DRL » 深度强化学习(五)——IMPALA, Hierarchical RL, OpenAI, AlphaGo(1)
2019-10-04 :: 6304 WordsIMPALA
论文:
《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》
代码:
https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30
IMPALA是DeepMind于2018年提出的。
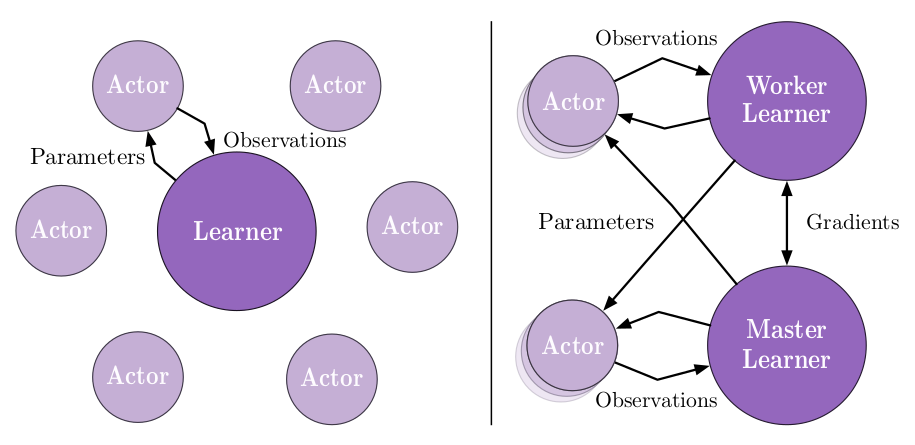
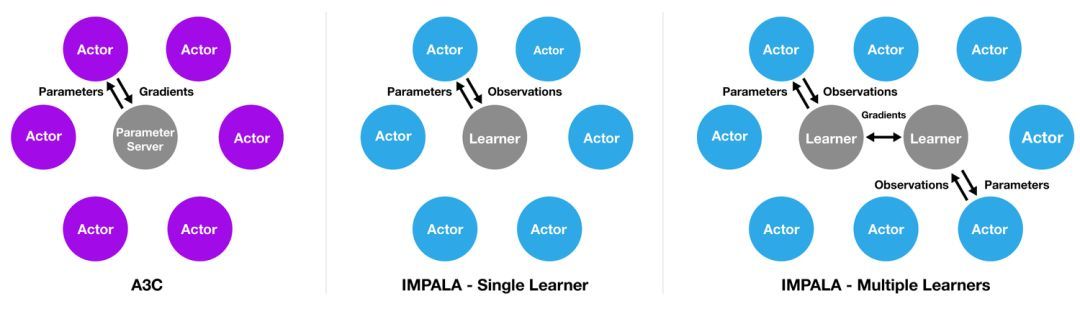
IMPALA的灵感来自于热门的A3C架构(上图左),后者使用多个分布式actor来学习agent的参数。在类似这样的模型中,每个actor都使用策略参数的一个副本,在环境中操作。actor会周期性地暂停探索,将它们已经计算得出的梯度信息分享至中央参数服务器,而后者会对此进行更新。
与此不同,IMPALA(上图中)中的actor不会被用来计算梯度信息。它们只是收集经验,并将这些经验传递至位于中心的learner。learner会计算梯度。因此在这样的模型中,actor和learner是完全独立的。
为了利用当代计算系统的规模优势,IMPALA在配置中可支持单个learner机器,也可支持多个相互之间同步的learner机器(上图右)。
由于actor只用于环境采样,而这个任务通常是一个仿真环境(例如游戏模拟器),因此它和learner在计算侧重点上有很大差异(例如在游戏领域,actor更侧重于仿真、渲染。),所以actor和learner的软硬件可以是异构的。
其次,由于Actor无须计算梯度,因此就可以一直采样,而无须等待策略的更新,这也是它和Batched A2C的最大区别。
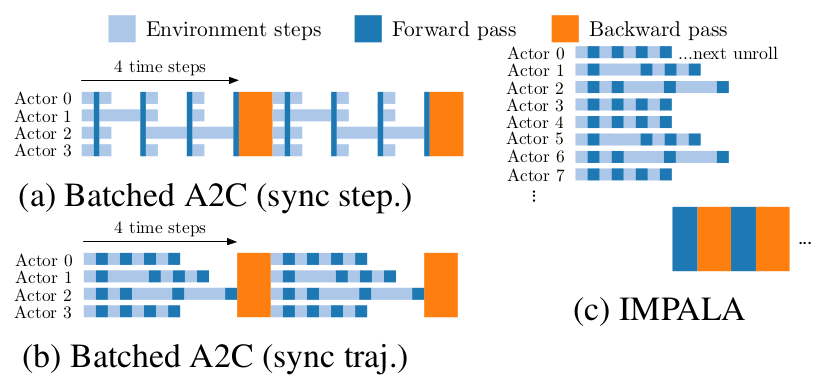
上图展示了这种差异,A2C采样了一个Batch之后,所有的actor都要停下来计算梯度,而IMPALA中的actor可以一直采样,从而大大提高了采样效率。
上图中的Batched A2C(sync step)和Batched A2C(sync traj)的区别在于:前者每次采样之后都要同步,这对于采样时间差异较大的例子,显然效率是很低下的。而后者是采样一批之后,再同步。
不过这种操作和学习的解耦也导致actor的策略落后于learner。为了弥补这样的差距,IMPALA还引入了V-trace技术。
参考:
https://zhuanlan.zhihu.com/p/56043646
AlphaStar之IMPALA
https://mp.weixin.qq.com/s/1zJyw67B6DqsHEJ3avbsfQ
DeepMind推出分布式深度强化学习架构IMPALA,让一个Agent学会多种技能
https://mp.weixin.qq.com/s/nfsm1v7MuI6mSpRb-rGBBQ
谷歌推出分布式强化学习框架SEED,性能“完爆”IMPALA,可扩展数千台机器,还很便宜
https://mp.weixin.qq.com/s/FQ7h0vixcztBUu70iFeYXw
Google发布”强化学习”框架”SEED RL”
Hierarchical RL

之前已经提到,在DeepMind测试的40多款游戏中,有那么几款游戏无论怎么训练,结果都是0,也就是DQN完全无效。上面就是其中最知名的代表游戏《Montezuma’s Revenge》。这是一个解谜游戏,比如图中要拿到钥匙,然后去开门。这对我们而言是通过先验知识得到的。但是很难想象计算机如何仅仅通过图像感知这些内容。感知不到,那么这种游戏也就无从解决。
论文:
《Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation》
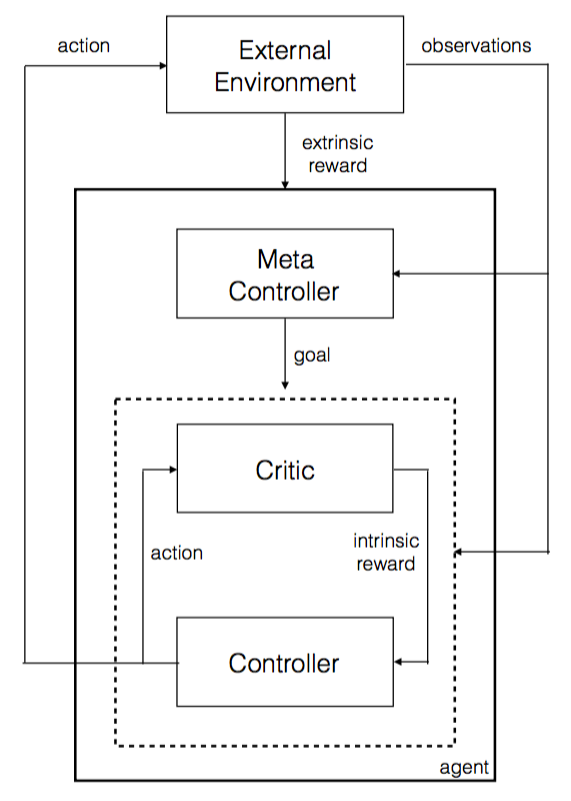
该论文的主要思路就是,弄一个两个层级的神经网络,顶层用于决策,确定下一步的目标,底层用于具体行为。
这里的内在目标是人工确定的,因此智能程度不高,但是比较实用。
其他算法:
FuN (FeUdal Networks for Hierarchical Reinforcement Learning)
HIRO (Data Efficient Hierarchical Reinforcement Learning)
HAC (Learning Multi-Level Hierarchies with Hindsight)
参考:
https://zhuanlan.zhihu.com/p/78098982
Hierarchical IL/RL(ICML 2018)
https://zhuanlan.zhihu.com/p/267524544
分层强化学习survey
https://blog.csdn.net/zhkmxx930xperia/article/details/87742722
Integrating Temporal Abstraction and Intrinsic Motivation
https://blog.csdn.net/songrotek/article/details/51384752
DRL前沿之:Hierarchical Deep Reinforcement Learning
https://mp.weixin.qq.com/s/IYyGgnoXZm6YfamLejqoNQ
深度强化学习试金石:DeepMind和OpenAI攻克蒙特祖玛复仇的真正意义
https://mp.weixin.qq.com/s/iBWjobr9srhB3MTiE_Wwmg
史上最强Atari游戏通关算法:蒙特祖玛获分超过200万!
PILCO
论文:
《PILCO: A Model-Based and Data-Efficient Approach to Policy Search》
《Efficient Reinforcement Learning using Gaussian Processes》
《Data-Efficient Reinforcement Learning in Continuous-State POMDPs》
《Improving PILCO with Bayesian Neural Network Dynamics Models》
参考:
https://zhuanlan.zhihu.com/p/27537744
基于模型的强化学习方法PILCO及其扩展(一)
https://zhuanlan.zhihu.com/p/27539273
基于模型的强化学习方法PILCO及其扩展(二)
https://zhuanlan.zhihu.com/p/27697260
基于模型的强化学习算法PILCO及其扩展(三)
https://zhuanlan.zhihu.com/p/72642285
基于模型的强化学习论文合集
OpenAI
OpenAI,由诸多硅谷大亨(Elon Musk等)联合建立的人工智能非营利组织。
官网:
https://openai.com/
github:
https://github.com/openai
自2020年微软与OpenAI在GPT-3源代码独家访问权上达成协议以来,OpenAI就不再向社会大众开放GPT-3的模型代码(尽管GPT-1和GPT-2仍是开源项目)。
出于对科技巨头霸权的“反叛”,一个由各路研究人员、工程师与开发人员志愿组成的计算机科学家协会成立,立志要打破微软与OpenAI对大规模NLP模型的垄断,且取得了不错的成果。
这个协会,就是:EleutherAI。
它以古罗马自由女神Eleutheria的名字命名,透露出对巨头的不屑与反抗。
EleutherAI的成立于2020年7月,主要发起人是一群号称自学成才的黑客,主要领导人包括Connor Leahy、Leo Gao和Sid Black。
The Common Pile:8TB合法授权/公共领域数据集,用于规避版权争议。(2025年6月)
Anthropic AI成立于2021年2月。Dario Amodei(CEO)、Daniela Amodei(总裁),均为前OpenAI高管。
Baselines
若干经典RL算法的实现,包括A2C、DQN等。
代码:
https://github.com/openai/baselines
Gym
Openai gym是一个用于开发和比较强化学习(reinforcement learning,RL)算法的工具包,与其他的数值计算库兼容,如tensorflow或者theano库。现在主要支持的是python语言,以后将支持其他语言。
官网:
https://gym.openai.com/
sudo apt install libffi-dev swig
git clone https://github.com/openai/gym
cd gym
pip install -e . # minimal install
pip install -e .[all] # all install
这里选择minimal install就可以了,all install需要安装MuJoCo,而后者是收费软件。(2021.10被DeepMind收购并免费。)
和Gym配套的还有一个算法库:
https://github.com/openai/baselines
当然,看名字也知道这只是一个简单的算法库。
参考:
http://tech.163.com/16/0510/09/BMMOPSCR00094OE0.html
马斯克的AI野心——OpenAI Gym系统深度解析
https://mp.weixin.qq.com/s/KK1gwDW2EyptZOiuFjyAlw
OpenAI发布强化学习环境Gym Retro:支持千种游戏
https://blog.csdn.net/jinzhuojun/article/details/77144590
常用增强学习实验环境 I (MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
https://blog.csdn.net/jinzhuojun/article/details/78508203
常用增强学习实验环境 II (ViZDoom, Roboschool, TensorFlow Agents, ELF, Coach等)
https://mp.weixin.qq.com/s/0oVG7zMi08dzMQrk43T3mw
像训练Dota2一样训练真实机器人?Gibson Environment环境了解一下
https://mp.weixin.qq.com/s/_A0q8DFAsIclaofVgZfjMA
定制股票交易OpenAI Gym强化学习环境
https://blog.csdn.net/gsww404/article/details/80627892
OpenAI-baselines的使用方法
https://mp.weixin.qq.com/s/6yXI2PXuuPeipj9WQo_e2Q
如何在Windows上安装和渲染OpenAI-Gym
RND
OpenAI最近开发了RND(Random Network Distillation),一种基于预测的强化学习算法,用于鼓励强化学习代理通过好奇心来探索他们所处环境。在游戏任务Montezuma’s Revenge上首次超过人类的平均表现。
blog:
https://blog.openai.com/reinforcement-learning-with-prediction-based-rewards/
Reinforcement Learning with Prediction-Based Rewards
代码:
https://github.com/openai/random-network-distillation
AlphaGo
概述
AlphaGo算是这波AI浪潮的里程碑事件了。如果说AlexNet让学术界重新认识了DL的话,AlphaGo则让大众都认识到了DL的威力。我也是在AlphaGo的感召之下,投身ML/DL领域的(2016.7)。因此,了解AlphaGo的原理,就成为了我一直以来的目标。岂料直到三年多之后(2019.11),我才能真正看懂AlphaGo。
在讲解原理之前,我们首先回顾一下AlphaGo的各个重要事件。
2015.10 AlphaGo Fan 5:0 击败樊麾。
2016.3 AlphaGo Lee 4:1 击败李世石。
樊麾讲解AlphaGo与李世石的五番棋:
https://deepmind.com/research/alphago/alphago-games-simplified-chinese/
2017.1 AlphaGo Master 60:0 击败各大高手。
2017.5 AlphaGo Ke 3:0 击败柯洁。
2017.10 AlphaGo Zero。
2017.12 AlphaZero:
训练4小时打败了国际象棋的最强程序Stockfish!
训练2小时打败了日本将棋的最强程序Elmo!
训练8小时打败了与李世石对战的AlphaGo Lee!
这里包含了AlphaGo一系列战役的棋谱:
http://www.alphago-games.com/
DarkForestGo
DarkForestGo是田渊栋2015年11月的作品,虽然棋力和稍后的AlphaGo相去甚远,但毕竟也算是用到了RL和DNN了。
论文:
《Better Computer Go Player with Neural Network and Long-term Prediction》
代码:
https://github.com/facebookresearch/darkforestGo
DarkForest中的一些规则借鉴了开源围棋软件Pachi:
http://pachi.or.cz/
以下是作者本人的讲解:
https://zhuanlan.zhihu.com/p/20607684
AlphaGo的分析
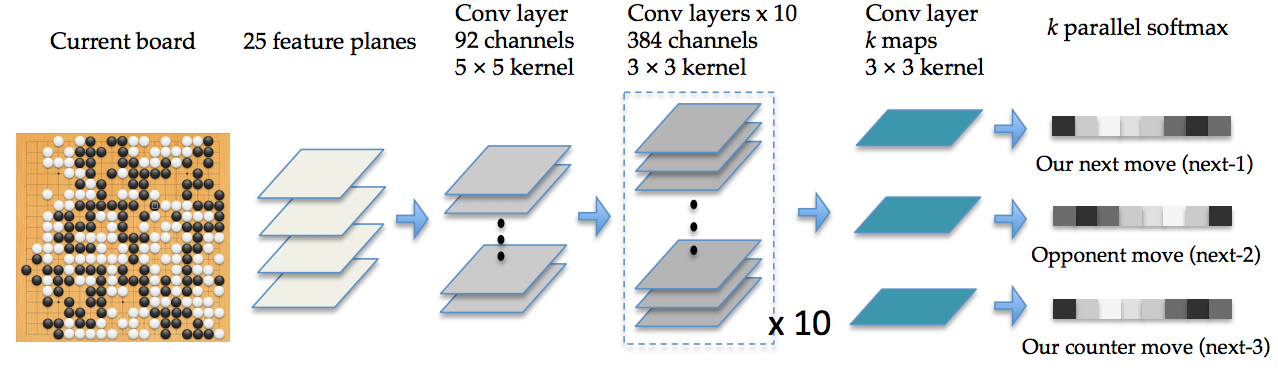
上图是DarkForest的网络结构图。其中的细节,我们将在讲解AlphaGo的时候,再细说。
AlphaGo
论文:
《Mastering the game of Go with deep neural networks and tree search》
AlphaGo主要由几个部分组成:
-
走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。
-
快速走子(Fast rollout),目标和1一样,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。
-
估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。
-
蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
以下是详细的解说。

您的打赏,是对我的鼓励
