ML » 机器学习(二十二)——NLP常用评价度量, Tokenization, 机器学习分类器性能指标
2017-05-20 :: 5483 WordsNLP常用评价度量
机器翻译的评价指标主要有:BLEU、NIST、Rouge、METEOR等。
参考:
http://blog.csdn.net/joshuaxx316/article/details/58696552
BLEU,ROUGE,METEOR,ROUGE-浅述自然语言处理机器翻译常用评价度量
http://blog.csdn.net/guolindonggld/article/details/56966200
机器翻译评价指标之BLEU
https://mp.weixin.qq.com/s/niVOM-lnzI2-Tgxn8Qterw
NLP中评价文本输出都有哪些方法?为什么要小心使用BLEU?
http://blog.csdn.net/han_xiaoyang/article/details/10118517
机器翻译评估标准介绍和计算方法
http://blog.csdn.net/lcj369387335/article/details/69845385
自动文档摘要评价方法—Edmundson和ROUGE
https://mp.weixin.qq.com/s/XiZ6Uc5cHZjczn-qoupQnA
对话系统评价方法综述
https://zhuanlan.zhihu.com/p/33088748
数据集和评价指标介绍
https://mp.weixin.qq.com/s/9hoM_yF96XxSbQHEP6oasw
怎样生成语言才能更自然,斯坦福提出超越Perplexity的评估新方法
https://mp.weixin.qq.com/s/TnAZUjFSn7ATtRmBexJlXw
文本生成评价方法BLEU ROUGE CIDEr SPICE Perplexity METEOR
https://mp.weixin.qq.com/s/n4OnRGkrn5DYuZUmmrmzpg
NLG任务评价指标BLEU与ROUGE
https://zhuanlan.zhihu.com/p/445450292
为什么bleu不是一个完美的文本生成评测指标
LLM评估
https://zhuanlan.zhihu.com/p/677583745
评估大模型快速入门:用MMLU评估 GPT-3
https://zhuanlan.zhihu.com/p/656260901
TruthfulQA: Measuring How Models Mimic Human Falsehoods - 事实性评估
https://github.com/CLUEbenchmark/SuperCLUE
中文通用大模型综合性基准
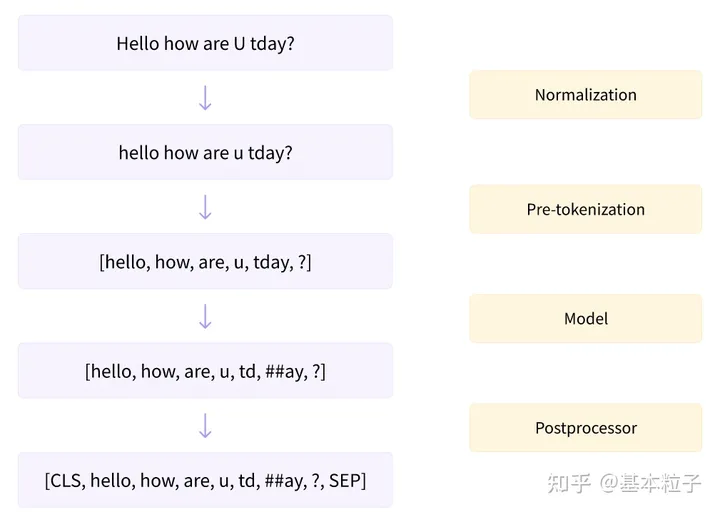
Tokenization
Tokenization vs. embedding
Tokenization是给文本矢量化的一种基本形式。它们并不能捕捉到token之间任何更深层次的关系或模式。
Embedding是词块的高级向量表示。它们试图捕捉词块之间最细微的差别、联系和语义。
https://mp.weixin.qq.com/s/vf3XKV1cg2H2MxS_6czfFQ
关于LLM:揭秘token与embedding的机制
Subword
对于英文来说,文字的粒度从细到粗依次是character, subword, word。character和word都很好理解,分别是字母和单词。而subword相当于英文中的词根、前缀、后缀等。
之前的Neural Machine Translation基本上都是基于word单词作为基本单位的,但是其缺点是不能很好的解决out-of-vocabulary即单词不在词汇库里的情况,且对于单词的一些词法上的修饰(morphology)处理的也不是很好。一个自然的想法就是能够利用比word更基本的组成来建立模型,以更好的解决这些问题。
参考:
https://plmsmile.github.io/2017/10/19/subword-units/
subword-units
https://zhuanlan.zhihu.com/p/69414965
Subword模型
https://zhuanlan.zhihu.com/p/86965595
深入理解NLP Subword算法:BPE、WordPiece、ULM
https://mp.weixin.qq.com/s/la3nZNFDviRcSFNVso29oQ
NLP三大Subword模型详解:BPE、WordPiece、ULM
https://mp.weixin.qq.com/s/TPRqDyGpkVuJcgomTu774A
子词技巧:The Tricks of Subword
https://mp.weixin.qq.com/s/fe7-wimFCAtp3ohB3TVywg
通俗讲解Subword Models
https://mp.weixin.qq.com/s/5z3CMmIR0U9-p2BwJnsYKg
神经机器翻译的Subword技术
BPE
Byte Pair Encoding(BPE)本来是一种数据压缩算法,后来被用于分词。它从命名实体、同根词、外来语、组合词(罕见词有相当大比例是上述几种)的翻译策略中得到启发,认为把这些罕见词拆分为“子词单元”(subword units)的组合,可以有效的缓解NMT的OOV和罕见词翻译的问题。BPE对英文、德文、俄文等表音文字效果较好,但不太适用于中文。
论文:
《Neural Machine Translation of Rare Words with Subword Units》
代码:
https://github.com/rsennrich/subword-nmt
BPE算法的各种实现中,以OpenAI开源的tiktoken库较快:
https://github.com/openai/tiktoken
Byte-level BPE(BBPE)和Byte-Pair Encoding (BPE)的区别:
BPE是最小词汇是字符级别,而BBPE是字节级别的,通过UTF-8编码方式,理论上可以表示这个世界上的所有字符。
参考:
https://www.cnblogs.com/huangyc/p/10223075.html
一文读懂BERT中的WordPiece
https://mp.weixin.qq.com/s/OGBk_ZptFzbjKdnv2RVZFA
机器如何认识文本?NLP中的Tokenization方法总结
https://zhuanlan.zhihu.com/p/652520262
LLM大语言模型之Tokenization分词方法(WordPiece,Byte-Pair Encoding (BPE),Byte-level BPE(BBPE)原理及其代码实现)
机器学习分类器性能指标
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类。这个实值或概率预测结果的好坏,直接决定了学习器的泛化能力。实际上,根据这个实值或概率预测结果,我们可将测试样本进行排序,“最可能”是正例的排在最前面,“最不可能”是正例的排在最后面。这样,分类过程就相当于在这个排序中以某个“截断点”(cut point)将样本分为两部分,前一部分判作正例,后一部分则判作反例。
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若我们更重视 “查准率”(precision),则可选择排序中靠前的位置进行截断,若更重视“查全率”(recall,也称召回率),则可选择靠后的位置进行截断。
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)和假反例(false negative)。
查准率P和查全率R的定义如下:
\[P=\frac{TP}{TP+FP},R=\frac{TP}{TP+FN}\]以P和R为坐标轴,所形成的曲线就是P-R曲线。曲线下方的面积一般称为AP(Average Precision)。
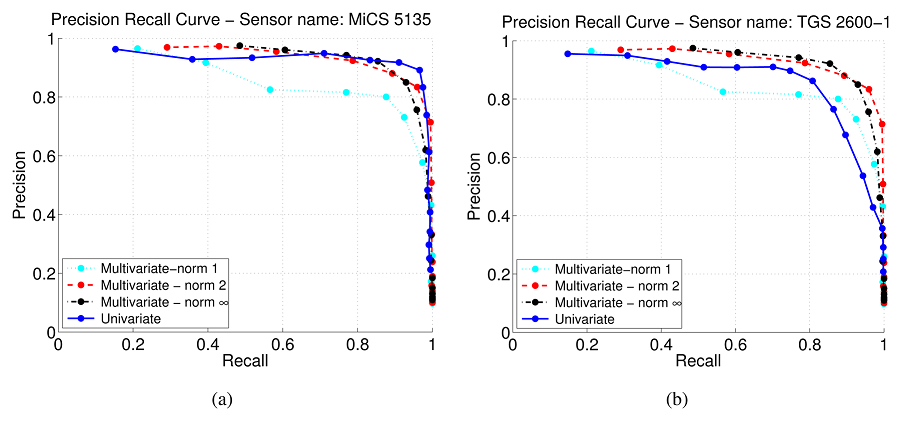
注意:
1.测试样本的排序过程非常重要。不然P-R曲线的峰值可能出现在图形的中部。
2.虽然P-R曲线总体上是个下降曲线,但不是严格的单调下降曲线。在局部,会由于TP样本的增多,使P值升高。
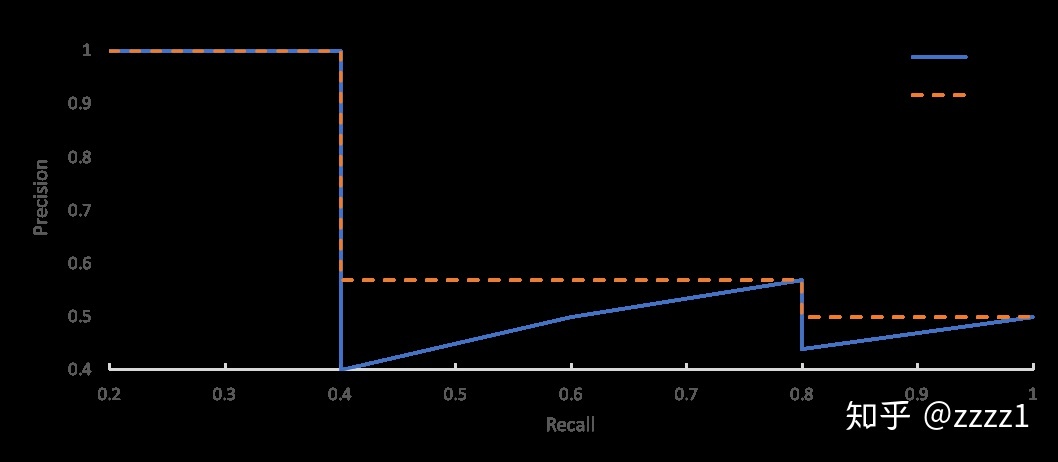
3.有的评测为了使P-R曲线成为单调下降曲线,对原始定义进行了细微修改(如下图所示):\(P(r_0)=\max (P(r\mid r \ge r_0))\)
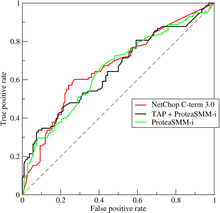
ROC(Receiver operating characteristic)曲线的纵轴是真正例率(True Positive Rate,TPR),横轴是假正例率(False Positive Rate,FPR)。其定义如下:
\[TPR=\frac{TP}{TP+FN},FPR=\frac{FP}{TN+FP}\]ROC曲线下方的面积被称为AUC(Area Under ROC Curve)。
更多内容参见下图:
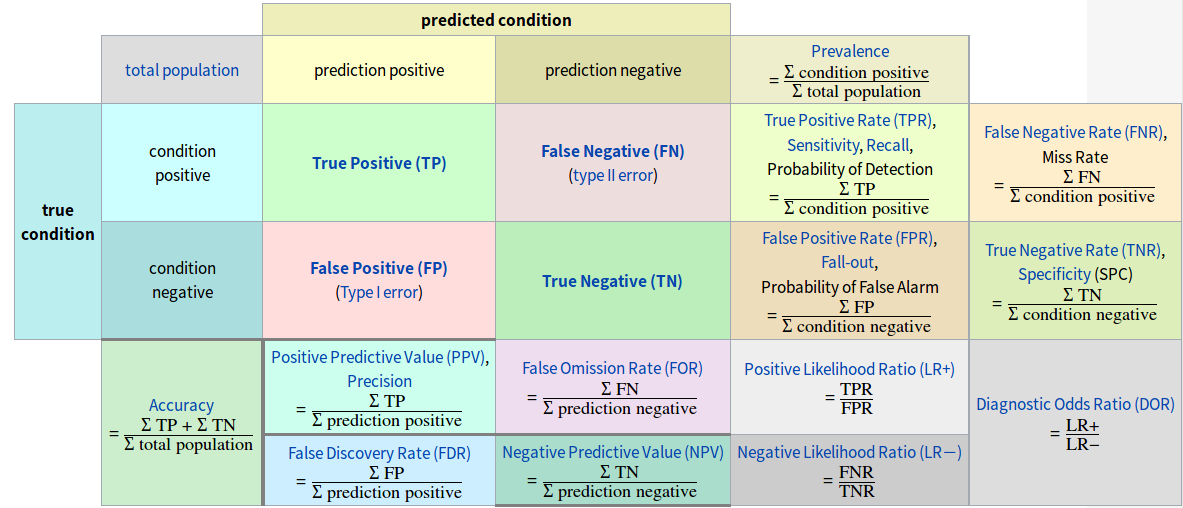
原图地址:
https://en.wikipedia.org/wiki/Sensitivity_and_specificity
从这张图表衍生出一种数据可视化方式——confusion matrix:
除此之外,还有F-measure:
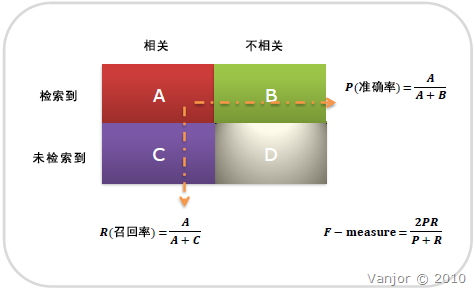
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回率。所以,在两者都要求高的情况下,可以用F-measure来衡量。
虽然precision、recall和F1为我们提供了一个单值度量,但它们不考虑返回的搜索结果的顺序。为了解决这一局限性,人们设计了以下排序感知的度量标准:
Mean Reciprocal Rank(MRR)
Average Precision(AP)
Mean Average Precision(MAP)
Accuracy和Precision是一对容易混淆的概念。其一般定义如下图所示:

当然,这个定义和机器学习中的定义无关,主要用于物理和统计领域。
这里再提几个和上述概念类似的ML术语。
Ground truth:在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注。正确的t标注是ground truth, 错误的标记则不是。(也有人将所有标注数据都叫做ground truth)
由于使用错误的数据,对模型的估计比实际要糟糕,因此使用高质量的数据是很有必要的。
Golden:Golden这个术语的使用范围并不局限于ML领域,凡是能够给出“标准答案”的地方,都可以将该答案称为Golden。
比如在DL领域的硬件优化中,通常使用标准算法生成Golden结果,然后用优化之后的运算结果与之比对,以验证优化的正确性。
上述内容中,预测结果和标签之间只有真和假两种关系,因此又被称为二元相关性问题。
类似的还有分等级的相关性问题。例如,我们有一个排序模型,它会为一个特定的查询返回5个最相关的结果。这时预测结果和ground-truth之间就不是简单的真和假的关系了。
比如,预测结果的第一名虽然不是ground-truth的第一名,但却是ground-truth的第二名。这样的话,显然就不能直接否定预测结果了。
评估这类问题,可以采用如下度量:
Cumulative Gain
Discounted Cumulative Gain
Normalized Discounted Cumulative Gain
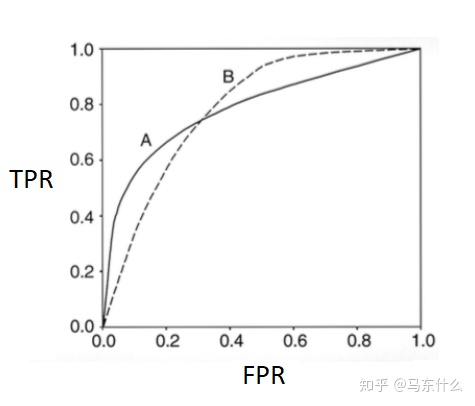
如图,modelA和modelB的ROC曲线下面积AUC是相等的,但是两个模型在不同区域的预测能力是不相同的,所以我们不能单纯根据AUC的大小来判断模型的好坏。
参考:
https://mp.weixin.qq.com/s/5nnHBKEToepi3dhXLfQBtw
机器学习分类器性能指标详解
https://mp.weixin.qq.com/s/6eESoUvMObXSb2jy_KPRyg
如何评价我们分类模型的性能?
https://mp.weixin.qq.com/s/mOYUCc3xKMfVw81B6zSeNw
7种最常用的机器学习算法衡量指标
https://mp.weixin.qq.com/s/zvxB6VqrSOosgGSViCmjEQ
不止准确率:为分类任务选择正确的机器学习度量指标
https://mp.weixin.qq.com/s/2HKx36bIBZAqvzdXfcSfqA
我们常听说的置信区间与置信度到底是什么?
https://mp.weixin.qq.com/s/Uowbo19wNkjT-9eAIjS8jQ
过来,我这里有个“混淆矩阵”跟你谈一谈
https://mp.weixin.qq.com/s/u-QTHFSA-8rwvL0KBVYXjQ
深度学习模型评估,从图像分类到生成模型
https://mp.weixin.qq.com/s/sKiAwLoxdP9yyZX0-R4UrA
一文读懂AUC-ROC

您的打赏,是对我的鼓励
