DRL » 深度强化学习(七)——AlphaGo(3)
2019-10-22 :: 6634 WordsAlphaGo
MuZero(续)
https://mp.weixin.qq.com/s/IcaxjdDLjihCK-nKBlJVWg
从α到μ:DeepMind棋盘游戏AI进化史
https://mp.weixin.qq.com/s/BWWCqAoSRkNAWXMiTOFhAA
DeepMind推出Agent57,在所有雅达利游戏上超越人类玩家
https://mp.weixin.qq.com/s/CvkIFuLTBDW0L8A9rJL7Ng
新算法MuZero登顶Nature,AI离人类规划又近了一步
https://mp.weixin.qq.com/s/dTJ7NvVs7qjF2FRoAZ_WlQ
MuZero算法过程详解
GnuGo
GnuGo是一个DRL时代之前的老牌开源围棋软件,但是它只有文字界面。一般使用Quarry作为它的GUI。
sudo apt install quarry
Leela Zero
Leela Zero是比利时人Gian-Carlo Pascutto开源的围棋AI。它的算法与AlphaGo Zero相同。而训练采用GTP协议,集合全球算力,进行分布式训练。
官网:
http://zero.sjeng.org/
代码:
https://github.com/gcp/leela-zero
GTP
Go Text Protocol,其目的是建立一个比GMP(Go Modem Protocol)协议的ascii接口更合适于双机通信、更简单、更有效、更灵活的接口。
GTP将围棋软件分成了前后端,前端软件提供GUI,而后端软件负责对弈。
官网:
http://www.lysator.liu.se/~gunnar/gtp/
参考:
https://www.tianqiweiqi.com/go-gtp.html
围棋引擎的GTP协议
minigo
Google员工Andrew Jackson作品。但tf官方一再强调这并非TensorFlow项目的一环,也不是DeepMind的AlphaGo官方版本,而是由独立的团队依照AlphaGo Zero的论文而实做出的版本。
官网:
https://github.com/tensorflow/minigo
参考:
https://zhuanlan.zhihu.com/p/352536850
AlphaGo Zero中的强化学习算法和google开源工程实现——从原理到代码实现
ELF OpenGo
ELF OpenGo是Facebook开源的围棋AI,它是FB的AI游戏框架ELF的一部分。
官网:
https://github.com/pytorch/ELF
参考:
https://mp.weixin.qq.com/s/lOAx3suLIS-pEWyi8xZl6Q
“全民体验”AlphaZero:FAIR田渊栋首次开源超级围棋AI
PhoenixGo
PhoenixGo是腾讯微信团队的AlphaGo Zero复刻版。
官网:
https://github.com/Tencent/PhoenixGo
参考:
https://mp.weixin.qq.com/s/tJDmxsuS1QigYS75ZIdzRA
微信团队开源围棋AI技术PhoenixGo,复现AlphaGo Zero论文
KataGo
KataGo是2019年以后发起的一个新项目,主要解决了Leela Zero和ELF OpenGo耗费算力过多的问题。它不仅训练更快,推理也有极大改进,即使家用显卡PC也可在合理的时间算出结果。支持更多的规则(如日本规则、自由调整贴目、还棋头等),改善了AlphaGo胜势下缓手的缺陷。
目前,KataGo的棋力已经超越了Leela Zero和ELF OpenGo。
官网:
https://katagotraining.org/
Lizzie
Lizzie诞生于2018年初,是程序员Annie Wagner设计的一款可加载围棋AI的图形界面程序,最初是为了实现Leela Zero的棋局实时分析功能。此后增加了对KataGo及一些其他开源围棋AI引擎的支持,可以使各种围棋AI运行在图形化界面下,方便使用者进行棋局分析。
目前最常用的是如下的Lizzie修改版:
https://github.com/yzyray/lizzieyzy
象棋软件
Stockfish是一款开源国际象棋程序。由于最初的开发者中的两位分别来自挪威和意大利,为了纪念两国历史悠久的鳕鱼贸易,开发者将他们的程序命名为了Stockfish。
Stockfish将传统计算机国际象棋技术发挥到了极致,包括但不限于alpha-beta搜索,各种剪枝技术,以及手动调整参数的估值函数等等。至少在2017年之前,Stockfish几乎稳坐各大计算机国象程序棋力排名榜第一名。
国际象棋领域,有一个Leela Chess Zero(lc0)项目:
https://lczero.org/
和Leela Zero一样,同样是AlphaGo Zero的开源复刻。
NNUE的全名是Efficiently Updatable Neural Network,最初由日本将棋程序员那須悠于2018年提出,并应用于将棋程序中。把EUNN換成NNUE是因為NUE(ぬえ)是一种日本传统中的妖怪──鵺。
使用NNUE算法的Stockfish,最终反超lc0,重新夺回王者之位。
NNUE使用的是传统的ab剪枝,而不是MCTS。ab剪枝搜索的速度比MCTS更快,但不适合GPU加速,因此NNUE的推理一般使用CPU。
中国象棋有克隆lc0的px0、ggz:
http://px0.org/
和克隆Stockfish的pikafish(皮卡鱼):
https://www.pikafish.com/
AI作弊/对抗
十多年前,当我还是一个中二青年的时候,就幻想有朝一日能够拿围棋世界冠军。当然,就算再中二,我自己也明白靠实力那是不可能的,当时做梦的法宝是制造一个AI,然后碾压一下所谓的国手。
按照当时(2000年前后)人们的预计,这个AI在2030年之前,都不可能造出来,然而,最终的结果实际上只花了一半左右的时间。
再之后,随着AI围棋的平民化,我的中二梦终于也有人将之付诸实现了:
https://mp.weixin.qq.com/s/npt2zZrKwPnNdY-hsa2RjQ
AI再乱围棋圈:“食言之战”柯洁落败;首例素人作弊引风波
这次作弊风波所使用的AI就是Leela Zero,可见目前(2018.5)它的棋力已经超过了顶尖棋手。
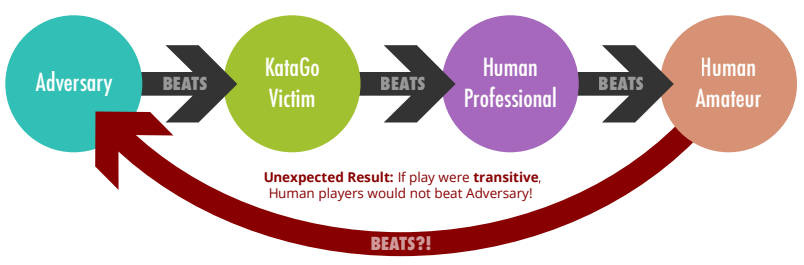
论文:
《Adversarial Policies Beat Superhuman Go AIs》
官网:
https://goattack.far.ai/
参考:
https://www.zhihu.com/question/569568604
如何看待katago被找到致命缺陷?
https://www.zhihu.com/question/584836681
如何看待美国业余围棋爱好者战胜顶级围棋AI,15局胜14局?
https://www.zhihu.com/question/554569740
国际象棋比赛疑用智能肛珠作弊,比赛作弊是如何靠人工智能和肛珠实现的?
参考
https://blog.csdn.net/amds123/article/details/70666594
论文笔记:Mastering the game of Go with deep neural networks and tree search
https://mp.weixin.qq.com/s/Sfv-jzQAkN0PsZOGZUQhkQ
AlphaGo Zero横空出世,DeepMind Nature论文解密不使用人类知识掌握围棋
https://mp.weixin.qq.com/s/oAxouYX7-wDC5okbu–Wuw
Nature重磅:人工智能从0到1, 无师自通完爆阿法狗100-0
https://zhuanlan.zhihu.com/p/30262872
关于AlphaGo Zero
https://zhuanlan.zhihu.com/p/30263585
DeepMind新一代围棋程序AlphaGo Zero再次登上Nature
https://www.zhihu.com/question/66861459
如何评价DeepMind发表在Nature上的AlphaGo Zero?
https://deepmind.com/blog/alphago-zero-learning-scratch/
AlphaGo Zero官方声明
https://zhuanlan.zhihu.com/mathNote
某牛的专栏,主要讲自制AlphaGo
http://xtf615.com/2018/02/10/AlphaGo/
Alpha Go论文解析
http://xtf615.com/2018/02/12/AlphaGo-Zero/
AlphaGo Zero论文解析
http://xtf615.com/2018/02/24/AlphaZeroDesign/
AlphaZero问题研究和算法设计与实现
https://mp.weixin.qq.com/s/DC9QqHdWT0xFnowEBuJDbw
自动化所解读“深度强化学习”:从AlphaGo到AlphaGoZero
https://mp.weixin.qq.com/s/uZtaxRwROCqYmL2k6Muxaw
从阿尔法狗元(AlphaGo Zero)的诞生看终极算法的可能性
https://mp.weixin.qq.com/s/i5OmLu8aNbypiTUmP4teeQ
刘遥行:深入浅出看懂AlphaGo Zero
https://mp.weixin.qq.com/s/aBrwbB_DOGTen-6XL7LGFQ
邓侃:白话蒙特卡洛树搜索和ResNet
https://mp.weixin.qq.com/s/nbTkr0PImlXUSYl91HD91Q
AlphaGo背后的力量:蒙特卡洛树搜索入门指南
https://mp.weixin.qq.com/s/-tH7DQo1cK9gA0bcpBJSDA
AlphaGo Zero:笔记与伪代码
https://mp.weixin.qq.com/s/CJuVoOf7idUChFIn7dH0Lg
围棋中的数学原理
https://mp.weixin.qq.com/s/d46qNFaftt4wxpV4sZnG-w
一张图看懂AlphaGo Zero
https://zhuanlan.zhihu.com/p/31749249
比AlphaGo Zero更强的AlphaZero问世,8小时解决一切棋类!
https://mp.weixin.qq.com/s/L7bZMkqyncwEt6D5tK1OdQ
AlphaZero炼成最强通用棋类AI,DeepMind强化学习算法8小时完爆人类棋类游戏
https://mp.weixin.qq.com/s/tFdnxqV5a5xZrFtB6E0AiQ
新AlphaZero出世称霸棋界,8小时搞定一切棋类!自对弈通用强化学习无师自通!
https://mp.weixin.qq.com/s/NwuuNIc9kc2qOGQP2pvRnA
AlphaZero原理与启示
https://mp.weixin.qq.com/s/8Zv3ElL2nWK-UDOHNjKb4g
从源码解密AlphGo Zero背后基本原理
https://mp.weixin.qq.com/s/qYWsFBKNCKCGUmizX_1sVg
AlphaGo 教学工具终于上线了!
https://mp.weixin.qq.com/s/JxbIeDk8_wnYu_ewUHp29g
深度学习与围棋实战书籍《Deep Learning and the Game of Go》
https://mp.weixin.qq.com/s/gsRnbknytz2FY2dWgdWEYg
精通国际象棋的AI研究员:AlphaZero真的是一次突破吗?
https://zhuanlan.zhihu.com/p/31809930
浅述:从Minimax到AlphaZero,完全信息博弈之路(1)
https://zhuanlan.zhihu.com/p/32073374
浅述:从Minimax到AlphaZero,完全信息博弈之路(2)
https://zhuanlan.zhihu.com/p/32089487
AlphaZero实战:从零学下五子棋
http://mp.weixin.qq.com/s/72riTTC3w0q9oF5H-51kXA
手把手教你搭建AlphaZero(使用Python和Keras)
https://mp.weixin.qq.com/s/Qw2tT7H1PwDvPgOYy8YUsQ
AlphaGo Zero代码迟迟不开源,TF等不及自己推了一个
https://mp.weixin.qq.com/s/Vq-osjgNXJQu5avGkxQdsw
手把手:AlphaGo有啥了不起,我也能教你做一个
https://mp.weixin.qq.com/s/ajajJ9yJZsOy4Vc0ULBxXg
国际象棋版AlphaZero出来了诶,还开源了Keras实现
https://zhuanlan.zhihu.com/p/41814142
从源码解密AlphaGo Zero背后基本原理
https://www.ifanr.com/630602
AlphaGo的棋局,与人工智能有关,与人生无关
https://mp.weixin.qq.com/s/J0w6kzzdKTbsaiZitbQdoA
达观数据:一文详解AlphaGo原理
https://mp.weixin.qq.com/s/BBQ54HHrFiqxXkC-EI6ELw
Science封面:AlphaZero达成终极进化体,史上最强棋类AI降临!
https://mp.weixin.qq.com/s/Pgw_xaCNl_kCPCg8NFzUBQ
人类没法下了!DeepMind贝叶斯优化调参AlphaGo,自弈胜率大涨16.5%
https://mp.weixin.qq.com/s/eE3oL6c5zHmTglHE-dgBvg
详解AlphaGo到AlphaGo Zero!
https://mp.weixin.qq.com/s/aAF0Gr7yEPkHRLASecJipw
百度正用谷歌AlphaGo,解决一个比围棋更难的问题
https://hackernoon.com/the-3-tricks-that-made-alphago-zero-work-f3d47b6686ef
The 3 Tricks That Made AlphaGo Zero Work
https://web.stanford.edu/~surag/posts/alphazero.html
A Simple Alpha(Go) Zero Tutorial
https://mp.weixin.qq.com/s/362skBPuwxS-bLcvv14MQg
井字棋、五子棋AlphaGo Zero算法实战
https://mp.weixin.qq.com/s/IaJoaQJw68JXBN93d680PQ
深入浅出解读并思考AlphaGo
https://mp.weixin.qq.com/s/foiyPVtLH5KVe_ST5rn-EQ
深度学习与围棋:为围棋数据设计神经网络
https://mp.weixin.qq.com/s/AcdhvGO-SdqODMFuVBJvUA
AI杀入斗地主领域,快手开发DouZero对标AlphaZero,干掉344个AI获第一

您的打赏,是对我的鼓励
