technology » 音频常识, Kannel, ZeroC ICE, 分布式ID生成器, BBR
2018-02-06 :: 5642 Words音频常识
人的听觉范围
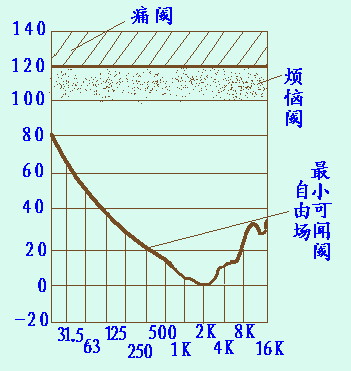
图上的上限是到16KHz,但并不是说16KHz以上听不到了,因为高频听力随着年龄增长而减弱直到丧失,一般来说25岁以上的人,在16KHz以上的听力几乎完全丧失,而10几岁的人,完全可以听到19KHz左右的声音(这就是有一种传说中的蚊音手机铃声神马的,在中学生间流传很广,据说老师听不到只有学生能听到,也是基于这个道理)。
各种编解码算法比较
http://www.rosoo.net/a/201012/10600.html
speech codec (G.711, G.723, G.726, G.729, iLBC)
这个帖子比较了ITU提出的G系列的各种语音编解码方案。
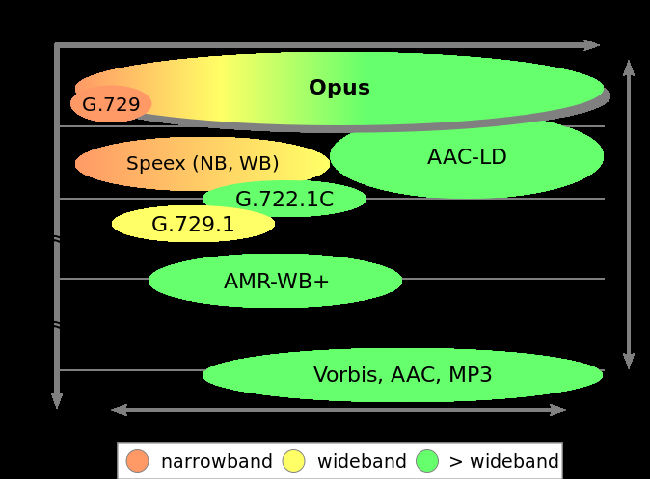
上图是各种音频编解码框架的比较图。
其中narrowband是指频率在4kHz以下的声音信号,一般情况下,人的说话声就位于这个频率范围内,因此又被称为“语音”。
allband是指频率在24kHz以下的声音信号。这也是人耳所能听到的频率范围。这个范围内的声音统称“音频”。
介于两者之间的,被称为wideband。
早年上网用的Modem,之所以速度上限仅为56kbs,其实主要是因为它占用的是普通电话信道,而56kbs对于电话来说,已经是绰绰有余了。
声道
声道一般表示为X.Y的形式,其中X为高音音箱的个数,Y为低音音箱的个数。比如常见的2.1声道,就是左音箱、右音箱+低音音箱(俗称低音炮)。
一般来说,Y的值为0或1。而X的值,有以下几种:
1.X=1。单声道
2.X=2。左、右。
3.X=4。前左、前右,后左、后右。
4.X=5。前左、前右,后左、后右、中置。
5.X=7。前左、前右,后左、后右、中置、中左、中右。
数字功放
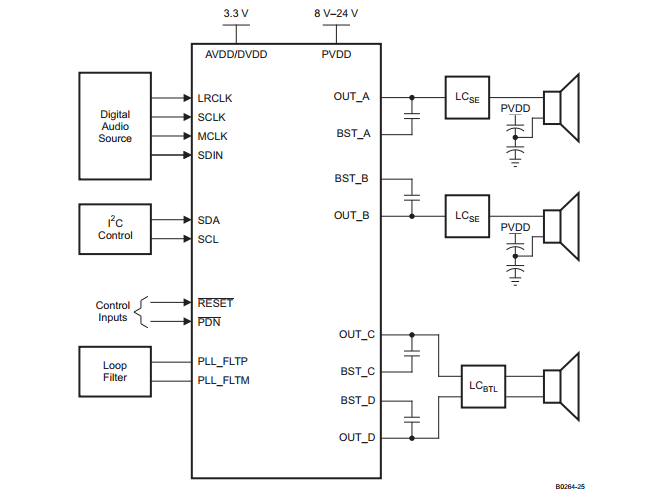
上图是TI TAS5731M的2.1声道应用图。
其中的SE,表示单端连接模式(Single-End),和桥接式负载 BTL(Bridge-Tied-Load)相对应。后者在同等供电电压和负载的情况下,可以提供4倍于SE的输出功率,并具有良好的低频响应,常用于连接低音音箱。
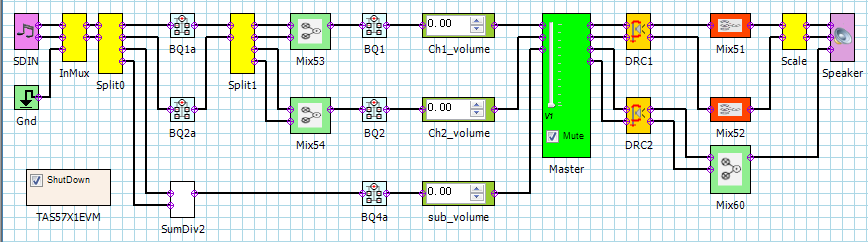
这是TI TAS5731M数字音频的处理流程,其中上两路是高音声道,最下面一路是低音声道。
IIS
亦称I2S。Inter—IC Sound总线是飞利浦公司为数字音频设备之间的音频数据传输而制定的一种总线标准,该总线专责于音频设备之间的数据传输,广泛应用于各种多媒体系统。
I2S总线由4根线组成:
1.SDATA。数据线,根据方向的不同,又分为SDO和SDI。一根数据线可以传输两个声道的数据,但对于当前越来越多的声道来说,这显然就不够用了。因此目前的MCU设计中,多数都集成了更多的SDO线。这些SDO线共享各种时钟线。多SDO线的DMA传输,一般采用时分复用的交错数据流的方式来设置。
2.LRCK,(也称WS)。帧时钟,用于切换左右声道的数据。LRCK为“1”表示正在传输的是右声道的数据,为“0”则表示正在传输的是左声道的数据。LRCK的频率等于采样频率。
3.SCLK,也叫位时钟(BCLK)。1个脉冲对应数字音频的每一位数据。SCLK的频率=2×采样频率×采样位数。
4.MCLK,称为主时钟,也叫系统时钟(Sys Clock),是采样频率的256倍或384倍。它可以使系统间能够更好地同步。
I2S总线的性能主要由以下指标决定:
1.采样频率。根据上面对narrowband、wideband、allband的讨论,以及采样定理可知,采样频率最低为8kHz,超过48kHz可以算是allband。
2.采样位数。越大越好。目前数字功放(如TI TAS5731M)已经可以支持24bit和32bit,但wifi芯片基本还是16bit的。
I2S总线的时序标准分为三种:
1.I2S。
2.Left-Justified
3.Right-Justified
I2S总线在硬件测试时,可播放1KHz正弦波的wav文件。这个wav文件的频率,在人的声觉最敏感的范围(1KHz~4KHz)内,同时也便于示波器观察模拟端的输出信号。
文件后缀名与编码格式
| 文件后缀名 | 音频编码(空表示编码格式和文件后缀名一致) | 视频编码(空表示该格式没有视频数据) |
|---|---|---|
| .aac .ac3 .ape .mp2 .mp3 .flac .wma | ||
| .au | pcm_s16be | |
| .wav | pcm_s16le pcm_float | |
| .ogg | vorbis | |
| .m4a | mpeg4 aac | |
| .3gp | mpeg4 | amr_nb |
| .3g2 | mpeg4 | mpeg4 aac |
| .asf | msmpeg4 | mp3 |
| .mov | mpeg4_qt | mpeg4 aac_qt |
| .rm | rv10 | ac3 |
| .vob | mpeg2 | ac3 |
| .wmv | wmv | wma |
常用格式中的.avi .mp4,由于支持的编码格式众多,且没有主要的使用格式,故不列出。
术语
Pre-emphasis,预加重。与之对应的是De-emphasis去加重。是一项关于噪声整形的技术。
开源音频编解码包
1.Speex
http://speex.org/
一个老项目,教程多,但官方已经放弃,转而推荐Opus。
2.Opus
http://opus-codec.org/
最近的一个新项目,基于IETF RFC 6716(2012.9)。由于比较新,教程很少。
3.G.726等一系列算法代码
http://www.itu.int/rec/T-REC-G.191-201003-I/en
ITU官网上的工具包,包含了G.711和G.726算法。
Kannel
Kannel是一个开源的WAP&SMS网关项目。
官网:
http://www.kannel.org/
这里提到这个项目,并非它有多么重要——实际上它从2010年之后就几乎没有更新了,最新的版本定格在2014年。它所代表的WAP已经无人问津,至于SMS吧,似乎又用不到这么复杂的框架。
但我之所以要提它,主要在于情怀。2007年底的时候,公司给我安排了一个在App中集成彩信发送功能的任务。当时由于能力尚浅,虽然努力了一个月,最终却没有实际成果,很是让领导质疑了一阵,幸好接手的哥们同样做不出来,而我的下一个任务——使用jpeglib,获得了成功,才算将事情平息下来。
过了一年,闲暇无聊之际,旧事重提,于是发现了Kannel,并做了一个demo。可惜公司时局变化,这一切都变得无足轻重了。
ZeroC ICE
我在研究生时代,研究过CORBA、EJB、COM这样的中间件技术。然而工作以后,再没有机会使用。平时偶尔关注,也只是晓得CORBA从来没有流行过,EJB在Struts、Hibernate、Spring等框架的围攻下,用者寥寥。直到最近,因为项目需要接触到ZeroC的ICE框架。
ICE框架的官网地址:
https://zeroc.com/downloads/ice
安装:
wget https://zeroc.com/download/GPG-KEY-zeroc-release
sudo apt-key add GPG-KEY-zeroc-release
sudo apt-add-repository "deb http://zeroc.com/download/apt/ubuntu16.04 stable main"
sudo apt update
sudo apt install zeroc-ice-all-runtime zeroc-ice-all-dev
sudo apt install libssl-dev
pip install zeroc-ice
多语言demo:
https://github.com/zeroc-ice/ice-demos
注意demo的master分支是开发分支,好多代码都是有问题的,请切换到正在使用版本的分支,例如:
git checkout 3.6
2022.7
和CORBA竞争的MS的DCOM也好不到哪里去。唯一用的多的,主要在工控领域。
OPC DA在其发展时,建立在当时的Windows技术:OLE、ActiveX、COM/DCOM 之上。但此后行业发生了变化,其他操作系统和技术也开始流行。
COM是微软投入C++门下后给C++打的一个超大补丁用来解决C++的ABI没有标准的问题。
https://zhuanlan.zhihu.com/p/426818530
聊聊越来越火的OPC DA OPC UA的标准
https://www.zhihu.com/question/19998748
COM过时了吗?它的应用前景究竟如何?
https://www.zhihu.com/question/49433640
怎么通俗的解释COM组件?
Hprose
Hprose是ZeroC ICE的一个竞争者,由国内某高手打造,支持的语言超过20种,堪称最全。不过貌似没什么大公司用啊。。。
其标榜的无需生成桩代码的优点,相比ZeroC ICE的老版本来说,的确是个进步。但目前的ZeroC ICE 3.6版本,也同样提供了类似的功能。这或者也是Hprose一直火不起来的原因。
官网:
http://hprose.com/
Github:
https://github.com/hprose
分布式ID生成器

这种结构是雪花算法提出者Twitter的分法。百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
参考:
http://mp.weixin.qq.com/s/Bk5k6vRG4Rq4iCtmtYDEGQ
Leaf——美团点评分布式ID生成系统
https://mp.weixin.qq.com/s/6J7n3udEyQvUHRHwvALNYw
Leaf:美团分布式ID生成服务开源
https://mp.weixin.qq.com/s/_z0-90xbsCd4Pdi6UlEvnA
分布式ID生成器
https://mp.weixin.qq.com/s/Yk2ZlGCEINGrsTfHI6zpsw
分布式id生成器
https://mp.weixin.qq.com/s/E3PGP6FDBFUcghYfpe6vsg
唯一ID生成算法剖析
https://mp.weixin.qq.com/s/ZbZRMFjbl5oG8yncv8hCtQ
认识“雪花ID”:如何在分布式环境中大规模生成唯一ID?
https://mp.weixin.qq.com/s/F7WTNeC3OUr76sZARtqRjw
分布式架构系统生成全局唯一序列号的一个思路
BBR
Bottleneck Bandwidth and Round-trip propagation time是Google于2016年10月提出的TCP拥塞控制算法,其相关代码目前已经加入Linux内核中。
经典的拥塞控制算法设计于1980年代,当时将丢包作为拥塞的信号,这是符合当时落后的实际情况的。
但是网络丢包存在两种情况:第一为拥塞丢包,第二为错误丢包。因此丢包通常并不等同于拥塞。
随着带宽的增加,第一类丢包已经大为减少。目前广域网普遍属于高带宽,高延迟的情况。这种情况术语叫做长肥管道(long-fat pipe,即延迟高、带宽大的链路)。
BBR就是针对长肥管道而设计的新式算法。
参考:
http://netdevconf.org/1.2/slides/oct5/04_Making_Linux_TCP_Fast_netdev_1.2_final.pdf
Making Linux TCP Fast
https://www.zhihu.com/question/53559433
Linux Kernel 4.9 中的BBR算法与之前的TCP拥塞控制相比有什么优势?
https://zhuanlan.zhihu.com/p/144273871
TCP拥塞控制详解
http://blog.csdn.net/dog250/article/details/52895080
Google’s BBR拥塞控制算法模型解析
https://zhuanlan.zhihu.com/p/24431669
BBR是个什么鬼?-1 带宽与RTT探测
https://zhuanlan.zhihu.com/p/26321951
BBR是个什么鬼?-2 外皮后的真相
https://mp.weixin.qq.com/s/NWNMfykpJQ-LD9oV1X6zTw
基于bbr拥塞控制的云盘提速实践
https://mp.weixin.qq.com/s/P3zAW3lxj8aowXtxXCOwqA
Google BBR拥塞控制算法背后的数学解释

您的打赏,是对我的鼓励
