Generative Model » GAN(四)——Stack GAN, GAN Ensemble, Pix2Pix, CycleGAN, StarGAN
2019-04-19 :: 5522 WordsEBGAN & BEGAN(续)
AutoEncoder:Encoder->Decoder
GAN:Decoder->Encoder
对于生成模型来说,细节是很重要的,然而原始的GAN,通常只能生成模糊的图片。如何提高图片的分辨率呢?
EBGAN将D网络的结构由Encoder改为了Encoder->Decoder(也就是一个AE),即输入和输出都是图片。将Loss由KL散度改为了MSE。
这样的做法可以类比CV中的分类网络和语义分割网络。由于Loss和图片的每个像素都直接相关,因此更利于生成细节信息。
类似的,这里的AE,也可以换成其他Encoder->Decoder网络,例如U-NET。
EBGAN的最大特点就是判别器一开始就非常强(因为有pretrain),因此生成器在一开始就能获得比较大的“能量驱动”(energy based),使得在一开始生成器就进步非常快。所以如果我们比较看中训练效率,希望在短期内获得一个比较不错的生成器的话,就可以考虑EBGAN。
BEGAN则借鉴了EBGAN和WGAN各自的一些优点。
Stack GAN
论文:
《StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》
早期以DCGAN为代表的网络生成的图片分辨率太低,质量不够好,都不超过100×100,在32×32或者64×64左右。这是因为难以一次性学习到生成高分辨率的样本,收敛过程容易不稳定。因此采用级联结构,逐次提升分辨率的Stack GAN应运而生。
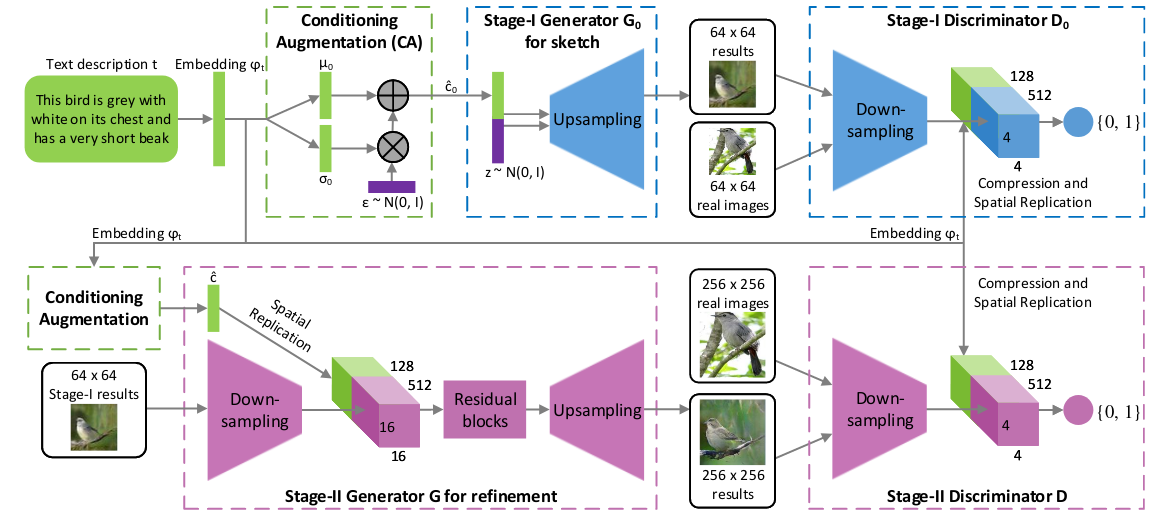
上图是Stack GAN的网络结构图。其中的Conditioning Augmentation,显然使用了和VAE类似的添加随机噪声的技术。
类似想法的还有LAPGAN。
论文:
《Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks》
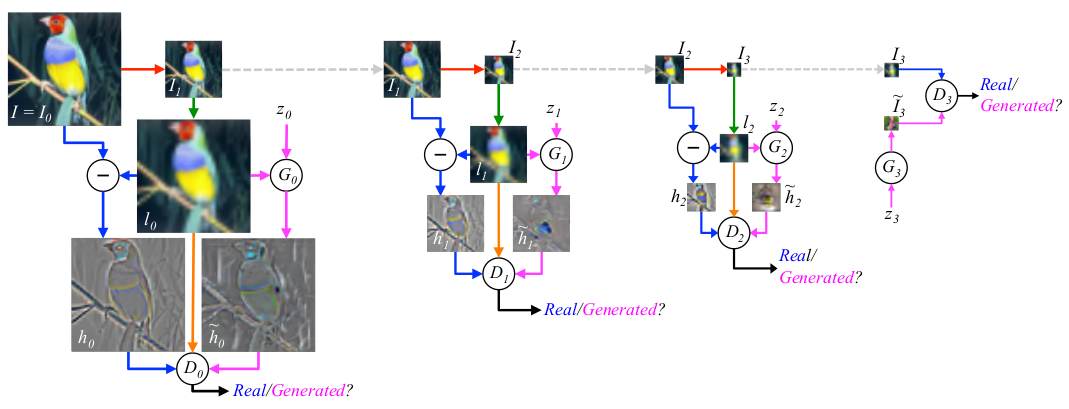
上图是LAPGAN的网络结构图。顾名思义,这是使用了Laplacian Pyramid来不断提升生成图片的分辨率。
另,StackGAN还有后续版本StackGAN++。
参考:
https://www.cnblogs.com/wangxiaocvpr/p/5966776.html
LAPGAN论文笔记
https://zhuanlan.zhihu.com/p/30532830
眼见已不为实,迄今最真实的GAN:Progressive Growing of GANs
GAN Ensemble
除了级联结构之外,以下结构用的也比较多。
多判别器单生成器
论文:
《Generative Multi-Adversarial Networks》
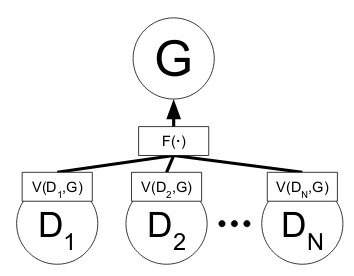
采用多个判别器的好处带来了类似于boosting的优势,训练一个过于好的判别器,会损坏生成器的性能,这是GAN面临的一个大难题。如果能够训练多个没有那么强的判别器,然后进行boosting,可以取得不错的效果,甚至连dropout技术都可以应用进来。
多个判别器还可以相互进行分工,比如在图像分类中,一个进行粗粒度的分类,一个进行细粒度的分类。在语音任务中,各自用于不同声道的处理。
单判别器多生成器
论文:
《Multi-Agent Diverse Generative Adversarial Networks》
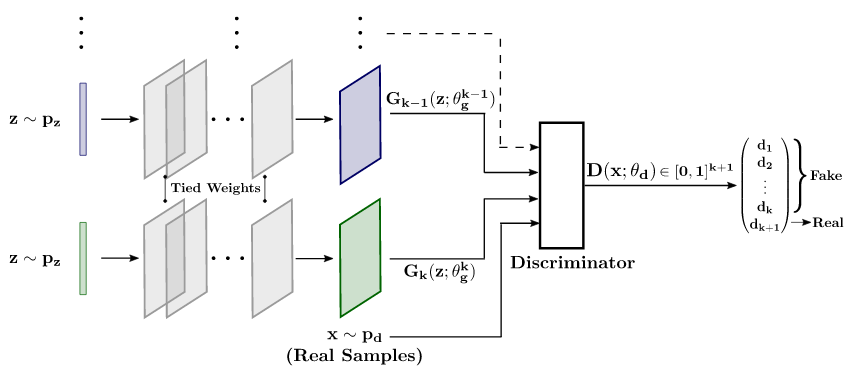
一般来说,生成器相比判别器要完成的任务更难,因为它要完成数据概率密度的拟合,而判别器只需要进行判别,导致影响GAN性能的一个问题就是模式坍塌,即生成高度相似的样本。采用多个生成器单个判别器的方法,可以有效地缓解这个问题。
从上图结构可以看出,多个生成器采用同样的结构,在网络的浅层还共享权重。
增加分类器
论文:
《Triple Generative Adversarial Nets》
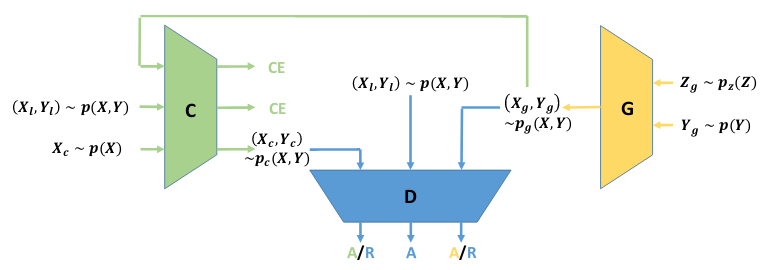
在利用GAN进行半监督的图像分类任务时,判别器需要同时担任两个角色,即判别生成的假样本,以及预测类别,这对判别器提出了较高的要求。通过增加一个分类器可以分担判别器的工作量,即将捕捉样本和标签的条件分布这一任务交给生成器和分类器,而判别器只专注于区分真实样本和生成的样本。
Pix2Pix
论文:
《Image-to-image translation with conditional adversarial networks》
代码:
https://github.com/phillipi/pix2pix
torch版本
https://github.com/affinelayer/pix2pix-tensorflow
tensorflow版本
https://github.com/williamFalcon/pix2pix-keras
keras版本
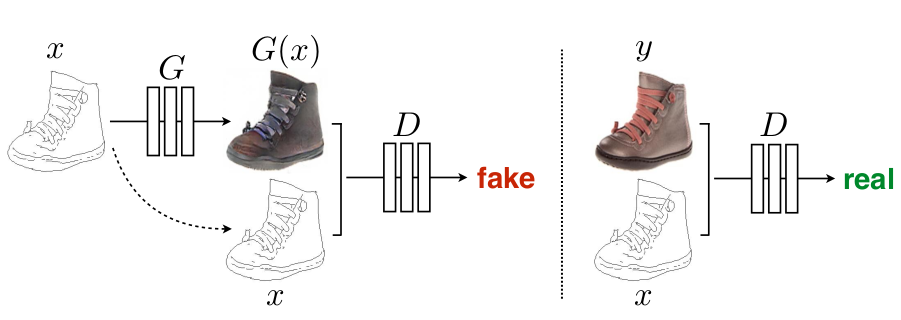
Pix2Pix对于user control的要求比一般的CGAN更高,这里的监督信息不再是一个类别,而是一张图片。上图就是一个使用Pix2Pix对素描图上色的示例。其中的素描图就相当于CGAN中的类别信息。
Pix2Pix相对于传统GAN的改进在于:
1.D网络的输入同时包括生成的图片X和它的素描图Y,X和Y使用Concat操作进行融合。例如,假设两者都是3通道的RGB颜色图,则D网络的Input就是一个6通道的tensor,即所谓的Depth-wise concatenation。
2.G网络使用dropout来提供随机性。作者在实践中发现,传统的噪声向量在这个模型的学习过程中,被模型忽略掉了,起不到相应的作用。
3.G网络使用U-NET。实践表明,U-NET比AE的效果要好。
4.L1损失函数的加入来保证输入和输出之间的一致性。
5.使用PatchGAN来保证局部精准。
一般的GAN的D网络,只需要输出一个true or fasle的矢量,这代表对整张图像的评价。而PatchGAN输出的是一个NxN的矩阵,这个NxN的矩阵的每一个元素,对应着原图中的一个Patch。
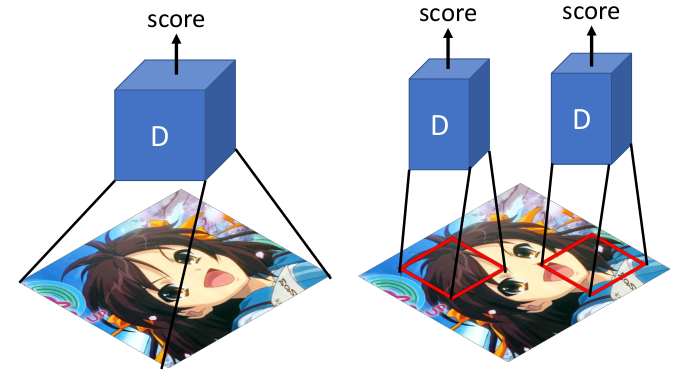
判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。这一步在具体实现上,就是使用Conv来代替D网络最后一层的FC。由于Conv操作不在乎输入尺寸,因此可以用不同尺寸的图片训练网络。

这是使用不同大小的patch的效果。可以看出patch size越大,则效果越好,但是计算量也越大。s
参考:
https://blog.csdn.net/stdcoutzyx/article/details/78820728
Pix2Pix-基于GAN的图像翻译
https://zhuanlan.zhihu.com/p/38411618
pix2pix
https://www.jianshu.com/p/8c7a7cb7198c
pix2pix
https://blog.csdn.net/gdymind/article/details/82696481
一文读懂GAN, pix2pix, CycleGAN和pix2pixHD
https://mp.weixin.qq.com/s/_PlISSOaowgvVW5msa7GlQ
条件GAN高分辨率图像合成与语义编辑pix2pixHD
https://mp.weixin.qq.com/s/PoSA6JXYE_OexEoJYzaX4A
利用条件GANs的pix2pix进化版:高分辨率图像合成和语义操作
https://blog.csdn.net/xiaoxifei/article/details/86506955
关于PatchGAN的理解
https://zhuanlan.zhihu.com/p/56808180
图像翻译三部曲:pix2pix, pix2pixHD, vid2vid
CycleGAN
Style Transfer的基本内容可参见《深度学习(十五)》。
除了基于纹理的Style Transfer之外,基于GAN的Style Transfer是另外一个流派。
CycleGAN是朱俊彦2017年的作品。
朱俊彦,清华本科(2012)+UCB博士(2018)。
个人主页:
http://people.csail.mit.edu/junyanz/
论文:
《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》
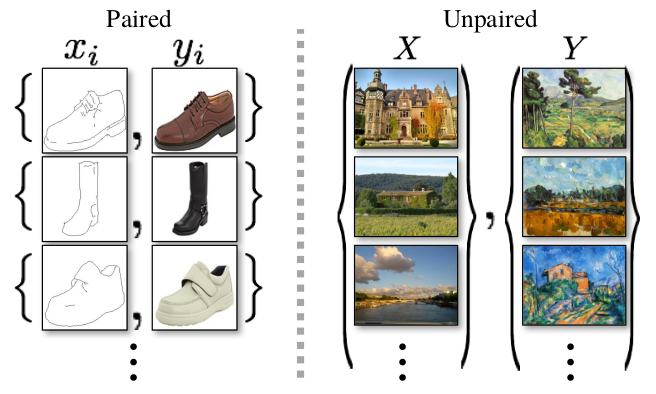
Pix2Pix要求训练数据的X和Y是成对的,因此它只适合于图片翻译任务。对于一般的Style Transfer来说,训练数据显然是不配对的,那么又该怎么办呢?
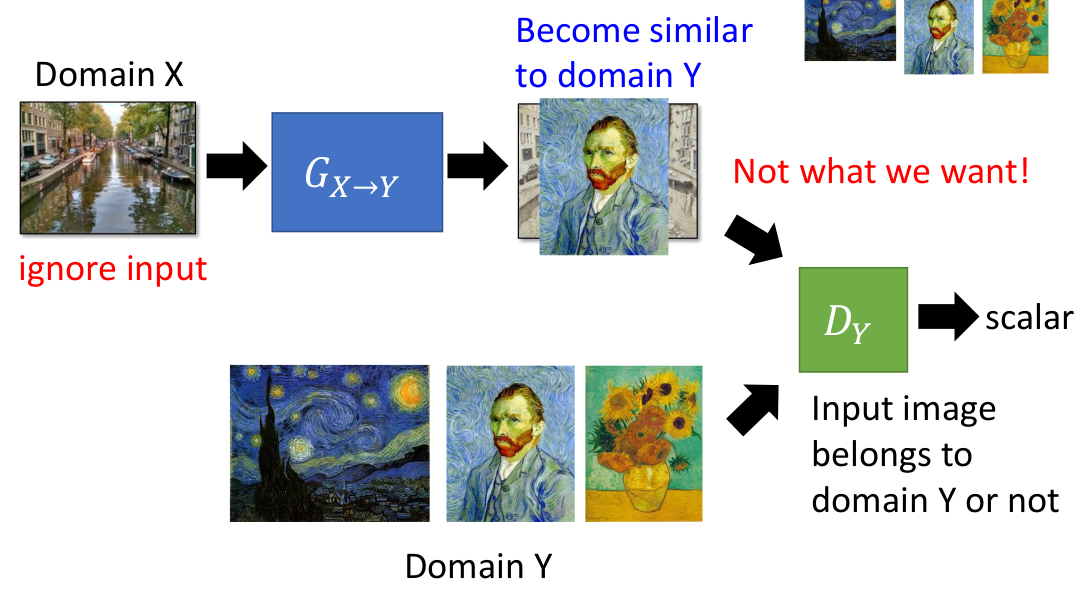
首先,简单的按照CGAN的做法,肯定是行不通的。最终生成的图片,实际上只是Y的复刻,一点X的影子都没有。
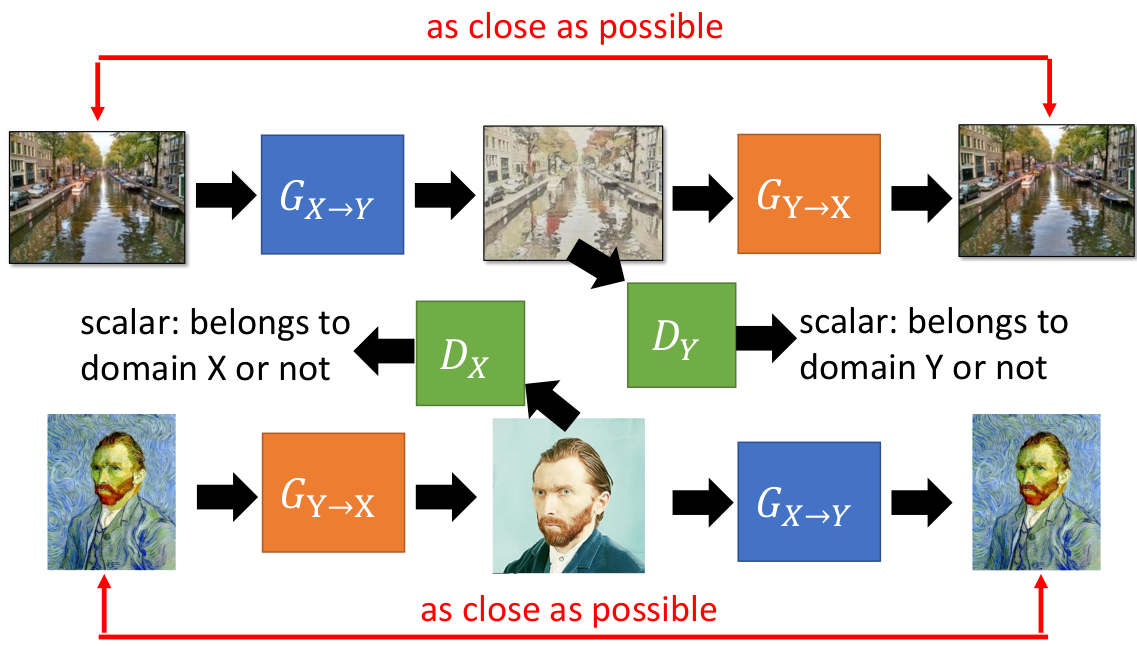
上图是CycleGAN的网络结构图。它的要点如下:
1.既然G网络缺乏配对的生成数据,那么不妨采用类似AE的手法来处理。
1)我们首先使用\(G_{X\to Y}\)将X变成Domain Y的数据\(Y'\)。
2)再使用\(G_{Y\to X}\)将\(Y'\)变成Domain X的数据\(X'\)。
3)X和\(X'\)显然是配对的,因此也就是可以比较的。
2.D网络不需要配对数据即可训练。
3.为了增加训练稳定性,我们可以交替训练两个网络:\(X\to Y'\to X'\)和\(Y\to X'\to Y'\)。其中的\(G_{X\to Y}\)和\(G_{Y\to X}\)在两个网络中的参数是相同的。
CycleGAN不仅可用于Style Transfer,还可用于其他用途。
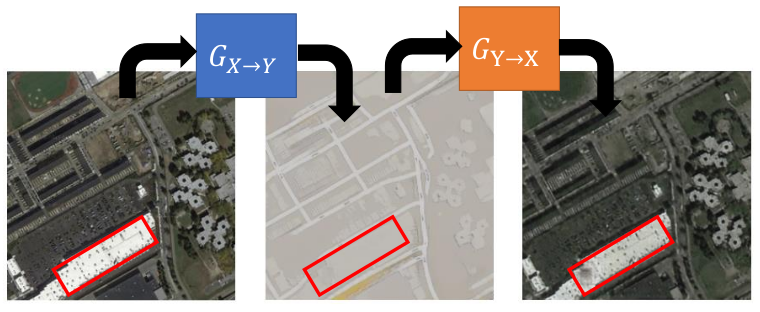
上图是CycleGAN用于Steganography(隐写术)的示例。
值得注意的是,CycleGAN的idea并非该文作者独有,同期(2017.3)的DualGAN和DiscoGAN采用了完全相同做法。
DualGAN论文:
《DualGAN: Unsupervised Dual Learning for Image-to-Image Translation》
DiscoGAN论文:
《Learning to Discover Cross-Domain Relationswith Generative Adversarial Networks》
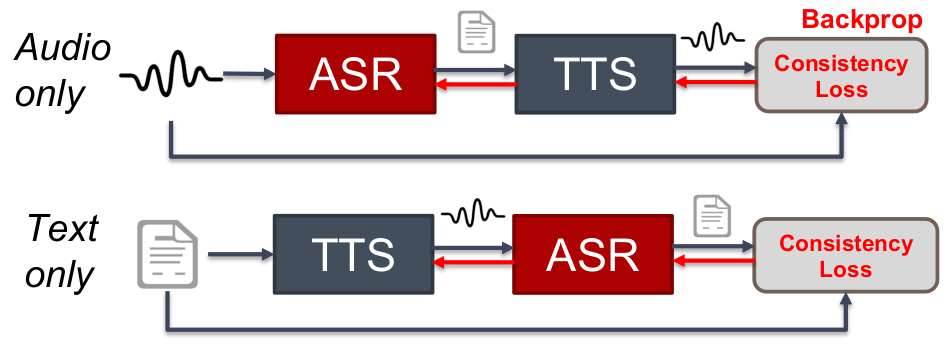
Cycle-consistency的思想也可用于其他领域。例如:
参考:
https://zhuanlan.zhihu.com/p/28342644
CycleGAN的原理与实验详解
https://mp.weixin.qq.com/s/7GHBH79kWIpEBLYX-VEd7A
CycleGAN:图片风格,想换就换
https://mp.weixin.qq.com/s/sxa0BfXtylHXzjq0YBn-Kg
伯克利图像迁移cycleGAN,猫狗互换效果感人
https://mp.weixin.qq.com/s/tzPCU1bxQ7NWtQ7o2PjF0g
BAIR提出MC-GAN,使用GAN实现字体风格迁移
https://mp.weixin.qq.com/s/A2VhfO3CkyQGCs5GqBWzOg
实景照片秒变新海诚风格漫画:清华大学提出CartoonGAN
https://mp.weixin.qq.com/s/rt4uuqh8IrZTjsYXEZvxKQ
阿里提出全新风格化自编码GAN,图像生成更逼真!
https://mp.weixin.qq.com/s/3lrCRiq5zuX9yWxiQRQE9A
CartoonGAN不靠手绘,也能成为漫画达人
https://mp.weixin.qq.com/s/PhaDqX3OT-mqyFHohDMfdA
从Pix2Code到CycleGAN:2017年深度学习重大研究进展全解读
https://mp.weixin.qq.com/s/dwEHorYSJuX9JapIYLHiXg
BicycleGAN:图像转换多样化,大幅提升pix2pix生成图像效果
https://mp.weixin.qq.com/s/VU06PqZ4OaLxpjLwIObWZw
加强版CycleGAN!贾佳亚等提出卡通图与真实人脸转换模型,看女神突破次元壁长啥样
https://mp.weixin.qq.com/s/eT7K78e2xKkTqmz67pqmEg
炫酷的图像转换:从pix2pix到CycleGAN
https://mp.weixin.qq.com/s/iFuZ8IqyrKGTxJ2ChU6NJA
CycleGAN之美:赛马翻译成斑马背后的直觉和数学
https://mp.weixin.qq.com/s/zLsIhb-KhchiWlJLnMO7Wg
循环生成网络CycleGan原理介绍
StarGAN
论文:
《StarGAN: Unified Generative Adversarial Networksfor Multi-Domain Image-to-Image Translation》
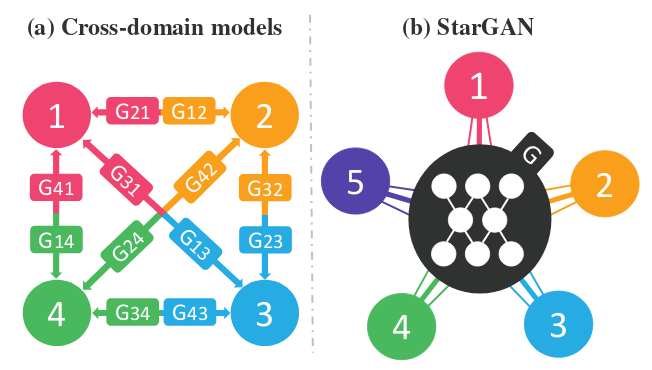
CycleGAN的局限在于:对于两个Domain之间的变换,需要两个G网络。可以想象,当Domain的数量上升时,所需G网络的个数将呈指数级增长。如上图左半部分所示。

您的打赏,是对我的鼓励
