^2\),因为\(Z_k\)是从专属\(X_k\)的分布中采样出来的,这个生成器应该要把开始的\(X_k\)还原回来。
分布标准化
让我们来思考一下,根据上图的训练过程,最终会得到什么结果。
首先,我们希望重构X,也就是最小化\(\mathcal{D}(\hat{X}_k,X_k)^2\),但是这个重构过程受到噪声的影响,因为\(Z_k\)是通过重新采样过的,不是直接由encoder算出来的。显然噪声会增加重构的难度,不过好在这个噪声强度(也就是方差)通过一个神经网络算出来的,所以最终模型为了重构得更好,肯定会想尽办法让方差为0。而方差为0的话,也就没有随机性了,所以不管怎么采样其实都只是得到确定的结果(也就是均值)。说白了,模型会慢慢退化成普通的AutoEncoder,噪声不再起作用。
为了使模型具有生成能力,VAE决定让所有的\(p(Z\mid X)\)都向标准正态分布看齐。如果所有的\(p(Z\mid X)\)都很接近标准正态分布\(\mathcal{N}(0,I)\),那么根据定义:
\[p(Z)=\sum_X p(Z|X)p(X)=\sum_X \mathcal{N}(0,I)p(X)=\mathcal{N}(0,I) \sum_X p(X) = \mathcal{N}(0,I)\]这样我们就能达到我们的先验假设:p(Z)是标准正态分布。然后我们就可以放心地从\(\mathcal{N}(0,I)\)中采样来生成图像了。
那怎么让所有的\(p(Z\mid X)\)都向\(\mathcal{N}(0,I)\)看齐呢?如果没有外部知识的话,其实最直接的方法应该是在重构误差的基础上中加入额外的loss:
\[\mathcal{L}_{\mu}=\Vert f_1(X_k)\Vert^2,\mathcal{L}_{\sigma^2}=\Vert f_2(X_k)\Vert^2\]因为它们分别代表了均值\(\mu_k\)和方差的对数\(\log \sigma^2\),达到\(\mathcal{N}(0,I)\)就是希望二者尽量接近于0了。不过,这又会面临着这两个损失的比例要怎么选取的问题,选取得不好,生成的图像会比较模糊。所以,原论文直接算了一般(各分量独立的)正态分布与标准正态分布的KL散度\(KL\Big(N(\mu,\sigma^2)\Big\Vert N(0,I)\Big)\)作为这个额外的loss,计算结果为:
\[\mathcal{L}_{\mu,\sigma^2}=\frac{1}{2} \sum_{i=1}^d \Big(\mu_{(i)}^2 + \sigma_{(i)}^2 - \log \sigma_{(i)}^2 - 1\Big)\]这里的d是隐变量Z的维度,而\(\mu_{(i)}\)和\(\sigma_{(i)}^2\)分别代表一般正态分布的均值向量和方差向量的第i个分量。直接用这个式子做补充loss,就不用考虑均值损失和方差损失的相对比例问题了。显然,这个loss也可以分两部分理解:
\[\begin{aligned}&\mathcal{L}_{\mu,\sigma^2}=\mathcal{L}_{\mu} + \mathcal{L}_{\sigma^2}\\ &\mathcal{L}_{\mu}=\frac{1}{2} \sum_{i=1}^d \mu_{(i)}^2=\frac{1}{2}\Vert f_1(X)\Vert^2\\ &\mathcal{L}_{\sigma^2}=\frac{1}{2} \sum_{i=1}^d\Big(\sigma_{(i)}^2 - \log \sigma_{(i)}^2 - 1\Big)\end{aligned}\]综上,最终的Loss为:
\[\mathcal{L}=\mathcal{L}_{reconstruct}+\mathcal{L}_{\mu,\sigma^2}\]Reparameterization Trick
这是实现模型的一个技巧。我们要从\(p(Z\mid X_k)\)中采样一个\(Z_k\)出来,尽管我们知道了\(p(Z\mid X_k)\)是正态分布,但是均值方差都是靠模型算出来的,我们要靠这个过程反过来优化均值方差的模型,但是“采样”这个操作是不可导的,而采样的结果是可导的,于是我们利用了一个事实:
从\(\mathcal{N}(\mu,\sigma^2)\)中采样一个Z,相当于从\(\mathcal{N}(0,I)\)中采样一个\(\varepsilon\),然后让\(Z=\mu + \varepsilon \times \sigma\)。
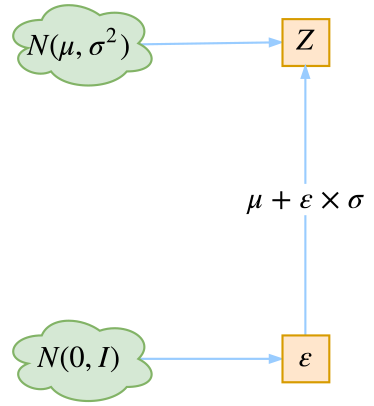
于是,我们将从\(\mathcal{N}(\mu,\sigma^2)\)采样变成了从\(\mathcal{N}(0,I)\)中采样,然后通过参数变换得到从\(\mathcal{N}(\mu,\sigma^2)\)中采样的结果。这样一来,“采样”这个操作就不用参与梯度下降了,改为采样的结果参与,使得整个模型可训练了。
VAE本质
VAE本质上就是在我们常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
那另外一个encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。直觉上来想,当decoder还没有训练好时(重构误差远大于KL loss),就会适当降低噪声(KL loss增加),使得拟合起来容易一些(重构误差开始下降);反之,如果decoder训练得还不错时(重构误差小于KL loss),这时候噪声就会增加(KL loss减少),使得拟合更加困难了(重构误差又开始增加),这时候decoder就要想办法提高它的生成能力了。
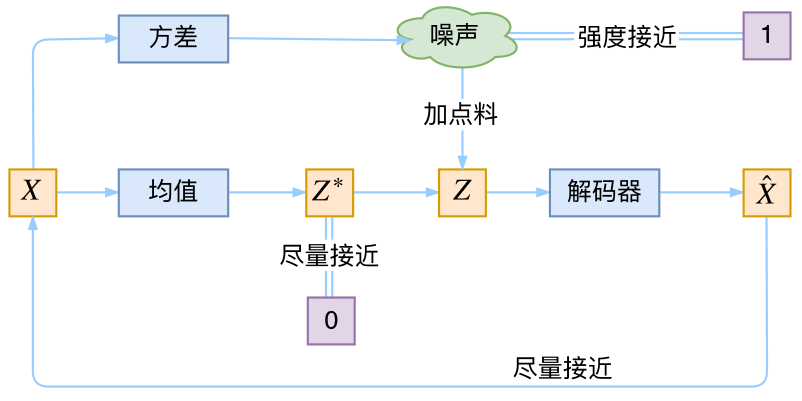
简言之,重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的。所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
VAE Inference
对于训练好的VAE模型,我们只需要从\(\mathcal{N}(0,I)\)中采样z,然后输入decoder即可。
必须注意这和训练阶段的Reparameterization Trick的异同:
1.Reparameterization Trick的目的是将\(\mathcal{N}(0,I)\)映射为\(\mathcal{N}(\mu,\sigma^2)\)。
2.由于KL loss的目的是让均值为0,方差为1,因此对于训练好的模型来说,Z就是\(\mathcal{N}(0,I)\)分布的了。
正态分布?
对于\(p(Z\mid X)\)的分布,是不是必须选择正态分布?可以选择均匀分布吗?
正态分布有两组独立的参数:均值和方差,而均匀分布只有一组。前面我们说,在VAE中,重构跟噪声是相互对抗的,重构误差跟噪声强度是两个相互对抗的指标,而在改变噪声强度时原则上需要有保持均值不变的能力,不然我们很难确定重构误差增大了,究竟是均值变化了(encoder的锅)还是方差变大了(噪声的锅)。而均匀分布不能做到保持均值不变的情况下改变方差,所以正态分布应该更加合理。
条件VAE
最后,因为目前的VAE是无监督训练的,因此很自然想到:如果有标签数据,那么能不能把标签信息加进去辅助生成样本呢?这个问题的意图,往往是希望能够实现控制某个变量来实现生成某一类图像。当然,这是肯定可以的,我们把这种情况叫做Conditional VAE,或者叫CVAE。正如在GAN中我们有个CGAN。
但是,CVAE不是一个特定的模型,而是一类模型,总之就是把标签信息融入到VAE中的方式有很多,目的也不一样。这里基于前面的讨论,给出一种非常简单的CVAE。
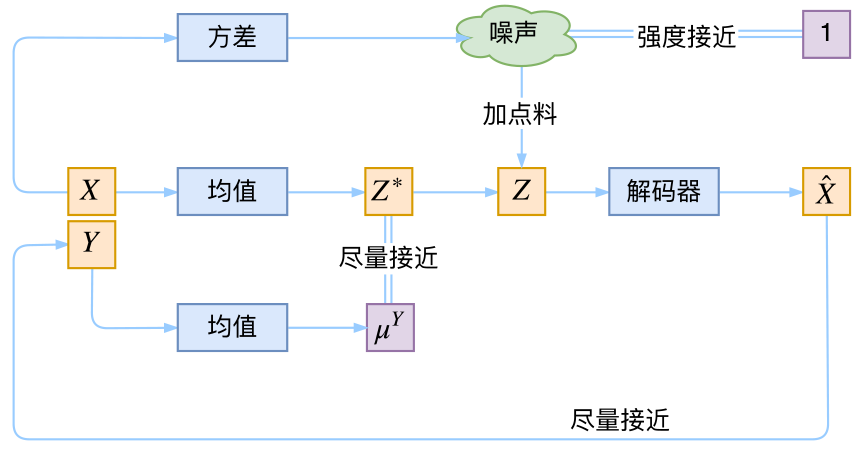
在前面的讨论中,我们希望X经过编码后,Z的分布都具有零均值和单位方差,这个“希望”是通过加入了KL loss来实现的。如果现在多了类别信息Y,我们可以希望同一个类的样本都有一个专属的均值\(\mu^Y\)(方差不变,还是单位方差),这个\(\mu^Y\)让模型自己训练出来。这样的话,有多少个类就有多少个正态分布,而在生成的时候,我们就可以通过控制均值来控制生成图像的类别。事实上,这样可能也是在VAE的基础上加入最少的代码来实现CVAE的方案了,因为这个“新希望”也只需通过修改KL loss实现:
\[\mathcal{L}_{\mu,\sigma^2}=\frac{1}{2} \sum_{i=1}^d\Big[\big(\mu_{(i)}-\mu^Y_{(i)}\big)^2 + \sigma_{(i)}^2 - \log \sigma_{(i)}^2 - 1\Big]\]参考:
https://mp.weixin.qq.com/s/1EvILWkBHKu2RV_xBuU8VQ
条件变分自编码器(CVAE)
https://mp.weixin.qq.com/s/hi0cVv4danL8IXT2BGxXbw
条件变分自动编码器CVAE:基本原理简介和keras实现
VAE的另一个介绍
以下章节的内容主要摘自:
https://www.jeremyjordan.me/variational-autoencoders/
Variational autoencoders
该文中文版:
https://mp.weixin.qq.com/s/tRB85VF8XH9TTXZsiNVLhA
深入理解变分自编码器
自编码器是发现数据的一些隐状态(不完整,稀疏,去噪,收缩)表示的模型。 更具体地说,输入数据被转换成一个编码向量,其中每个维度表示从数据学到的属性。 最重要的是编码器为每个编码维度输出单个值, 解码器随后接收这些值并尝试重新创建原始输入。
变分自编码器(VAE)提供了描述隐空间观察的概率方式。 因此,我们不需要构建一个输出单个值来描述每个隐状态属性的编码器,而是要用编码器描述每个隐属性的概率分布。

您的打赏,是对我的鼓励
