resource » 数据结构 & 普通CS算法(一)
2020-09-17 :: 6223 Words数据结构 & 普通CS算法
https://github.com/TheAlgorithms
搜索算法,一触即达:GitHub上有个规模最大的开源算法库
Introduction to Algorithms Third Edition, published by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein.(CLRS)
Computer Systems: A Programmer’s Perspective(CSAPP)
Structure and Interpretation of Computer Programs(SICP)
https://github.com/krahets/hello-algo
中文的算法入门教程
TopK
https://zhuanlan.zhihu.com/p/76734219
面试官最喜爱的TopK问题算法详解
https://www.cnblogs.com/qlky/p/7512199.html
海量数据中找出前k大数(topk问题)
https://www.jianshu.com/p/5b8f00d6a9d7
topK算法问题
正则表达式
C++可用的regex性能最高的是Hyperscan,Google的re2有很多著名的工业级项目背书,是最优选择。
https://mp.weixin.qq.com/s/OtVRL37CNt_d5yEJPzzBzg
一个由正则表达式引发的血案
https://mp.weixin.qq.com/s/udEQzNk7vTltFhLyAXrsNQ
图文解读助你理解和使用正则表达式
https://zhuanlan.zhihu.com/p/27971065
关于多正则匹配
https://segmentfault.com/a/1190000007929344
Python正则表达式re模块简明笔记
https://mp.weixin.qq.com/s/Tewaynja3ggkcpzAli-1YQ
Python正则表达式
https://mp.weixin.qq.com/s/8rqgDGejBZd51riVNZZ7tg
使用Python验证常见的50个正则表达式
https://mp.weixin.qq.com/s/MFvJ8jcQf0pOiu-GRPMlFQ
动手学正则表达式
Trie树
Trie树也称字典树,因为其效率很高,所以在在字符串查找、前缀匹配等中应用很广泛,其高效率是以空间为代价的。
下面以英文单词构建的字典树为例,这棵Trie树中每个结点包括26个孩子结点,因为总共有26个英文字母(假设单词都是小写字母组成)。
如给出字符串”abc”,”ab”,”bd”,”dda”,根据该字符串序列构建一棵Trie树。则构建的树如下:
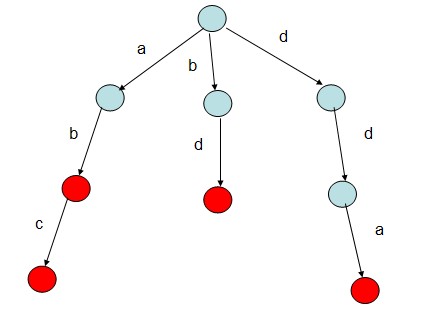
参考:
https://mp.weixin.qq.com/s/J7C70ASC6GZJqmqut0Z6Ag
双数组Trie树(DoubleArrayTrie)Java实现
https://mp.weixin.qq.com/s/nMmrVPvjaPOLgxKNjMzetw
动画+解析,轻松理解“Trie树”
排序
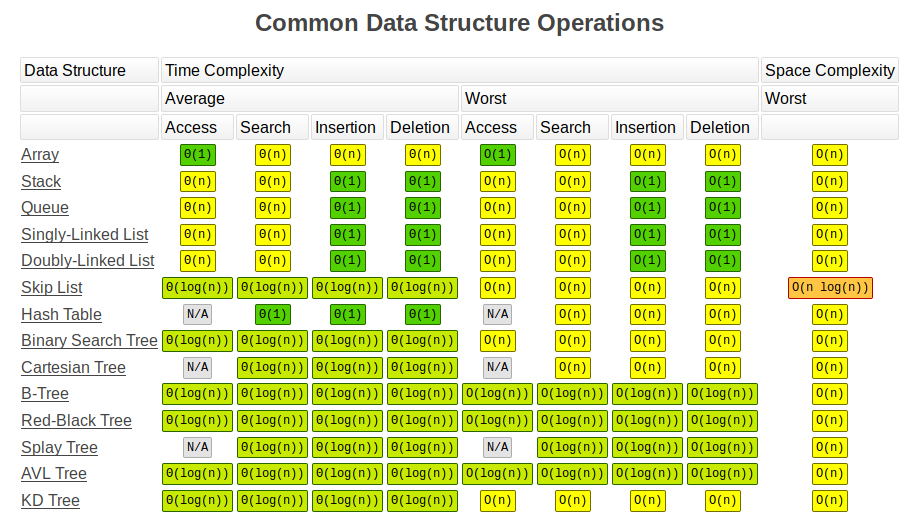
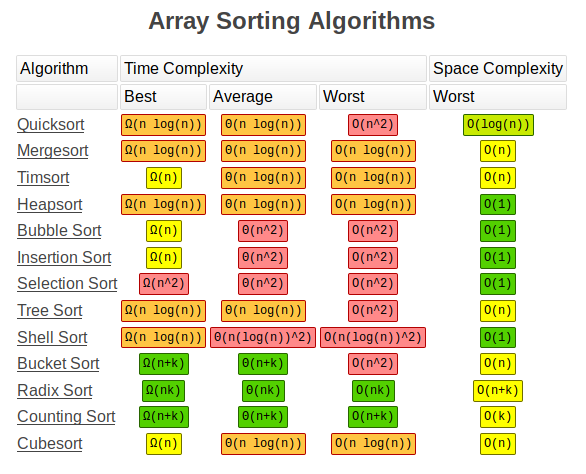
上面两个图的原始地址:
http://bigocheatsheet.com/
该网站还提供了其他关于算法复杂度的资料。
https://mp.weixin.qq.com/s/xttZJVR0r5vssOJ19sBHGQ
快速排序算法
https://mp.weixin.qq.com/s/jQ6fEi_K2RSesJxZn_kujg
外部排序
https://mp.weixin.qq.com/s/QAAfjSeZtfd3PSN3wAP8RQ
什么是外部排序?
https://mp.weixin.qq.com/s/Yp1hD2Bbmj3pRrLYjfwfEw
用Python手写十大经典排序算法
https://mp.weixin.qq.com/s/qLbCjTkDUHUosWQJjymqzQ
诸葛亮 vs 司马懿,排序算法大战谁能笑到最后?
https://www.cnblogs.com/tuding/p/7335853.html
双调排序Bitonic Sort,适合并行计算的排序算法
https://mp.weixin.qq.com/s/fP36LYFjAqqfP3rbYxAJlA
优秀的排序算法如何成就了伟大的机器学习技术

https://mp.weixin.qq.com/s/FAp10hI05qLLZi5BypondA
除了冒泡排序,你知道Python内建的排序算法吗?
这篇blog其实和Python关系不大,它主要讲述了Timsort排序算法。
Tim Peters,美国软件工程师。他于2002年在python上实现了Timsort排序算法。该算法后来被诸如Java、Android、GNU Octave等所采用。
早期最好的排序算法是QuickSort,比如C语言库自带的qsort函数,使用的就是该算法。然而它对于倒序数组这种最坏情况的复杂度居然是\(O(n^2)\)。
当然,Timsort也非完美,比如它的空间复杂度就比QuickSort高。
https://mp.weixin.qq.com/s/gBHmBLGILd6rZ-6cuelw0Q
这可能是你听说过最快的稳定排序算法(Timsort)
https://zhuanlan.zhihu.com/p/695042849
图解世界上最快的排序算法:Timsort
Introsort是由David Musser在1997年设计的排序算法。这个排序算法首先从快速排序开始,当递归深度超过一定深度(深度为排序元素数量的对数值)后转为堆排序。采用这个方法,内省排序既能在常规数据集上实现快速排序的高性能,又能在最坏情况下仍保持\(O(n \log(n))\)的时间复杂度。
Glidesort巧妙地结合了Timsort风格的归并排序在预排序数据上的最佳性能和pattern-defeating quicksort在重复元素较多的数据集上的优势。
https://blog.csdn.net/gitblog_00088/article/details/138788294
探秘Glidesort:一种创新的稳定排序算法

基数排序(Radix Sort),先按低优先级排序,再按高优先级排序。
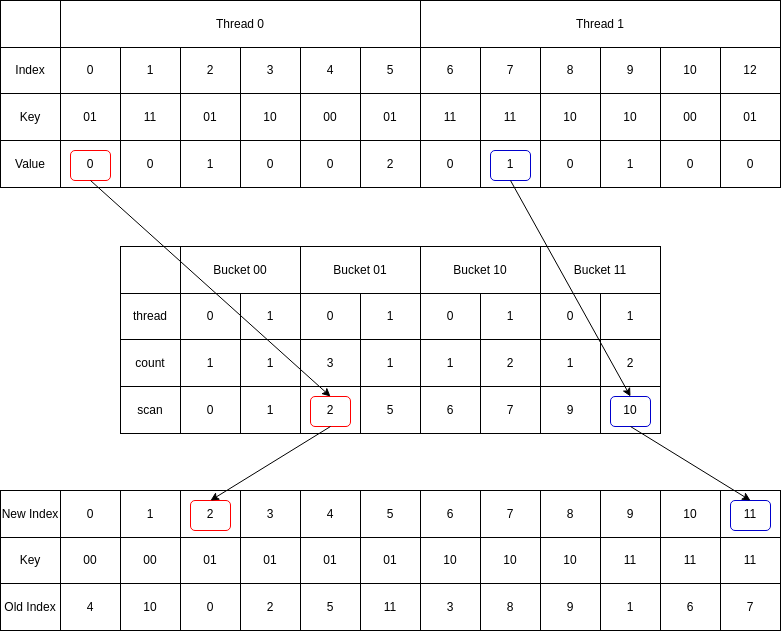
上图是GPU并行Radix Sort的原理图。
- Index是排序元素的原始序列号。
- Key是元素的值,为了简单起见,这里使用二进制,元素一共只有4个取值。根据取值的不同,分配到4个bucket。
- Value是该值在thread中重复出现的序号。Count是该值在Thread中出现的次数。
- Scan是去除自身之后的累加和(Exclusive Cumsum)。
- Value + Scan就是该元素在排好序之后的Index。
所以这里的排序问题,实际上被转化为如何并行求Exclusive Cumsum的问题了。
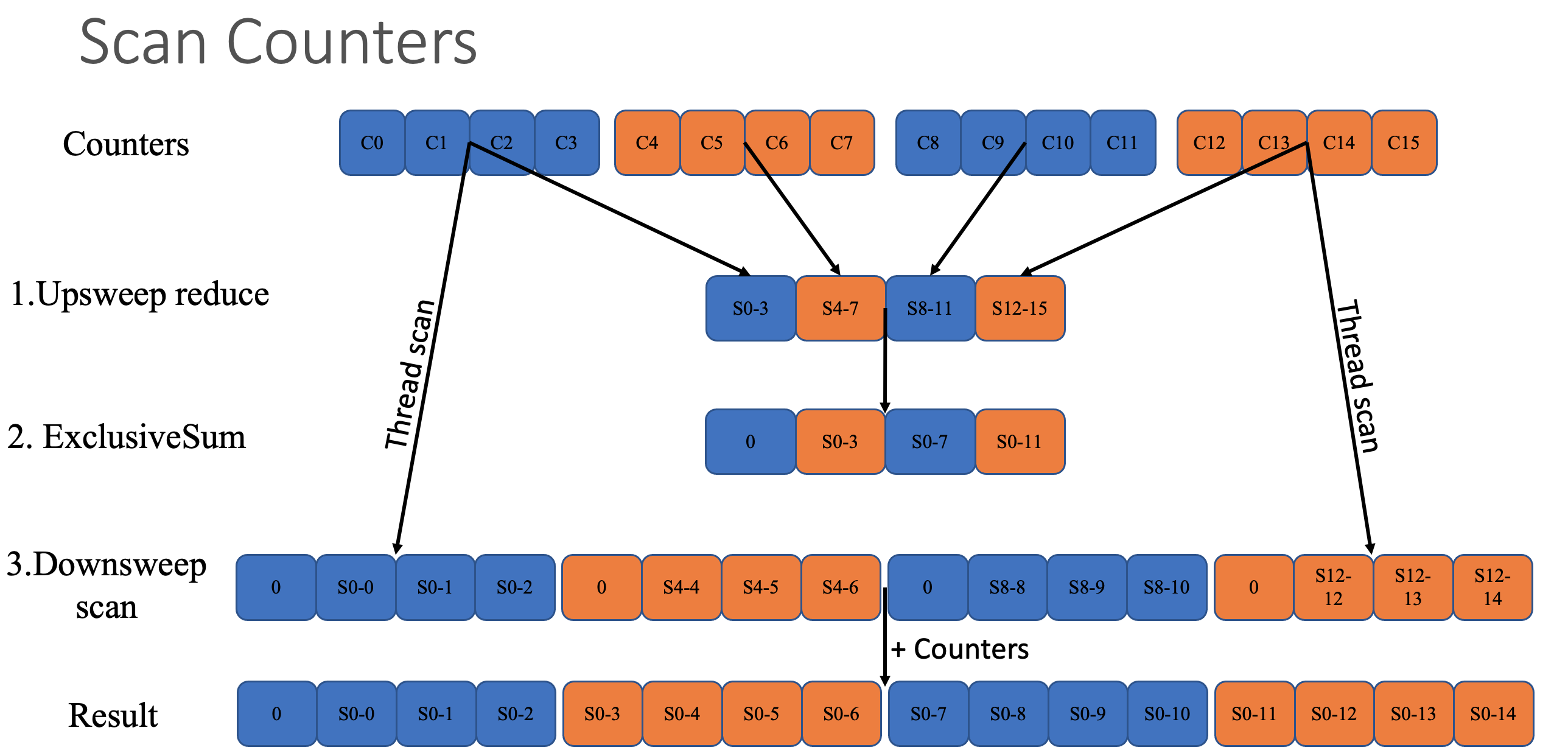
https://zhuanlan.zhihu.com/p/488016994
CUDA中的radix sort算法
Bloom Filter
https://blog.csdn.net/zhaodedong/article/details/78186450
Bloom Filter的原理和实现
https://blog.csdn.net/zhaodedong/article/details/78445910
Bloom Filter的数学背景
https://mp.weixin.qq.com/s/aPepcwG_VMioqGQ_Fp3deg
海量数据处理利器之布隆过滤器
https://zhuanlan.zhihu.com/p/371219898
布隆过滤器、LRU Cache
红黑树
https://mp.weixin.qq.com/s/IaYnfEZ2bUXIpQvN3ZqFGA
图解红黑树
https://juejin.im/post/5e509b27f265da57455b3f33
面试被问“红黑树”,我一脸懵逼…
https://www.cnblogs.com/linzworld/p/13720477.html
从根源上探究红黑树的本质
https://mp.weixin.qq.com/s/cESH1pmPiR5mpQC96RCoig
红黑树杀人事件始末
https://mp.weixin.qq.com/s/f5rppHa9zL0M9IVNtzk7Og
彻底搞懂“红黑树”…
Skip List
http://blog.csdn.net/u013709270/article/details/53470428
跳跃表的原理及实现
http://www.cppblog.com/mysileng/archive/2013/04/06/199159.html
Skip List(跳跃表)原理详解与实现
https://mp.weixin.qq.com/s/Zz9xjr36gd-FeUH6p6SKLg
跳表:会跳的链表原来这么diao
https://mp.weixin.qq.com/s/JbhEN5yc_igLQdhUH-ImBQ
高频面试数据结构——跳表
https://mp.weixin.qq.com/s/WlHl9xMJ-CZg5REFWSo0YA
深入理解跳表及其在Redis中的应用
ACBM算法
ACBM算法是在AC(Aho-Corasick)自动机(UNIX上的fgrep命令使用的就是AC算法)的基础之上,引入了BM(Boyer-Moore)算法的多模扩展,实现的高效的多模匹配。和AC自动机不同的是,ACBM算法不需要扫描目标文本串中的每一个字符,可以利用本次匹配不成功的信息,跳过尽可能多的字符,实现高效匹配。
Alfred Vaino Aho,1941年生,加拿大计算机科学家。普林斯顿大学博士,长期供职于贝尔实验室,后为哥伦比亚大学教授。egrep和fgrep的发明人,AWK语言的联合发明人。2003年获IEEE John von Neumann Medal。
Margaret John Corasick,贝尔实验室研究员。
Robert Stephen Boyer,德克萨斯大学教授。
J Strother Moore,德克萨斯大学教授。Boyer的好朋友,两人的绝大多数成就都是合作完成的。
虽然KMP算法以\(O(m+n)\)的复杂度独树一帜,常数也是1,但由于其很烂的缓存命中率,还不如其他最坏复杂度更高的算法。
C++标准库在待查找串\(len <= 3\)时,直接进行一次线性比较;在\(3< len < 256\)时,会使用一种修改后的Horspool算法,以提高缓存效率。而当待查找串\(len > 256\)时,则会使用Two-Way算法。
参见:
http://blog.csdn.net/sealyao/article/details/6817944
ACBM算法
https://mp.weixin.qq.com/s/yVOgAuD9hEYAMdLyvae2VA
最长公共子序列与最长公共子串
https://mp.weixin.qq.com/s/8rP3fF9iVnplhkFmxuj6fw
一文读懂KMP算法
https://mp.weixin.qq.com/s/-M8o1dTbYcnIe2ZkqWxkcg
一看就懂的字符串匹配算法KMP、BM、Sunday
https://mp.weixin.qq.com/s/if7P0yq59DbBEjW15vfaQA
推荐一个高效算法wumanber:每秒680万匹配!
https://mp.weixin.qq.com/s/4m1O5ZHsZTRc-JuBF97_3w
字符串匹配的Boyer-Moore算法
https://www.zhihu.com/question/392846851
C++string中find函数是用什么算法实现的?他的时间复杂度如何?实际比手写KMP效率相比如何?
Hash Map
std::map用二叉树实现,相当于Java中的TreeMap,而std::unordered_map用hash表实现,相当于Java中的HashMap。
C++11之前的一些非标准STL还实现了一种叫做hash_map的容器,原理上也是使用hash表,C++11标准为了不与之前的非标实现冲突,换了个名字而已。
如果使用复杂类型当key的话,unordered_map需要提供该复杂类型的hash函数。
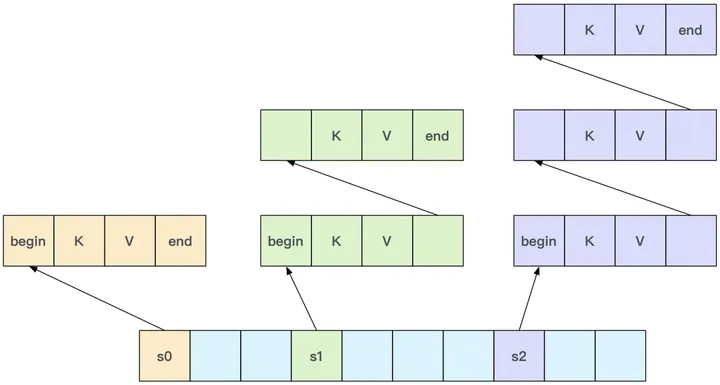
std::unordered_map内存布局

absl::flat_hash_map内存布局
absl::flat_hash_map采用开放寻址法(open addressing)解决hash碰撞,并使用二次探测(quadratic probing)方式。absl::flat_hash_map改进了内存布局,将所有pair放在一段连续内存中,将hash值相同的多个pair放在相邻位置。
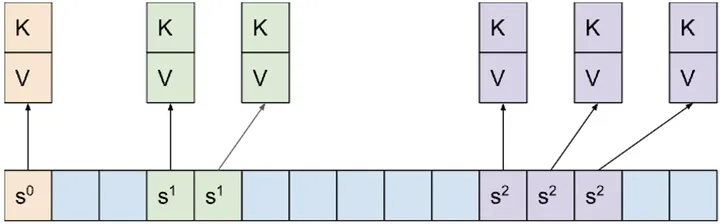
absl::node_hash_map内存布局
超过最大负载因子后,表大小会增加一倍。这就是所谓的rehash操作。absl::node_hash_map在rehash时,pair本身无需移动。
https://zhuanlan.zhihu.com/p/614105687
C++中的HashTable性能优化
计算cumsum
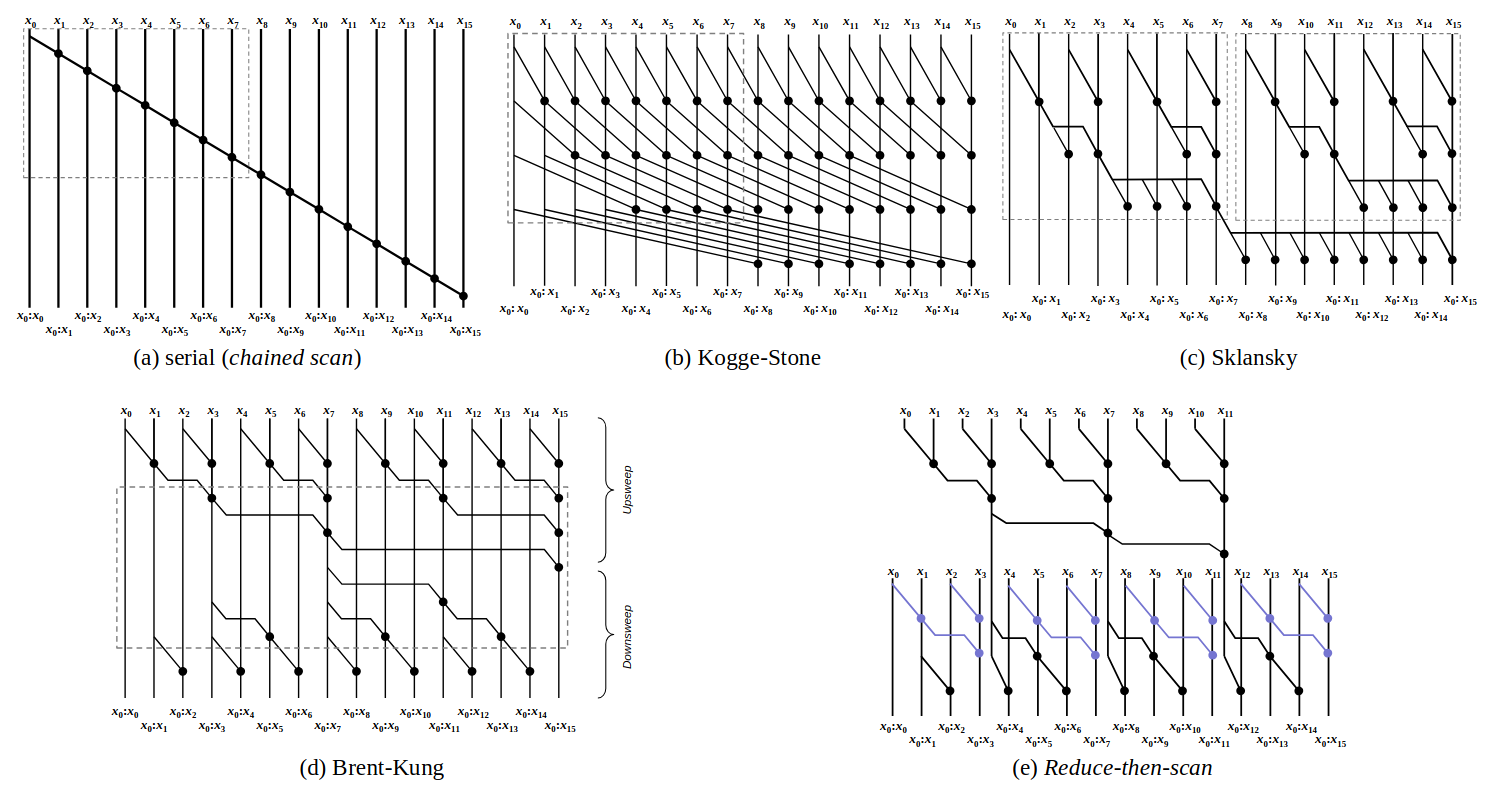
上图展示了一些常用的计算cumsum的并行算法。
其中,Sklansky方法相对比较简单一些,因为每一层的线程数都是相同的。
其中核心的计算index的代码如下:
for (uint32_t s = 1; s <= num_threads_x; s <<= 1) {
if (row_exists) {
uint32_t a = (threadIdx.x / s) * (2 * s) + s;
uint32_t ti = a + (threadIdx.x % s);
uint32_t si = a - 1;
sum[ti] = sum[ti] + sum[si]
}
__syncthreads();
}
参考:
https://research.nvidia.com/publication/single-pass-parallel-prefix-scan-decoupled-look-back
并行前缀(Parallel Prefix)加法器也采用了类似的思路。
https://www.cnblogs.com/sasasatori/p/18662877
并行前缀(Parallel Prefix)加法器

您的打赏,是对我的鼓励
