ML » 机器学习(二十五)——Tri-training, simhash, LSH
2017-06-19 :: 4986 Words单分类SVM&多分类SVM(续)
Hinge Loss
在之前的SVM的推导中,我们主要是从解析几何的角度,给出了SVM的计算公式。但SVM实际上也是有loss function的:
\[\ell(y) = \max(0, 1-t \cdot y)\]其中,\(t=\pm 1\)表示分类标签,\(y=w \cdot x+b\)表示分类超平面计算的score。可以看出当t和y有相同的符号时(意味着 y 预测出正确的分类),loss为0。反之,则会根据y线性增加one-sided error。
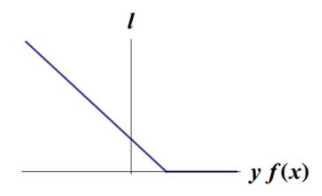
由于其函数形状像个合叶,因此又名Hinge Loss函数。
多分类SVM的Hinge Loss公式:
\[\ell(y) = \sum_{t \ne y} \max(0, 1 + \mathbf{w}_t \mathbf{x} - \mathbf{w}_y \mathbf{x})\]参见:
http://www.jianshu.com/p/4a40f90f0d98
Hinge loss
http://mp.weixin.qq.com/s/96_u9QM63SISwTbimmH6wA
支持向量回归机
https://mp.weixin.qq.com/s/0yvu3oG7YXUdeQz4QwEJ-A
线性分类原来是这么一回事
https://mp.weixin.qq.com/s/1ZNCbj5kMFENzP_SapQYgg
Softmax分类及与SVM比较
https://mp.weixin.qq.com/s/j_LzPcESaou0FOS2Z4f3kA
关于SVM,面试官们都怎么问
数据不平衡问题
SVM中超参数C决定了错误分类的惩罚值,为了处理不平衡类别的问题,我们可以给C按类加权重:
\[C_k=C*W_k\]其中,权值和类别K出现的频率成反比。
Platt scaling
https://blog.csdn.net/giskun/article/details/49329095
SVM的概率输出(Platt scaling)
Tri-training
半监督学习
之前提到的算法,多数都属于监督学习算法。其特点在于,构建一个包含标记数据的训练集,用来训练算法模型。
然而,获得标记数据是一个费时费力的高成本过程,实际工作中,更有可能的情况是:少量标记数据+大量未标记数据。
未标记数据的处理方式,一般有如下三种:
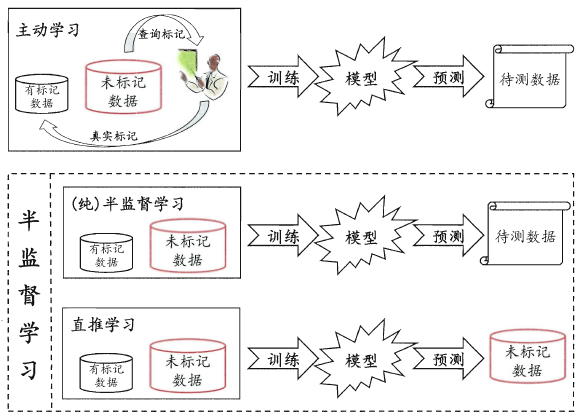
主动学习
1.根据标记数据生成一个简单的模型A。
2.挑出对改善模型性能帮助最大的样本数据B。
3.通过查询行业专家获得B的真实标记。
4.根据B的真实标记,更新模型A。
以SVM为例,对于改善模型性能帮助最大的样本往往是位于分类边界的样本,可将这些样本挑出来,查询它的标记。
参考:
https://mp.weixin.qq.com/s/9pGfdn3cAT7G5-TNWwg_qg
主动学习(ACTIVE LEARNING)
纯半监督学习和推断学习
纯半监督学习和推断学习,都属于广义上的半监督学习。和主动学习不同,半监督学习无需专家提供的外部信息。
但标记数据总归不能无中生有,半监督学习的实现有赖于若干假设,其中主要有聚类假设和流形假设两种。其本质都是“相似的样本拥有相似的输出”。
纯半监督学习假定未标记数据为训练样本集,而推断学习则认为未标记数据为测试样本集。
虽然多数情况下,半监督学习能有效提升模型的泛化性能,然而这并不是绝对的。当半监督学习之后,模型的泛化性能反而下降时,我们首先需要检查数据是否满足算法所依赖的假设。
参考:
http://www.cnblogs.com/chaosimple/p/3147974.html
半监督学习
协同训练算法
协同训练(co-training)算法是一种多学习器的半监督学习算法。它是多视图(multi-view)学习的代表。
以电影为例,它拥有多个属性集:图像、声音、字幕等。每个属性集就构成了一个视图。
协同训练假设不同的视图具有“相容性”。所谓相容性是指,如果一个电影从图像判断,像是动作片,那么从声音判断,也有很大可能是动作片。
协同训练的算法流程:
1.在每个视图上,基于有标记数据,分别训练出一个分类器。
2.每个分类器挑选自己最有把握的未标记数据,赋予伪标记。
3.其他分类器利用伪标记,进一步训练模型,最终达到相互促进的目的。
理论上,如果不同视图之间具有完全相容性,则模型准确度可达到任意上限。而实际中,虽然很难满足完全相容性假设,但该算法仍能有效提升模型的准确度。
原始的协同训练算法的主要局限在于,构造视图在工程上是件很有难度的事情。后续的一些改进算法针对这点,在应用范围上做了不少改进。如基于不同学习算法、不同的数据采样、不同的参数设置的协同训练算法。
理论研究表明,只要弱学习器之间具有显著分歧(或差异),即可通过相互提供伪标记的方式提升泛化性能。因此,协同训练算法又被称为基于分歧的算法。
Tri-training
2005年,周志华提出了Tri-training算法。该算法的流程如下:
1.首先对有标记示例集进行可重复取样(bootstrap sampling)以获得三个有标记训练集,然后从每个训练集产生一个分类器。
2.在协同训练过程中,各分类器所获得的新标记示例都由其余两个分类器协作提供,具体来说,如果两个分类器对同一个未标记示例的预测相同,则该示例就被认为具有较高的标记置信度,并在标记后被加入第三个分类器的有标记训练集。
参考:
http://www.cnblogs.com/liqizhou/archive/2012/05/11/2496162.html
Tri-training, 协同训练算法
Co-Forest & Co-Trade
Co-Forest & Co-Trade是周志华在Tri-training基础上的改进算法。
参考:
http://lamda.nju.edu.cn/huangsj/dm11/files/gaoy.pdf
半监督学习中的几种协同训练算法
simhash
simhash是一种能计算文档相似度的hash算法。
论文:
《Similarity Estimation Techniques from Rounding Algorithms》
《Detecting Near-Duplicates for Web Crawling》
代码:
https://github.com/yanyiwu/simhash
类似的相似度Hash算法,还有用于图像搜索的aHash、pHash、dHash。
参考:
https://www.biaodianfu.com/simhash.html
文本内容相似度计算方法:simhash
http://www.cnblogs.com/chenwenbiao/archive/2011/09/12/2174139.html
simhash算法的原理
http://www.cnblogs.com/chenwenbiao/archive/2011/09/12/2174137.html
simhash与Google的网页去重
http://blog.jobbole.com/21928/
Simhash算法原理和网页查重应用
https://blog.csdn.net/luoweifu/article/details/8220992
看起来像它——图像搜索其实也不难
https://www.jianshu.com/p/193f0089b7a2
相似图片检测:感知哈希算法之dHash的Python实现
https://mp.weixin.qq.com/s/vwhetMpQllczILptBNcoWg
基于快速GeoHash,如何实现海量商品与商圈的高效匹配?
LSH
论文:
《Approximate nearest neighbors: towards removing the curse of dimensionality》
《Similarity Search in High Dimensions via Hashing》
说到Hash,大家都很熟悉,是一种典型的Key-Value结构,最常见的算法莫过于MD5。其设计思想是使Key集合中的任意关键字能够尽可能均匀的变换到Value空间中,不同的Key对应不同的Value,即使Key值只有轻微变化,Value值也会发生很大地变化。这样特性可以作为文件的唯一标识,在做下载校验时我们就使用了这个特性。
但是有没有这样一种Hash呢?他能够使相似Key值计算出的Value值相同或在某种度量下相近呢?甚至得到的Value值能够保留原始文件的信息,这样相同或相近的文件能够以Hash的方式被快速检索出来,或用作快速的相似性比对。位置敏感哈希(Local Sensitive Hashing, LSH)正好满足了这种需求。
相似性检索在各种领域特别是在视频、音频、图像、文本等含有丰富特征信息领域中的应用变得越来越重要。丰富的特征信息一般用高维向量表示,由此相似性检索一般通过K近邻或近似近邻查询来实现。
传统主要方法是基于空间划分的算法——tree类似算法,如R-tree,Kd-tree,SR-tree。这种算法返回的结果是精确的,但是这种算法在高维数据集上的时间效率并不高。实验指出维度高于10之后,基于空间划分的算法时间复杂度反而不如线性查找。LSH方法能够在保证一定程度上的准确性的前提下,时间和空间复杂度得到降低,并且能够很好地支持高维数据的检索。
参考:
http://blog.csdn.net/icvpr/article/details/12342159
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍
https://blog.csdn.net/guoziqing506/article/details/53019049
LSH(Locality Sensitive Hashing)原理与实现
https://www.cnblogs.com/wt869054461/p/9234184.html
局部敏感哈希-Locality Sensitivity Hashing
https://blog.csdn.net/yc461515457/article/details/48845775
局部敏感哈希LSH(Locality Sensitive Hashing)
https://blog.csdn.net/baidu_21807307/article/details/51794373
局部敏感哈希深度解析(locality-sensetive hashing, LSH)
K-D Tree
K-Dimensional Tree
https://mp.weixin.qq.com/s/pkqC8phkYDZhLvMaDNaHkg
空间连接运算与空间索引
https://blog.csdn.net/acdreamers/article/details/44664645
K-D树
SR-tree
sphere/rectangle-tree
https://wenku.baidu.com/view/22416a14b94ae45c3b3567ec102de2bd9605de83.html
基于SR-树的空间对象最近邻查询
GRASS GIS
一个开源的GIS软件。
官网:
https://grass.osgeo.org/
上面列举的这些空间搜索算法,在该软件中都有实现。

您的打赏,是对我的鼓励
