ML » 机器学习(二十四)——Learning Rate, 单分类SVM&多分类SVM
2017-06-18 :: 5710 WordsOptimizer
Muon(续)
这里msign是矩阵符号函数,它并不是简单地对矩阵每个分量取sign操作,而是sign函数的矩阵化推广,它跟SVD的关系是:
\[\begin{equation}\boldsymbol{U},\boldsymbol{\Sigma},\boldsymbol{V}^{\top} = \text{SVD}(\boldsymbol{M}) \quad\Rightarrow\quad \text{msign}(\boldsymbol{M}) = \boldsymbol{U}_{[:,:r]}\boldsymbol{V}_{[:,:r]}^{\top}\end{equation}\]实践中,如果每一步都对M做SVD来求解\(msign(M)\)的话,那么计算成本还是比较大的,因此作者提出了用Newton-schulz迭代来近似计算\(msign(M)\)。
Muon是为了matrix设计的,因此非matrix参数word embedding,lm head,rmsnorm gamma都是用AdamW进行更新的。
Muon在大模型训练时不够稳定,会有MaxLogit爆炸的问题,除了常规的Weight Decay之外,还要配合QK-Clip等算法。
参考:
https://kexue.fm/archives/10592
Muon优化器赏析:从向量到矩阵的本质跨越
https://kexue.fm/archives/11126
QK-Clip:让Muon在Scaleup之路上更进一步
参考
http://sebastianruder.com/optimizing-gradient-descent/
An overview of gradient descent optimization algorithms
https://mp.weixin.qq.com/s/k_d02G2V4yd6HdGfw2mf1Q
从修正Adam到理解泛化:概览2017年深度学习优化算法的最新研究进展
https://mp.weixin.qq.com/s/cOCCapYrmrS_DyPkj_XRlg
常见的几种最优化方法
https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/3-06-speed-up-learning/
加速神经网络训练
http://www.cnblogs.com/neopenx/p/4768388.html
自适应学习率调整:AdaDelta
https://mp.weixin.qq.com/s/VoBK-l_ieSg2UupC2ix2pA
听说你了解深度学习最常用的学习算法:Adam优化算法?
https://mp.weixin.qq.com/s/YRyqvlNe24mlFZ7GB9vDnw
一文看懂常用的梯度下降算法
https://mp.weixin.qq.com/s/qncTSBCvjMzAual5Sz9R3A
解析深度学习优化:Momentum、RMSProp和Adam
https://mp.weixin.qq.com/s/q7BI-YyhtmNzUfBMTKVdqQ
Hitting time analysis of SGLD!
https://mp.weixin.qq.com/s/vt7BEHbwJrAzlL2Pc-6QFg
掌握机器学习数学基础之优化(上)
https://mp.weixin.qq.com/s/6NBLLLa-S625iaehR8zDfQ
掌握机器学习数学基础之优化(下)
https://zhuanlan.zhihu.com/p/73441350
从物理角度理解加速梯度下降
https://mp.weixin.qq.com/s/n1Ks8I3Ldgb-u-kVbGBZ5Q
机器学习中的优化方法
https://mp.weixin.qq.com/s/4XOI8Dq6fqe8rhtJjeyxeA
超级收敛:使用超大学习率超快速训练残差网络
http://mp.weixin.qq.com/s/Q5kBCNZs3a6oiznC9-2bVg
Michael Jordan新研究官方解读:如何有效地避开鞍点
https://mp.weixin.qq.com/s/idmt0F49tOCh-ghWdHLdUw
吴恩达导师Michael I.Jordan学术演讲:如何有效避开鞍点。这是Jordan半年后的另一个演讲,有些新内容。
https://mp.weixin.qq.com/s/jVjemfcLzIWOdWdxMgoxsA
超越Adam,从适应性学习率家族出发解读ICLR 2018高分论文
https://mp.weixin.qq.com/s/dseeCB-CRtZnzC3d4_8pYw
AMSGrad能够取代Adam吗
https://zhuanlan.zhihu.com/p/81020717
从SGD到NadaMax,十种优化算法原理及实现
https://zhuanlan.zhihu.com/p/22252270
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
https://www.zhihu.com/question/64134994
如何理解深度学习分布式训练中的large batch size与learning rate的关系?
https://mp.weixin.qq.com/s/2wolhiTrWVeaSHxOpalUZg
深度学习中的优化算法串讲
Learning Rate
Optimizer主要解决的是梯度下降的方向,而Learning Rate则是确定梯度下降的步长。
虽然许多常见的Optimizer策略,实际上也包含了相应的Learning Rate的策略,但是两者毕竟是不同的两件事情,有些Learning Rate的策略,可以和不同的Optimizer搭配使用。
本节就讲述一下这些Learning Rate的策略。
某些Optimizer的cycle参数。它的效果如下所示:
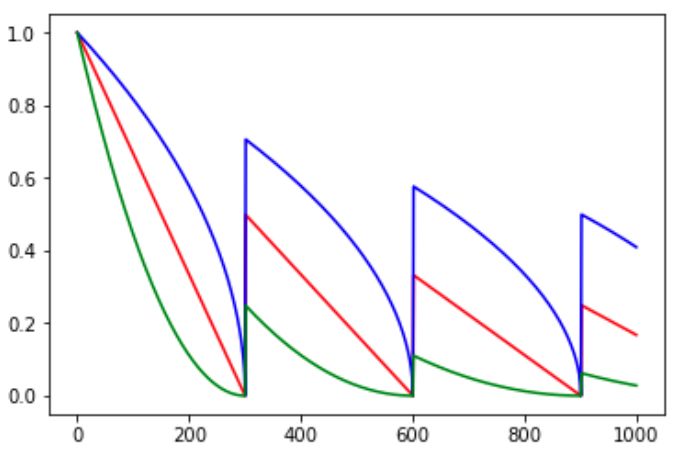
cycle参数的初衷是为了防止训练后期LR十分小,导致结果一直在某个局部最小值附近振荡。突然调大LR可以跳出注定不会继续增长的区域探索其他区域。
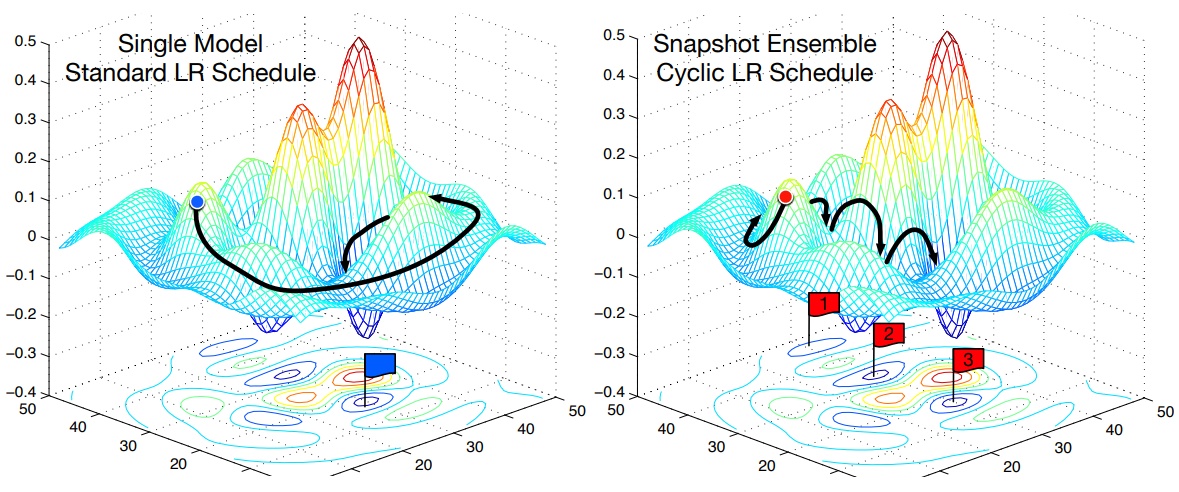
上图展示了Cyclic LR的另一种用法:
每隔一段时间重启学习率,这样在单位时间内能收敛到多个局部最小值,从而得到很多个模型做集成。
在训练深度学习模型时,特别是在训练初期,直接从一个很高的学习率开始可能会导致模型权重更新过大,从而使训练不稳定。相反,从一个很低的学习率开始可能会导致训练进度缓慢。为了解决这个问题,warmup策略在训练的初期使用一个逐渐增加的学习率,从较低的学习率开始,逐渐“预热”到预定的最高学习率,这个过程称为“warmup”。
参考:
https://mp.weixin.qq.com/s/4hSar7SuCjLkZUjuIfu1Lg
如何选择最适合你的学习率变更策略
https://zhuanlan.zhihu.com/p/32923584
Tensorflow中learning rate decay的奇技淫巧
https://mp.weixin.qq.com/s/B9nUwPtgpsLkEyCOlSAO5A
1cycle策略:实践中的学习率设定应该是先增再降
https://mp.weixin.qq.com/s/o10Fp2VCwoLqgzirbGL9LQ
如何估算深度神经网络的最优学习率
https://zhuanlan.zhihu.com/p/261134624
pytorch的余弦退火学习率
https://mp.weixin.qq.com/s/XD0eyKiBgsqmcucIsW20uw
了解学习率及其如何提高深度学习的性能
单分类SVM&多分类SVM
原始的SVM主要用于二分类,然而稍加变化,也可用于单分类和多分类。
单分类SVM
单分类任务是一类特殊的分类任务。在该任务中,大多数样本只有positive一类标签,而其他样本则笼统的划为另一类。
单分类SVM(也叫Support Vector Domain Description(SVDD))是一种单分类算法。和普通SVM相比,它不再使用maximum margin了,因为这里并没有两类的data。
单分类SVM的目标,实际上是确定positive样本的boundary。boundary之外的数据,会被分为另一类。这实际上就是一种异常检测的算法了。它主要适用于negative样本的特征不容易确定的场景。
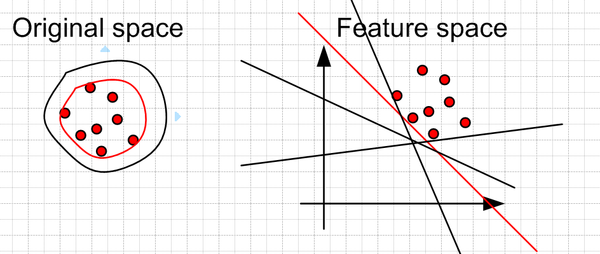
这里可以假设最好的boundary要远离feature space中的原点。左边是在original space中的boundary,可以看到有很多的boundary都符合要求,但是比较靠谱的是找一个比较紧(closeness)的boundary(红色的)。这个目标转换到feature space就是找一个离原点比较远的boundary,同样是红色的直线。
当然这些约束条件都是人为加上去的,你可以按照你自己的需要采取相应的约束条件。比如让data的中心离原点最远。
下面我们讨论一下SVDD的算法实现。
首先定义需要最小化的目标函数:
\[\begin{align} &\operatorname{min}& & F(R,a,\xi_i) = R^2 + C \sum_{i=1}^N \xi_i\\ &\operatorname{s.t.}& & (x_i - a)^T (x_i - a) \leq R^2 + \xi_i\text{,} \qquad \xi_i \geq 0 \end{align}\]这里a表示形状的中心,R表示半径,C和\(\xi\)的含义与普通SVM相同。
Lagrangian算子:
\[L(R,a,\alpha_i,\xi_i) = R^2 + C \sum_{i=1}^N \xi_i - \sum_{i=1}^N \gamma_i \xi_i - \sum_{i=1}^N \alpha_i \left( R^2 + \xi_i - (x_i - c)^T (x_i - c) \right)\]对偶问题:
\[L = \sum_{i=1}^N \alpha_i (x_i^T \cdot x_i) - \sum_{i,j=1}^N \alpha_i \alpha_j (x_i^T \cdot x_i)\]使用核函数:
\[L = \sum_{i=1}^N \alpha_i K(x_i,x_i) - \sum_{i,j=1}^N \alpha_i \alpha_j K(x_i,x_j)\]预测函数:
\[y(x) = \sum_{i=1}^N \alpha_i K(x,x_n) + b\]根据计算结果的符号,来判定是正常样本,还是异常样本。
参考:
https://www.projectrhea.org/rhea/index.php/One_class_svm
One-Class Support Vector Machines for Anomaly Detection
https://www.zhihu.com/question/22365729
什么是一类支持向量机(one class SVM)
https://mp.weixin.qq.com/s/04rKUq2q70iyvgOEWQMs0g
20年单类别(One-Class)分类全面综述论文,从2001到2020
多分类SVM
多分类任务除了使用多分类算法之外,也可以通过对两分类算法的组合来实施多分类。常用的方法有两种:one-against-rest和DAG SVM。
one-against-rest
比如我们有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的;第二次我们把类别2的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。
但有时也会出现两种很尴尬的情况,例如拿一篇文章问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。
分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个。不可分类现象就着实难办了,只能把它分给第6个类别了……
更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了“数据集偏斜”问题。
DAG SVM
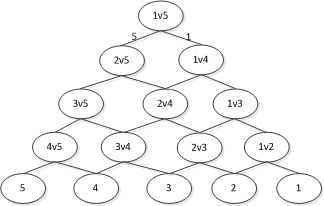
DAG SVM(也称one-against-one)的分类思路如上图所示。
粗看起来DAG SVM的分类次数远超one-against-rest,然而由于每次分类都只使用了部分数据,因此,DAG SVM的计算量反而更小。
其次,DAG SVM的误差上限有理论保障,而one-against-rest则不然(准确率可能降为0)。
显然,上面提到的两种方法,不仅可用于SVM,也适用于其他二分类算法。
参考:
http://www.blogjava.net/zhenandaci/archive/2009/03/26/262113.html
将SVM用于多类分类

您的打赏,是对我的鼓励
