Generative Model » AIGC(二)——SORA, Autoregressive Model
2024-05-29 :: 5966 WordsDiffusion Model(续)
https://diffusion.csail.mit.edu/2026/index.html
Introduction to Flow Matching and Diffusion Models
https://zhuanlan.zhihu.com/p/377603135
Diffusion Probabilistic Model
https://yang-song.github.io/blog/2021/score/
Generative Modeling by Estimating Gradients of the Data Distribution
https://www.zhihu.com/question/536012286
diffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN?
https://www.zhihu.com/question/558475081
AI绘画过去也一直有研究,为什么会在最近几个月突然爆发?
https://mp.weixin.qq.com/s/G50p0SDQLSghTnMAOK6BMA
Diffusion Model
https://zhuanlan.zhihu.com/p/549623622
Diffusion Models:生成扩散模型
https://www.zhihu.com/question/549222340
国内有没有类似于Disco Diffusion的AI绘画工具?
https://zhuanlan.zhihu.com/p/617905470
Stable Diffussion显存不够用的拯救者插件
https://www.zhihu.com/question/577079491
stable diffusion的技术原理是什么?
https://zhuanlan.zhihu.com/p/617134893
文生图模型之Stable Diffusion
https://www.zhihu.com/question/649097976
为什么vae效果不好,但vae+diffusion效果就好了?
https://blog.csdn.net/v_JULY_v/article/details/130361959
图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer
https://zhuanlan.zhihu.com/p/613337342
Stable Diffusion原理介绍与源码分析(一)
https://zhuanlan.zhihu.com/p/615310965
Stable Diffusion原理介绍与源码分析(二、DDPM、DDIM、PLMS)
https://www.zhihu.com/question/2002852610374391417
如何评价Kaiming He新作《Generative Modeling via Drifting》?
https://zhuanlan.zhihu.com/p/1918415337877143861
Diffusion推理加速方案整理
Diffusion Transformer(DiT)
DiT使用Transformer替换了U-Net架构,算是2023年度Diffusion Model的一大改进。
《Scalable Diffusion Models with Transformers》
https://blog.csdn.net/v_JULY_v/article/details/144797429
Diffusion Transformer(DiT)——将扩散过程中的U-Net换成ViT
Consistency Models
扩散模型广泛应用于DALLE、stable diffusion等文生图的模型中,但一直以来扩散模型的一个缺点就是采样速度较慢,通常需要100-1000的评估步骤才能抽取一个不错的样本。
23年5月,OpenAI的Yang Song等人提出了Consistency Models,相比扩散模型,其使用1个步骤就能获得不错的样本,整体效率至少提升100倍,同时也极大地降低了算力成本。
https://blog.csdn.net/v_JULY_v/article/details/136318383
文生图的最新进展:从一致性模型CMs、LCM、SDXL到Stable Diffusion3、SDXL-Lightning
SDXL
Stable Diffusion XL引入了一种名为对抗扩散蒸馏(Adversarial Diffusion Distillation,ADD)的技术。
GANs可以作为独立的单步模型进行文本到图像合成的训练,且采样速度不错。
Stable Diffusion XL = SD + GAN

Hyper-SD
采用Trajectory Segmented Consistency Distillation技术,达到One-step生成的目的。
在机器人领域的应用
Diffusion Model不仅可用于文生图,还可以用于机器人领域,实现文本到动作的转换。
https://blog.csdn.net/v_JULY_v/article/details/142854390
从MDM、RobotMDM到UCSD的Exbody——人体运动扩散模型:赋能机器人的训练
Diffusion Policy引入扩散模型(duffision model),输入一段观测序列,输出未来一段时间的行为序列,在机器人操作数据集上学习,即模仿学习或监督学习。
https://blog.csdn.net/v_JULY_v/article/details/143651718
Diffusion Policy——斯坦福机器人UMI所用的扩散策略:从原理到其编码实现(含Diff-Control、ControlNet详解)
text-to-image量化模型评估指标
评估量化模型生成图片的效果,主要看两个方面:
- Quality:指图像本身的内在质量,包括清晰度、对比度、色彩饱和度、细节丰富度等视觉属性。常用指标有FID、IR。
- Similarity:指生成图像与某个参考图像或预期结果之间的相似度。这可以是与原始图像的相似度,也可以是与用户提供的文本提示或指令的一致性。常用指标有LPIPS、PSNR。
Diffusion LLM
https://zhuanlan.zhihu.com/p/29270223916
扩散大语言模型介绍
https://www.zhihu.com/question/1908485413494034535
Google竟然也在搞Diffusion语言模型
https://zhuanlan.zhihu.com/p/24214732238
自回归是否是通往语言智能的唯一路径?——生成模型的一些思考
https://www.zhihu.com/question/2033568954673796072
为什么2026年大模型都在往“理解生成统一”方向发展?去掉VAE和VE到底能带来什么本质性的提升?
SORA
https://openai.com/research/video-generation-models-as-world-simulators
官方技术报告
MS解读SORA的论文:
《Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models》
SORA的使用方法:
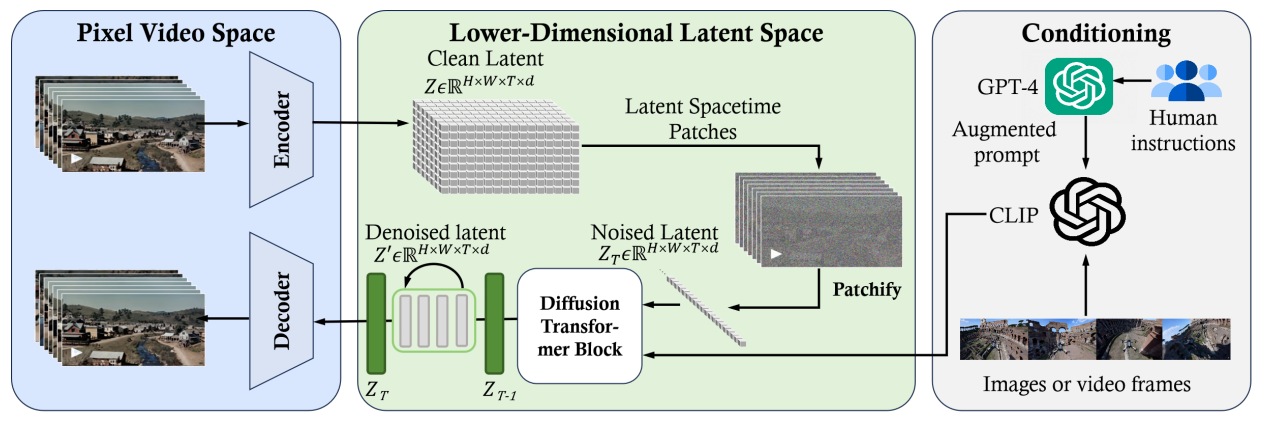
SORA的基本框架:
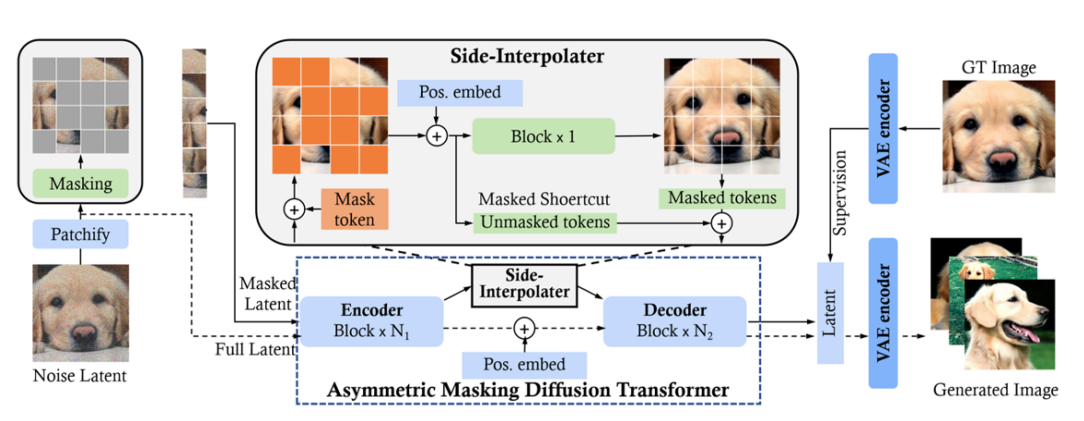
训练时可以采用Masked Diffusion Transformer (MDT)的方法增强学习效果。
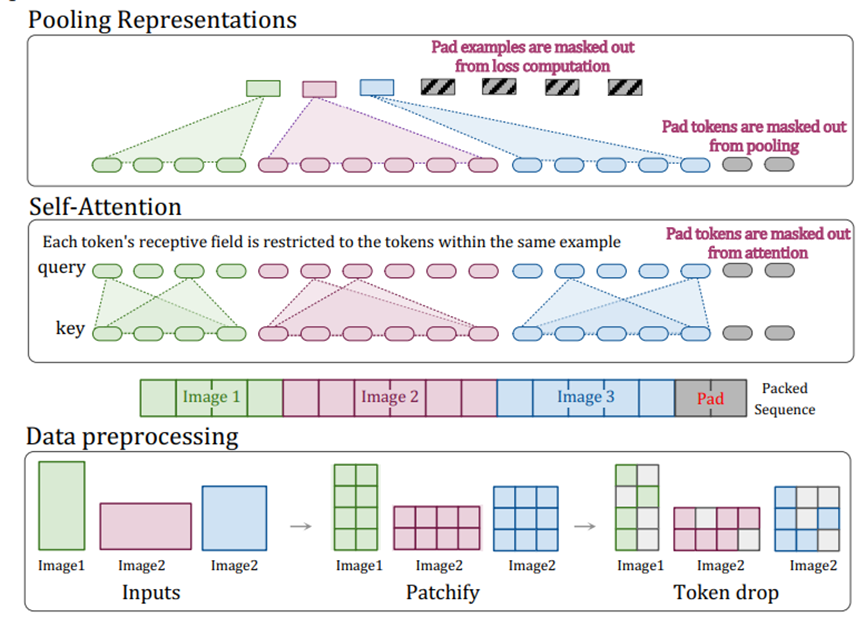
NaViT(Native Resolution ViT)没有采用传统的将图像调整至固定大小的做法,而通过特定的架构来实现对任意分辨率和宽高比图像的灵活处理。打包支持保持宽高比的可变分辨率图像,减少了训练时间,提高了性能,并增加了灵活性。
VDT:综合“ViViT的时空编码”与“DiT的扩散Transformer”
Open Sora是新加坡国立大学尤洋团队的作品。
官网:
https://hpcaitech.github.io/Open-Sora/
代码:
https://github.com/hpcaitech/Open-Sora

opensora说实话一言难尽,模型架构和最终效果都和sora没啥关系,硬蹭个sora的名号,不太优雅。
这大哥在新国立ap,然后自己学生不带甩给别人,自己课不教,每天北京天天跑投资人,两张脸变得极快,反正nus的朋友对他一大堆意见。
Deepseek官方给出了很多部署优化方向,尤洋这哥们没动手优化。Deepseek的人都看不下去了,去小红书跟尤洋对线。
如果deep seek把这些秘密都公开了,那他做infra相对于其他的公司就没有任何优势了,而且deep seek的优化效率更高,更彰显了他的无能。
他为啥那么避讳农大 ,挺好的985。他就那么不待见自己的母校?中国农大->清华->伯克利->新国立
专门做infra的公司被做算法的公司顺手做的infra给碾了,当然不敢相信。
https://www.zhihu.com/question/13087686159
伯克利尤洋计算后认为卖DeepSeek API (MaaS)月亏损4亿,计算是否正确?离低成本有多远?
AI视频最常见“人物变脸、产品变形、角色越跑越偏”的问题。Seedance之类的AI模型允许你上传多张多角度素材(正面/侧面/背面),告诉AI:这个东西就是参考对象,必须从头到尾保持外形、颜色、五官、细节完全不变;场景、动作、镜头可以随便换,但参考对象本身不能走样;
参考:
https://zhuanlan.zhihu.com/p/683231546
Sora大模型技术精要——原理、关键技术、模型架构与未来趋势
https://fisherdaddy.com/posts/sora-reading-list/
“Road to Sora” 论文阅读清单
https://blog.csdn.net/v_JULY_v/article/details/136143475
视频生成Sora的全面解析:从AI绘画、ViT到ViViT、TECO、DiT、VDT、NaViT等
https://blog.csdn.net/v_JULY_v/article/details/134655535
Sora之前的视频生成发展史:从Gen2、Emu Video到PixelDance、SVD、Pika 1.0
https://blog.csdn.net/v_JULY_v/article/details/136845242
视频生成Sora的从零复现:从Latte、Open-Sora(含1.0及其升级版)到StreamingT2V
https://zhouyifan.net/2024/06/05/20240405-SVD/
Stable Video Diffusion结构浅析与论文速览
https://mp.weixin.qq.com/s/FYIC3F5po7_v0VP89pEORQ
追本溯源:OpenAI Sora技术报告解读
Autoregressive Model
AR vs AE的相关内容在《Large Language Model(二)》中已有描述,这里不再赘述。
Autoregressive Model实际上是最古老的生成模型,比GAN/VAE/Flow/Diffusion都要古老。
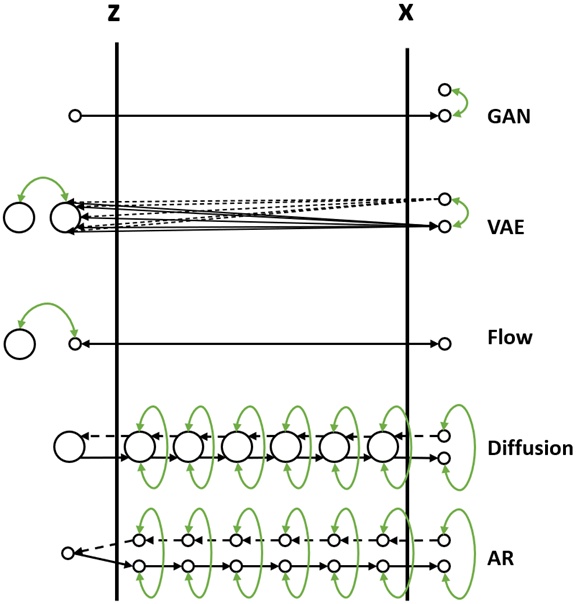
这里以PixelCNN为例介绍一下AR Model的原理。
![]()
PixelCNN简单来说就是按照从左到右,从上到下的顺序依次生成图片。表面上和Diffusion Model差不多,也是若干step的生成过程。
但是有个问题就是中间步骤不能省略。比如一张28x28的图片,如果一次出1个点的话,一共就要28x28个step。少了其中的某一步,图片就不完整了。而且显然一次出1个点的模型一定和一次出2个点的模型是不一样的。
但Diffusion Model就无所谓了,少了某一步,无非少了一种Noise Predictor而已,不会对结果有什么根本性的影响。
PixelCNN训练和过程和Autoencoder差不多,也是最终生成的图片和训练图片做比较。但是为了表示没有偷看后面的数据,训练时需要用MASK遮住还未生成的那部分。
此外,PixelCNN还要给图片打分,用以表明生成的图片是那一类的。比如MNIST数据集的手写数字的10分类。
这样最终训练好之后,只要给出分类信息和seed,就可以生成图片了。
参考:
https://zhuanlan.zhihu.com/p/591881660
通俗形象地分析比较生成模型(GAN/VAE/Flow/Diffusion/AR)
https://mp.weixin.qq.com/s/YZcw5pnHzuACSvEmGZHnEQ
自回归模型:PixelCNN
https://www.microsoft.com/en-us/research/uploads/prod/2022/12/Generative-Models-for-TTS.pdf
Generative Models for TTS
VAR

Visual Auto Regressive认为传统AR模型自上而下、逐行扫描的光栅顺序(或称raster-scan顺序)是不符合认知的。
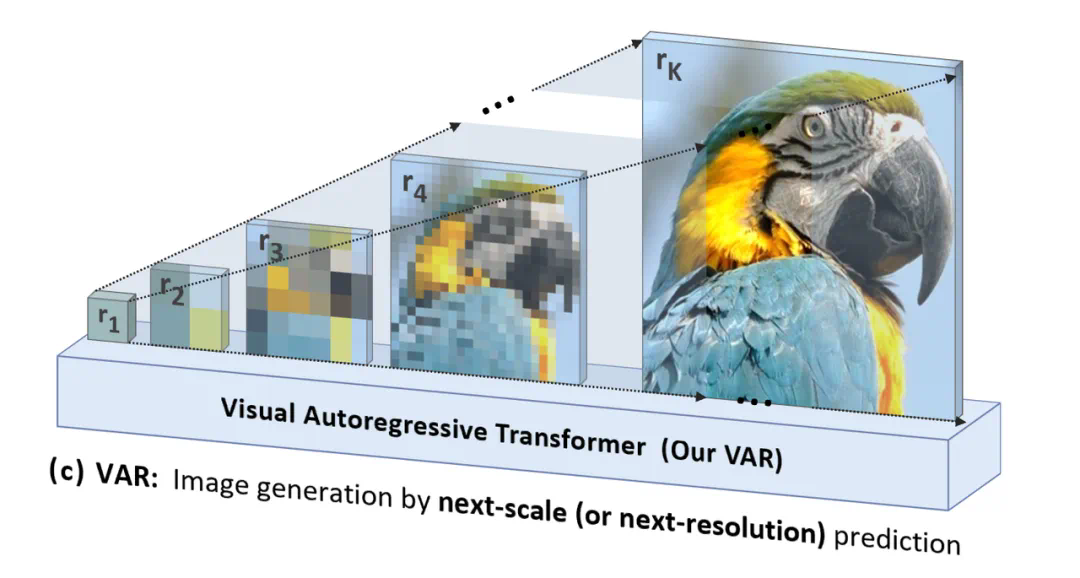
而上图的从整体到细节的多尺度顺序逐渐生成,才更符合逻辑。
VAR的另一个显著优势是大幅提高了生成速度:在自回归的每一步(每一个尺度内部),所有图像token是一次性并行生成的;跨尺度则是自回归的。这使得在模型参数和图片尺寸相当的情况下,VAR能比传统AR快数十倍。
VAR也是首个效果和性能达到Diffusion模型水平的AR模型。

您的打赏,是对我的鼓励
