DL » 深度学习(一)——人工智能, 前言, MP神经元模型
2017-01-13 :: 4668 Words人工智能
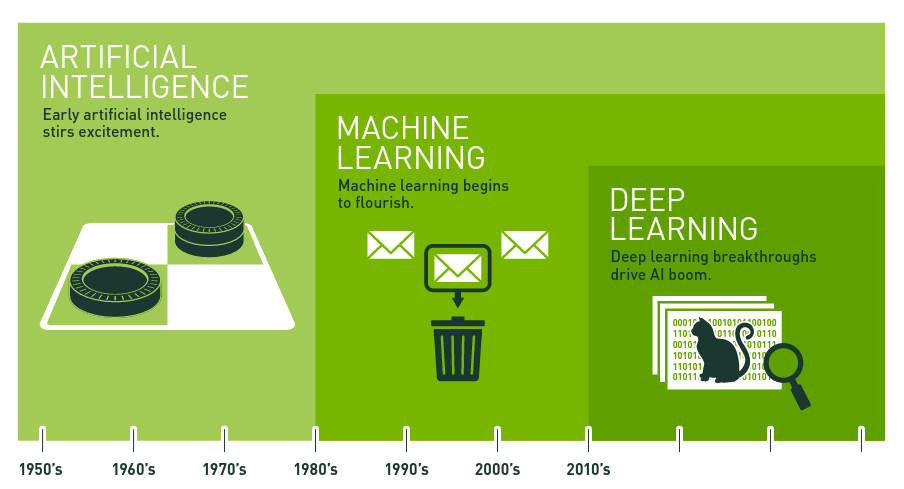
经过长期研究和积累,人工智能形成了三大学派:符号主义、联结主义和行为主义。
符号主义认为人类认知和思维的基本单元是符号,人的思维过程就是符号处理。符号主义曾经长期“统治”人工智能领域,在机器定理证明、专家系统等方面取得了不俗的成绩。
联结主义认为人的智能是通过大脑的神经元互相联结实现的,不同的神经元对不同的输入模式具有敏感性,神经元之间的联结权重可以通过刺激和反馈进行学习。当前流行的深度学习方法就是在人工神经网络的基础上发展而来的。
行为主义认为行为产生智能,智能是对外界复杂环境的适应,而这种适应表现为基于感知信号所采取的行动。家用扫地机器人、波士顿公司的“大狗”都是行为主义学派的代表性成果。
https://mp.weixin.qq.com/s/qaGyZJjNch7OIXIBONJx0Q
人工智能是大杂烩吗?
前言
神经网络本质上不是什么新东西。十几年前,我还在上学的时候,就接触过皮毛。然而那时这玩意更多的还是学术界的屠龙之术,工业界几乎没有涉及。
及至近日重新拾起,方才发现,这十年正是神经网络蓬勃发展,逐渐进入应用阶段的十年。各种概念层出不穷,远非昔日模样。
Deep Learning虽然在学术界的大牛看来,属于旧概念的炒作。然而由于神经网络本身的非线性和连接的复杂性,其中的概念的确比一般的浅层算法复杂的多,从这个角度来说,称其为Deep,也算有些道理。
这里最主要的参考文献包括:
《机器学习》,周志华著。
周志华,1973年生,南京大学博士(2000年)。南京大学教授。
从派系而言,周属于统计学派,对深度学习并不感冒。然而《机器学习》一书(又称西瓜书),已经成为ML入门的必读经典,因此这里也把它列为主要的参考文献之一。
在深度学习统治学界的时代,周依然能用gcForest、mcODM之类的算法,撑起统计学派的大旗,堪称国内一流的学者。
http://www.useit.com.cn/thread-13132-1-1.html
《Deep Learning Tutorial》,李宏毅著。
http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
台湾大学李宏毅副教授的深度学习课程
李宏毅,国立台湾大学硕士(2010年)+博士(2012年)。国立台湾大学计算机系助理教授。
李宏毅的课程难度适中,内容全面,且更新很快,每隔半年逛一下,必有新收获。
https://www.csie.ntu.edu.tw/~yvchen/f106-adl/syllabus.html
李宏毅的搭档,美女陈蕴侬的深度学习课程

陈蕴侬,国立台湾大学本硕(2011年)+CMU博士(2015年)。国立台湾大学计算机系助理教授。
http://introtodeeplearning.com/
MIT 6.S191 Introduction to Deep Learning。涵盖深度学习导论、序列建模、深度视觉、生成模型、强化学习、图神经网络、对抗学习、贝叶斯模型、神经渲染、机器学习嗅觉等方面,是DL领域的综合课程。
《Deep Learning》,Ian Goodfellow、Yoshua Bengio、Aaron Courville著。
原版:
http://www.deeplearningbook.org/
中文版:
https://github.com/exacity/deeplearningbook-chinese
这本书基于markdown文件,使用tex编译而成,可作为编写大型书的代码参考项目。
安装方法:
sudo apt install texlive-xetex texlive-lang-chinese texlive-science xindy
make
《Deep Learning With Python》,Keras的作者Francois Chollet著。偏重于DL实战。
此外,Stanford、CMU、UCB等名校也有大量相关课程。
其他参考文献将在各相关部分列出。
Deep Learning圈子的主要人物:
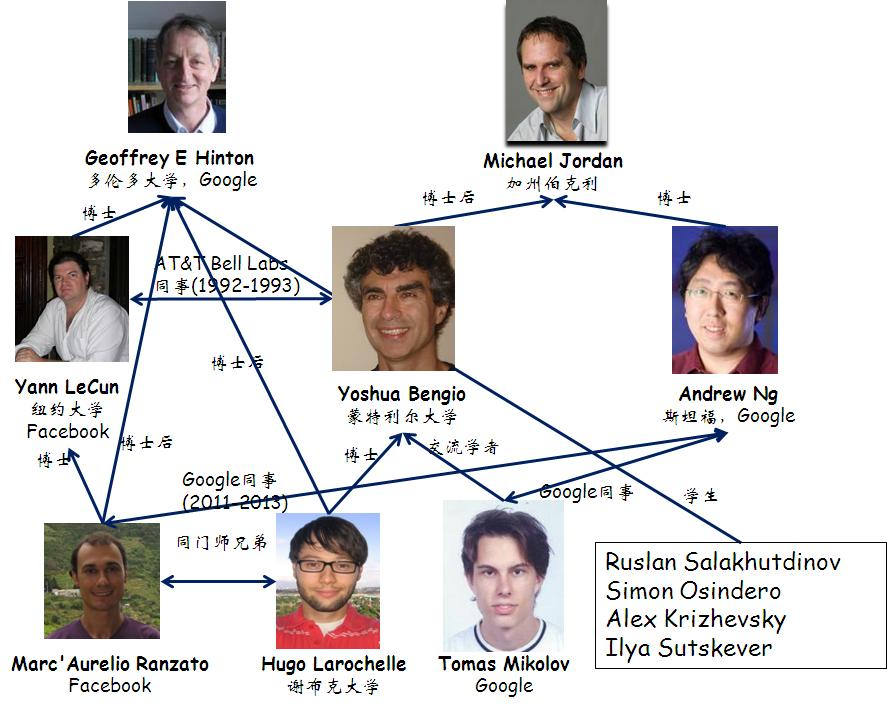
Yann LeCun,1960年生,法国科学家。Pierre and Marie Curie University博士。Geoffrey Hinton是他博士后时代的导师。CNN的发明人。纽约大学教授,Facebook AI研究所主任。由于他的姓名发音非常东方化,因此被网友起了很多中文名如燕乐存、杨乐康等。2017.3,Yann访华期间正式公布中文名:杨立昆。
Léon Bottou,法国科学家,随机梯度下降算法的发明人。
Yoshua Bengio,1964年生,法国出生的加拿大科学家。深度学习的另一个宗师。
这三个法国佬,都是好基友。只不过Yann LeCun和Yoshua Bengio研究神经网络,而Léon Bottou研究SVM,学术上分属不同派系。
Geoffrey Everest Hinton,1947年生,英国出生的加拿大科学家,爱丁堡大学博士,多伦多大学教授。连接主义的代表人物,多层神经网络的宗师。英国皇家学会会员。Hinton的事迹参见《对Geoffrey Everest Hinton的深度挖掘》
一般将Geoffrey Hinton、Yann LeCun和Yoshua Bengio并称为深度学习的三大宗师。
2019.3.27 三巨头被共同授予2018年度图灵奖。
2024.10.8 Hinton被授予诺贝尔物理学奖。
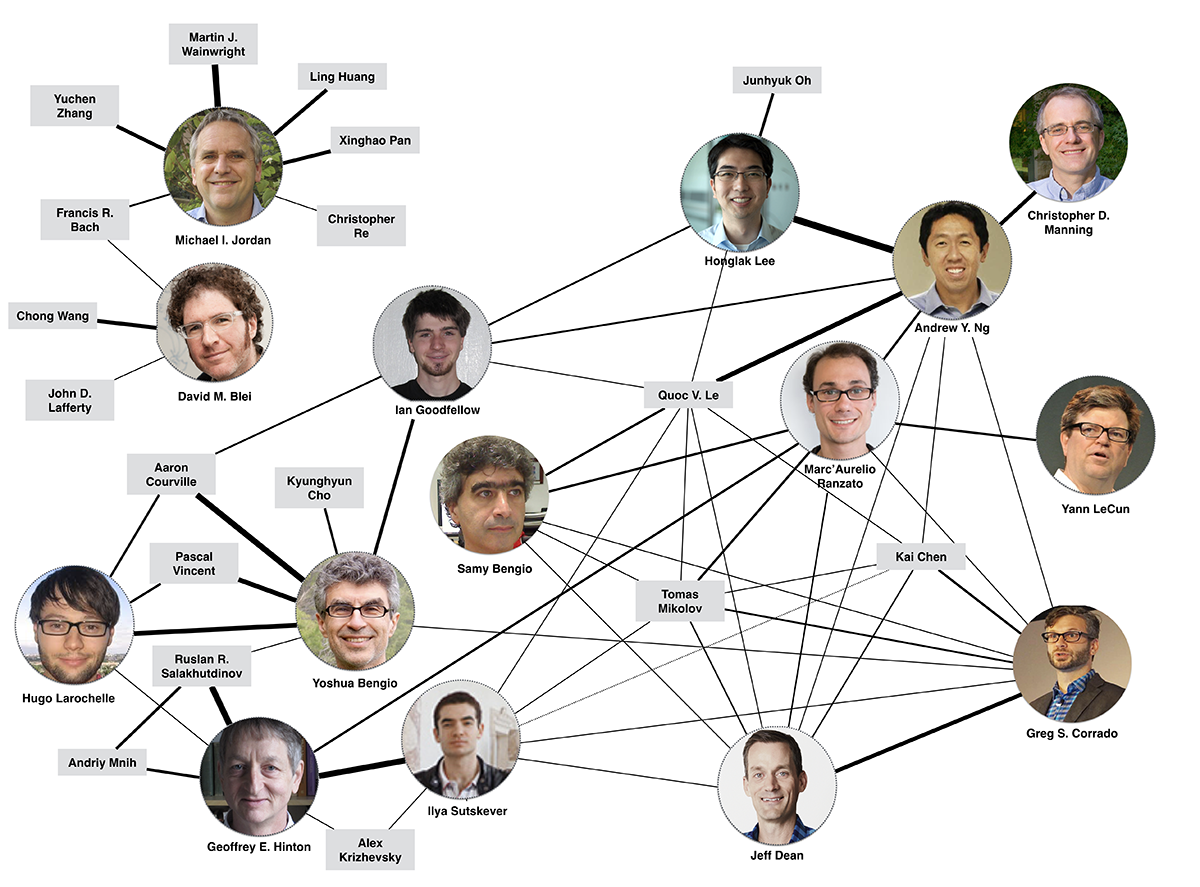
上图是一个更大的DL牛人关系图。
https://mp.weixin.qq.com/s/w_LKb-xOdyBsQBRGmHo6zw
深度学习综述:Hinton、Yann LeCun和Bengio经典重读
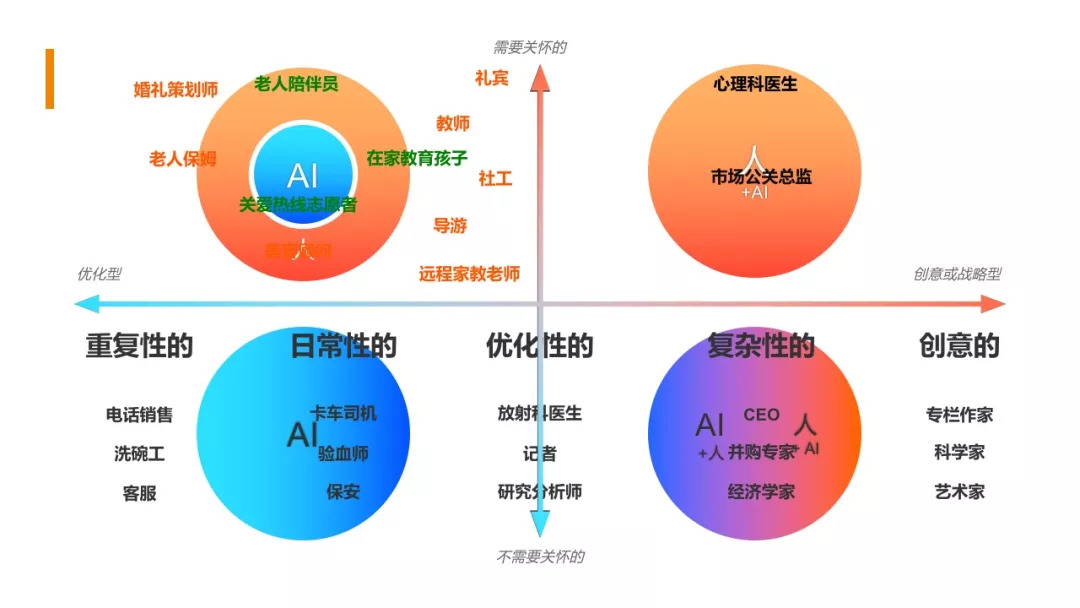
上图是李开复提出了AI替代人工的象限图。非创意和非关怀类的职业会逐渐被AI所取代。
2025.4
从目前的现状来看,洗碗工没有失业,倒是画师失业了。AI的准确性不够,但是创意远超人类。。。囧
早年搞深度学习的这帮人被当作异端,受到统计学派的极度迫害。
统计机器学习派,就好比国内南京大学的周志华,北京大学人工智能学院的院长朱松纯。朱松纯在美国的时候,把后来和Hinton一起拿图灵奖的lecun整的精神都不正常了,深度神经网络火了后,朱在美国不被待见,年薪150万美元跑回北大,北大号称千金买马骨。
最搞笑的是,上面看现在的人工智能深度神经网络技术很火,说要引进海外的人工智能领军人物,于是北大150万美元引进了朱,上面做梦也没想到,这个朱是反现在的人工智能技术(深度神经网络)的,北大这是欺负上面不懂,耍了上面一把。
朱松纯在北大提出,应该搞以中国哲学(老子,儒家,易经)为核心的中国通用人工智能技术,150万美元一年,就引进了这么个玩意。
Hinton死磕神经网络,被美国大学辞退赶到多伦多大学,多伦多大学计算机学院也多次想赶Hinton走,连给他上课的报酬都是最低的,一个50多岁老头连个独立办公室都没有,和十几个人共有办公室,就是逼他主动走,属于人生失败的屌丝典范(因为加拿大大学有和美国大学完全不同的制度,只要教职工不主动离职,校方就不会辞退,所以有美国大学收容所的说法)。
Hinton拿了图灵奖后,多伦多大学都不给他提供独立办公室,直到拿了诺奖后,才给了Hinton一间独立办公室。Hinton调侃说:“得奖后他们给了我一间办公室,之前多伦多大学觉得我不配拥有。”
Hinton具体技术是懂的,因为他在多伦多大学没那么多学生给他干活,他得亲自干一部分(虽然拿诺奖后他感谢说,活都是学生干的)。
朱在九十年代博士生论文中,成功的将EM最大熵原理,以及贝叶斯框架为代表的统计学工具引入视觉算法设计中,问题建模典型算法如FRAME。其后在本世纪初2002年左右DDMCMC图像分割算法可以看作是这一设计思想的集大成。
https://zhuanlan.zhihu.com/p/1950888664159721144
朱松纯早中期视觉算法中的执念
MP神经元模型
MP神经元模型是1943年,由Warren McCulloch和Walter Pitts提出的。
Warren Sturgis McCulloch,1898~1969,美国神经生理学和控制论科学家。哥伦比亚大学博士,先后执教于MIT、Yale、芝加哥大学。
Walter Harry Pitts, Jr.,1923~1969,美国计算神经学科学家。
这个人的经历,实在是非典型。家里贫穷,大约是读不起大学,15岁的时候,到芝加哥大学旁听Bertrand Russell的讲座。Russell很看重这个年轻人,但由于他只是访问学者,于是在回国之前,将Pitts介绍给Rudolf Carnap,后者为Pitts安排了一份在学校打杂的工作。这一打杂就是五六年时间,最后凭借论文,获得芝加哥大学的准学士学位(因为他始终都不是正式学籍的学生),这也是他一生唯一的学位。
但是如果看看Pitts的合作者的阵容,就知道Pitts水平之高了。他们是:Warren McCulloch、Jerome Lettvin、Norbert Wiener。
MP神经元模型如下图所示:
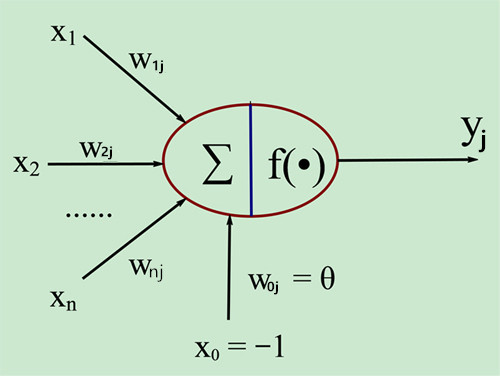
即:
\[y_j=f\left(\sum _{i=1}^nw_{ij}x_i-\theta_j\right)\]f被称为称为激活函数(Activation Function)或转移函数(Transfer Function),用以提供非线性表达能力。f的参数其实就是《机器学习(一)》中提到的逻辑回归。
生物神经元和MP神经元模型的对应关系如下表:
| 生物神经元 | MP神经元模型 |
|---|---|
| 神经元 | \(j\) |
| 输入信号 | \(x_i\) |
| 权值 | \(w_{ij}\) |
| 输出信号 | \(y_j\) |
| 总和 | \(\sum\) |
| 膜电位 | \(\sum _{i=1}^nw_{ij}x_i\) |
| 阈值 | \(\theta_j\) |
从上图亦可看出,如果将阈值看作输入为-1.0的哑节点的连接权重,则权重和阈值可统一为权重。神经网络训练的过程,实际上就是根据样本调整权重和阈值的过程。
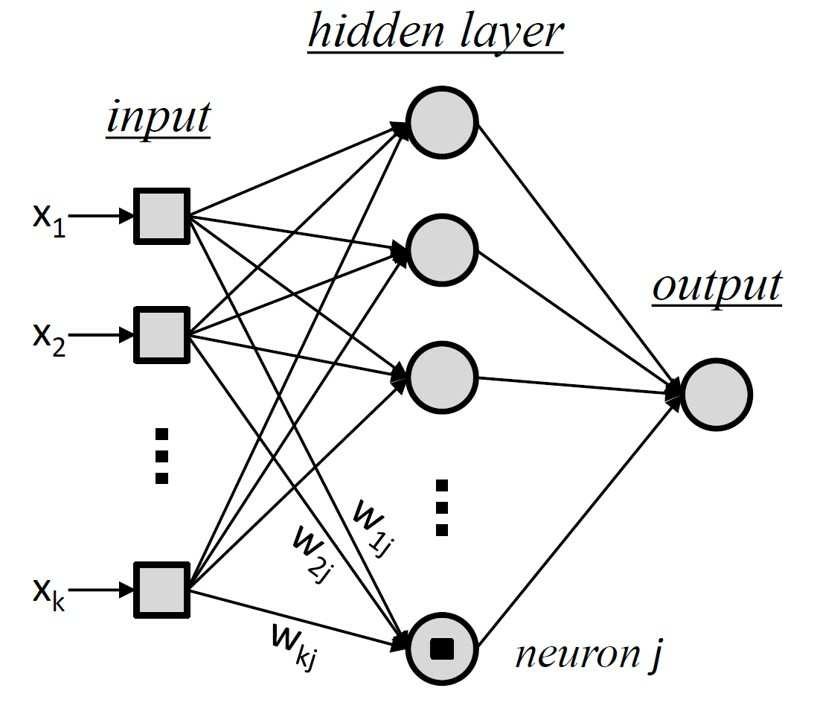
实际使用中,可以将多个神经元组合成一个Layer,也就是通常所说的full connect layer。
参考:
http://blog.csdn.net/u013007900/article/details/50066315
神经网络学习之M-P模型
单层感知器 vs. 多层感知器
神经网络的层数越多,其表达力越丰富,如下表所示:
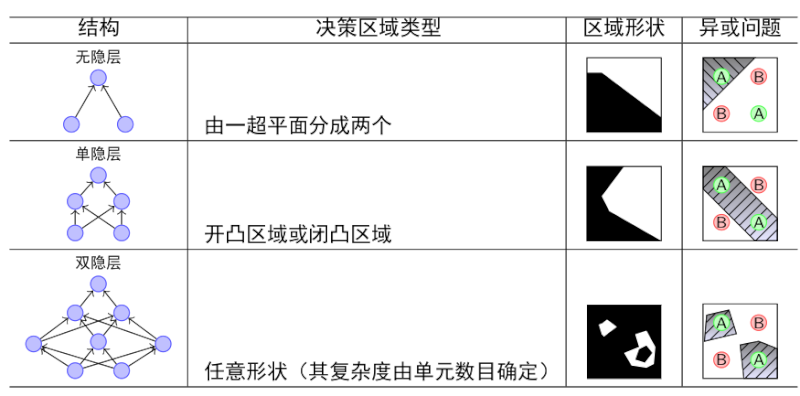
宽度也有类似的现象:
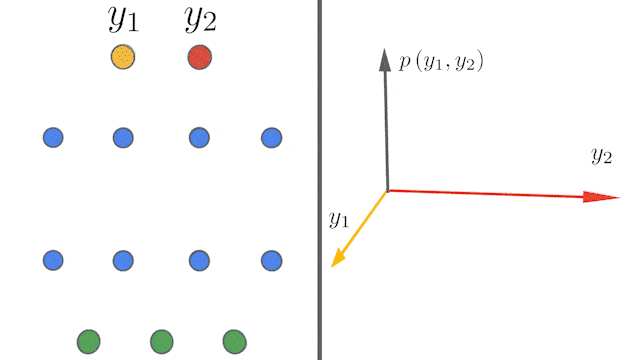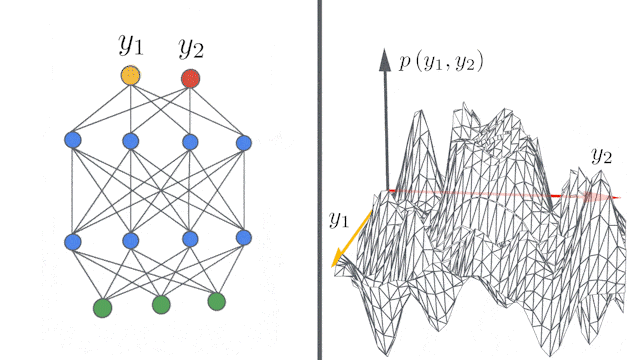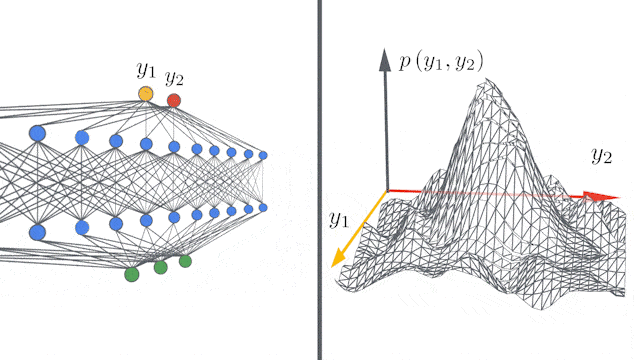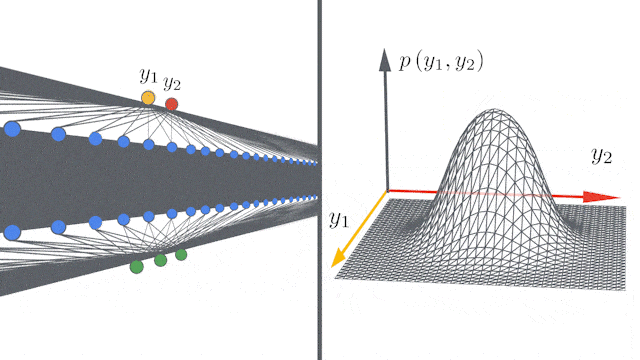
实际上无限宽的神经网络模型等价于Gaussian Processes。
参考:
https://mp.weixin.qq.com/s/W0mVk_KtL2Tr_Uo-1el7Aw
5行代码打造无限宽神经网络模型
https://mp.weixin.qq.com/s/3C5b1cd4PwoYeAEkj5wbYw
用小学数学带你感受人工智能的魅力

您的打赏,是对我的鼓励
