DL » 深度学习(十四)——seq2seq, Normalization进阶
2017-08-29 :: 6566 Wordsseq2seq
seq2seq最早用于Neural Machine Translation(NMT)领域(与之相对应的有Statistical Machine Translation)。训练后的seq2seq模型,可以根据输入语句,自动生成翻译后的输出语句。
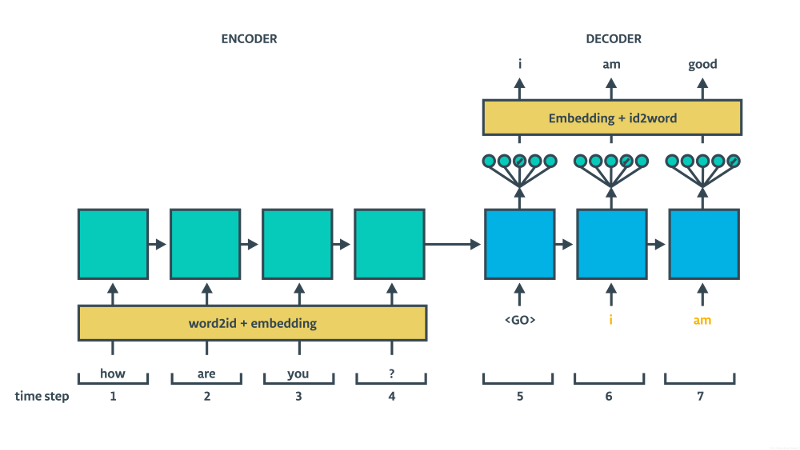
上图是seq2seq的结构图。可以看出seq2seq实际上是一种Encoder-Decoder结构。
在Encoder阶段,RNN依次读入输入序列。但由于这时,没有输出序列与之对应,因此这仅仅相当于一个对隐层的编码过程,即将句子的语义编码为隐层的状态向量。
从中发现一个问题:状态向量的维数决定了存储的语义的内容上限(显然不能指望,一个200维的向量,能够表示一部百科全书。)因此,seq2seq通常只用于短文本的翻译。
在Decoder阶段,我们根据输出序列,反向修正RNN的参数,以达到训练神经网络的目的。
Beam Search Decoder
https://guillaumegenthial.github.io/sequence-to-sequence.html
Seq2Seq with Attention and Beam Search
https://blog.csdn.net/mr_tyting/article/details/78604721
Seq2Seq Learning(Encoder-Decoder,Beam Search,Attention)
参考
https://github.com/ematvey/tensorflow-seq2seq-tutorials
一步步的seq2seq教程
http://blog.csdn.net/sunlylorn/article/details/50607376
seq2seq模型
http://datartisan.com/article/detail/120.html
Seq2Seq的DIY简介
https://mp.weixin.qq.com/s/U5yqXBHFD9LgIQJrqOlXFw
机器翻译不可不知的Seq2Seq模型
http://www.cnblogs.com/Determined22/p/6650373.html
DL4NLP——seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
https://mp.weixin.qq.com/s/m-Z0UBgmFQ4CE0yLKYoHZw
seq2seq和attention如何应用到文档自动摘要
http://blog.csdn.net/young_gy/article/details/73412285
基于RNN的语言模型与机器翻译NMT
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
The Unreasonable Effectiveness of Recurrent Neural Networks
https://mp.weixin.qq.com/s/8u3v9XzECkwcNn5Ay-kYQQ
基于Depthwise Separable Convolutions的Seq2Seq模型_SliceNet原理解析
https://mp.weixin.qq.com/s/H6eYxS7rXGDH_B8Znrxqsg
seq2seq中的beam search算法过程
https://mp.weixin.qq.com/s/U1yHIc5Zq0yKCezRm185VA
Attentive Sequence to Sequence Networks
https://mp.weixin.qq.com/s/cGXANj7BB2ktTdPAL4ZEWA
图解神经网络机器翻译原理:LSTM、seq2seq到Zero-Shot
https://mp.weixin.qq.com/s/jYUAKyTpm69J6Q34A06E-w
百度提出冷聚变方法:使用语言模型训练Seq2Seq模型
https://mp.weixin.qq.com/s/Fp6G1aI_utDd_kTbdHvEVQ
完全基于卷积神经网络的seq2seq
http://localhost:4500/theory/2017/06/21/Deep_Learning_6.html
从2017年顶会论文看Attention Model
https://mp.weixin.qq.com/s/Op_oYiNvaTXvsvAnl8Heew
基于Self-attention的文本向量表示方法,悉尼科技大学和华盛顿大学最新工作
https://mp.weixin.qq.com/s/fBrt4g_Kjmt1tGVZw5KgrQ
从LSTM到Seq2Seq
https://mp.weixin.qq.com/s/riIC6ybvqAJx9mzb-AQIOw
Facebook AI发布新版本FairSeq序列到序列(Seq2Seq)学习工具,可生成故事与快速推断
https://mp.weixin.qq.com/s/DIqjVxF_kACkivzez4_Hog
编码器-解码器网络:神经翻译模型详解
https://mp.weixin.qq.com/s/Alg4rOXNvb4GA8N4Joy-Jg
Seq2seq强化,Pointer Network简介
https://mp.weixin.qq.com/s/kdmmgVdWxz2nJPmjcprvqg
机器学习中的编码器-解码器结构哲学
https://mp.weixin.qq.com/s/OcrT2-sAWJg-ILdHwi4t5Q
seq2seq最新变体,稀疏序列模型
https://mp.weixin.qq.com/s/_1lr612F3x8ld9gvXj9L2A
推断速度达seq2seq模型的100倍,谷歌开源文本生成新方法LaserTagger
Normalization进阶
Batch Normalization
在《深度学习(三)》中,我们已经简单的介绍了Batch Normalization的基本概念。这里主要讲述一下它的实现细节。
我们知道在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?
原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对输入数据归一化,早就是一种基本操作了。然而这样只对神经网络的输入层有效。更好的办法是对每一层都进行归一化。
然而简单的归一化,会破坏神经网络的特征。(归一化是线性操作,但神经网络本身是非线性的,不具备线性不变性。)因此,如何归一化,实际上是个很有技巧的事情。
首先,我们回顾一下归一化的一般做法:
\[\hat x^{(k)} = \frac{x^{(k)} - E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}}\tag{1}\]其中,\(x = (x^{(0)},x^{(1)},…x^{(d)})\)表示d维的输入向量。
接着,定义归一化变换函数:
\[y^{(k)}=\gamma^{(k)}\hat x^{(k)}+\beta^{(k)}\tag{2}\]这里的\(\gamma^{(k)},\beta^{(k)}\)是待学习的参数。
BN的主要思想是用同一batch的样本分布来近似整体的样本分布。显然,batch size越大,这种近似也就越准确。
用\(\mathcal{B}=\{x_{1,\dots,m}\}\)表示batch,则BN的计算过程如下:
Step 1.计算mini-batch mean。
\[\mu_\mathcal{B}\leftarrow \frac{1}{m}\sum_{i=1}^mx_i\tag{3}\]Step 2.计算mini-batch variance。
\[\sigma_\mathcal{B}^2\leftarrow \frac{1}{m}\sum_{i=1}^m(x_i-\mu_\mathcal{B})^2\tag{4}\]Step 3.normalize。
\[\hat x_i\leftarrow \frac{x_i-\mu_\mathcal{B}}{\sqrt{\sigma_\mathcal{B}^2+\epsilon}}\tag{5}\]这里的\(\epsilon\)是为了数值的稳定性而添加的常数。
Step 4.scale and shift。
\[y_i=\gamma\hat x_i+\beta\equiv BN_{\gamma,\beta}(x_i)\tag{6}\]在实际使用中,BN计算和卷积计算一样,都被当作神经网络的其中一层。即:
\[z=g(Wx+b)\rightarrow z=g(BN(Wx+b))=g(BN(Wx))\tag{7}\]从另一个角度来看,BN的均值、方差操作,相当于去除一阶和二阶信息,而只保留网络的高阶信息,即非线性部分。因此,上式最后一步中b被忽略,也就不难理解了。
BN的误差反向算法相对复杂,这里不再赘述。
在inference阶段,BN网络忽略Step 1和Step 2,只计算后两步。
-
\(\beta,\gamma\)由之前的训练得到。
-
\(\mu,\sigma\)原则上要求使用全体样本的均值和方差,但样本量过大的情况下,也可使用训练时的若干个mini batch的均值和方差的FIR滤波值。因此,这两个参数也是训练得到的。
由公式7可以看出,BN不是针对x(输入的),而是针对Wx+b的。而W每个channel都不同。因此,对于Layer: batch*channel*height*width来说,对batch*height*width个像素点统计得到一个均值和一个标准差,这样总共会得到channel组参数。
前面章节曾指出:
-
relu得用Kaiming初始化。
-
tanh得用Xavier初始化。
而在网络层的激活函数前加上BN的话,采用什么初始化都无所谓。
BN的缺点参见:
https://mp.weixin.qq.com/s/l2N_cQAzy_mubCeok1qfnA
Batch Normalization的诅咒
BN推理加速参见:
https://mp.weixin.qq.com/s/fAiIGJnciAi3pf8MQ7UqKg
使用Batch Normalization折叠来加速模型推理
Instance Normalization
Instance Normalization主要用于CV领域。
论文:
《Instance Normalization: The Missing Ingredient for Fast Stylization》
首先我们列出对图片Batch Normalization的公式:
\[y_{tijk}=\frac{x_{tijk}-\mu_i}{\sqrt{\sigma_i^2+\epsilon}}, \mu_i=\frac{1}{HWT}\sum_{t=1}^T \sum_{l=1}^W \sum_{m=1}^Hx_{tilm}, \sigma_i^2=\frac{1}{HWT}\sum_{t=1}^T \sum_{l=1}^W \sum_{m=1}^H(x_{tilm}-m\mu_i)^2\]其中,T为图片数量,i为通道,j、k为图片的宽、高。
Instance Normalization的公式:
\[y_{tijk}=\frac{x_{tijk}-\mu_{ti}}{\sqrt{\sigma_{ti}^2+\epsilon}}, \mu_{ti}=\frac{1}{HW} \sum_{l=1}^W \sum_{m=1}^Hx_{tilm}, \sigma_{ti}^2=\frac{1}{HW} \sum_{l=1}^W \sum_{m=1}^H(x_{tilm}-m\mu_{ti})^2\]从中可以看出Instance Normalization实际上就是对一张图片的一个通道内的值进行归一化,因此又叫做对比度归一化(contrast normalization)。
参考:
http://www.jianshu.com/p/d77b6273b990
论文中文版
https://mp.weixin.qq.com/s/EOuuW5R1_4RU-mabSJeKWQ
Instance Norm梯度公式推导
再看Batch Normalization
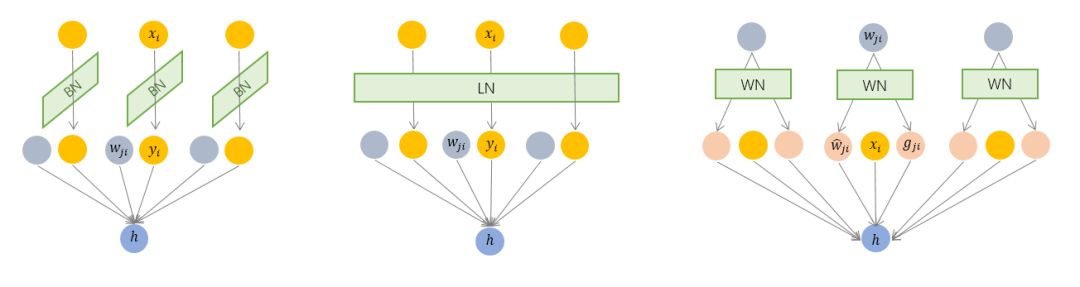
从上图可以看出,BN是对input tensor的每个通道进行mini-batch级别的Normalization。而LN则是对所有通道的input tensor进行Normalization。
BN的特点:
对于batch size比较小的时候,效果非常不好,而batch size越大,那么效果则越好,因为其本质上是要通过mini-batch得到对整个数据集的无偏估计;
在训练阶段和推理阶段的计算过程是不一样的;
在CNN上表现较好,而不适用于RNN甚至LSTM。
Layer Normalization
\[\begin{aligned} \text{LN}(x) = \gamma \left(\frac{x - \mu_B}{\sigma_B}\right) + \beta, \\ \text{where} \\ \mu_B = \frac{1}{M} \sum_{i=1}^{M} x_i, \\ \sigma_B = \sqrt{\frac{1}{M} \sum_{i=1}^{M} (x_i - \mu_B)^2 + \epsilon}, \end{aligned}\]和BN一样,\(\beta,\gamma\)由训练得到。
由于它是针对x的,因此对每个样本都要统计它的均值和方差,这对于inference来说,计算量是偏大的。
LN的特点:
不依赖于batch size的大小,即使对于batch size为1的在线学习,也可以完美适应;
适用于RNN或LSTM,而在CNN上表现一般。
和BN一样,LN通常也忽略公式7中的b。
从实践来看,LN在NLP任务上的表现比BN好。
参考:
https://mp.weixin.qq.com/s/-QzsVs6V2pwvFQlRVYVx2Q
LayerNorm是Transformer的最优解吗?
https://www.zhihu.com/question/395811291
transformer为什么使用layer normalization,而不是其他的归一化方法?
Weight Normalization
WN的公式如下:
\[w=\frac{g}{\|v\|}v\]WN将权重分为模和方向两个分量,并分别进行训练。
论文:
《Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks》
WN的特点:
计算简单,易于理解。
相比于其他两种方法,其训练起来不太稳定,非常依赖于输入数据的分布。

您的打赏,是对我的鼓励
