Generative Model » AIGC(一)——概述, CLIP, Cross Attention, Diffusion Model
2023-01-17 :: 5191 Words概述
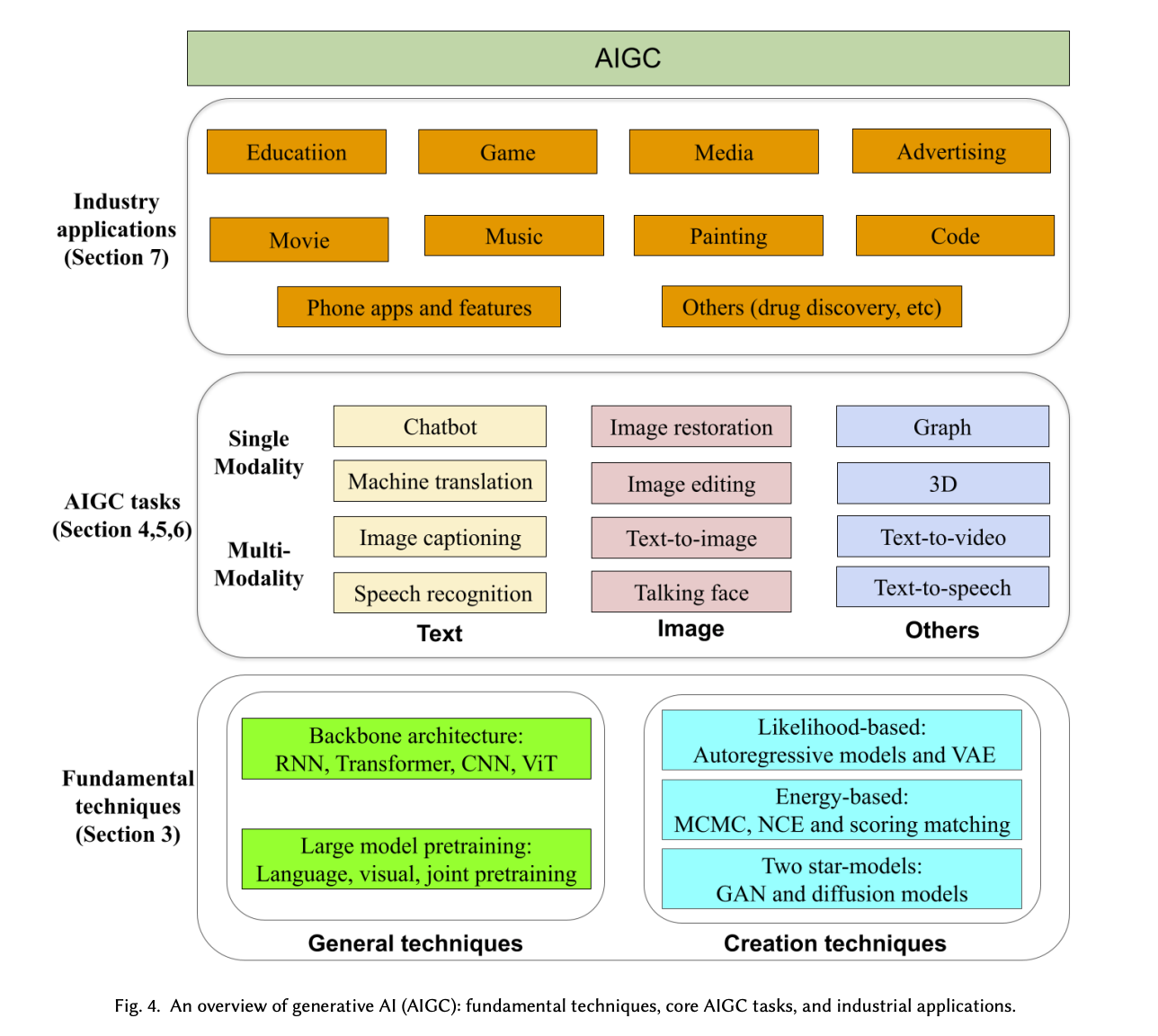
《A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT》
《ChatGPT is not all you need. A State of the Art Review of large Generative AI models》
ChatGPT(文本到文本的对话模型)
DALL-E-2(文本到图像的生成模型)
Codex(文本到代码的生成模型)
Dreamfusion (文本到3D图像)
Flamingo(图像到文本)
Phenaki(文本到视频)
AudioLM(文本到音频)
Galactica(文本到科学文本)
AlphaTensor(自动搜索高性能的矩阵运算逻辑)
https://civitai.com/
一个AI艺术的网站
https://space.bilibili.com/12566101
一个AI绘图方面的博主(秋葉aaaki)
https://microsoft.github.io/generative-ai-for-beginners
Generative AI for Beginners
在C站,一个南京艺术学院毕业的学美术小姐姐,网名叫娜乌斯嘉,她用自己的照片训练了lora,并分享给全网AI绘画爱好者们使用。
她的B站主页:
https://space.bilibili.com/8095370
CLIP
CLIP由OpenAI在2021年1月发布。
CLIP模型在不使用ImageNet数据集的任何一张图片(zero-shot)进行训练的的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手(在ImageNet上zero-shot精度为76.2%,这在之前一度被认为是不可能的)。
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text,WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一,后续在WIT上还孕育出了DALL-E模型)
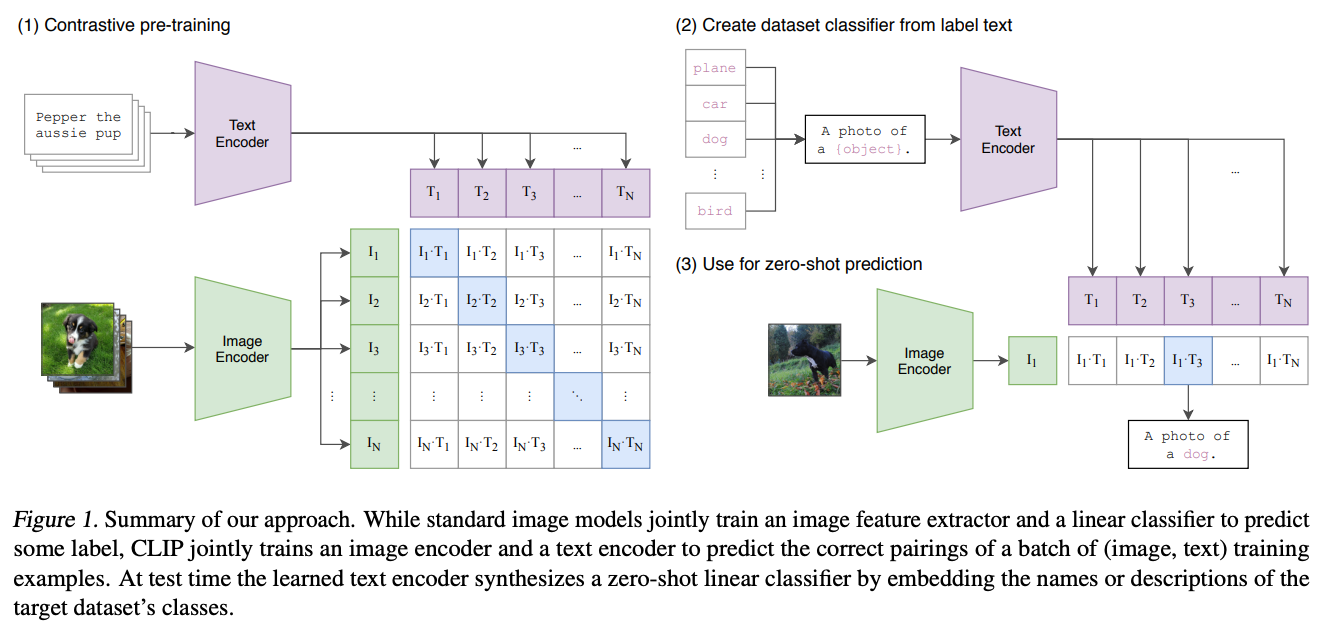
Text Encoder可以采用NLP中常用的text transformer模型。而Image Encoder可以采用常用CNN模型或者vision transformer等模型,相似度是计算文本特征和图像特征的余弦相似性cosine similarity。
CLIP建立了“文字潜在空间”到“图片潜在空间”的对应关系。上面提到的在ImageNet上的测试,属于“图生文”,配合Diffusion Model即可“文生图”。这类模型也被称为VLP(Vision-Language Pre-training)模型。
https://zhuanlan.zhihu.com/p/493489688
神器CLIP:连接文本和图像,打造可迁移的视觉模型
https://zhuanlan.zhihu.com/p/589170132
FLIP:通过图像掩码加速CLIP训练
https://www.zhihu.com/question/593888697
如何评价Meta/FAIR 最新工作Segment Anything?
https://zhuanlan.zhihu.com/p/620271321
最强Zero-Shot视觉应用:Grounding DINO + Segment Anything + Stable Diffusion
https://www.zhihu.com/question/593914819
Meta发布图像分割论文Segment Anything,将给CV研究带来什么影响?
https://blog.csdn.net/v_JULY_v/article/details/131205615
AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion
https://blog.csdn.net/m0_60177079/article/details/149296630
CLIP、Open CLIP、SigLip、SigLip2的相关总结
CLIPTextModel的基类是BaseModelOutputWithPooling,它有两个输出;
- last_hidden_state:模型最后一层输出的完整隐藏状态,通常是一个三维张量,形状为
[batch_size, sequence_length, hidden_size]。 - pooler_output:对最后一层的隐藏状态进行某种形式的池化操作得到的。形状为
[batch_size, hidden_size]。
BLIP
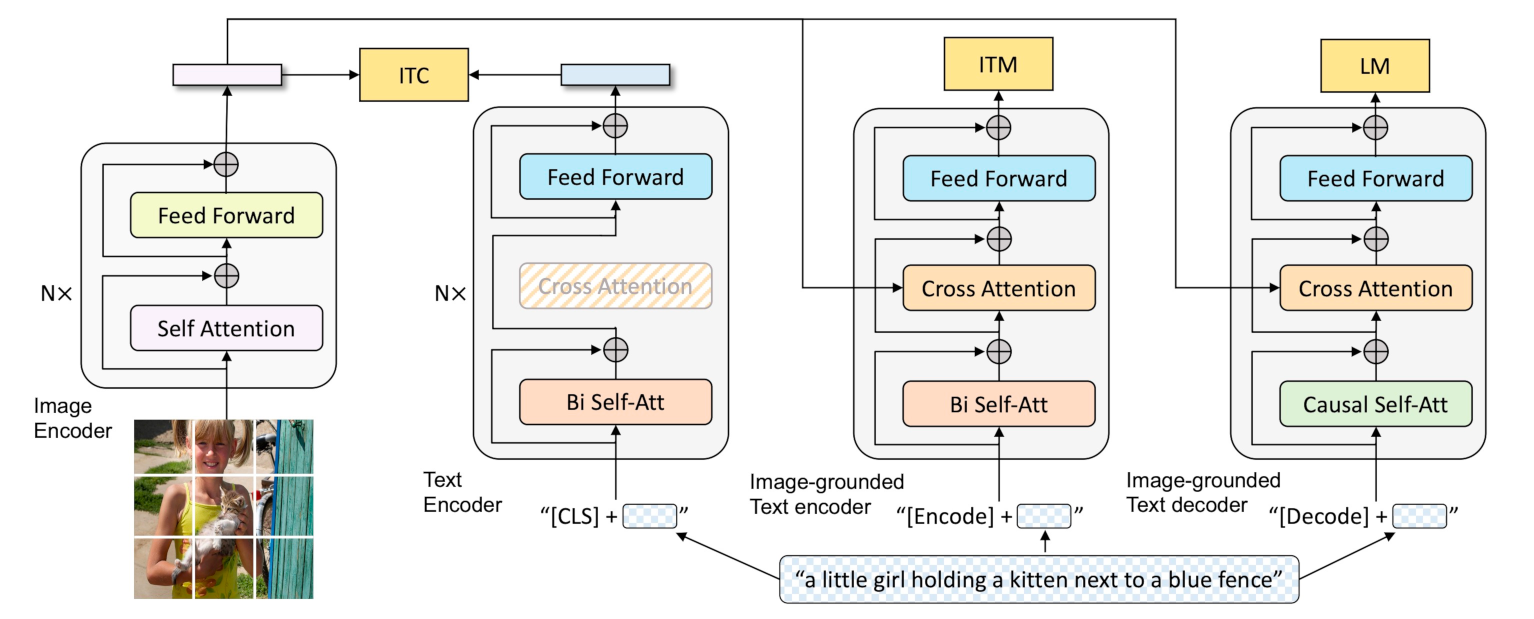
Image-Text Contrastive Loss目标是对齐视觉和文本的特征空间。
Image-Text Matching Loss调整视觉和语言之间的细粒度对齐。
Language Modeling Loss使模型能够将视觉信息转换为连贯的字幕。
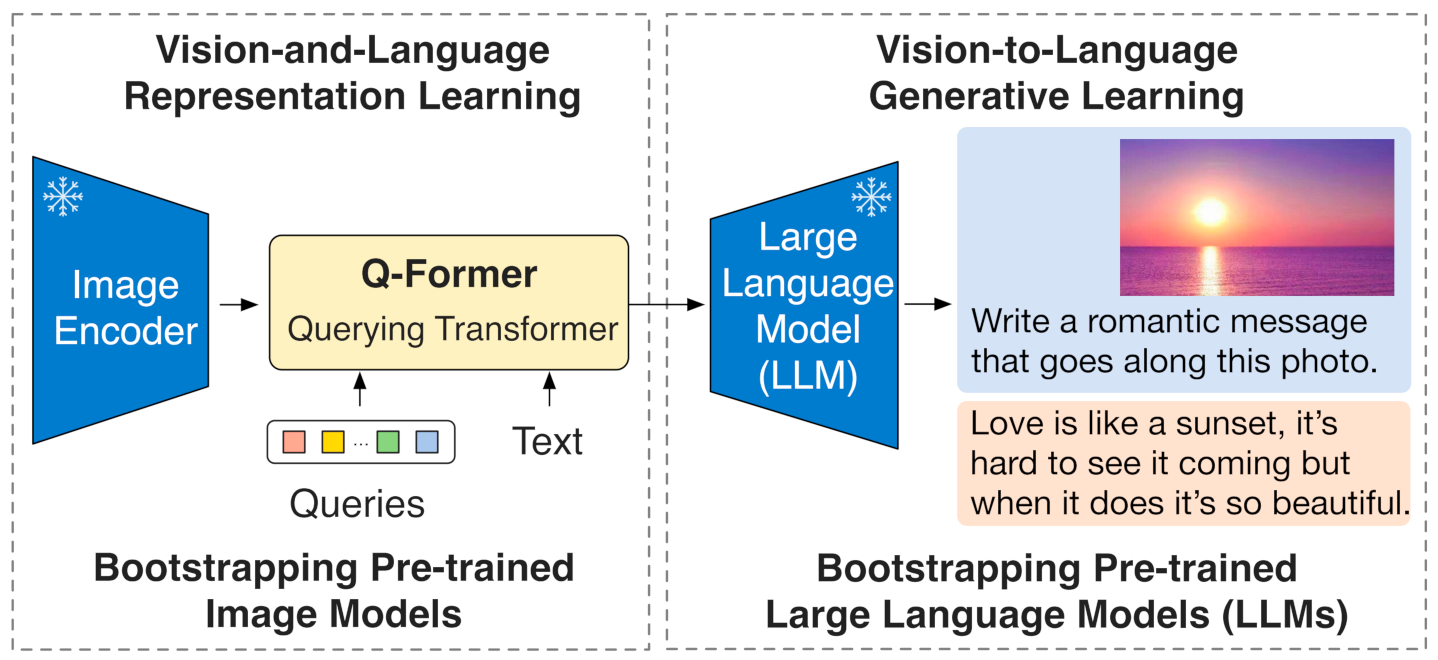
BLIP-2的视觉侧和文本侧分别使用预训练的CLIP ViT-G/14模型和FLAN-T5模型,仅中间的起桥接作用的Q-Former参与训练,训练需要的成本和数据量进一步降低,BLIP-2的训练数据量仅129M,16卡A100训练9天。
此后这类桥接预训练的大模型(无论是CV还是NLP)的工作逐渐成为了主流,从头开始训练的,渐趋式微。
DALLE 2

DALLE由于是前CLIP时代的东西,已经有些过时了。这里直接介绍DALLE 2。
prior的训练:根据文本特征(即CLIP text encoder编码后得到的文本特征),预测图像特征(CLIP image encoder编码后得到的图片特征)
decoder生成图:常规的扩散模型解码器,解码生成图像。这里的decoder就是升级版的GLIDE(GLIDE基于扩散模型)。
DALLE 3
对于稍微复杂的文本,目前的文生图模型生成的图像往往会容易忽略部分文本描述,甚至无法生成文本所描述的图像。这个问题主要还是由于训练数据集本身所造成的,更具体的是说是图像caption不够准确。
图像常规的文本描述往往过于简单(比如COCO数据集),它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等。
DALLE 3 = 原始caption和合成长caption混合训练 + T5 + latent decoder
Cross Attention
Cross Attention是另一种常见的多模态信息融合的手段。

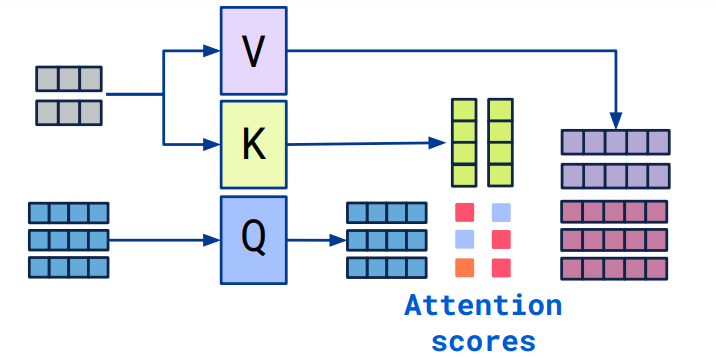
- 拥有两个序列S1、S2。
- 计算S1的K(\([B,M,d_k]\))、V(\([B,M,d_v]\))。
- 计算S2的Q(\([B,N,d_k]\))。
- 根据K和Q,计算注意力矩阵。
- 将V应用于注意力矩阵。
- 输出的序列长度与S2一致(\([B,N,d_v]\))。
https://vaclavkosar.com/ml/cross-attention-in-transformer-architecture
Cross-Attention in Transformer Architecture
Diffusion Model
Diffusion Model也是一类生成模型方法。
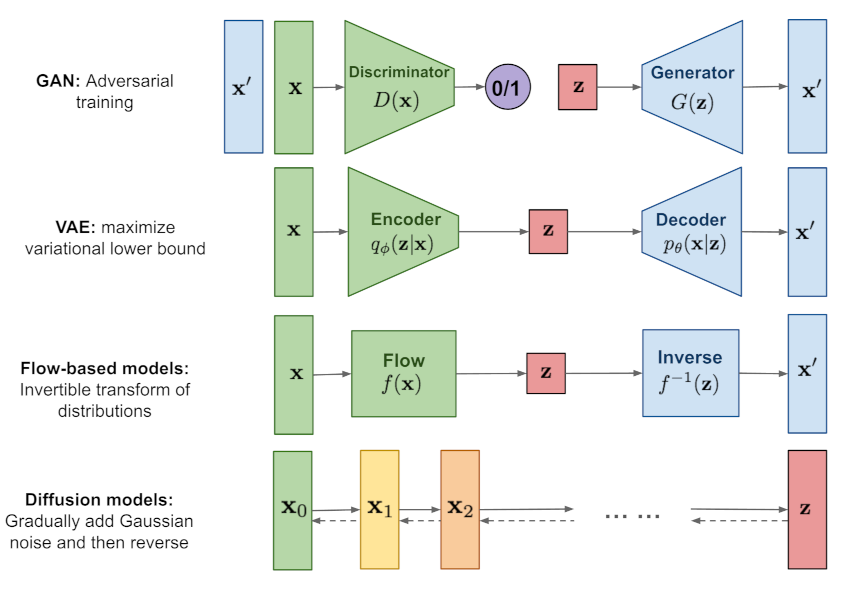
Diffusion Model主要通过采样的方法,不断逼近模型的数据分布,从而生成数据。基本原理和VAE一样仍然是Markov Chain Monte Carlo。
以下以Stable Diffusion模型为例,介绍一下Diffusion Model的套路。

我们首先来看一下Stable Diffusion的流水线:
1.输入是一段文字,或者是一段文字+一张背景图片,输出是一张生成的图片。
2.Text Encoder用于NLP。
3.Image Decoder用于生成图片。
4.上述这些部分都是很常规的,中间的Image Information Creator才是Stable Diffusion的关键。
![]()
如上图所示,Image Information Creator的输入是一个随机的噪声,而输出是一个information tensor。无论是噪声,还是information tensor都属于Information World,而最后生成的图片属于Visual World。
早期的原始Diffusion Model并没有这种World的划分,而是直接由噪声得到图片,所以很不Stable。
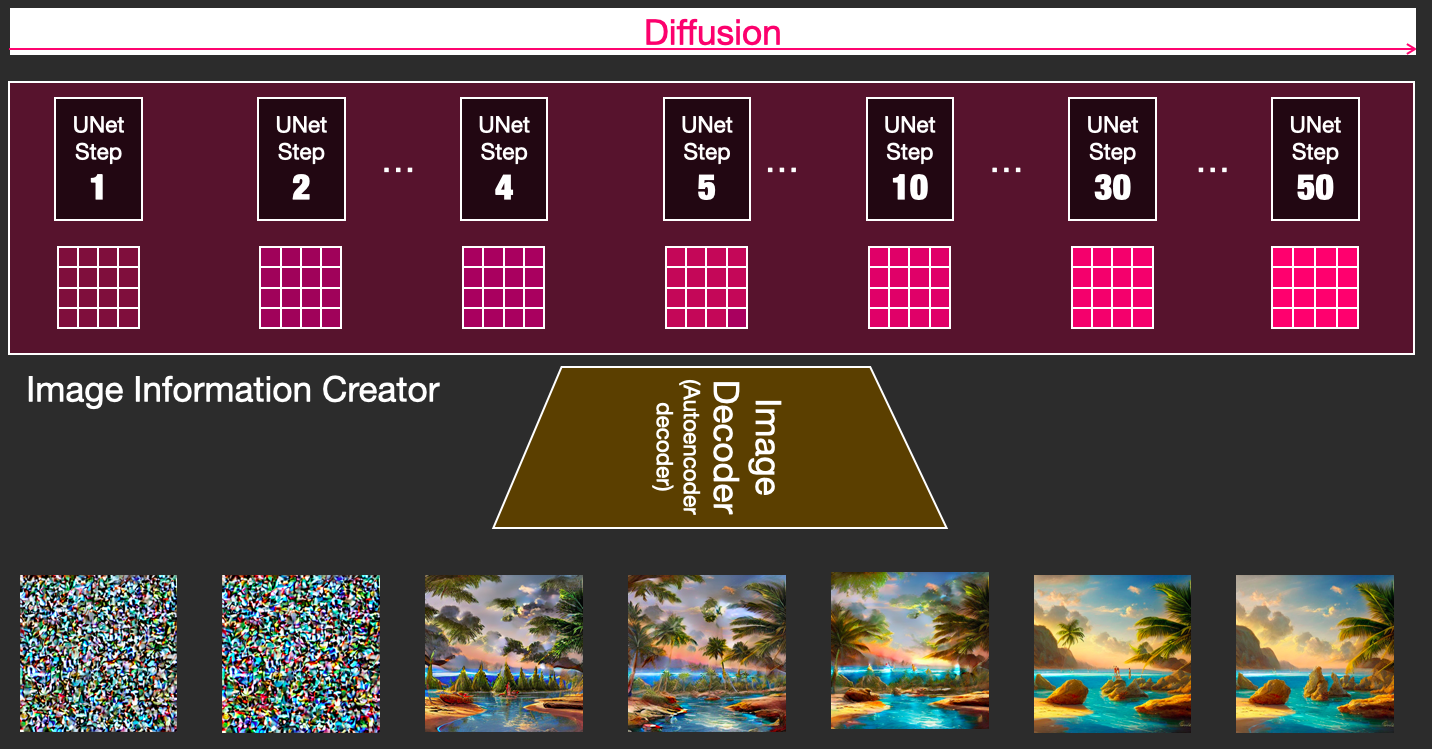
从上图可以看出:Diffusion Model由于天生就是渐变的迭代过程,因此在流程的可控性上很有优势。
当时间宽裕时可以通过高轮次的迭代获得高质量的合成样本,同时较低轮次的快速合成也可以得到没有明显瑕疵的合成样本。(仍以上图为例,实际上Step 4的图片就已经相当OK了。)而高低轮次迭代之间完全不需要重新训练模型,只用手动调整一些轮次相关的参数。
因此,很自然的又有了Cascaded Diffusion Models。
论文:
《Cascaded Diffusion Models for High Fidelity Image Generation》
回到Stable Diffusion本身,我们先看一下没有两种World划分的Diffusion Model是怎么训练的。

首先我们生成一堆的随机噪声,然后随机选择其中一种噪声,添加到图片上。这样就得到了一组数据集:
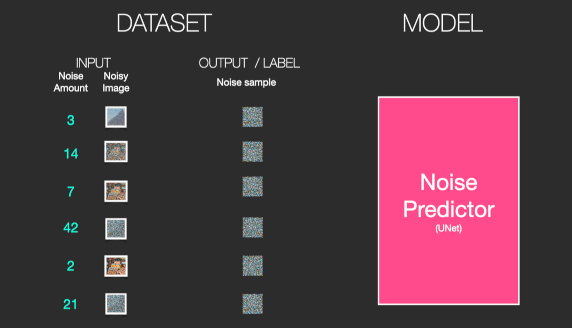
我们的目标就是训练一个噪声预测模型。
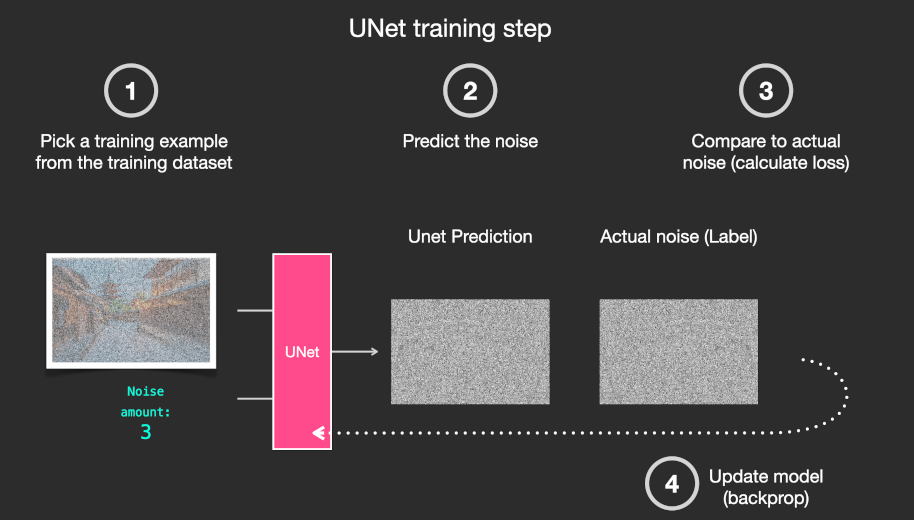
用预测的噪声和原始生成的噪声做对比,计算loss。
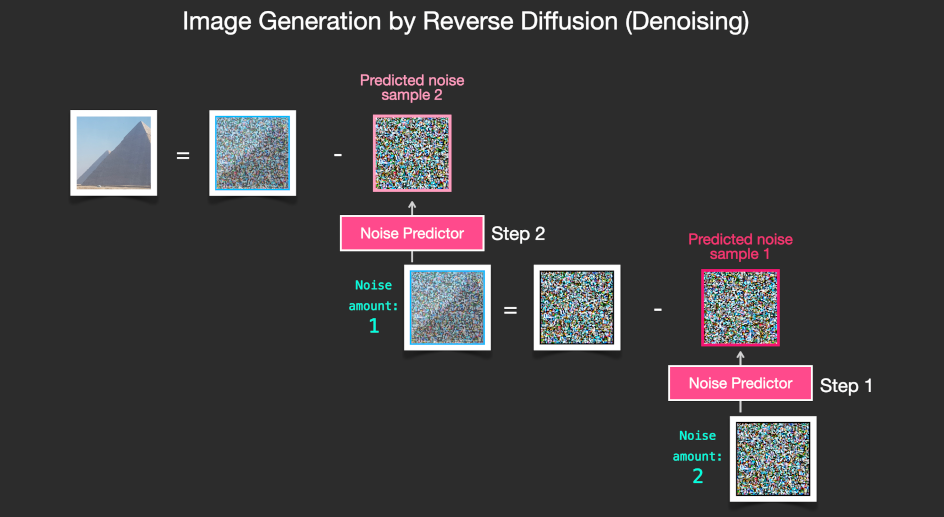
推理的时候,首先生成一组噪声图片,放入Noise Predictor,生成预测的噪声。然后用噪声图片-预测的噪声就得到了生成的图片。这个去噪过程,也可以进行多个Step。显然Step越多,图片质量越高。
多个Step其实也是一种变相的加深网络方法。

这种把预测图片改进为预测噪声的思路,一般被称为DDPM(Denoising Diffusion Probabilistic Model)。
使用两种World划分的Stable Diffusion,还要再复杂一些,但也不多了。
Image Decoder部分使用传统的AutoEncoder进行训练。
这样Diffusion过程就可以在Information World中进行了。
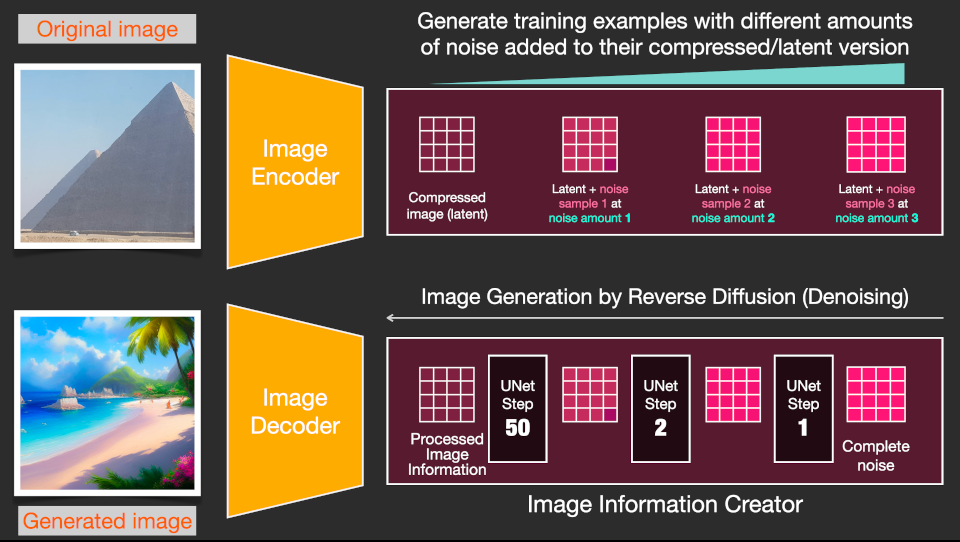
Stable Diffusion的完整架构图如下:
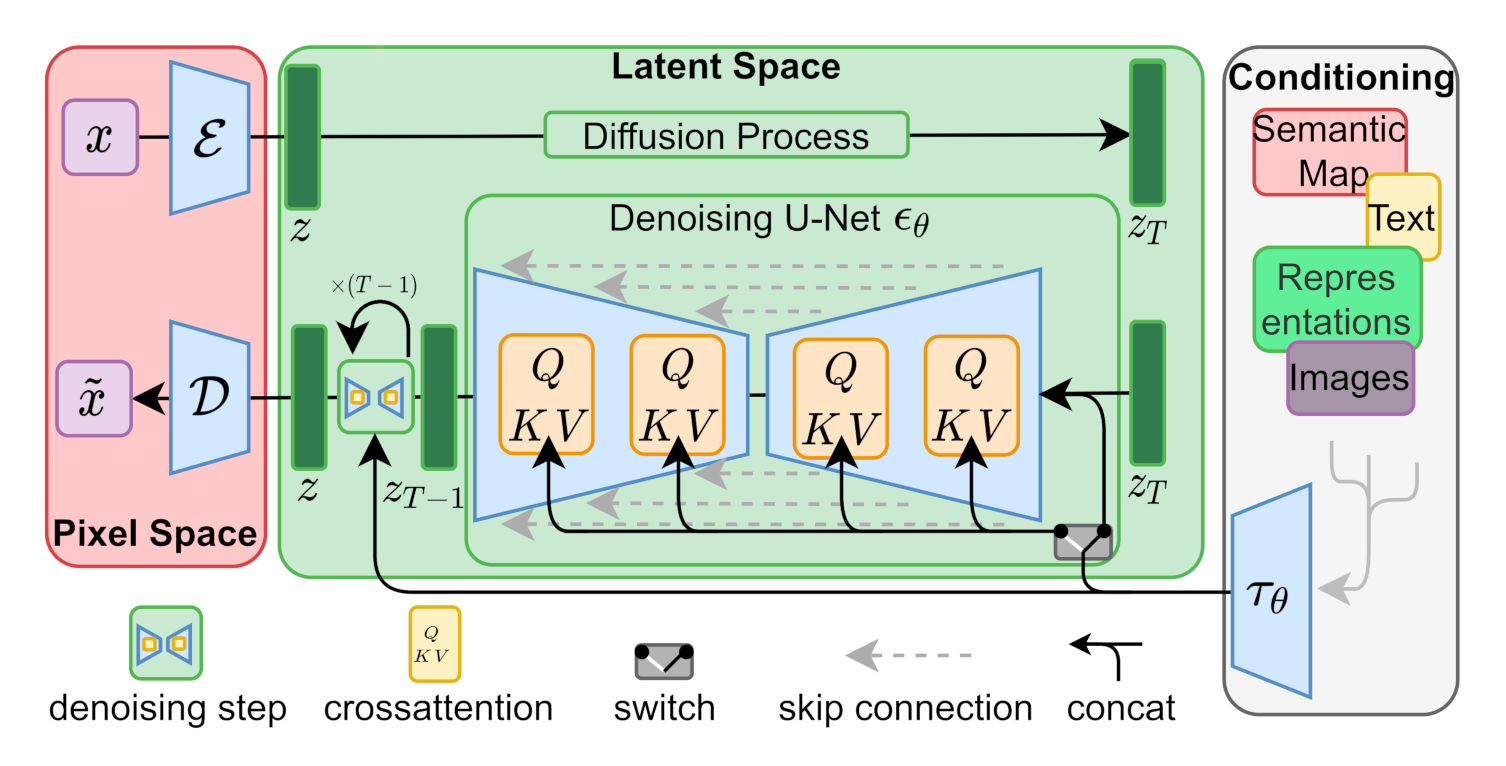
常见的应用包括:TEXT2IMAGE、IMAGE2IMAGE、INPAINT。
Stable Diffusion的推理过程:

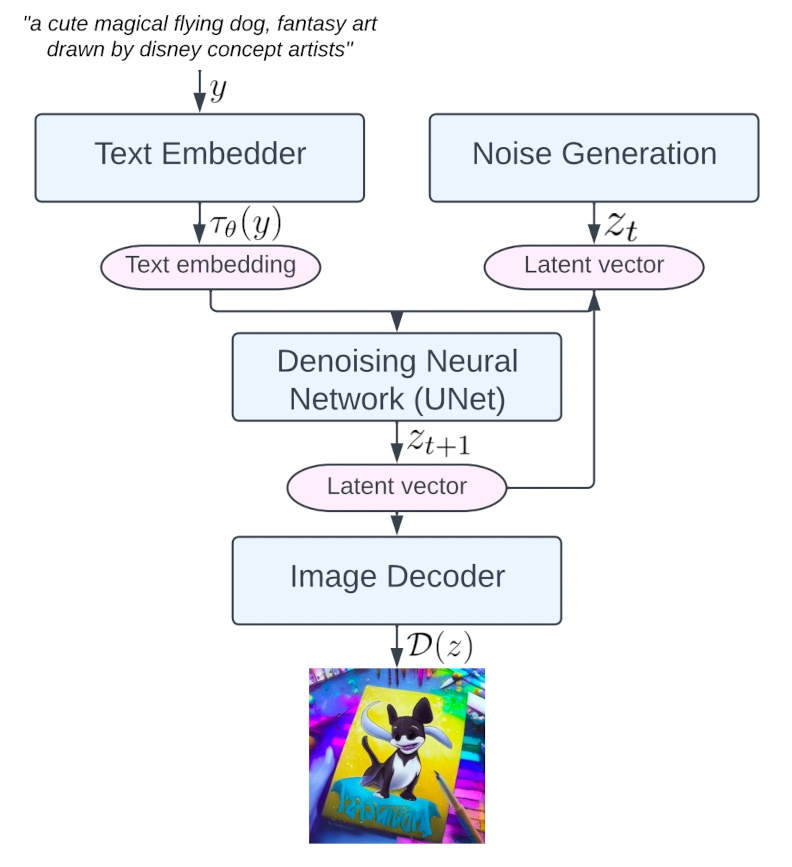

上图中的CLIP和AutoencoderKL均已在大数据集上进行了预训练。
CLIPEmbedder文本编码器对Prompt提示词进行编码,生成大小为[B, K, E]的embedding表示(即context),其中K表示文本最大编码长度max length, E表示embedding的大小。

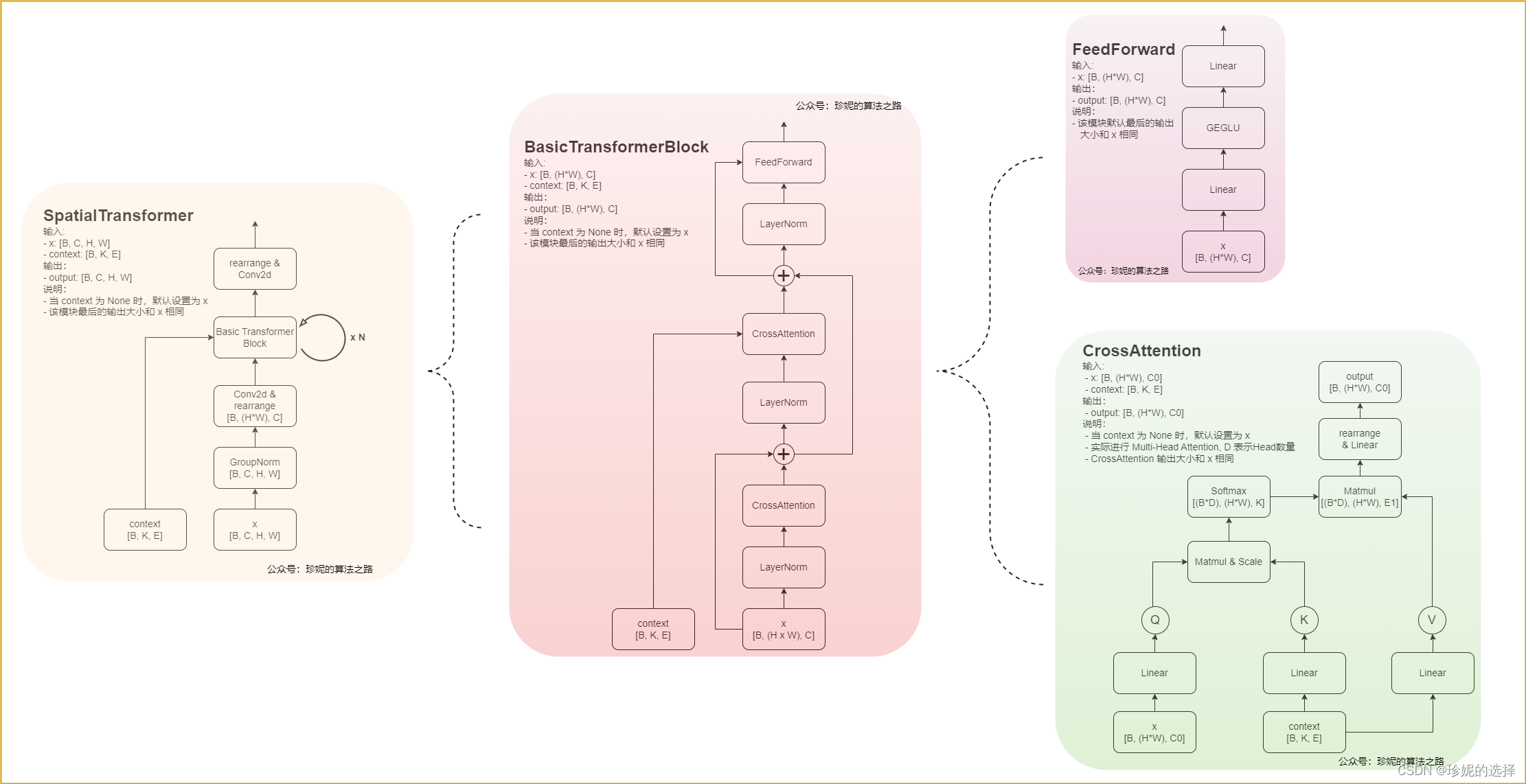
由于Cross Attention的output的序列长度和Q一致,所以变长的Prompt只能作为KV存在。

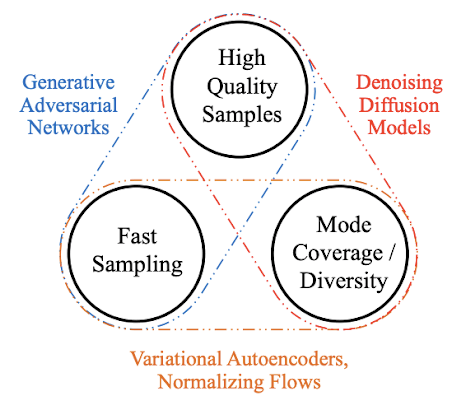
不同类型的文生图模型的考虑因素/优缺点
参考:
https://jalammar.github.io/illustrated-stable-diffusion/
The Illustrated Stable Diffusion
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
What are Diffusion Models?
https://zhuanlan.zhihu.com/p/366004028
另辟蹊径—Denoising Diffusion Probabilistic一种从噪音中剥离出图像/音频的模型
https://zhuanlan.zhihu.com/p/384144179
Denoising Diffusion Probabilistic Model(DDPM)
https://speech.ee.ntu.edu.tw/~hylee/ml/ml2023-course-data/DDPM%20(v7)
李宏毅:DDPM讲解
https://zhuanlan.zhihu.com/p/637815071
DDPM(模型架构篇)
https://zhuanlan.zhihu.com/p/650394311
DDPM(数学原理篇)

您的打赏,是对我的鼓励
