VAE(三)——VAE vs GAN, VAE参考资源
2019-05-05Vanilla VAE
VAE的另一个介绍(续)
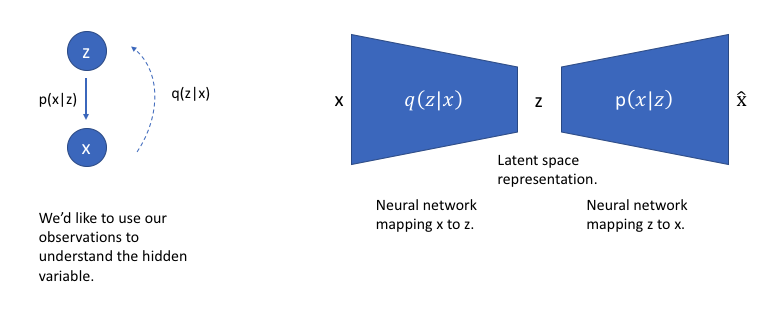
举个例子,假设我们已经在一个大型人脸数据集上训练了一个Autoencoder模型, encoder的维度是6。理想情况下, 我们希望自编码器学习面部的描述性属性,比如肤色,人是否戴眼镜,从而能够用一些特征值来表示这些属性。
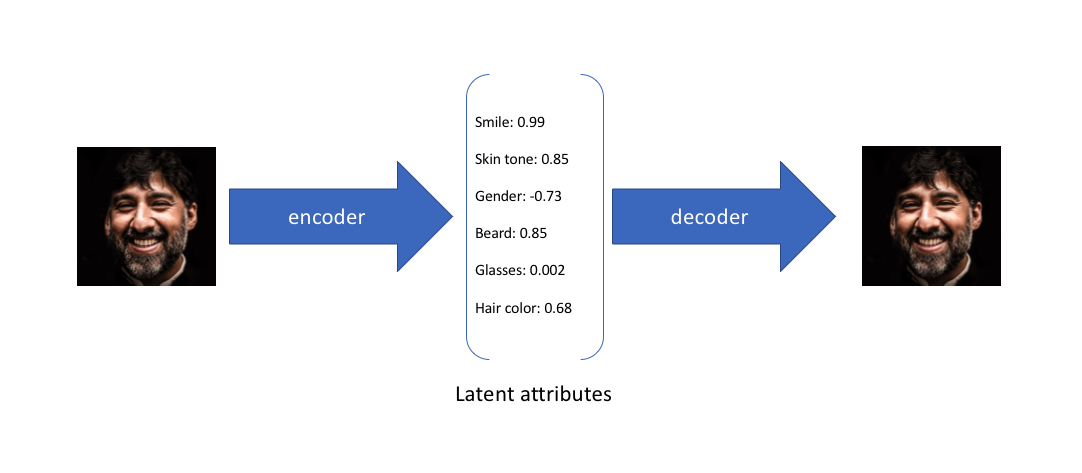
在上面的示例中,我们使用单个值来描述输入图像的隐属性。 但是,我们其实更愿意用一个分布去表示每个隐属性。 比如, 输入蒙娜丽莎的照片,我们很难非常自信的为微笑属性分配一个具体值, 但是用了变分自编码器, 我们就能比较自信的说微笑属性服从什么分布。
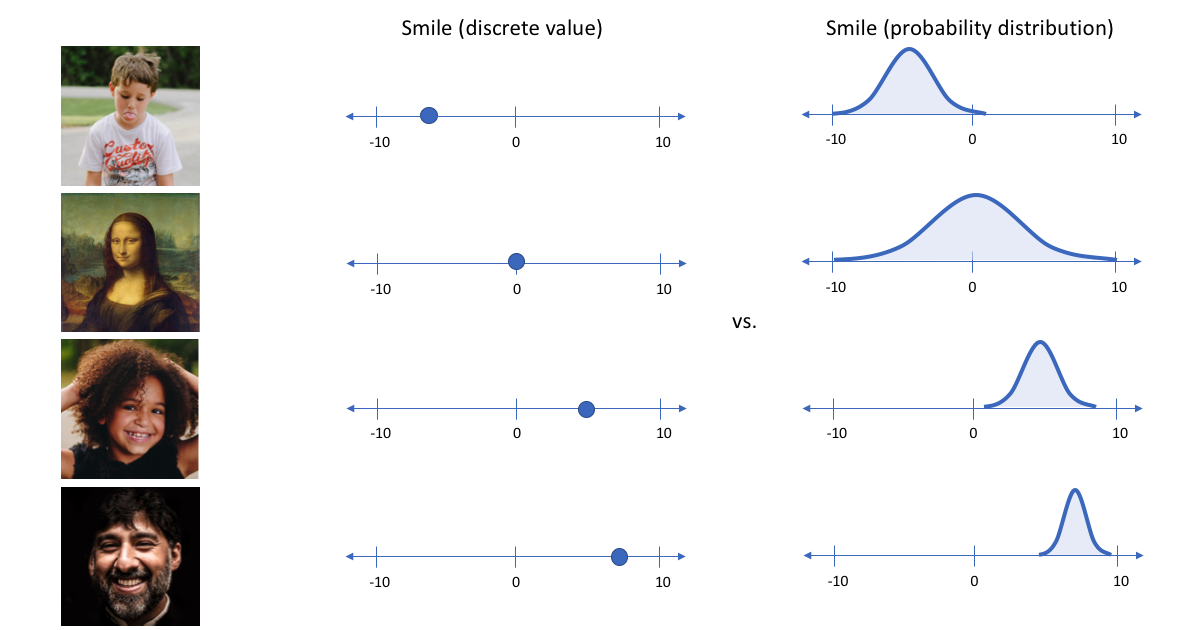
通过这种方法,我们现在将给定输入的每个隐属性表示为概率分布。 当从隐状态解码时,我们将从每个隐状态分布中随机采样,来生成向量作为解码器的输入。
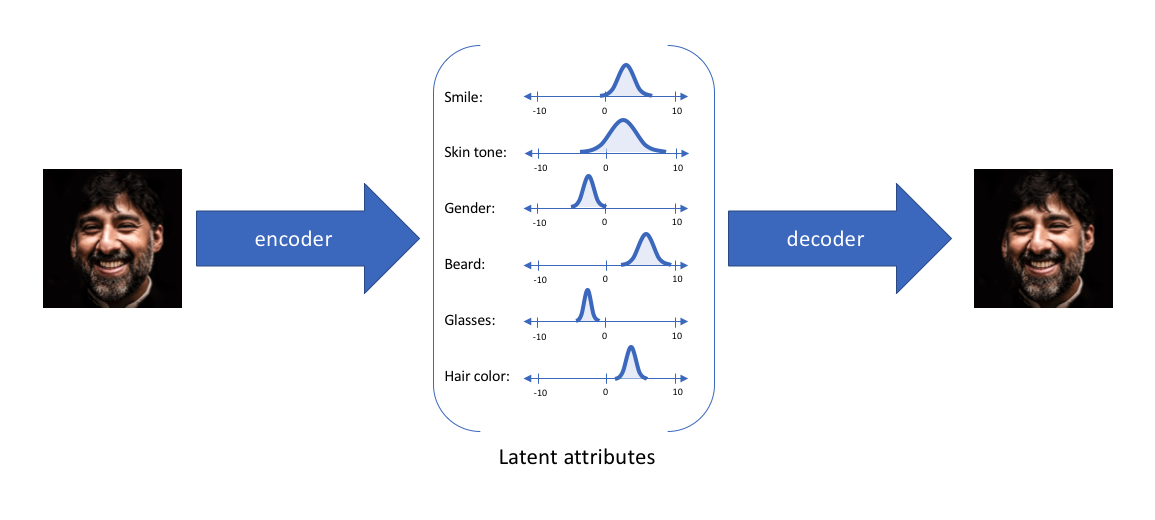
通过构造我们的编码器来输出一系列可能的值(统计分布),然后随机采样该值作为解码器的输入,我们能够学习到一个连续,平滑的隐空间。因此,在隐空间中彼此相邻的值应该与非常类似的重建相对应。而从隐分布中采样到的任何样本,我们都希望解码器理解, 并准确重构出来。
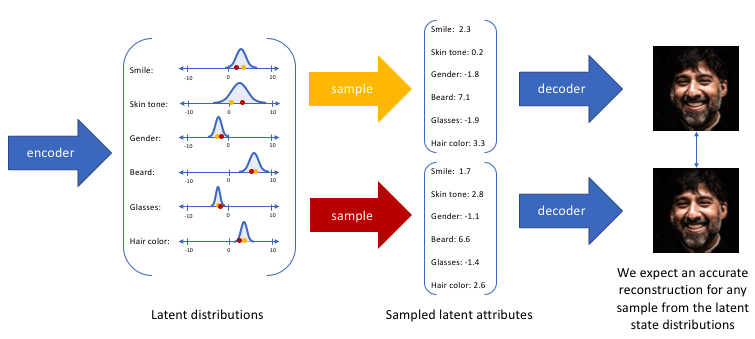
我们可以进一步将此模型构造成神经网络架构:
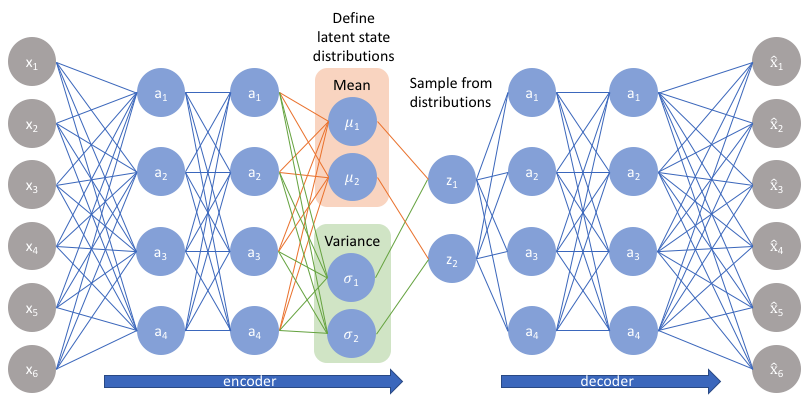
下图是VAE的结构图:
Reparameterization Trick的图示:
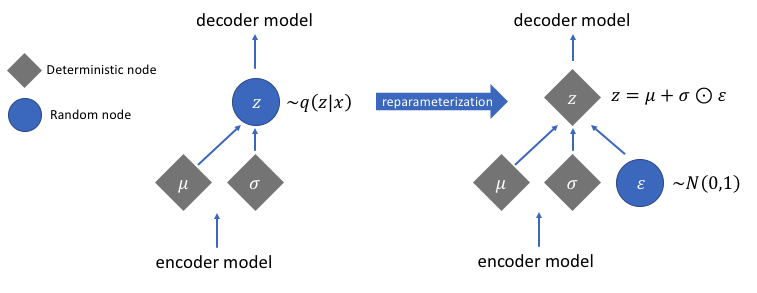
从上面两图可以看出如下几点:
1.mean tensor和variance tensor都是从上一层经FC计算得到。
2.两者的差异主要是由生成z时候的角色决定的:做加法的就是mean tensor,做乘法的就是variance tensor。
Reparameterization Trick的反向传播:
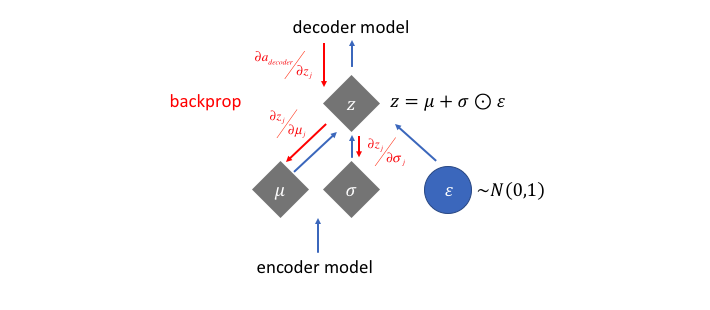
数值计算 vs 采样计算
VAE的基本概念到此差不多了,苏剑林趁热打铁又写了以下理论文章:
https://kexue.fm/archives/5343
变分自编码器(二):从贝叶斯观点出发
特将要点摘录如下。
对于不是很熟悉概率统计的读者,容易混淆数值计算和采样计算的概念。
已知概率密度函数p(x),那么x的期望也就定义为:
\[\mathbb{E}[x] = \int x p(x)dx\tag{1}\]如果要对它进行数值计算,也就是数值积分,那么可以选若干个有代表性的点\(x_0 < x_1 < \dots < x_n\),然后得到:
\[\mathbb{E}[x] \approx \sum_{i=1}^n x_i p(x_i) \left(\frac{x_i - x_{i-1}}{x_n - x_0}\right)\tag{2}\]如果从p(x)中采样若干个点\(x_1,x_2,\dots,x_n\),那么我们有:
\[\mathbb{E}[x] \approx \frac{1}{n}\sum_{i=1}^n x_i,\quad x_i \sim p(x)\tag{3}\]我们可以比较(2)跟(3),它们的主要区别是(2)中包含了概率的计算而(3)中仅有x的计算,这是因为在(3)中\(x_i\)是从p(x)中依概率采样出来的,概率大的\(x_i\)出现的次数也多,所以可以说采样的结果已经包含了p(x)在里边,就不用再乘以\(p(x_i)\)了。
生成模型近似
对于二值数据,我们可以对decoder用sigmoid函数激活,然后用交叉熵作为损失函数,这对应于\(q(x\mid z)\)为伯努利分布;而对于一般数据,我们用MSE作为损失函数,这对应于\(q(x\mid z)\)为固定方差的正态分布。
苏剑林稍后还写了以下两文,都很值得一看:
https://kexue.fm/archives/5332
基于CNN和VAE的作诗机器人:随机成诗
https://kexue.fm/archives/5383
变分自编码器:这样做为什么能成?
VAE vs AE
VAE和AE的差异在于:
1.两者虽然都是X->Z->X’的结构,但是AE寻找的是单值映射关系,即:\(z=f(x)\)。
2.而VAE寻找的是分布的映射关系,即:\(D_X\to D_Z\)。
为什么会有这个差别呢?我们不妨从生成模型的角度考虑一下。既然AE的decoder做的是Z->X’的变换,那么理论上它也可以作为生成器使用。但这里有个问题,显然不是所有的\(R^Z\)都是有效的Z,或者可以说Z只占了高维空间\(R^Z\)的一部分。Z的边界在哪里?如何得到有效的z,从而生成x?这些都不是AE能解决的。
VAE映射的是分布,而分布可以通过采样得到有效的z,从而生成相应的x。
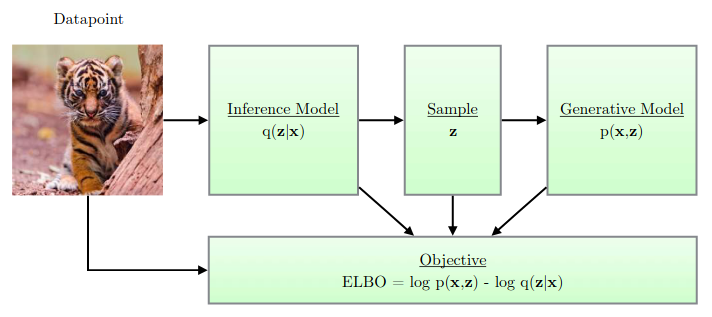
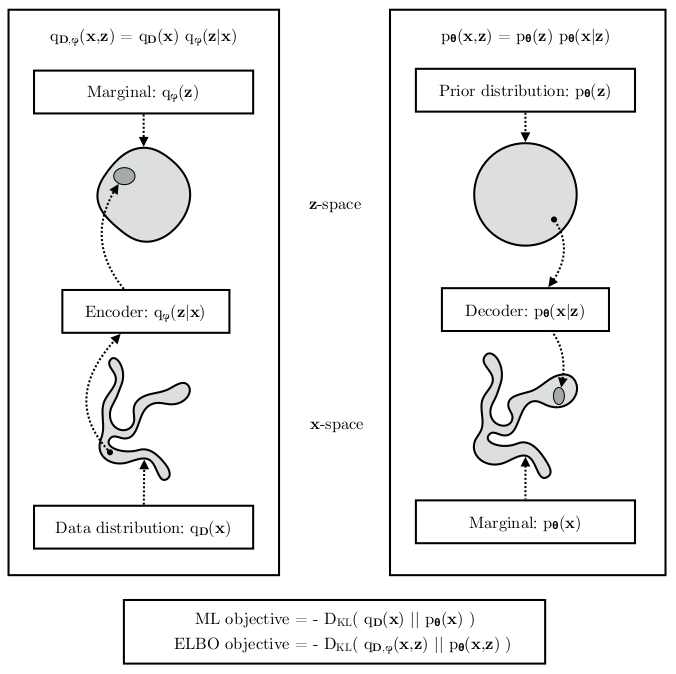
参考
https://mp.weixin.qq.com/s/COtuXSpIcujE-pxfeAbTAQ
《变分自编码器(VAE)导论》93页书册
https://mp.weixin.qq.com/s/TqZnlXLKHhZn3U29PlqetA
变分自编码器VAE面临的挑战与发展方向
https://mp.weixin.qq.com/s/mtZ4_pwl8_GhitgImAU0VA
一文读懂什么是变分自编码器
https://mp.weixin.qq.com/s/LQFuXgI7uZK2UKRfZvlVbA
Variational AutoEncoder
https://jaan.io/what-is-variational-autoencoder-vae-tutorial/
Tutorial - What is a variational autoencoder?
https://mp.weixin.qq.com/s/lnSMdOk8fYfdU4aGeI5j7Q
未标注的数据如何处理?一文读懂变分自编码器VAE
https://mp.weixin.qq.com/s/ELdemKdQixXgBAmlhagDAg
基于可变自动编码器(VAE)的生成建模,理解可变自动编码器背后的原理
https://zhuanlan.zhihu.com/p/27549418
花式解释AutoEncoder与VAE
https://mp.weixin.qq.com/s/TJDGZvAvT7KamR_WN-oYYw
如何使用变分自编码器VAE生成动漫人物形象
https://mp.weixin.qq.com/s/1q36Cb4Fy4Mg7DcrAcJv3A
双人协作游戏带你理解变分自编码器-Part1
https://mp.weixin.qq.com/s/zJf-dWsMe5WELgDz7TlivA
双人协作游戏带你理解变分自编码器-Part2
VAE的发展
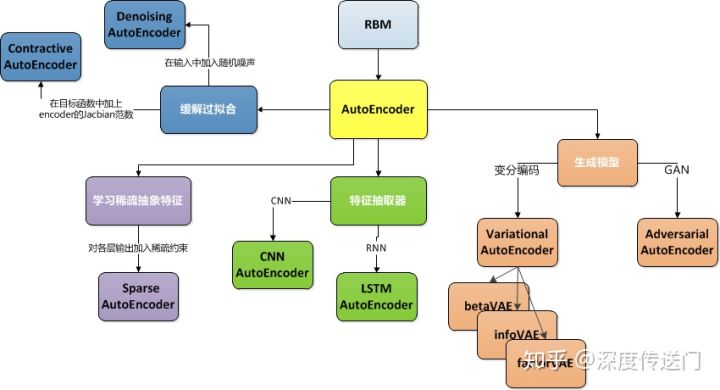
https://zhuanlan.zhihu.com/p/68903857
一文看懂AutoEncoder模型演进图谱
VAE vs GAN
VAE是直接计算生成图片和原始图片的均方误差而不是像GAN那样去对抗来学习,这就使得生成的图片会有点模糊。但是VAE的收敛性要优于GAN。因此又有GAN hybrids:一方面可以提高VAE的采样质量和改善表示学习,另一方面也可以提高GAN的稳定性和丰富度。
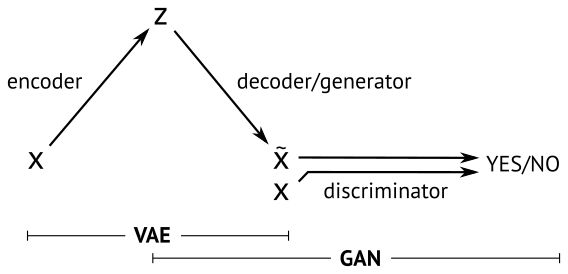
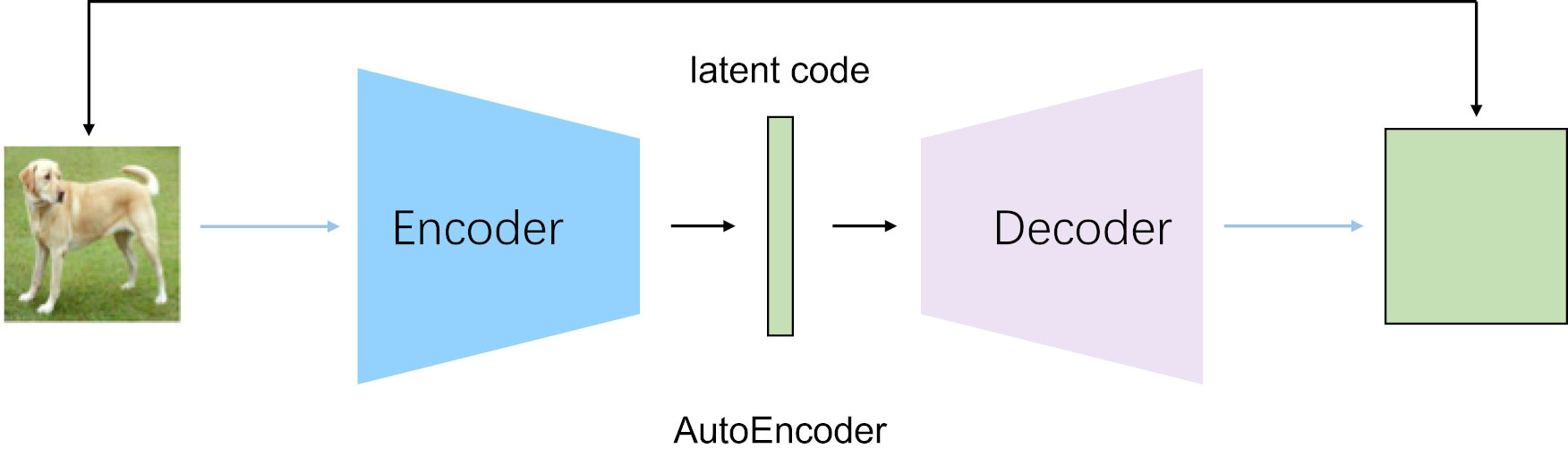
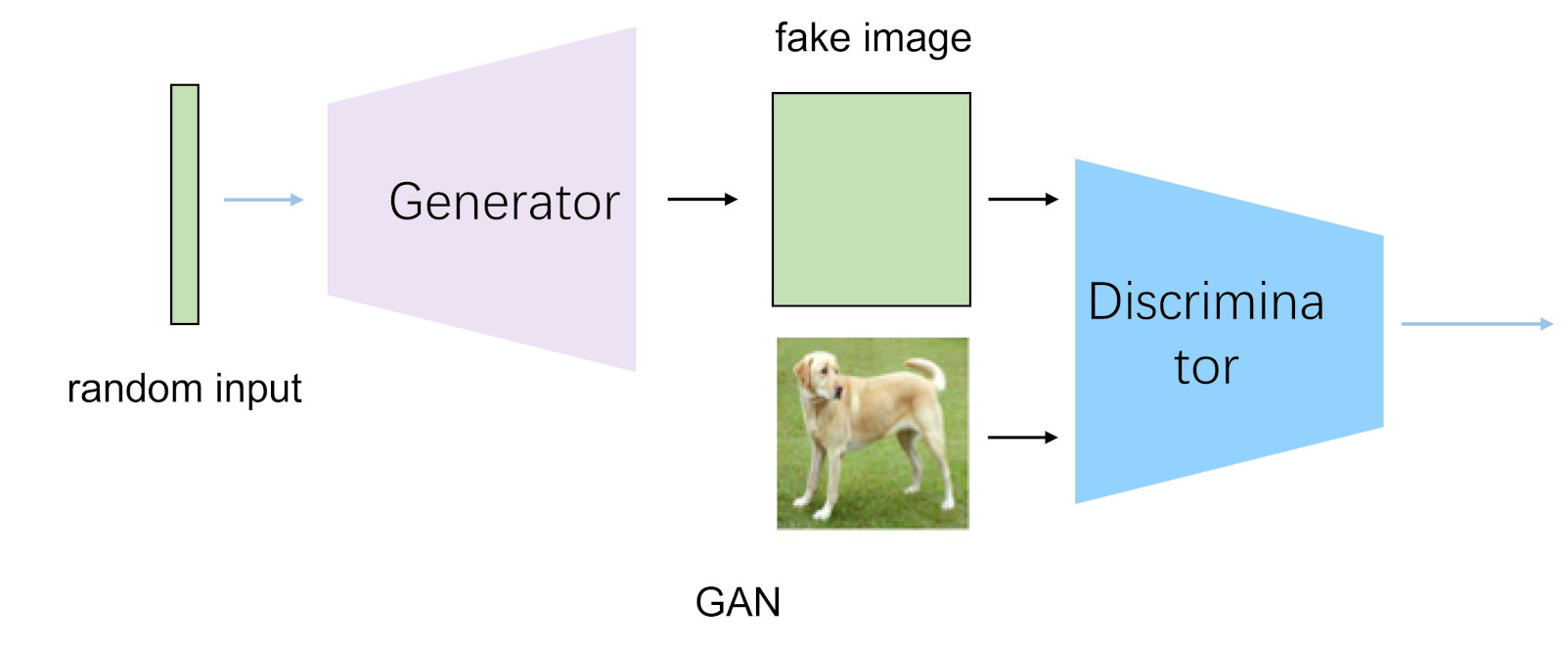
上图给出了VAE和GAN的联系和区别。
无论是VAE还是GAN,我们在接触一个新模型的时候都需要注意以下几点:
1.网络结构和训练流程。
2.Loss。
3.随机性的引入方法。
其中,第3点是生成模型特有的,必须加倍重视。
参考:
https://mp.weixin.qq.com/s/d_P-4uQx0kC2w6J69OZIAw
Deepmind研究科学家最新演讲:VAEs and GANs
https://mp.weixin.qq.com/s/9N_3JkNEPdXQgFn0S7MqnA
走进深度生成模型:变分自动编码器(VAE)和生成对抗网络(GAN)
AAE
论文:
《Adversarial Autoencoders》
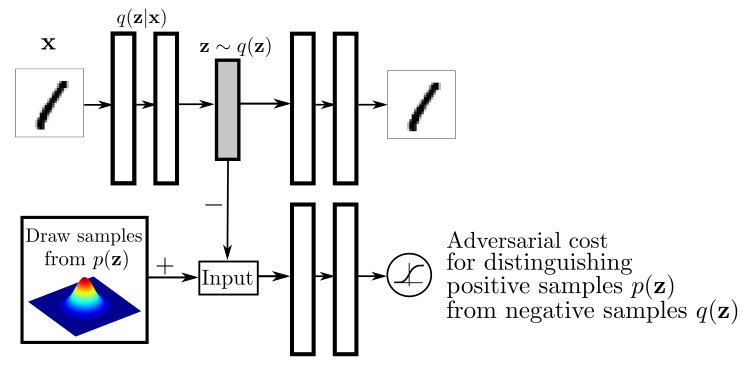
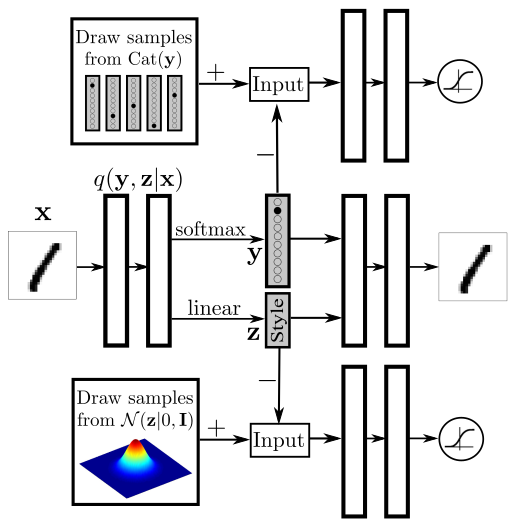
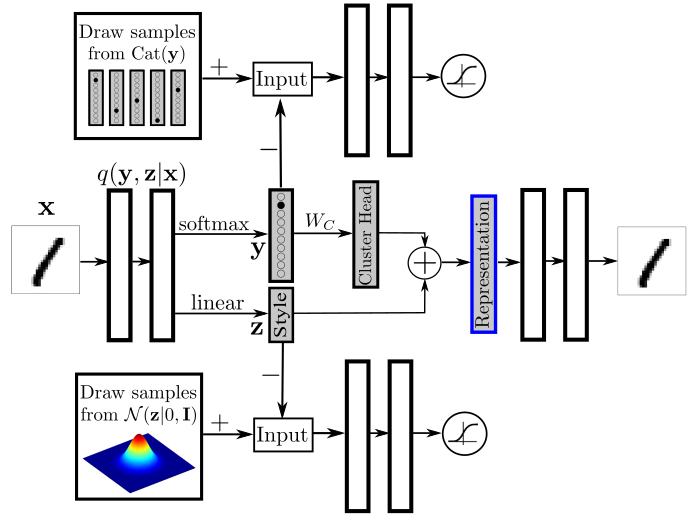
参考:
http://kissg.me/2017/12/17/papernotes03/
AAE, ALI, BiGAN
VAE-GAN
论文:
《Autoencoding beyond pixels using a learned similarity metric》
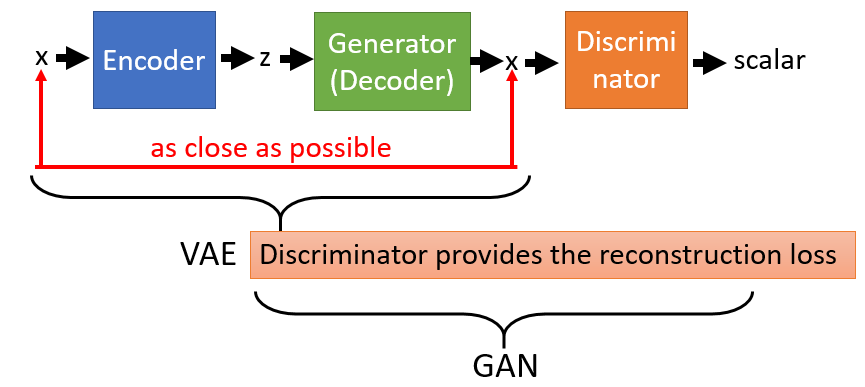
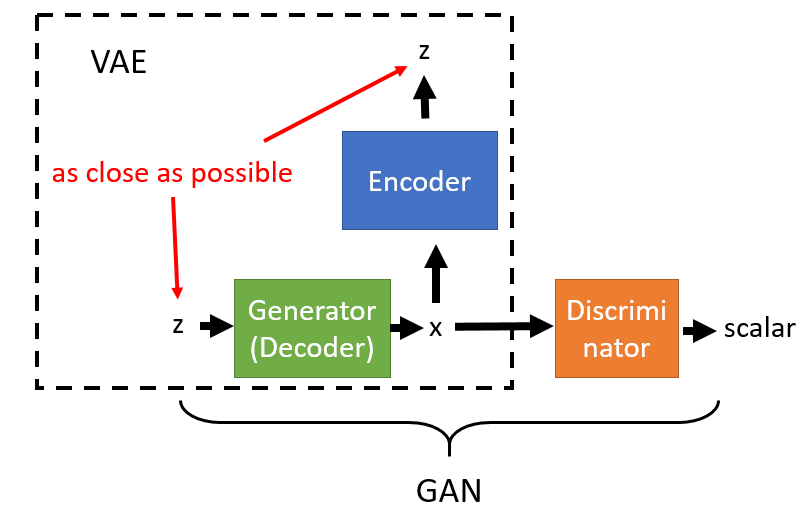
而关于VAEGAN,有趣的一点是,我们不仅可以用GANs来提升VAE,也可以用VAE来提升GANs。如果是被用作后者的话,“GANVAE”其实就等效为CycleGAN的一部分。
参考:
https://mp.weixin.qq.com/s/fzadP8NwPTxuhEB0O4GU8g
漫谈生成模型,从AE到CVAE-GAN
BiGAN
论文:
《Adversarial Feature Learning》
BiVAE
论文:
《A Variational Autoencoding Approach for Inducing Cross-lingual WordEmbeddings》
Big transformation
我们前面提到的风格转换都是比较小幅度的风格转换,有的时候我们会需要做非常大的风格转换,譬如把真人照片转成动漫照片。
VQ-VAE
https://mp.weixin.qq.com/s/t4YYIl4o_TAPG7737ZfiaA
面向无监督任务:DeepMind提出神经离散表示学习生成模型VQ-VAE
https://mp.weixin.qq.com/s/GJr-YtV84eV1KbkyVSkcBA
超越BigGAN,DeepMind提出“史上最强非GAN生成器”VQ-VAE-2
https://zhuanlan.zhihu.com/p/91434658
VQ-VAE解读
VAE参考资源
https://mp.weixin.qq.com/s/6G1y2xMclUyzz_GQzKDrIw
变分U-Net,可按条件独立变换目标的外观和形状
https://zhuanlan.zhihu.com/p/88750084
从自编码器(AE)到变分自编码器(VAE)再到条件变分自编码器(CVAE):一份小白入门基础总结
https://mp.weixin.qq.com/s/ZlLuhu08m_RnD-h86df8sA
清华大学提出SA-VAE框架,通过单样本/少样本学习生成任意风格的汉字
https://mp.weixin.qq.com/s/51Xu7osdVa-fCV-IZbHdCA
Wasserstein自编码器
https://mp.weixin.qq.com/s/0HK026K6jru10VscvT2rOQ
哈佛大学提出变分注意力:用VAE重建注意力机制
https://mp.weixin.qq.com/s/790wbFnxkNbNRampiV-0MQ
谷歌大脑提出对抗正则化方法,显著改善自编码器的泛化和表征学习能力
https://mp.weixin.qq.com/s/iOdh1iIP0GIYe4gRDE0z-g
漫谈概率PCA和变分自编码器
https://mp.weixin.qq.com/s/pBnKNRc56HhBWvrYaZjGdw
稳定、表征丰富的球面变分自编码器
https://mp.weixin.qq.com/s/QOdQKdLolR-YTihzaA81yw
黄怀波 :自省变分自编码器理论及其在图像生成上的应用
https://mp.weixin.qq.com/s/FqY9I02blg3S8_K50B7czQ
UC伯克利提出小批量MH测试:令MCMC方法在自编码器中更强劲
https://zhuanlan.zhihu.com/p/48985202
谈谈变分自编码器背后的数学知识
https://mp.weixin.qq.com/s/fYR2dS3wCMMVk3s9O4nqUw
自编码表示学习 25页最新进展综述,90篇参考文献
https://zhuanlan.zhihu.com/p/52974147
VAE的细节:\(p(x \mid z)\)的噪音,与\(p(z \mid x)\)的编码坍塌
https://mp.weixin.qq.com/s/uNjF6NxVRs_gAKAmxRpThQ
华为美研所提出自动编码变换网络AET:用无监督逼近全监督效果
https://zhuanlan.zhihu.com/p/60330303
用于协同过滤的变分自编码器论文引介
https://mp.weixin.qq.com/s/CSx7dnqPjVDAvM6ena-FTw
从俄罗斯方块到星际2,全都用得上:DeepMind无监督分割大法,为游戏而生
https://mp.weixin.qq.com/s/XMLYjw_wN-M8jluczkbcyw
一种考虑缓和KL消失的简单VAE训练方法
https://mp.weixin.qq.com/s/0coPJFrW7anW7QuqjPBt3g
深度生成模型在信号处理领域的应用
https://mp.weixin.qq.com/s/3ZHlWlO0FdnQTnskcrz2IA
生成式模型入门:训练似然模型的技巧
https://mp.weixin.qq.com/s/KtKYk08xEqwA43Phxw2-_w
基于自编码器的通用性文本表征
https://mp.weixin.qq.com/s/hwb3eRWbwa9weCWz1ypOxw
VAE系解纠缠:从VAE到βVAE,再到β-TCVAE
https://mp.weixin.qq.com/s/yB7tq2vcBpVBnM-j9PgRsw
人脸合成效果媲美StyleGAN,而它是个自编码器
https://mp.weixin.qq.com/s/J59d1K5WX-wnzhws3k60AQ
万字长文带你了解变分自编码器VAEs
https://mp.weixin.qq.com/s/g-OPU4vp66HWcpqjdD2bBg
使用PyTorch从理论到实践理解变分自编码器VAE
https://mp.weixin.qq.com/s/8zi0JrloxuRdHcRm1dzCEQ
利用VAE和LSTM生成时间序列

