Recommender System » 推荐系统(二)——常用排序算法, 用户画像, 工程细节(1)
2020-01-03 :: 5848 Words推荐算法中的常用排序算法
Pointwise方法
Pranking (NIPS 2002), OAP-BPM (EMCL 2003), Ranking with Large Margin Principles (NIPS 2002), Constraint Ordinal Regression (ICML 2005)。
Pairwise方法
Learning to Retrieve Information (SCC 1995), Learning to Order Things (NIPS 1998), Ranking SVM (ICANN 1999), RankBoost (JMLR 2003), LDM (SIGIR 2005), RankNet (ICML 2005), Frank (SIGIR 2007), MHR(SIGIR 2007), Round Robin Ranking (ECML 2003), GBRank (SIGIR 2007), QBRank (NIPS 2007), MPRank (ICML 2007), IRSVM (SIGIR 2006)。
Listwise方法
LambdaRank (NIPS 2006), AdaRank (SIGIR 2007), SVM-MAP (SIGIR 2007), SoftRank (LR4IR 2007), GPRank (LR4IR 2007), CCA (SIGIR 2007), RankCosine (IP&M 2007), ListNet (ICML 2007), ListMLE (ICML 2008) 。
LambdaMART
https://www.zhihu.com/question/41418093
求解LambdaMART的疑惑?
https://liam0205.me/2016/07/10/a-not-so-simple-introduction-to-lambdamart/
LambdaMART不太简短之介绍
http://blog.csdn.net/huagong_adu/article/details/40710305
Learning To Rank之LambdaMART的前世今生
参考
https://lumingdong.cn/learning-to-rank-in-recommendation-system.html
推荐系统中的排序学习
https://mp.weixin.qq.com/s/YjYVE6jzySVsZmXSPivB5w
达观数据搜索引擎排序实践(上篇)
https://mp.weixin.qq.com/s/UpN7tAMjbFLSPcDYsWaykg
达观数据搜索引擎排序实践(下篇)
https://mp.weixin.qq.com/s/xigME-griWFwEvvPNqWuvg
美团点评联盟广告的场景化定向排序机制
https://blog.csdn.net/stdcoutzyx/article/details/50879219
Learning to Rank简介
http://www.cnblogs.com/wentingtu/archive/2012/03/13/2393993.html
Learning to Rank入门小结
https://blog.csdn.net/anshuai_aw1/article/details/86018105
排序学习(Learning to rank)综述
https://mp.weixin.qq.com/s/dRaiYPIdh_oJcQD-UxAlkA
优秀的排序算法如何成就了伟大的机器学习技术
https://mp.weixin.qq.com/s/XT4_E2d2gr1T8jCo82ix4A
深入浅出排序学习:写给程序员的算法系统开发实践
https://zhuanlan.zhihu.com/p/64952093
排序评价指标
https://zhuanlan.zhihu.com/p/64970393
PointwiseRank
https://zhuanlan.zhihu.com/p/65224450
PairwiseRank
https://zhuanlan.zhihu.com/p/66514492
ListwiseRank
https://zhuanlan.zhihu.com/p/69246361
基于query的排序
https://www.zhihu.com/question/26933554
如何评价知乎的回答排序算法?(威尔逊置信区间下界)
https://mp.weixin.qq.com/s/yQs8Mhe0kM6XMA7JfjRuPA
达观数据推荐系统算法实践—重排序
https://mp.weixin.qq.com/s/vO1lhVQuvIGwJpqg7V2SfA
LTR排序算法LambdaRank原理详解
https://mp.weixin.qq.com/s/AWXD21HU8gFSbX6F5fHmtQ
浅谈Learning to Rank中的RankNet和LambdaRank算法
用户画像
https://mp.weixin.qq.com/s/TydTE50NzxMbGAigqv6BCw
如何破解“千人千面”,深度解读用户画像
https://mp.weixin.qq.com/s/bdAp_FExIK5IJH8WnD53Wg
你真的懂用户画像吗?
https://mp.weixin.qq.com/s/LN6ib-8b_SZHR9u_-OMwNg
推荐系统眼中的你:内容画像与用户画像
https://mp.weixin.qq.com/s/95Zklj8ovheQV3Gnc-2h-Q
小米大数据总监司马云瑞详解小米用户画像的演进及应用解读
https://mp.weixin.qq.com/s/iuchckQ-MRqSZ2QwghgPTQ
浅谈“用户画像”
https://mp.weixin.qq.com/s/ptI6cBxtykTQoljZR94RTw
从入门到冠军:中国移动人群画像赛TOP1经验分享
https://mp.weixin.qq.com/s/mSBwsMpOcn4RyVsyWSaYnQ
用户画像必会的行为偏好计算方法
https://mp.weixin.qq.com/s/lD1UCWLKc8yzEQBDZ3htRw
用户画像技术及方法论
https://mp.weixin.qq.com/s/MFKYddfINEQnUO-WPTTdGg
用户画像基础
https://mp.weixin.qq.com/s/-VVM5RIRdPOgA4MscwQ7MQ
推荐系统之用户画像基础
https://mp.weixin.qq.com/s/jyiDWiK0zczEaZKY5Hy5xg
网易大数据用户画像实践
https://mp.weixin.qq.com/s/pmovTV3TIoB6oA60pL_zeg
网易严选画像建设实践
https://mp.weixin.qq.com/s/YJG8PXBgljJvtttXy2cDmA
用户画像初探
https://mp.weixin.qq.com/s/Nl79i9agMuyJl885ybphVg
用户画像实践篇
推荐系统的工程细节
推荐系统不仅是算法,还包括若干工程细节。这些细节虽然不算复杂,够不上算法的层面,然而对产品的成败,却有举足轻重的作用。
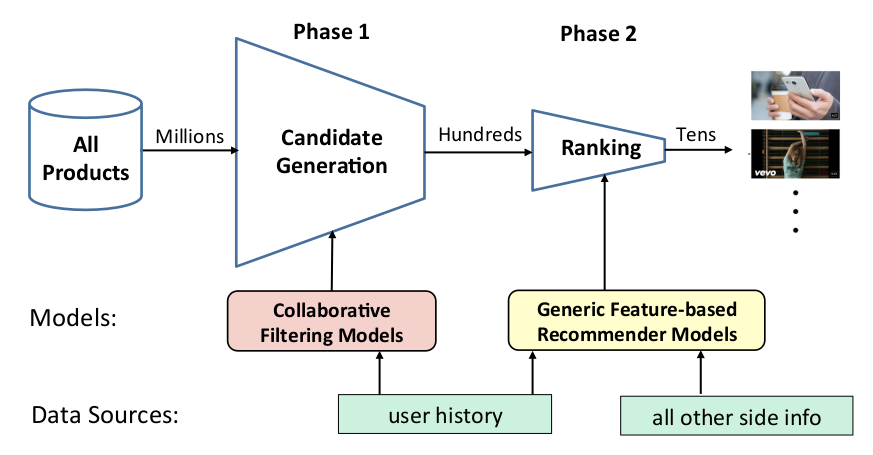
一般架构
用户数据
用户自然特征:性别,年龄,地域,教育水平,出生日期,职业,星座
用户兴趣特征:兴趣爱好,使用网站,浏览/收藏内容,互动内容,品牌偏好,产品偏好
用户社会特征:婚姻状况,家庭情况,社交/信息渠道偏好
用户消费特征:收入状况,购买力水平,已购商品,购买渠道偏好,最后购买时间,购买频次
评价推荐质量
以今日头条类的新闻推荐为例,评估指标一般为:
1.平均转化率(点击量/曝光量)
2.人均阅读篇数(点击PV/点击UV)
3.平均阅读完成率
4.人均阅读时长(这个会受文章长度影响)
5.用户互动数据(评论、分享)
对评估指标的选取一般遵循以下原则:
1.用户满意度。
2.预测准确度。
3.覆盖率。
4.多样性。
5.新颖性。
6.惊喜度。
7.信任度。
8.实时性
9.鲁棒性
测试方法一般包括:
A/B测试、双盲交叉验证
需要思考的问题
1.新用户/新商品的冷启动问题。
2.马太效应问题。这在推荐算法中也叫做banana problem。原因是在美国这边的超市,几乎所有人都爱买banana,因为最便宜,也好吃也健康。所以过多的数据量可能会导致一个超市推荐算法疯狂推荐Banana给所有人。
PS:NLP领域的TF-IDF算法可有效防止马太效应问题。
按照道理来讲,推荐系统要做的事情其实是“推荐用户希望看到的东西”,但是“用户希望看到的东西”落实到指标上,可就让人头大了。
以新闻推荐为例。你说究竟要得到什么呢?
高CTR?那么擦边球的软色情以及热门文章就会被选出来。
高Staytime?那么视频+文章feed流就退化为视频feed流
高read/U?那么短文章就会被选出来。
exploration & exploitation,简单说,就是保证精准推荐的同时,进行兴趣探索。
一说大家都明白了,这不就是所有推荐系统做的最差的地方吗?我看了一个东西,就使劲出一个东西,App明明很多东西,我却越用越窄。
这个问题更加玄学,更加让人无奈。EE要不要做?
肯定要做,你不能让用户只能看到一类新闻,这样久了他的feed流只会越来越小,自己也觉得没劲,所以一定要做兴趣探索。
但是做,就势必牺牲指标,探索的过程是艰难的,大部分时间用户体验上也是负向的。
那么,牺牲多少ctr来保EE才算是合适的?EE的ROI什么时候算是>1的?怎么样确定EE的效果?EE要E到什么程度?
对于新业务线暂时不要以GMV为导向,可以从流量或转化率的角度入手,选取CTR作为核心指标;对于比较稳定的业务线则以GMV为导向,选取UV价值作为核心指标。
参考:
https://www.zhihu.com/question/26990692
类似今日头条这样的个性化推荐网站怎么评价推荐质量的优劣?
https://www.zhihu.com/question/19660417
为什么那么多牛人成天在研究讨论算法,系统自动推荐的东西还是不能令人满意呢?
https://mp.weixin.qq.com/s/EGorUTYz09PYU3CdU_qwDA
如何省时省力验证模型效果?达观数据在线分层实验平台给你支招
https://mp.weixin.qq.com/s/S9AjPkYLzRQpg5evyaoleQ
推荐系统的工程实现
https://mp.weixin.qq.com/s/cjo5MYa-t9tWDCjwDpkOeg
推荐系统评估
https://mp.weixin.qq.com/s/M0-TIuZBIYi4xGv5SkN6xw
利用高效率的补贴策略驱动用户增长
召回
这个词在推荐系统中至少有三个不同的含义:
1.recall。ML领域的查全率也称召回率。参见《机器学习(二十二)》。
2.match。指对大量的物品做一个初选,针对每一个用户形成个性化侯选集。
3.产品召回,流失客户召回。这个和通常汉语中意思一致,表示失而复得/得而复失。
术语
GMV(Gross Merchandise Volume)成交额
CTR(Click-Through-Rate)即点击通过率,是互联网广告常用的术语,指网络广告(图片广告/文字广告/关键词广告/排名广告/视频广告等)的点击到达率,即该广告的实际点击次数除以广告的展现量。
RTB(Real Time Bidding,实时竞价)
eCPM(千次展示期望收入)
CPM(Cost per mille)
CPC(Cost per click)
CPA(Cost per action)
CPT(按展现时间收费)、CPL(按潜在线索收费)、CPS(按成功销售收费)
ROI(return on investment)投资回报率
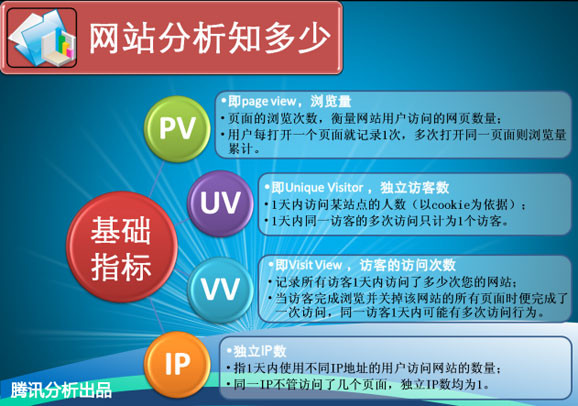
\[同比=\frac{2010.12}{2009.12}\] \[环比=\frac{2010.12}{2010.11}\]独立IP数:是指当天记录的唯一的IP数,一般以IP地址来统计。
独立访客数(Unique Visitor):指当天有多少台电脑访问,一般以COOKIE来统计。
独立访客高于IP:例如一个局域网对外是相同的一个IP,但是有10个人同时访问,那么这个时候,独立访客为10,唯一IP仅为1。
IP高于独立访客:一个用户,上网的时候频繁掉线,拔号10次均打开了受统计网站,此时,独立访客仅计为1,而IP数则被计为10。
Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。
ARPPU:Average Revenue per Paying User
https://mp.weixin.qq.com/s/cg2zMqX4x16H8E_qP8bs2w
DAU是啥,数据指标是啥?必知必会的数据分析常识
https://mp.weixin.qq.com/s/naV3fDu5wANmk7wX0boWJA
电商指标详细介绍和推荐系统常用评估指标
数据埋点
数据埋点是数据产品经理、数据运营以及数据分析师,基于业务需求或产品需求对用户在应用内产生行为的每一个事件对应的页面和位置植入相关代码,并通过采集工具上报统计数据,以便相关人员追踪用户行为,推动产品优化或指导运营的一项工程。
参考:
https://zhuanlan.zhihu.com/p/53522063
数据产品经理需要掌握的产品埋点方法
https://mp.weixin.qq.com/s/IvGkPnYdifuAzrUV3MTyhA
数据埋点太难!知乎的做法有何可借鉴之处?

您的打赏,是对我的鼓励
