ML » 机器学习(三十三)——机器学习的算法体系&相关术语表, ACBM算法, 高斯过程回归, 花式采样, 元胞自动机
2018-01-29 :: 5114 Wordst-SNE
t-SNE(续)
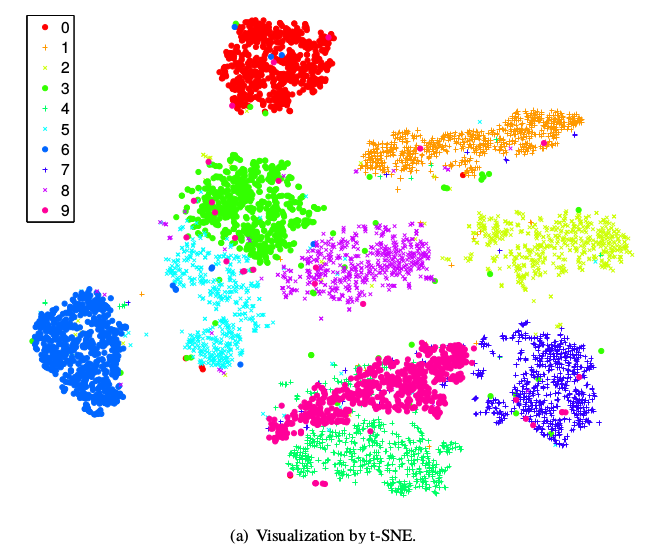
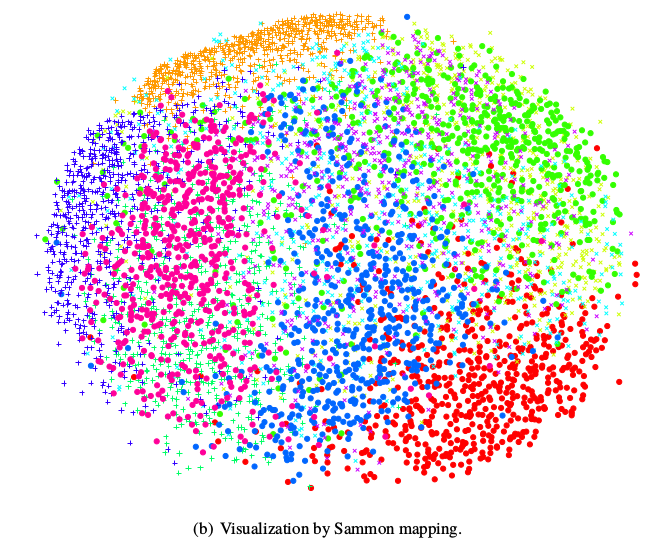
上图分别是使用t-SNE和Sammon mapping可视化MNIST数据集后的效果图。从中可以看出t-SNE图中,数据更成团状,可视化效果更好。
t-SNE的不足主要有四个:
主要用于可视化,很难用于其他目的。比如测试集合降维,因为他没有显式的预估部分,不能在测试集合直接降维;比如降维到10维,因为t分布偏重长尾,1个自由度的t分布很难保存好局部特征,可能需要设置成更高的自由度。
t-SNE倾向于保存局部特征,对于本征维数(intrinsic dimensionality)本身就很高的数据集,是不可能完整的映射到2-3维的空间
t-SNE没有唯一最优解,且没有预估部分。如果想要做预估,可以考虑降维之后,再构建一个回归方程之类的模型去做。但是要注意,t-sne中距离本身是没有意义,都是概率分布问题。
训练太慢。有很多基于树的算法在t-sne上做一些改进。
FastTSNE
该工具包提供了两种快速实现tSNE的方法:
Barnes-hut tsne:源于Multicore tSNE,适用于小规模数据集,时间复杂度为O(nlogn)。
Fit-SNE:源于Fit-SNE的C++实现方法,适用于样本量在10,000以上的大规模数据集,时间复杂度为O(n)。
代码:
https://github.com/pavlin-policar/fastTSNE
参考
https://www.zhihu.com/question/52022955
t-sne数据可视化算法的作用是啥?为了降维还是认识数据?
https://mp.weixin.qq.com/s/Rs9ri6Xs5R-yitrda8pJMg
详解可视化利器t-SNE算法:数无形时少直觉
https://mp.weixin.qq.com/s/_DXMlNZHVKm2jMnLGQFM_Q
还在用PCA降维?快学学大牛最爱的t-SNE算法吧
http://www.datakit.cn/blog/2017/02/05/t_sne_full.html
t-SNE完整笔记
https://yq.aliyun.com/articles/70733
比PCA降维更高级——(R/Python)t-SNE聚类算法实践指南
https://mp.weixin.qq.com/s/7Vy7l1YyBT7rMYW2i1AsuA
线性判别分析(LDA)原理详解
https://mp.weixin.qq.com/s/cnzQ7XepftDOZXslCf1MUA
你真的会用t-SNE么?有关t-SNE的小技巧
https://mp.weixin.qq.com/s/lbpe2NO1m8S38wpnp47BEg
通过可视化隐藏表示,更好地理解神经网络
https://mp.weixin.qq.com/s/F08aOjKsVdRInN6GPNJ7cA
t-SNE:最好的降维方法之一
https://mp.weixin.qq.com/s/qHOmUJgalvxwEBCBiiR7ig
t-SNE
https://mp.weixin.qq.com/s/EaeVywxcQX3goW7WqYiOBA
探究Softmax的替代品:exp(x)的偶次泰勒展开式总是正的
https://mp.weixin.qq.com/s/GEagy8-BwWcuWgzG9e8XbA
t-SNE:可视化效果最好的降维算法
机器学习的算法体系&相关术语表
算法体系
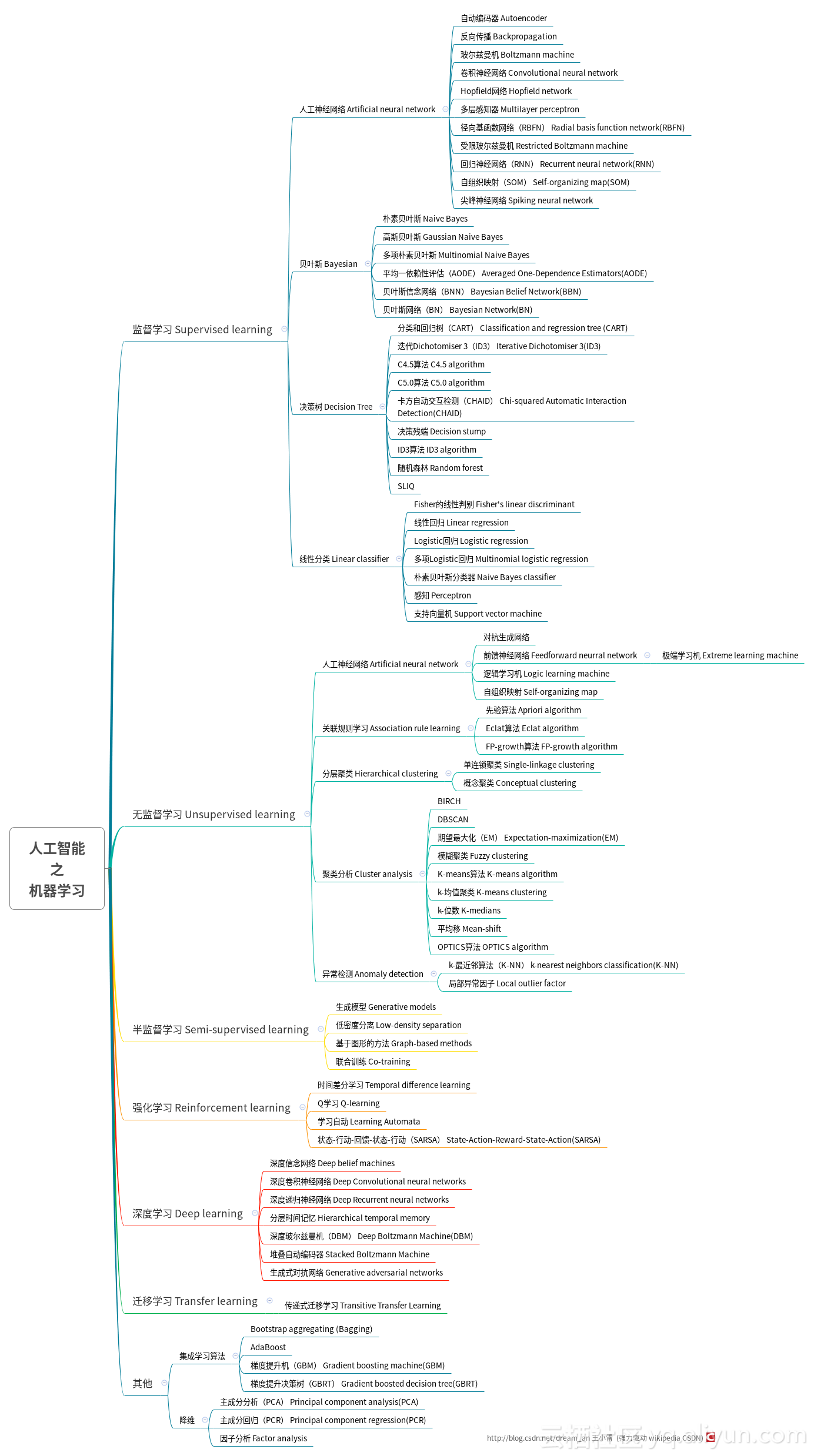
原文:
https://mp.weixin.qq.com/s/HapJwwmN3-dbQvzp2jzt1w
一文看懂机器学习的算法体系
相关术语表
https://mp.weixin.qq.com/s/6KRNawRE1i8de3ctgv6aVg
机器学习词汇表:纵览机器学习基本词汇与概念
https://mp.weixin.qq.com/s/AtImcIBaRIJVXpOP2hruBQ
Google发布机器学习术语表 (包括简体中文)
https://www.zhihu.com/question/469612040
刚进算法团队,大牛们讨论高深的cv术语和算法,如何才能听懂?
高斯过程回归
从大的分类来说,机器学习的算法可分为两类:
1.定义一个模型,用训练数据训练模型的参数,然后用训练好的模型进行预测。这种方法的缺点在于,预测效果和模型与样本的匹配程度有关。比如对非线性样本采用线性模型,其预测效果通常不会太好。但是增加模型的复杂度,又会导致过拟合。
2.定义一个函数分布,赋予每一种可能的函数一个先验概率,可能性越大的函数,其先验概率越大。但是可能的函数往往为一个不可数集,即有无限个可能的函数,随之引入一个新的问题:如何在有限的时间内对这些无限的函数进行选择?一种有效解决方法就是高斯过程回归(Gaussian process regression,GPR)。
Radford M. Neal,1956年生,加拿大科学家。多伦多大学博士(1995)和教授。贝叶斯神经网络的发明人。导师为Geoffrey Hinton。
个人主页:http://www.cs.toronto.edu/~radford/
Danie G. Krige,1919~2013,南非矿业工程师和统计学家,威特沃特斯兰德大学教授。地理统计学早期的代表人物之一。
http://www.cnblogs.com/hxsyl/p/5229746.html
浅谈高斯过程回归
https://mqshen.gitbooks.io/prml/content/Chapter6/gaussian/gaussian_processes_regression.html
Gaussian Processes Regression
http://www.gaussianprocess.org/gpml/chapters/RW.pdf
Gaussian Processes for Machine Learning
http://people.cs.umass.edu/~wallach/talks/gp_intro.pdf
Introduction to Gaussian Process Regression
http://wenku.baidu.com/view/72f80113915f804d2b16c173.html
高斯过程回归方法综述
https://mp.weixin.qq.com/s/ZE_Chzlgy_7wl9E9q1ckOA
AlphaGo Zero用它来调参?“高斯过程”到底有何过人之处?
https://mp.weixin.qq.com/s/VzN02XW3yN2peqTD6q-4Cg
从数学到实现,全面回顾高斯过程中的函数最优化
https://zhuanlan.zhihu.com/gpml2016
高斯世界下的Machine Learning
https://mp.weixin.qq.com/s/FJAgpbBgRA2Zk3BuiEwjdw
看得见的高斯过程:这是一份直观的入门解读
https://zhuanlan.zhihu.com/p/58987388
多元高斯分布完全解析
https://zhuanlan.zhihu.com/p/73832253
通俗理解高斯过程及其应用
https://zhuanlan.zhihu.com/p/75072046
Gaussian process classification初介绍——回归与分类点点滴滴
https://zhuanlan.zhihu.com/p/75589452
高斯过程Gaussian Processes原理、可视化及代码实现
https://mp.weixin.qq.com/s/Bw0vD9EEQijjE1gaIAetHw
如何推导高斯过程回归以及深层高斯过程详解
https://mp.weixin.qq.com/s/1HggYumIF2pAomCtA-eu6g
如何知道一个变量的分布是否为高斯分布?
热传导推荐算法
https://www.zhihu.com/question/20184666
推荐系统中用到的热传导算法和物质扩散是怎么用的?
http://tis.hrbeu.edu.cn/oa/pdfdow.aspx?Sid=20160307
基于影响力控制的热传导算法
http://www.doc88.com/p-7082821463697.html
改进的热传导和物质扩散混合推荐算法
花式采样
- 分层采样(stratified random sampling)
假设我们需要估计选举中每个候选人的平均票数。现假设该国有3个城镇:
A镇有100万工人,B镇有200万工人,以及C镇有300万退休人员。
如果我们选择从A、B和C镇分别抽取10、20和30个随机样本,那么我们可以在总样本一定的情况下,产生较小的估计误差。
- 蓄水池采样(Reservoir sampling)
采样过程:集合中总元素个数为n,随机选取k个元素。
step1:首先将前k个元素全部选取。
step2:对于第i个元素(i>k),以概率k/i来决定是否保留该元素,如果保留该元素的话,则随机丢弃掉原有的k个元素中的一个(即原来某个元素被丢掉的概率是1/k)。
结果:每个元素被最终被选取的概率都是k/n。
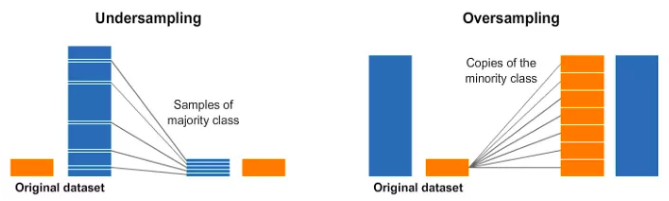
- 欠采样(Undersampling)和过采样(Oversampling)
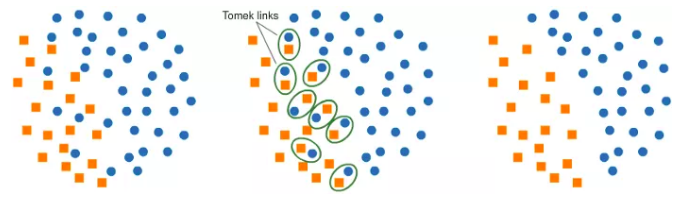
- Tomek Links
在这个算法中,我们最终从Tomek Links中删除了大多数元素,这为分类器提供了一个更好的决策边界。
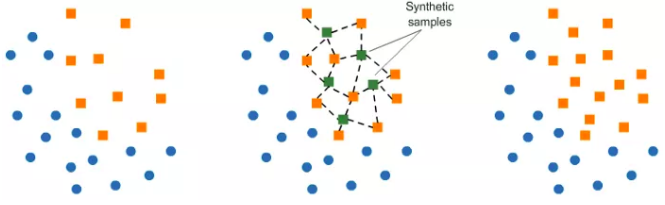
- SMOE(Synthetic Minority Oversampling Technique)
在现有元素附近合并少数类的元素。
参考:
https://mp.weixin.qq.com/s/d3bpfnx-JGY7whqnHwAmWw
机器学习中不得不知的5种采样方法,分层、水塘等!
https://mp.weixin.qq.com/s/OZ-HfxBgFSvqeH8AEjGluQ
采样算法哪家强?一个针对主流采样算法的比较
元胞自动机
http://www.doc88.com/p-8939046003005.html
元胞自动机理论及其在计算机仿真模拟中的应用
http://blog.csdn.net/chl033/article/details/5367861
元胞自动机与相关理论和方法
http://blog.csdn.net/deepfuture/article/details/5065284
元胞自动机
http://www.cnblogs.com/Firefly727/articles/1856328.html
元胞自动机
https://mp.weixin.qq.com/s/KZcNsTLurOm7MNfCkNvcZw
CNN与元胞自动机:“深度”之含义初探
https://mp.weixin.qq.com/s/TQ-koPMLknWQtDsolrU8Jw
什么是元胞自动机?
https://mp.weixin.qq.com/s/g8rogZKkZvGEYA9MD_kFwA
硬核解读!燃烧了152天的澳大利亚山火是怎么来的?又是怎么灭的?
明+
早在于谦当政时,就将锦衣卫的权限刑狱之权给“阉割”了。那就是锦衣卫不能随意抓人和办案,要抓人和办案必须有刑部给事中用印,内阁用印,司礼监用印的“三印法帖”,简称“驾帖”。如果没有驾帖,锦衣卫无权办案拿人。。。
锦衣卫从此“阉割”,至于东厂,那就是司礼监的秉笔太监兼的一个差事,锦衣卫都草鸡了,东厂还监督什么???而且驾帖也必须是司礼监用印啊,所以锦衣卫就从此几乎在司礼监面前根本抬不起头了。因为东厂的存在就是监察锦衣卫,而实际上在于谦改制后,锦衣卫实际上就成了内阁的走狗了。。。
西厂成立的第一个月,汪直就办了一件大案,震惊朝野。
洪熙朝和宣德朝三杨之一——工部尚书兼谨身殿大学士杨荣,被他抄家了。杨荣的孙子杨泰被砍头,杨荣的曾孙杨晔直接干掉在锦衣卫诏狱。
杨荣是明代内阁制度的创立者之一,是文官的代表人物。此案一出,内阁直接和宪宗翻脸,导致成立了仅四个月的西厂被迫关门。。。

您的打赏,是对我的鼓励
