ML » 机器学习(二十八)——KNN, AutoML, 数据不平衡问题
2017-10-19 :: 6375 WordsKNN
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
和K-means的区别
虽然K-means和KNN都有计算点之间最近距离的步骤,然而两者的目的是不同的:K-means是聚类算法,而KNN是分类算法。
一个常见的应用是:使用K-means对训练样本进行聚类,然后使用KNN对预测样本进行分类。
KNN在时间序列分析上的应用
KNN虽然主要是个分类算法,但通过构建特殊的模型,亦可应用于其他领域。其中,KNN在时间序列分析上的应用,就是一个很有技巧性的事情。
假设已知时间序列\(X:\{x_1,\dots,x_n\}\),来预测\(x_{n+1}\)。
首先,我们选取\(x_{n+1}\)之前的最近m个序列值,作为预测值的特征向量\(X_{m\{n+1\}}\)。这里的m一般根据时间序列的周期来选择,比如商场客流的周期一般为一周。
\(X_{m\{n+1\}}\)和预测值\(x_{n+1}\)组成了扩展向量\([X_{m\{n+1\}},x_{n+1}]\)。为了表明\(x_{n+1}\)是预测值的事实,上述向量又写作\([X_{m\{n+1\}},y_{n+1}]\)。
依此类推,对于X中的任意\(x_i\),我们都可以构建扩展向量\([X_{m\{i\}},y_{i}]\)。即我们假定,\(x_i\)的值由它之前的m个序列值唯一确定。显然,由于是已经发生了的事件,这里的\(y_{i}\)都是已知的。
在X中,这样的m维特征向量共有\(n-m\)个。使用KNN算法,获得与\(X_{m\{n+1\}}\)最邻近的k个特征向量\(X_{m\{i\}}\)。然后根据这k个特征向量的时间和相似度,对k个\(y_{i}\)值进行加权平均,以获得最终的预测值\(y_{n+1}\)。
参考:
https://zhuanlan.zhihu.com/p/29838009
K近邻算法
https://mp.weixin.qq.com/s?__biz=MzI4ODU5NjQ3OQ==&mid=2247483791&idx=1&sn=0fafce03d0c20a14020e193b9b5b64e6
机器学习分类算法之k-近邻算法
https://mp.weixin.qq.com/s/HYNHkk9KSxuWZEfmPXAJKA
KNN简明教程
https://mp.weixin.qq.com/s/7ohIh_dVfzNyt7TpBlCFYw
机器学习算法KNN简介及实现
https://mp.weixin.qq.com/s/NukVEGgbqVx0S-LlBNrb-Q
以前你可能一直用错“K均值聚类”?
https://mp.weixin.qq.com/s/ewXRcTrolJxxN549vMQcfg
一文搞懂K近邻算法(KNN),附带多个实现案例
https://zhuanlan.zhihu.com/p/62450795
kNN的花式用法
AutoML
概述
尽管现在已经有许多成熟的ML算法,然而大多数ML任务仍依赖于专业人员的手工编程实现。
然而但凡做过若干同类项目的人都明白,在算法选择和参数调优的过程中,有大量的套路可以遵循。
比如有人就总结出参加kaggle比赛的套路:
http://www.jianshu.com/p/63ef4b87e197
一个框架解决几乎所有机器学习问题
https://mlwave.com/kaggle-ensembling-guide/
Kaggle Ensembling Guide
既然是套路,那么就有将之自动化的可能,比如下面网页中,就有好几个AutoML的框架:
https://mp.weixin.qq.com/s/QIR_l8OqvCQzXXXVY2WA1w
十大你不可忽视的机器学习项目
下面给几个套路图:
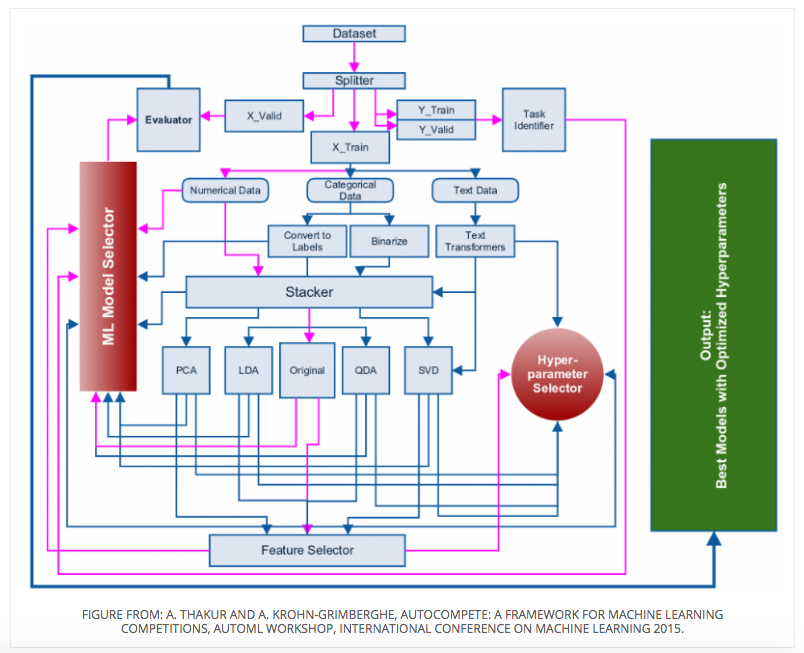
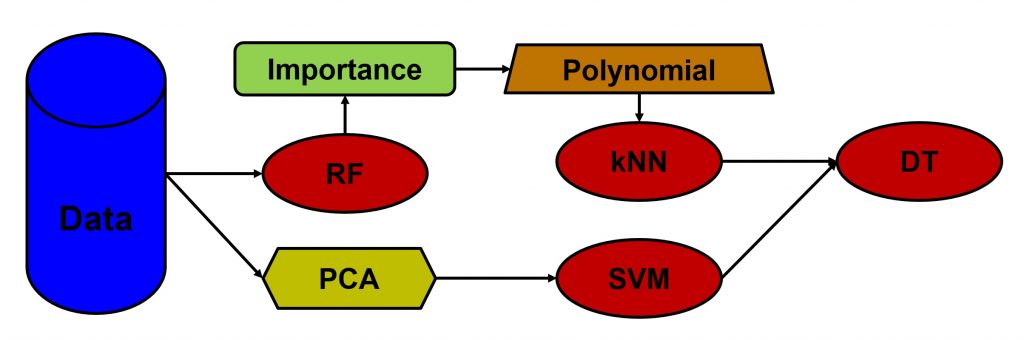
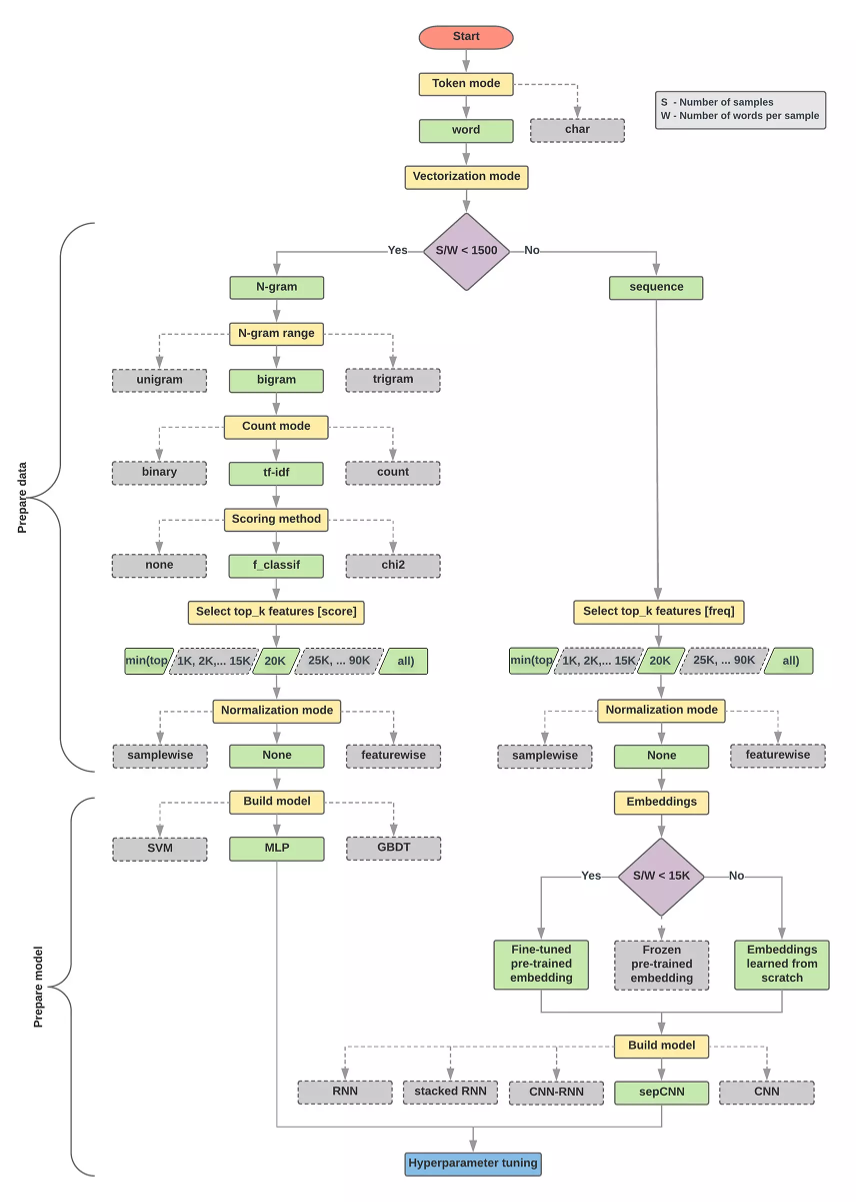
调参工具:
- Skopt
- Hyperopt
- Simple(x)
- Ray.tune
- Chocolate
- GpFlowOpt
- FAR-HO
- Xcessiv
- HORD
- ENAS
- NNI
- optuna
- hypergbm
https://zhuanlan.zhihu.com/p/93109455
关于AutoML,你想知道的都在这里!
超参数
所谓hyper-parameters,就是机器学习模型里面的框架参数,比如聚类方法里面类的个数,或者话题模型里面话题的个数等等,都称为超参数。它们跟训练过程中学习的参数(权重)是不一样的,通常是手工设定,不断试错调整,或者对一系列穷举出来的参数组合一通枚举(叫做网格搜索)。
AutoML是一个系统化的体系,包含3个要素:
-
自动特征工程AutoFeatureEng
-
自动调参AutoTuning
-
自动神经网络探索NAS
参见:
http://blog.csdn.net/xiewenbo/article/details/51585054
什么是超参数
http://www.cnblogs.com/fhsy9373/p/6993675.html
如何选取一个神经网络中的超参数hyper-parameters
https://mp.weixin.qq.com/s/Q7Xqb-GZXktFIM5yW8moPg
机器学习中的超参数的选择与交叉验证
https://mp.weixin.qq.com/s/zA7ePAwJ-xcmc8y9qNmE6g
一文详解超参数调优方法
https://mp.weixin.qq.com/s/_TSnP5jJsAZ1bW4CbmxdoQ
算法模型自动超参数优化方法
https://mp.weixin.qq.com/s/ou2OtXLE9-3jpaODHDumzQ
调参到头秃?你需要这份自动超参搜索技术攻略
FEDOT
FEDOT是一个AutoML框架。

代码:
https://github.com/nccr-itmo/FEDOT
参考:
https://zhuanlan.zhihu.com/p/386221257
通过FEDOT将AutoML用于时间序列数据
参考
https://mp.weixin.qq.com/s/-0–sZXjMvFKxxo87w4udg
自动机器学习工具全景图:精选22种框架,解放炼丹师
http://blog.csdn.net/aliceyangxi1987/article/details/71079448
一个框架解决几乎所有机器学习问题
https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-algorithm-cheat-sheet
MS提供的ML算法选择指南
https://mp.weixin.qq.com/s/53AcAZcCKBZI-i1CORl0bQ
分分钟带你杀入Kaggle Top 1%
https://mp.weixin.qq.com/s/NwVGkAcoDmyXKrYFUaK2Bw
如何在机器学习竞赛中更胜一筹?
https://mp.weixin.qq.com/s/5v80Qz2nEfoAig0ft_HzaA
Kaggle求生
https://mp.weixin.qq.com/s/K3EVwRFBJufXK5QKSQsPbQ
这是一份为数据科学初学者准备的Kaggle竞赛指南
https://mp.weixin.qq.com/s/hf4IOAayS29i6GB9m4GHcA
全自动机器学习:ML工程师屠龙利器
https://mp.weixin.qq.com/s/h2QQhoBfnEhU12RgatT3EA
机器学习都能自动化了?
https://mp.weixin.qq.com/s/-n-5Cp_hgkvdmsHGWEIpWw
自动化机器学习第一步:使用Hyperopt自动选择超参数
https://mp.weixin.qq.com/s/Nbwii7Di_h5Ewy5p5xzBdQ
解决机器学习问题有通法
http://automl.info/
某牛的blog
https://mp.weixin.qq.com/s/gXkD2PPNRhZGcXDxDXRAiQ
由0到1走入Kaggle-入门指导
https://mp.weixin.qq.com/s/2ZwhNN7kqigwRLqRnUOENw
谷歌做了45万次不同类型的文本分类后,总结出一个通用的“模型选择算法”
https://mp.weixin.qq.com/s/WQ-8OvF9-fRpRf5lgr5_iw
一种简单有效的网络结构搜索
https://mp.weixin.qq.com/s/g8U2C9bi75mE5OqWLPkgQw
自动化学习框架(AutoML)的性能比较
https://mp.weixin.qq.com/s/DkZGkI-CnEHfhXTDyp2nHQ
超参数搜索不够高效?这几大策略了解一下
https://zhuanlan.zhihu.com/p/48642938
分享一篇比较全面的AutoML综述
https://mp.weixin.qq.com/s/zE8N5snKK2EoM9WgAhI-_g
NeurIPS 2018 AutoML Phase1 冠军队伍 DeepSmart 团队解决方案分享
https://mp.weixin.qq.com/s/z6CaHP7I4WkJAu-eAJPwAg
自动机器学习计算量大!这种多保真度优化技术是走向应用的关键
https://mp.weixin.qq.com/s/JPAZTdvcxY3sgWukbn3ScQ
AutoML在推荐系统中的应用
https://mp.weixin.qq.com/s/95FH-_L5smx7WoNnfucWVg
为什么说自动化特征工程将改变机器学习的方式
https://mp.weixin.qq.com/s/lKsHvKjbIyBJ5OmCl2fIvg
如何基于Flink+TensorFlow打造实时智能异常检测平台?
https://mp.weixin.qq.com/s/MEGonT3rh0CTMkZ1Y8rZ7g
Auto Machine Learning自动化机器学习笔记
https://mp.weixin.qq.com/s/7-EMaoBsEAS3ZuubpZMaUQ
AutoML在表数据中的研究与应用
https://mp.weixin.qq.com/s/rI40udIwhd5rFbwmyehANw
AutoML技术及应用
https://mp.weixin.qq.com/s/vJInr8MwBKyPIcmdXF3ZVw
AutoFeatureENG
https://mp.weixin.qq.com/s/GXv_zkdmdJDdgWma_r3Hlw
scikit-learn中的自动模型选择和复合特征空间
数据不平衡问题
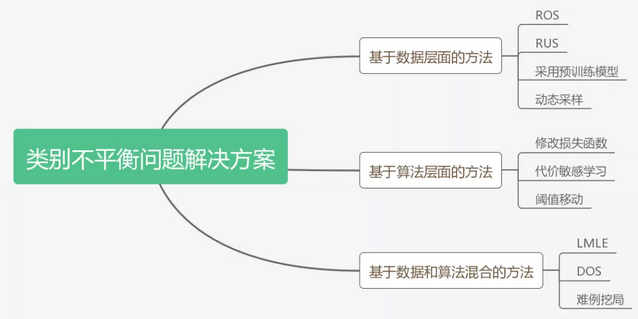
数据不平衡问题在现实世界中非常普遍。对于真实数据,不同类别的数据量一般不会是理想的uniform分布,而往往会是不平衡的;如果按照不同类别数据出现的频率从高到低排序,就会发现数据分布出现一个“长尾巴”,也即我们所称的长尾效应。大型数据集经常表现出这样的长尾标签分布:
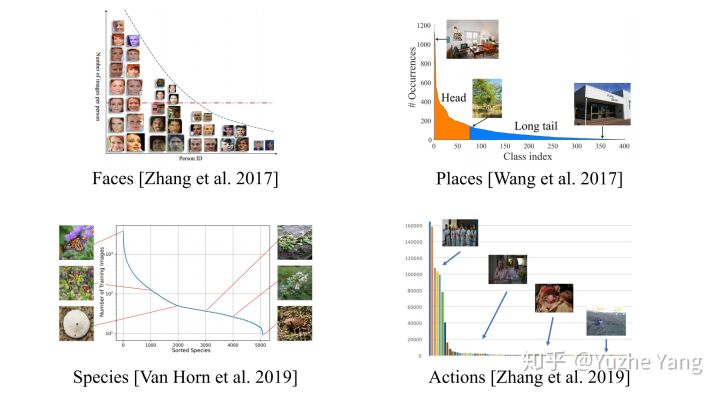
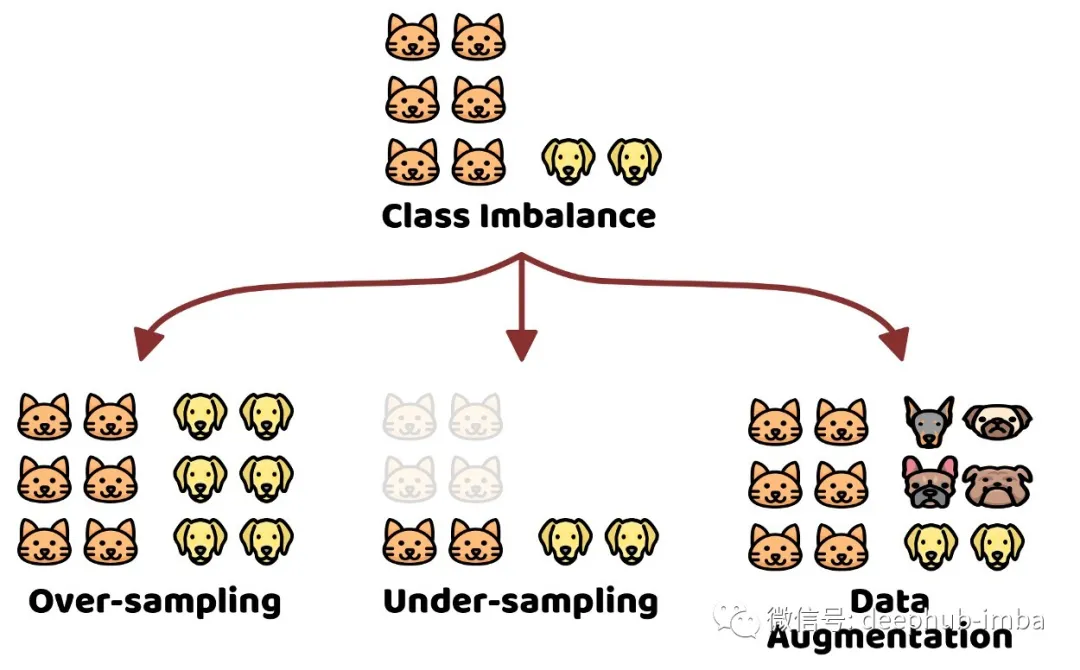
https://mp.weixin.qq.com/s/e0jXXCIhbaZz7xaCZl-YmA
如何处理不均衡数据?
https://mp.weixin.qq.com/s/2j_6hdq-MhybO_B0S7DRCA
如何解决机器学习中数据不平衡问题
https://mp.weixin.qq.com/s/gEq7opXLukWD5MVhw_buGA
七招教你处理非平衡数据
http://blog.csdn.net/u013709270/article/details/72967462
机器学习中的数据不平衡解决方案大全
https://mlr-org.github.io/mlr-tutorial/devel/html/over_and_undersampling/index.html
Imbalanced Classification Problems
https://mp.weixin.qq.com/s/QEHAV_rW25E0b0N7POr6tw
关于处理样本不平衡问题的Trick整理
https://mp.weixin.qq.com/s/5csfnBWZ2MQsnWZnNj9b8w
机器学习中样本比例不平衡的处理方法
https://mp.weixin.qq.com/s/ZL6UWrBB7qr8jp2QRA1MAQ
方法总结:教你处理机器学习中不平衡类问题
https://mp.weixin.qq.com/s/V5d3kbpXBf4883TQ_sq37A
遇到有这六大缺陷的数据集该怎么办?这有一份数据处理急救包
https://mp.weixin.qq.com/s/zLgD8DjnW1DfeqL_xITisQ
教你如何用python解决非平衡数据建模
https://mp.weixin.qq.com/s/ElOFb0Ln4qyG1x38NRFyag
如何处理数据不均衡问题
https://mp.weixin.qq.com/s/DxkHjArbr5XRdEGVNjJAKA
在深度学习中处理不均衡数据集
https://mp.weixin.qq.com/s/x48Ctb0_Eu1kcSGTYLt5BQ
机器学习中如何处理不平衡数据?
https://mp.weixin.qq.com/s/a57oy26UvLFNj4T8_pddCQ
关于图像分类中类别不平衡那些事
https://mp.weixin.qq.com/s/rXaicHuHlWegrpeulYmduw
目标检测中的不平衡问题综述
https://mp.weixin.qq.com/s/7_-SSVZpxLfnwn7EmbGyZA
极端类别不平衡数据下的分类问题研究综述
https://mp.weixin.qq.com/s/fAHlrfchgkQ1Wuc8sfTlZg
堪比Focal Loss!解决目标检测中样本不平衡的无采样方法
https://zhuanlan.zhihu.com/p/259710601
数据类别不平衡/长尾分布?不妨利用半监督或自监督学习
https://mp.weixin.qq.com/s/4gLlCmmw3GK_Sbt_BXXEKQ
使用遗传交叉算子进行过采样处理数据不平衡
https://mp.weixin.qq.com/s/gZio0rdg8KmU1rokTOBjqQ
通过随机采样和数据增强来解决数据不平衡的问题

您的打赏,是对我的鼓励
