linux » Linux学习心得(一)
2014-12-24 :: 5824 WordsGUI设计工具
GTK+的程序可以使用Glade来设计界面,它会生成一个脚本,运行该脚本,并make就行了。
QT的稍微麻烦一些。
1)首先打开QT Designer(新建时,不能使用KDE Designer,但修改建好后的工程可以,不知道是BUG,还是怎么回事)新建一个窗体,然后新建一个main.cpp,并将刚才生成的窗体选为主窗体。
2)打开KDev C/C++,选择导入工程,选择QMake Based导入,然后即可在IDE中编译并运行。
上面写的两个都是官方的设计器,而WxWidgets没有官方的设计器,但有很多第三方的设计器,我使用的是免费且开源的wxFormBuilder。用它可生成XRC文件,而WxWidgets中有使用XRC文件的接口。
printf和wprintf混用的问题
在linux中不可混用printf和wprintf,如果混用的话,则后使用的函数没有输出。
例如
printf("a\n");
wprintf(L"b\n");
输出为:
a
而
wprintf(L"b\n");
printf("a\n");
输出为:
b
关于这个问题的讨论见
http://bytes.com/groups/c/852681-wprintf-conflicts-printf-glibc-bug
解决方法统一使用一种函数
例如:
wprintf(L"%s","a\n");
wprintf(L"b\n");
或
printf("a\n");
printf("%ls",L"b\n");
在Linux下,printf输出到控制台经历了app->libc->syscall->console驱动四个阶段。
https://www.zhihu.com/question/456916638
printf是怎么输出到控制台的呢?
关于ascii字符集的一些打印控制字符的别名
\b——backspace
\f——pagebreak
\v——vertical tab
IO多路复用
I/O多路复用:用一个系统调用函数来监听我们所有关心的连接,也就说可以在一个监控线程里面监控很多的连接。
参考文献:
http://www.cnblogs.com/Anker/p/3265058.html
select、poll、epoll之间的区别总结
除此之外,freeBSD下的kqueue,Windows下的iocp,是其各自平台的官方IO多路复用方案。
select函数
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout)
函数参数介绍如下:
第一个参数maxfdp1指定待测试的描述字个数,它的值是待测试的最大描述字加1(因此把该参数命名为maxfdp1),描述字0、1、2…maxfdp1-1均将被测试,因为文件描述符是从0开始的。
中间的三个参数readset、writeset和exceptset指定我们要让内核测试读、写和异常条件的描述字。如果对某一个的条件不感兴趣,就可以把它设为空指针。struct fd_set可以理解为一个集合,这个集合中存放的是文件描述符,可通过以下四个宏进行设置:
void FD_ZERO(fd_set *fdset); //清空集合
void FD_SET(int fd, fd_set *fdset); //将一个给定的文件描述符加入集合之中
void FD_CLR(int fd, fd_set *fdset); //将一个给定的文件描述符从集合中删除
int FD_ISSET(int fd, fd_set *fdset); //检查集合中指定的文件描述符是否可以读写
(3)timeout告知内核等待所指定描述字中的任何一个就绪可花多少时间。其timeval结构用于指定这段时间的秒数和微秒数。
这个参数有三种可能:
(1)永远等待下去:仅在有一个描述字准备好I/O时才返回。为此,把该参数设置为空指针NULL。
(2)等待一段固定时间:在有一个描述字准备好I/O时返回,但是不超过由该参数所指向的timeval结构中指定的秒数和微秒数。
(3)根本不等待:检查描述字后立即返回,这称为轮询。为此,该参数必须指向一个timeval结构,而且其中的定时器值必须为0。
缺点:
1.单个进程通过轮询的方式监控所有的文件句柄,当文件句柄越多,处理的效率越低,为了保证效率,文件句柄也就设置了上限。
2.重复初始化:每次监控都重复将fdset从用户空间拷贝到内核空间,然后又从内核空间拷贝到用户空间,这个过程重复比较耗费系统资源。
参考:
https://mp.weixin.qq.com/s/dr6nmAg1XVjnx3hF51IC2g
Linux select一网打尽
poll函数
poll技术与select技术本质上是没有区别的,只是文件句柄的存储结构变更了,变成了链表,所以没有了文件句柄的上限,但是其他缺点依旧存在。
int poll ( struct pollfd * fds, unsigned int nfds, int timeout);
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 等待的事件 */
short revents; /* 实际发生了的事件 */
} ;
事件包括:
POLLIN 有数据可读。
POLLRDNORM 有普通数据可读。
POLLRDBAND 有优先数据可读。
POLLPRI 有紧迫数据可读。
POLLOUT 写数据不会导致阻塞。
POLLWRNORM 写普通数据不会导致阻塞。
POLLWRBAND 写优先数据不会导致阻塞。
POLLMSGSIGPOLL 消息可用。
POLLER 指定的文件描述符发生错误。
POLLHUP 指定的文件描述符挂起事件。
POLLNVAL 指定的文件描述符非法。
epoll接口
epoll技术提供了epoll_ctl函数,在用epoll_ctl函数进行事件注册的时候,会将文件句柄都复制到内核中,所以不用每次都复制一遍,当有新的文件句柄时采用的也是增量往内核拷贝,确保了每个文件句柄只会被拷贝一次。它只将链表中的就绪文件句柄从内核空间拷贝到用户空间,这样一来就不用遍历每个文件句柄,而只处理状态发生变更的。
参考:
http://www.cnblogs.com/Anker/archive/2013/08/17/3263780.html
IO多路复用之epoll总结
https://mp.weixin.qq.com/s/2RhYd8b38pa_vAx_7DpQhQ
Tornado原理浅析及应用场景探讨
https://mp.weixin.qq.com/s/dUo-a01uSssWkSc9wQpt2A
深入揭秘epoll是如何实现IO多路复用的
https://mp.weixin.qq.com/s/k3qALmbjxxAPPg6v1-RDOA
Linux的epoll使用LT+非阻塞IO和ET+非阻塞IO有效率上的区别吗?
https://mp.weixin.qq.com/s/h3CBZt2KEA-ScXFSKHaRBg
十个问题理解Linux epoll工作原理
https://zhuanlan.zhihu.com/p/384098769
从内核看epoll的实现(基于5.9.9)
eBPF
BPF(Berkely Packet Filter)提供了一种当内核或应用特定事件发生时候,执行一段代码的能力。
这种能力最初被用于TCP包的过滤,正如名字所示,后来也被广泛用于profile领域。
BPF采用了虚拟机指令规范,所以也可以看成是一种虚拟机实现,使我们可以在不修改内核源码和重新编译的情况下,扩展内核的能力。
既然有虚拟机和bytecode,那么也需要相应的编译器了:
官网:
https://github.com/iovisor/bcc
参考:
https://ebpf.io/zh-cn/
一个eBPF的专栏
https://www.ebpf.top/
一个eBPF的专栏
https://zhuanlan.zhihu.com/p/659240633
再次实现了一个Lua性能分析器
https://zhuanlan.zhihu.com/p/590881470
万字长文让你深入了解BPF字节码
https://zhuanlan.zhihu.com/p/484788508
一文看懂eBPF:eBPF实现原理
https://zhuanlan.zhihu.com/p/393199226
BPF内部原理
io_uring
epoll只支持network sockets和pipes,甚至连storage files都不支持。
eBPF也算是异步框架(事件驱动),但与io_uring没有本质联系,二者属于不同子系统, 并且在模型上有一个本质区别:
- eBPF对用户是透明的,只需升级内核(到合适的版本),应用程序无需任何改造;
- io_uring提供了新的系统调用和用户空间API,因此需要应用程序做改造。
随着设备越来越快,中断驱动(interrupt-driven)模式效率已经低于轮询模式 (polling for completions),这也是高性能领域最常见的主题之一。
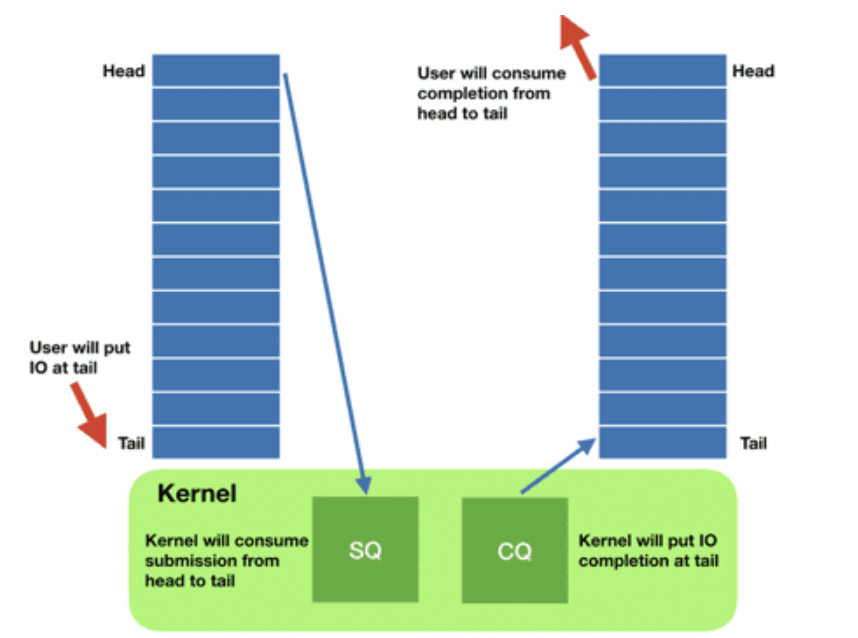
提交队列:submission queue (SQ)
完成队列:completion queue (CQ)
o_uring实例可工作在三种模式:
- 中断驱动模式(interrupt driven)
- 轮询模式(polled)
- 内核轮询模式(kernel polled)
参考:
https://arthurchiao.art/blog/intro-to-io-uring-zh
Linux异步I/O框架io_uring:基本原理、程序示例与性能压测
https://mp.weixin.qq.com/s/QshDG-nbmBcF1OBZbBFwjg
操作系统与存储:解析Linux内核全新异步IO引擎io_uring设计与实现
https://zhuanlan.zhihu.com/p/583413166
Linux I/O神器之io_uring
惊群
对于高性能的服务器而言,为了利用多CPU核的优势,大多采用多个进程(线程)同时在一个listen socket上进行accept请求。当这个fd(socket)的事件发生的时候,这些睡眠的进程(线程)就会被同时唤醒,多个进程(线程)从阻塞的系统调用上返回,这就是”惊群”现象。
“惊群”被人诟病的是效率低下,大量的CPU时间浪费在被唤醒发现无事可做,然后又继续睡眠的反复切换上。
参考:
https://mp.weixin.qq.com/s/dQWKBujtPcazzw7zacP1lg
深入浅出Linux惊群:现象、原因和解决方案
Reactor和Proactor
Reactor模式也叫Dispatcher模式,即I/O多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程/线程。
Reactor模式主要由Reactor和处理资源池这两个核心部分组成,它俩负责的事情如下:
-
Reactor负责监听和分发事件,事件类型包含连接事件、读写事件;
-
处理资源池负责处理事件,如read -> 业务逻辑 -> send;
Reactor是非阻塞同步网络模式,而Proactor是异步网络模式。
Reactor可以理解为“来了事件操作系统通知应用进程,让应用进程来处理”,而Proactor可以理解为“来了事件操作系统来处理,处理完再通知应用进程”。
Reactor模式是基于“待完成”的I/O事件,而Proactor模式则是基于“已完成”的I/O事件。
在Linux下的异步I/O是不完善的,这也使得基于Linux的高性能网络程序都是使用Reactor方案。
https://www.zhihu.com/question/26943938
如何深刻理解Reactor和Proactor?
https://blog.csdn.net/windows_nt/article/details/25151049
Reactor与Proactor的区别
https://cloud.tencent.com/developer/article/1488120
彻底搞懂Reactor模型和Proactor模型
参考
https://mp.weixin.qq.com/s/EDzFOo3gcivOe_RgipkTkQ
网络IO演变发展过程和模型介绍
https://www.zhihu.com/answer/241673170
怎样理解阻塞非阻塞与同步异步的区别?
https://mp.weixin.qq.com/s/CZ3qusMpNQwIudX5mcVeJw
彻底理解IO多路复用
https://mp.weixin.qq.com/s/ElWRnRHgjle8SYhnVQRj2Q
网络IO套路
https://mp.weixin.qq.com/s/1i_TryNe_RlxCb2xWkPCXA
同步阻塞网络IO
https://mp.weixin.qq.com/s/oNkbQsNgwUrd4nuvQlbJkw
I/O多路复用
五种IO模型包括:阻塞IO、非阻塞IO、IO多路复用、信号驱动IO、异步IO。
https://mp.weixin.qq.com/s/zIhCDj_0OSOmrevuqxJCBw
一口气说出5种互联网高并发IO模型
https://mp.weixin.qq.com/s/9YXsJo_u2zVNqvABoGqfqg
五种IO模型分析

您的打赏,是对我的鼓励
