ML » 机器学习(二十一)——NLP历史
2017-05-15 :: 7097 WordsLoss function详解
Triplet Loss(续)
针对每个样本\(x_i\),训练一个参数共享或者不共享的网络,得到三个元素的特征表达,分别记为:\(f(x_i^a), f(x_i^p), f(x_i^n)\)。
triplet loss的目的就是通过学习(即上图中的Learning),让\(x^a\)和\(x^p\)特征表达之间的距离尽可能小,而\(x^a\)和\(x^n\)的特征表达之间的距离尽可能大。
它的公式化的表示就是:
\[\|f(x_i^a)-f(x_i^p)\|_2^2 + \alpha < \|f(x_i^a)-f(x_i^n)\|_2^2\]其中,\(\alpha\)表示两个距离之间的间隔。因此,对应的目标函数也就很清楚了:
\[\sum_i^N\left[\|f(x_i^a)-f(x_i^p)\|_2^2 - \|f(x_i^a)-f(x_i^n)\|_2^2 + \alpha \right]_+\]这里距离用欧式距离度量,+表示[]内的值大于零的时候,取该值为损失,小于零的时候,损失为零。
需要注意的是Triplet Loss以及后面介绍的各种改进版softmax,其收敛速度不如softmax,因此,先用softmax训练几轮,再改用这些loss,也是常用的调参技巧。
参考:
https://blog.csdn.net/u010167269/article/details/52027378
Triplet Loss、Coupled Cluster Loss探究
https://blog.csdn.net/tangwei2014/article/details/46788025
triplet loss原理以及梯度推导
https://www.zhihu.com/question/62486208
triplet loss在深度学习中主要应用在什么地方?有什么明显的优势?
https://mp.weixin.qq.com/s/XB9VsW3NRwHua6AdRL3n8w
Lossless Triplet Loss:一种高效的Siamese网络损失函数
https://gehaocool.github.io/2018/03/20/Angular-Margin-%E5%9C%A8%E4%BA%BA%E8%84%B8%E8%AF%86%E5%88%AB%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
Angular Margin在人脸识别中的应用
https://mp.weixin.qq.com/s/SqaR_7gwJpUNPM7g4IHaYw
深度人脸识别中不同损失函数的性能对比
https://zhuanlan.zhihu.com/p/138850070
从Triplet loss看推荐系统中文章Embedding
https://mp.weixin.qq.com/s/tpI5k5sg15WHGv3YoMp-rA
Triplet-loss原理与应用
https://zhuanlan.zhihu.com/p/295512971
完全解析triplet loss
Coupled Cluster Loss
论文:
《Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles》
参考:
https://blog.csdn.net/u010167269/article/details/51783446
论文中文笔记
Focal Loss
https://zhuanlan.zhihu.com/p/28442066
何恺明团队提出Focal Loss,目标检测精度高达39.1AP,打破现有记录
https://www.zhihu.com/question/63581984
如何评价Kaiming的Focal Loss for Dense Object Detection?
https://mp.weixin.qq.com/s/Uf1lWtxOpKYCDLmCDlnVAQ
把Cross Entropy梯度分布拉‘平’,就能轻松超越Focal Loss
https://mp.weixin.qq.com/s/aKRUJt-_1QSQFcRVtuyJ4w
被忽略的Focal Loss变种
https://zhuanlan.zhihu.com/p/55036597
样本贡献不均:Focal Loss和Gradient Harmonizing Mechanism
https://mp.weixin.qq.com/s/LfCuOEndS4Y5dPqXTsE_hA
剖析Focal Loss损失函数: 消除类别不平衡+挖掘难分样本
https://mp.weixin.qq.com/s/Ryxu1qsmL_Roi5zDb1KSRQ
AP-Loss:提高单阶段目标检测性能的分类损失,超越Focal loss
https://mp.weixin.qq.com/s/lzb-R0CQ3YRY4a8WBbdOhw
Focal Loss详解以及为什么能够提高处理不平衡数据分类的表现
https://zhuanlan.zhihu.com/p/147691786
大白话Generalized Focal Loss
https://zhuanlan.zhihu.com/p/313684358
大白话Generalized Focal Loss V2
https://mp.weixin.qq.com/s/zLDUAnxghsBYiUMQQdbBGQ
Generalized Focal Loss:Focal loss魔改以及预测框概率分布
https://mp.weixin.qq.com/s/is8veFCOPpJDXA2okn7pNA
10分钟理解Focal loss数学原理与Pytorch代码
https://zhuanlan.zhihu.com/p/324613604
用概率分布评估检测框质量的Generalized Focal Loss V2
参考
https://mp.weixin.qq.com/s/SsHF3Zpqv61G68nim8ocnQ
深度学习激活函数全面综述论文
https://mp.weixin.qq.com/s/gw3hoDSaojVQUiD6YsMabA
理解神经网络中的目标函数
https://mp.weixin.qq.com/s/l0FRj78M73vQGqppNSyBwQ
深度学习常用损失函数总览:基本形式、原理、特点
https://mp.weixin.qq.com/s/h-QbwEbaivvHjdhDhE4V1A
如何为单变量模型选择最佳的回归函数
https://mp.weixin.qq.com/s/qXZMo_RitSenmI7x0xGNsg
中科院自动化所多媒体计算与图形学团队NIPS 2017论文提出平均Top-K损失函数,专注于解决复杂样本
https://mp.weixin.qq.com/s/YOdmv88koSHx5AMMEQZGgg
通俗聊聊损失函数中的均方误差以及平方误差
https://blog.csdn.net/zhangxb35/article/details/72464152
pytorch loss function总结
https://mp.weixin.qq.com/s/Xbi5iOh3xoBIK5kVmqbKYA
机器学习大牛是如何选择回归损失函数的?
https://mp.weixin.qq.com/s/f29WSb_xZxY1S_MP3Yp0dg
机器学习中常用的损失函数你知多少?
https://mp.weixin.qq.com/s/AdpO4xxTi0G7YiTfjEz_ig
机器学习必备的分类损失函数速查手册
https://mp.weixin.qq.com/s/NY1y0N6XedmMEvfsEFcTjQ
机器学习中的目标函数总结
https://mp.weixin.qq.com/s/ixYhM29-famb8lbzNYnHAg
深度学习中常用的损失函数有哪些?
https://mp.weixin.qq.com/s/AmXF0xA_T-ZjjnOt4XRgRw
谷歌提出新分类损失函数:将噪声对训练结果影响降到最低
https://www.zhihu.com/question/268105631
神经网络中,设计loss function有哪些技巧?
https://mp.weixin.qq.com/s/7cr6ptZucXzsZauItcZehw
使用一个特别设计的损失来处理类别不均衡的数据集
https://www.zhihu.com/question/264892967
深度学习中loss和accuracy的关系?
https://zhuanlan.zhihu.com/p/82199561
深度度量学习中的损失函数
https://mp.weixin.qq.com/s/CbORYhJQn27J0G4G6XpODw
用于弱监督图像语义分割的新型损失函数
https://mp.weixin.qq.com/s/Yo68YnMMvy5FXkCjBLCJuw
常见的损失函数
https://mp.weixin.qq.com/s/CPfhGxig9BMAgimBSOLy3g
用于图像检索的等距离等分布三元组损失函数
https://www.zhihu.com/question/375794498
深度学习的多个loss如何平衡?
https://mp.weixin.qq.com/s/tzY_lG0F9dP5Q-LmwuHLmQ
常见损失函数和评价指标总结
https://mp.weixin.qq.com/s/lw9frtqocqsS-q2KGfzO1Q
深入理解计算机视觉中的损失函数
https://mp.weixin.qq.com/s/_HQ5an_krRCYMVnwEgGJow
深度学习的多个loss如何平衡 & 有哪些“魔改”损失函数,曾经拯救了你的深度学习模型?
https://blog.csdn.net/shanglianlm/article/details/85019768
十九种损失函数
https://mp.weixin.qq.com/s/8oKiVRjtPQIH1D2HltsREQ
图像分割损失函数最全面、最详细总结
https://zhuanlan.zhihu.com/p/158853633
一文理解Ranking Loss/Margin Loss/Triplet Loss
https://zhuanlan.zhihu.com/p/235533342
目标检测:Loss整理
https://zhuanlan.zhihu.com/p/191355122
NLP样本不均衡之常用损失函数对比
https://mp.weixin.qq.com/s/KL_D8pWtcXCJHz7dd70jyw
Face Recognition Loss on Mnist with Pytorch
https://zhuanlan.zhihu.com/p/77686118
机器学习常用损失函数小结
https://zhuanlan.zhihu.com/p/38855840
SphereReID:从人脸到行人,Softmax变种效果显著
https://mp.weixin.qq.com/s/ZoLO6OilivPgle03KdNzCQ
人脸识别中Softmax-based Loss的演化史
https://mp.weixin.qq.com/s/DwtA6GivVCDvL4MXNDBFWg
阿里巴巴提出DR Loss:解决目标检测的样本不平衡问题
https://zhuanlan.zhihu.com/p/145927429
DR Loss
https://mp.weixin.qq.com/s/x0aBo-w669_2FyCGKWJ4iQ
理解计算机视觉中的损失函数
https://mp.weixin.qq.com/s/LOewKsxtWm7dFJS6ioryuw
Siamese网络,Triplet Loss以及Circle Loss的解释
https://zhuanlan.zhihu.com/p/58883095
常见的损失函数(loss function)总结
https://mp.weixin.qq.com/s/UjBCjwNDIxDoAoyQAf8V6A
旷视研究院提出Circle Loss,革新深度特征学习范式
https://mp.weixin.qq.com/s/5RpbXzuHp_tR6C_nBdiXGA
Circle Loss:从统一的相似性对的优化角度进行深度特征学习
https://zhuanlan.zhihu.com/p/304462034
根据标签分布来选择损失函数
https://mp.weixin.qq.com/s/Ywzbn2_QqYd1W8dv8cxupw
Seesaw Loss:一种面向长尾目标检测的平衡损失函数
https://mp.weixin.qq.com/s/qJIlbLuM7–wj3fDLUecYw
Pytorch中的四种经典Loss源码解析
https://mp.weixin.qq.com/s/7Jg-YvS3nvcPJ-zYhK96EA
分享神经网络中设计loss function的一些技巧
https://mp.weixin.qq.com/s/cYcztl8N9JF-XXp9xLJIxg
一文道尽softmax loss及其变种
https://mp.weixin.qq.com/s/MTeuRYutMiCmthEAObyAIg
从最优化的角度看待Softmax损失函数
https://zhuanlan.zhihu.com/p/23340343
Center Loss及其在人脸识别中的应用
https://zhuanlan.zhihu.com/p/34404607
人脸识别的LOSS(上)
https://zhuanlan.zhihu.com/p/34436551
人脸识别的LOSS(下)
https://mp.weixin.qq.com/s/kI22wSoyNT3QXXI8pVwbjA
腾讯AI Lab提出新型损失函数LMCL:可显著增强人脸识别模型的判别能力
https://mp.weixin.qq.com/s/8KM7wUg_lnFBd0fIoczTHQ
用收缩损失(Shrinkage Loss)进行深度回归跟踪
https://mp.weixin.qq.com/s/piYyhPbA6kAXuSE5yHfQ1g
人脸识别损失函数综述
https://zhuanlan.zhihu.com/p/60747096
人脸识别损失函数简介与Pytorch实现:ArcFace、SphereFace、CosFace
https://mp.weixin.qq.com/s/_cVNNZBBJljdWBPU9d38CA
常见的损失函数超全总结
https://mp.weixin.qq.com/s/P6xLYrNP4pNKtHcxAWAOKg
数据竞赛中的各种loss function
https://mp.weixin.qq.com/s/Q4ryiTOSJQaJ2e5clmXjtg
一文看尽深度学习中的15种损失函数
NLP历史
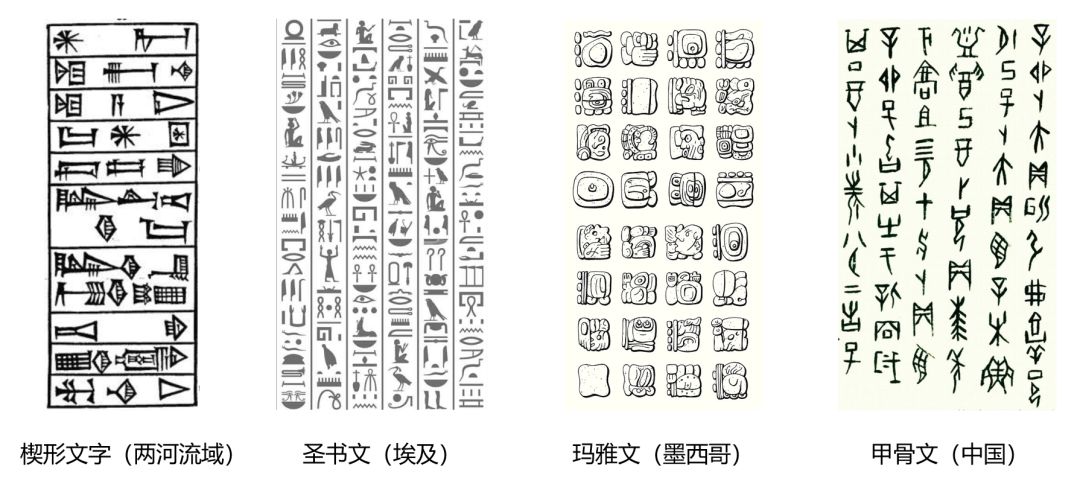
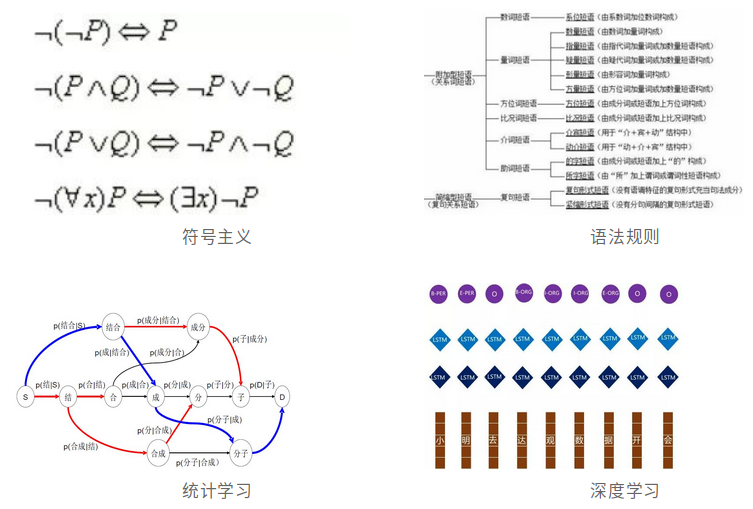
第一代技术(1950s):符号主义,用计算机的符号操作来模拟人的认知过程。
第二代技术(1970s):语法规则,依赖于专家人工制定的语法规则和本体设计(ontological design)。
第三代技术(1990s):统计学习,即让计算机阅读大量文章。
第四代技术(2010s):深度学习,用一个复杂的模型像人脑神经网络一样运作。
http://elinguistics.net/
这个网站可用于比较两种语言的亲缘/差异程度。
https://www.zhihu.com/question/526103427
维吾尔语能否和土耳其语互通?如果能的话,能互通多少?
2006年,马占凯发明包含“词库”和“联想扩散能力”的输入工具,被百度拒绝后转投搜狐,上线搜狗输入法。
参考:
https://mp.weixin.qq.com/s/1cdg635KcPTV6mFdwPo2OQ
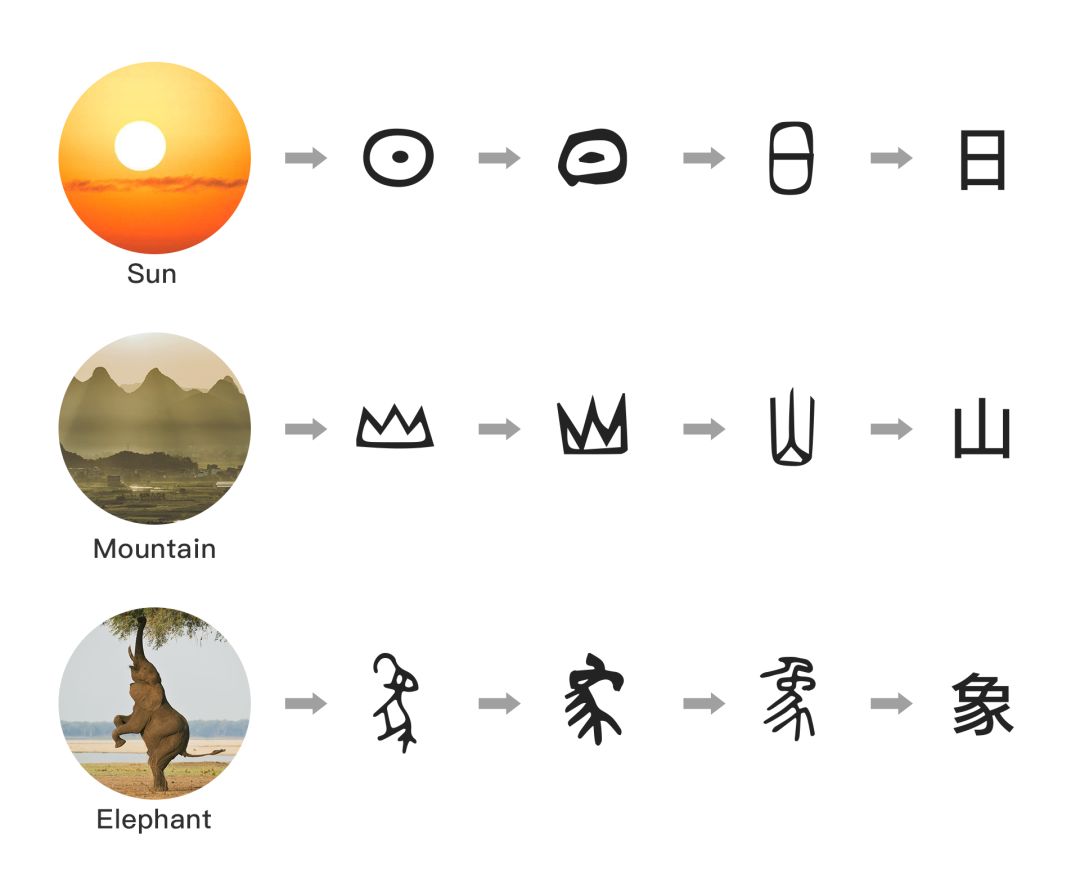
达观数据:文字的起源与文本挖掘的前世今生
https://mp.weixin.qq.com/s/krW1eUFu7iz9YyYFGbFVeQ
香侬科技提出中文字型的深度学习模型Glyce,横扫13项中文NLP记录
https://mp.weixin.qq.com/s/VtEM6paUPH28GFrwVNmz4w
自然语言处理起源:马尔科夫和香农的语言建模实验
https://mp.weixin.qq.com/s/qlKGgWq_FTYonMXEkhRwpw
中国境内语言概览
https://www.zhihu.com/question/30873035
Unicode字符集中有哪些神奇的字符?

您的打赏,是对我的鼓励
