Generative Model » GAN(七)——GAN参考资源(3), Flow-based Model
2021-01-07 :: 6280 WordsGAN参考资源
https://zhuanlan.zhihu.com/p/41114883
手机照片脑补成超大画幅,这个GAN想象力惊人
https://mp.weixin.qq.com/s/bKve_tZi9usz4oX0T3S15A
悉尼大学陶大程:遗传对抗生成网络有效解决GAN两大痛点
https://zhuanlan.zhihu.com/p/46629127
生成对抗网络-GAN—一个好老师的重要性
https://mp.weixin.qq.com/s/Sp0EYvaq-1u0mtnrrmFNCQ
为什么说GANs是一个绝妙的艺术创作工具?
https://mp.weixin.qq.com/s/uHEAtuY1_KZdUAdDAwFi_A
以为GAN只能“炮制假图”?它还有这7种另类用途
https://mp.weixin.qq.com/s/Yf5quOXmzJAy0GnJnvam5g
台湾学者研发新型二元神经元GAN!有望用于AI作曲
https://mp.weixin.qq.com/s/8aL7COItG7lS4q5-3IZCmQ
定制人脸图像没那么难!使用TL-GAN模型轻松变脸
https://mp.weixin.qq.com/s/9t0GvQW-cmakM0E9dWxBcg
旧照片着色修复神器!自注意力GAN效果惊艳
https://mp.weixin.qq.com/s/cUFQ6EADa39h2eFoa_Dh0A
最高76%破解成功率!GAN已经能造出“万能指纹”,你的手机还安全吗?
https://mp.weixin.qq.com/s/_tABIMkWX8L5xQFmvPI7rw
有效稳定对抗模型训练过程,伯克利提出变分判别器瓶颈
https://mp.weixin.qq.com/s/xr9fDv9DFkwi2ImV4RZAHg
换个角度看GAN:另一种损失函数
https://mp.weixin.qq.com/s/U1rrPfJDLgXHRj__XwrMZw
只有条件GAN才能稳定训练?对抗+自监督的无监督方法了解一下
https://mp.weixin.qq.com/s/xHKQlFFkBQLBg2GdZuGPSw
提升GAN训练的技巧汇总
https://mp.weixin.qq.com/s/ctB90bNhaMYvbLE4yketHQ
一文读懂对抗机器学习Universal adversarial perturbations
https://mp.weixin.qq.com/s/zRNtEKS2dKxyQU4VZm6Mwg
用GANs来自动生成音乐
https://mp.weixin.qq.com/s/zwzl-Tel3Avc4Dm7L5FS5A
NLP中的对抗训练+PyTorch实现
https://mp.weixin.qq.com/s/Ze2BXEexTIpNluRSdfeCsA
GAN和PS合体会怎样?东京大学图像增强新研究:无需配对图像,增强效果还可解释
https://mp.weixin.qq.com/s/qLhnvLhXHhRoPGtPWYCY0w
ICCV2019最佳论文SinGAN全面解读
https://zhuanlan.zhihu.com/p/97138846
《SinGAN:从单个自然图像中学习生成模型》论文笔记
https://mp.weixin.qq.com/s/mXjNtZvUHutBABh-f9qisQ
那些底层的图像处理问题中,GAN能有什么作为?
https://mp.weixin.qq.com/s/zVGDYhBiLCNhKTnkzbMxGA
时间序列GAN,Subadditivity of Probability Divergences
https://mp.weixin.qq.com/s/ssD3NAvGx5Eu4-oWy4KtzA
如何生动有趣地对GAN进行可视化?
https://mp.weixin.qq.com/s/qz4wUpSeF8Nlem8x4CrR-Q
学习一个宫崎骏画风的图像风格转换GAN
https://zhuanlan.zhihu.com/p/50790727
SeqGAN: Sequence GAN with Policy Gradient
https://mp.weixin.qq.com/s/bH5yYbwq6NGQJ84xUDhoxg
生成对抗网络在图像翻译上的应用
https://mp.weixin.qq.com/s/3Gsmrl4HbcnXpje0nyAq2w
中国西北大学和北京大学的研究结果是否将终结CAPTCHA验证码时代?
https://zhuanlan.zhihu.com/p/53260242
抛开复杂证明,我们从直觉上理解W-GAN为啥这么好训
https://mp.weixin.qq.com/s/FJA8Tctq_p4Mj-KgNn_OGg
为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN
https://mp.weixin.qq.com/s/SGCoCy8wJEhEpLSHrYK3pQ
韩松、朱俊彦等人提出GAN压缩法:算力消耗不到1/9,现已开源
https://mp.weixin.qq.com/s/D-rh9m7G-ERjWEEG6BQJNg
每个人都能用英伟达GAN造脸了
https://mp.weixin.qq.com/s/qRW344wWgS9PJ6UCwknS8g
Local GAN
https://mp.weixin.qq.com/s/-rwzlX-WipaIdV6ESOimxw
GAN加持!英伟达发布“山寨”游戏创造器,已完美复现《吃豆人》
https://mp.weixin.qq.com/s/orm5r4XHyotBCpBKqfZ-ng
GANSynth:使用GAN制作音乐
https://mp.weixin.qq.com/s/4zKgFfyLGAmqgHtf_Wb0nw
使用GAN生成序列数据
https://mp.weixin.qq.com/s/oRCbr0TCzFmTuf5jpWKBaA
GAN版马里奥创作家来了:一个样本即可训练,生成关卡要素丰富
https://mp.weixin.qq.com/s/2NrPolWxV-L-dFUXgGOd9w
在GAN中通过上下文的复制和粘贴,在没有数据集的情况下生成新内容
https://mp.weixin.qq.com/s/iqCMA7E_vtdymVxxz7bpRA
生成对抗网络(GAN)的数学原理全解
https://mp.weixin.qq.com/s/D0gLR6YU3rYTbFqSCwyi9Q
Semi-Supervised GAN
https://mp.weixin.qq.com/s/MY-nx_MDyBJHUidS3Xqs7g
最新《生成式对抗网络GAN进展》综述论文,41页pdf阐述GAN在计算机视觉应用进展
https://mp.weixin.qq.com/s/fQiZpUbeYvFnNZYYSE4dMQ
用GANs来做数据增强
https://mp.weixin.qq.com/s/KT_YHNLGdOI-mr4EnYgGvw
使用有限的数据来训练GANs
https://mp.weixin.qq.com/s/_cKtmNZbqHwZszocPXuy8g
让GAN随音乐律动的Python工具,网友:这是我见过的GAN的最佳用法
https://mp.weixin.qq.com/s/skDZcvuek3pAV1U07aORVA
改善图像处理效果的五大生成对抗网络
https://mp.weixin.qq.com/s/a1f_8wP0bMyNf99ihaCISg
对抗学习如何应用到推荐系统?ECIR2021<对抗学习推荐系统>教程,197页ppt
https://mp.weixin.qq.com/s/n8c2-NPtVe-k2L6qvEHsUA
改善图像处理效果的五大生成对抗网络
https://mp.weixin.qq.com/s/imOFQL01RaXUuZwew1izzg
基于GAN来做低光照图像增强,EnlightenGAN论文解读
https://zhuanlan.zhihu.com/p/637705399
VQGAN论文与源码解读:前Diffusion时代的高清图像生成模型
VAE参考资源+
https://mp.weixin.qq.com/s/0coPJFrW7anW7QuqjPBt3g
深度生成模型在信号处理领域的应用
https://mp.weixin.qq.com/s/3ZHlWlO0FdnQTnskcrz2IA
生成式模型入门:训练似然模型的技巧
https://mp.weixin.qq.com/s/KtKYk08xEqwA43Phxw2-_w
基于自编码器的通用性文本表征
https://mp.weixin.qq.com/s/hwb3eRWbwa9weCWz1ypOxw
VAE系解纠缠:从VAE到βVAE,再到β-TCVAE
https://mp.weixin.qq.com/s/yB7tq2vcBpVBnM-j9PgRsw
人脸合成效果媲美StyleGAN,而它是个自编码器
https://mp.weixin.qq.com/s/J59d1K5WX-wnzhws3k60AQ
万字长文带你了解变分自编码器VAEs
https://mp.weixin.qq.com/s/g-OPU4vp66HWcpqjdD2bBg
使用PyTorch从理论到实践理解变分自编码器VAE
https://mp.weixin.qq.com/s/8zi0JrloxuRdHcRm1dzCEQ
利用VAE和LSTM生成时间序列
Flow-based Model
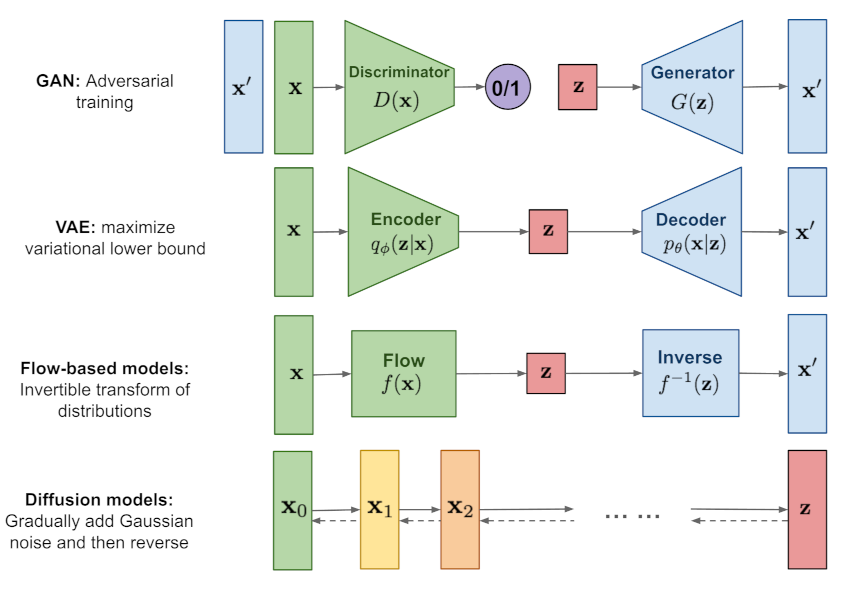
Flow-based Model是GAN和VAE之外的另一大类生成模型方法。
从表面来看,Flow-based Model和VAE非常类似,无非把Encoder和Decoder换成了Flow和它的Inverse,但是实际上两者不仅数学原理不同,具体的训练方法也有极大差异。上图说是照骗也不为过。
以下内容主要参考了李宏毅老师的课件:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2019/Lecture/FLOW%20(v7).pdf
还有以下笔记:
http://www.seeprettyface.com/pdf/Note_Flow.pdf
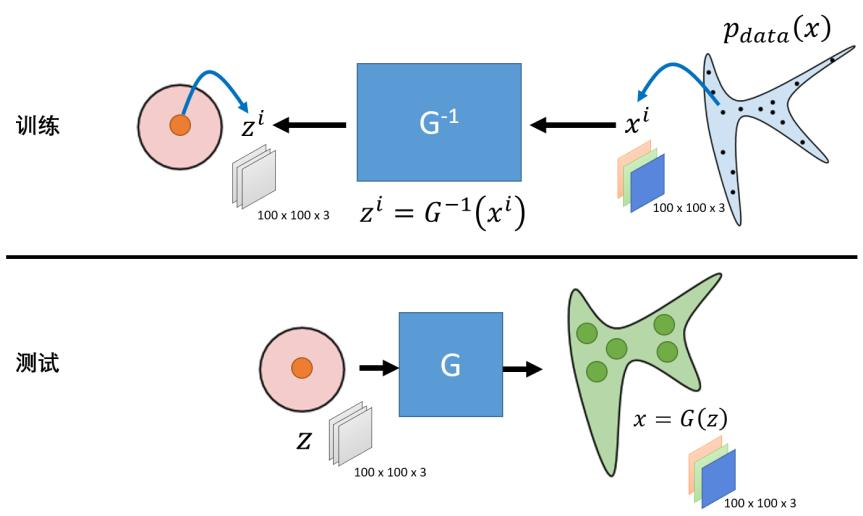
Flow-based Model的训练过程是用图片x通过网络\(f(x)\)生成随机数z。由于这个经过巧妙构造的\(f(x)\)具有可直接得到的可逆函数\(f^{-1}(z)\),所以在推理阶段,无需任何额外处理,即可直接由\(f^{-1}(z)\),从随机数z得到图片x。
随机数z可以是任意分布,但通常为了理论推导的简单,而使用正态分布,即所谓的Normalizing Flow。
Flow-based Model的理论不算复杂,难点主要在于如何构造可逆的函数G。目前已经有了一些成熟的构造方法,但相对于网络结构的千变万化,构造方法的种类就少的太多了。主流的大概也就是NICE、RealNVP和GLOW。
最初的NICE实现了从A分布到高斯分布的可逆求解;后来RealNVP实现了从A分布到条件非高斯分布的可逆求解;而最新的GLOW,实现了从A分布到B分布的可逆求解,其中B分布可以是与A分布同样复杂的分布,这意味着给定两堆图片,GLOW能够实现这两堆图片间的任意转换。
我们以NICE为例,介绍一下Flow-based Model的基本套路。
首先,\(G^{-1}\)必须是存在的且能被算出,这意味着G的输入和输出的维度必须是一致的并且G的行列式不能为0。因此,z和x的形状必须完全一致。
作为一个生成模型自然希望自己产生的数据的概率越高越好。因此这里的优化目标就是:
\[G^*=\arg \max_{G} \sum_{i=1}^m\log p_{G}(x^i)\]这里不加证明的给出结论:
\[\log p_{G}(x^i)=\log \pi(G^{-1}(x^i))+\log |det(J_{G^{-1}})|\]这里的第一项实际上就是\(\log \pi(z^i)\)。显然,当z为0时,正态分布的概率最大。
然而这会导致\(det(J_{G^{-1}})=0\),也就是第二项为\(-\infty\)。
所以z必须在两项之间平衡,才能得到最大值。这个平衡点就是我们的优化目标。
NICE采用了一种称为耦合层(Coupling Layer)的设计,如下图所示:
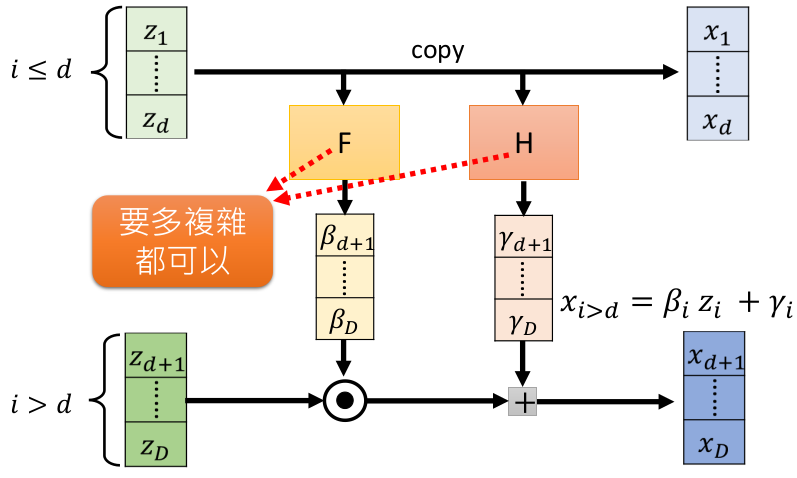
z和x都会被拆分成两个部分,分别是前1~d维和后d+1~D维。
z的1~d维直接复制(copy)给x的1~d维;z的d+1~D维分别通过F和H两个神经网络,通过仿射计算(affine)传递给x。
由于F和H的结果仅仅是系数,求偏导数的时候,会被当成常数,所以对于从\(G^{-1}\)构建G没有什么影响。
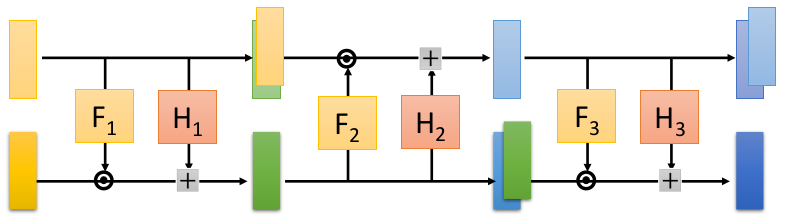
如果一层变换的表现力不足的话,我们也可以多做几层变换。需要注意的是,z的1~d维直接复制(copy)给x的1~d维的方式中的copy操作,对于生成模型的表现力会有影响。(总不可能生成图片的一部分还是随机噪声吧。)所以多层变换的话,需要使用交错的方式,组合copy操作和affine操作。
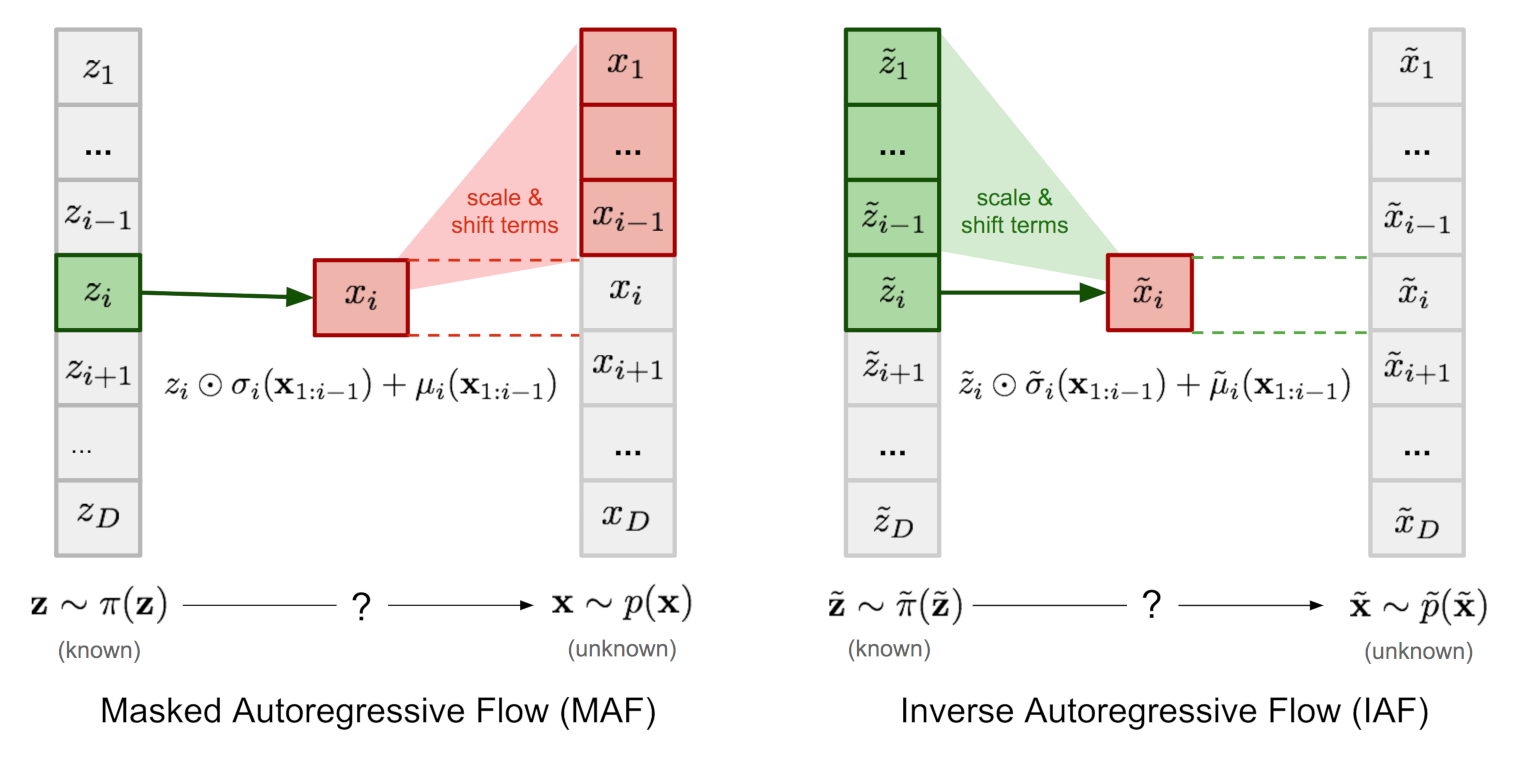
Masked Autoregressive Flow
Inverse Autoregressive Flow
参考:
https://zhuanlan.zhihu.com/p/44304684
Normalizing Flow小结
https://www.jianshu.com/p/66393cebe8ba
标准化流(Normalizing Flow)教程(一)
https://www.jianshu.com/p/db72c38233f3
标准化流(Normalizing Flow)(二):现代标准化流技术
https://mp.weixin.qq.com/s/oUQuHvy0lYco4HsocqvH3Q
Normalizing Flows入门(上)
https://mp.weixin.qq.com/s/XtlK3m-EHgFRKrtcwJHZCw
Normalizing Flows入门(中)
https://mp.weixin.qq.com/s/TRgTFBz_NmBJygQjOYwdqw
GAN/VAE地位难保?Flow在零样本识别任务上大显身手
https://mp.weixin.qq.com/s/xMO9jhzQH6P5NEA_D-uyIA
这个模型的脑补能力比GAN更强,ETH提出新型超分辨率模型SRFlow
https://zhuanlan.zhihu.com/p/351479696
基于流的生成模型-Flow based generative models
https://mp.weixin.qq.com/s/KrvW16GAxSGAPOCYYKbGUg
生成模型:标准化流(Normalized Flow)
https://lilianweng.github.io/posts/2018-10-13-flow-models/
Flow-based Deep Generative Models

您的打赏,是对我的鼓励
