DL » 深度学习(二十五)——多任务学习, DLSS, 神经元激活函数进阶(二)
2017-12-22 :: 6814 Words多任务学习
教程
http://cs330.stanford.edu/
CS 330: Deep Multi-Task and Meta Learning
论文
《Multi-Task Learning for Dense Prediction Tasks: A Survey》
《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》
概述
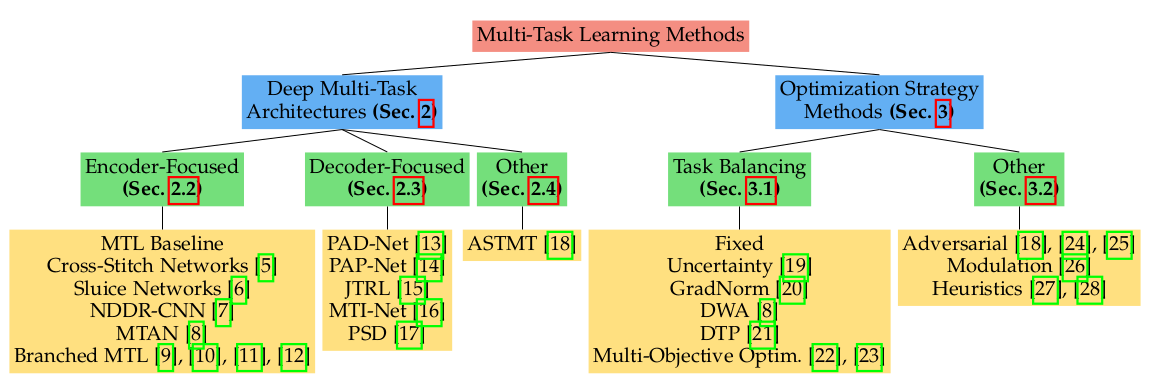
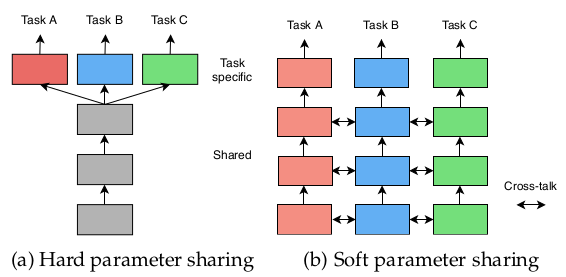
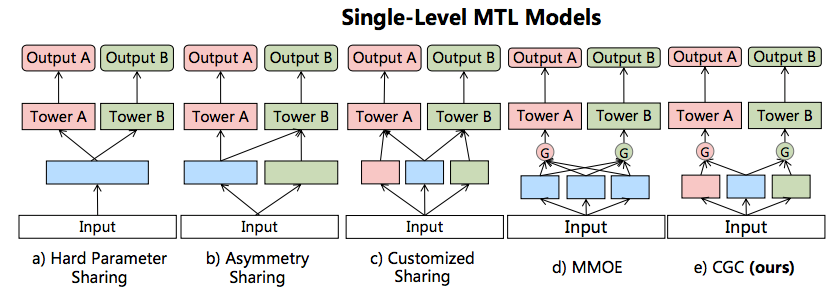
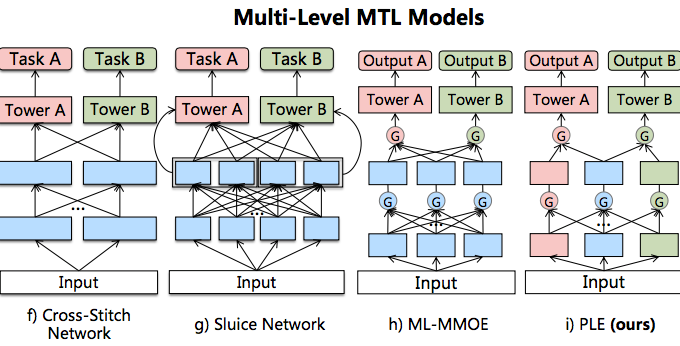
参考
https://mp.weixin.qq.com/s/guAgXdhZSbEAkERSB1sLRA
多任务学习-Multitask Learning概述
https://zhuanlan.zhihu.com/p/355147999
《Multitask Learning》-多任务学习发展的关键节点
https://mp.weixin.qq.com/s/A-CVKTz_moaFzTYywSt2gg
张宇 杨强:多任务学习概述
https://zhuanlan.zhihu.com/p/148132708
最新《深度多任务学习》综述论文
https://zhuanlan.zhihu.com/p/46044947
深度神经网络中多任务学习简介
https://zhuanlan.zhihu.com/p/67524006
多任务学习综述-A Survey on Multi-Task Learning
https://mp.weixin.qq.com/s/QXOy2jo4RhCZrD5bSVzBOQ
共享相关任务表征,一文读懂深度神经网络多任务学习
https://zhuanlan.zhihu.com/p/59413549
Multi-task Learning(Review)多任务学习概述
https://mp.weixin.qq.com/s/X6FwTgr282hbqgOz3oBX-w
多任务学习概述论文:从定义和方法到应用和原理分析
https://blog.csdn.net/CoderPai/article/details/80080455
多任务学习与深度学习
https://mp.weixin.qq.com/s/NpO1UP_mzyaeqW26xLY1Xg
CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
https://mp.weixin.qq.com/s/DUSa3SW1AgvJ0szL030NHQ
一个AI玩57个游戏,DeepMind离真正“万能”的AGI不远了!
https://mp.weixin.qq.com/s/P81I5vl99mV-4StNHmd_6A
作为多目标优化的多任务学习:寻找帕累托最优解
https://mp.weixin.qq.com/s/cyX_FzHF-6df9_AMUDu1aQ
One Model To Learn Them All
https://mp.weixin.qq.com/s/oY2yGrTmIpr3H2qvzYKInA
谷歌一个模型解决所有问题《One Model to Learn Them All》论文深度解读
https://mp.weixin.qq.com/s/VMHyEOn8uyRYt39QXVWUww
西湖大学张岳:自然语言处理中的多任务联合学习(384页PPT)
https://mp.weixin.qq.com/s/5zo-2WB9v2hOvKAC7ZhKuQ
基于学习的多任务框架L2MT,为多任务问题选择最优模型
https://mp.weixin.qq.com/s/MPhKUosKZbLtVjJ1XYGXYA
如何利用深度学习模型实现多任务学习?这里有三点经验
https://mp.weixin.qq.com/s/Oopgglg2G7TwnXeN2DtZhA
多任务+注意力机制的学习
https://mp.weixin.qq.com/s/vMgHCQ03Gt5v6GdgW-pY9A
一个神经网络实现4大图像任务,GitHub已开源
https://mp.weixin.qq.com/s/Zui8FFn1FDP_UoAGMH0L7Q
知其然,知其所以然:基于多任务学习的可解释推荐系统
https://mp.weixin.qq.com/s/8Ablt7Sa86DXTB1dE_RqaA
港中文开源基于PyTorch的多任务人脸识别框架
https://www.zhihu.com/question/345173757
多任务学习成功的原因是引入了别的数据库还是多任务框架本身呢?
https://zhuanlan.zhihu.com/p/52566508
深度神经网络中的多任务学习汇总
https://mp.weixin.qq.com/s/DUsXj46TCZ9w_Dxgw4ZH8g
用于多任务CNN的随机滤波分组,性能超现有基准方法
https://mp.weixin.qq.com/s/-SHLp26oGDDp9HG-23cetg
多任务学习在推荐算法中的应用
https://mp.weixin.qq.com/s/avWy3-mju0d0QjufX_bi4Q
Multi-task Learning的三个实用小知识
https://mp.weixin.qq.com/s/hLJB8yH8V0Ncug77jHU1Bw
模型独立学习:多任务学习与迁移学习
https://zhuanlan.zhihu.com/p/138597214
Multi-task Learning and Beyond: 过去,现在与未来
https://mp.weixin.qq.com/s/gIEJoE9B8mmNx6u6bqLspQ
最新《深度多任务学习》综述论文,22页pdf
https://mp.weixin.qq.com/s/ifTNRW0W7-P_LyfNldtavQ
多任务学习方法在推荐中的演变
https://zhuanlan.zhihu.com/p/269492239
多任务学习优化(Optimization in Multi-task learning)
https://www.cnblogs.com/RyanXing/p/10730829.html
Cross-stitch Networks for Multi-task Learning
https://mp.weixin.qq.com/s/T_UsCkj9hnV7tgOTcaf6Wg
Multi-Task多任务学习, 那些你不知道的事
https://mp.weixin.qq.com/s/vFHYk7202bSZ214Za_SOtQ
2021年浅谈多任务学习
https://mp.weixin.qq.com/s/pvQHUXo83hMfH8kCumXSQA
如何利用多任务学习提升模型性能?
https://mp.weixin.qq.com/s/dcv2pqccrAtg2nNaHTTU2Q
一文”看透”多任务学习
DLSS
DLSS的全称是Deep Learning Super Sampling,主要作用是通过Tensor Core硬件加速的深度学习对实时渲染的图片实现非常高质量的超采样,从而大幅提升游戏渲染的性能。
DLSS 1.x,刚开始出来这个东西,都是英伟达针对某个游戏进行智能训练,训练的成果文件,放在驱动里面了,采样原生的图画,然后生产新的画面,插入到游戏中,弊端很明显,游戏支持率很低,通过训练插入的画质(只有原生画质的50%渲染率,画质差不少)确实不咋地;
DLSS 2.0时代,NV觉得针对特定游戏训练不太好,这次换成了固定训练模式,让游戏厂家自己来适配,支持DLSS的游戏多了不少;
DLSS 1~2本质上是超分辨率技术(Super Resolution)。
DLSS 3本质上是插帧技术(Frame Generation)。现实中,大多数玩家对分辨率更敏感,对帧率没那么敏感的。
DLSS 3.5本质上是光线重构技术(Ray Reconstruction),只有在光追的时候才能开启。
以上技术名称都叫DLSS,本质上不是同一项技术,甚至是相互独立的。唯一共同点就是都和深度学习相关。
https://zhuanlan.zhihu.com/p/123642175
DLSS 2.0-基于深度学习的实时渲染图像重建
https://www.zhihu.com/question/618638060
如何评价英伟达推出的DLSS3.5?
FSR的全称是FidelityFX Super Resolution。
AMD的FSR其实和nvida的NIS(图像锐化)原理一样,都是没有用到AI的,属于机械式的脑补画面。不过它们是免费开源,跨平台的,所以不管是A卡,N卡还是i卡都能支持这项技术。
Intel的XeSS全称Xe Super Sampling,这是英特尔的深度学习超采样增强技术,它的原理和DLSS类似,都需要利用AI。
TSR(Temporal Super Resolution)时序超级分辨率技术是AMD与Epic联合开发的超采样技术,将会内置在未来的虚幻引擎中用于取代传统的TAA(Temporal Antialiasing)。原理类似英伟达的DLSS。
AMD一直在视觉计算的先进技术方面承受巨大压力,尤其是游戏应用,DLSS 3出来后AMD基本上在新的AAA游戏这边被压制完了,帧生成到现在(2023.8)都没搞定,现在新的DLSS 3.5,如果在RR光追降噪器方面进一步一统江湖,AMD真的在游戏光线追踪方面没得玩了。
TAA这一类算法利用了渲染图片的时域连贯性(Temporal coherency),既渲染结果的帧与帧之间大体是连续的,发生高频变化的概率不高。也就是说,我们可以假设需要渲染的场景在上一帧和当前帧几乎一样。
然而天下哪有这等好事,实时渲染或者游戏的图片序列中几乎每一帧都有或多或少的变化,从角色动画,到动态光影,到粒子特效。直接复用过去帧的样本来重建当前帧的图片会使重建的结果中产生很大的错误。
单帧的算法结果会模糊并且会和原生渲染不一致,而且帧间也经常会有抖动。
多帧的算法则需要用各种启发式的方法去解决各种过去帧和当前帧场景样本不一致的问题。
Cooperative Vector是DirectX 12和Vulkan正在引入的一项跨平台神经渲染API,核心目的是让GPU着色器(Pixel/Compute Shader 等)能直接、高效地执行矩阵-向量运算——也就是运行小型神经网络推理(如MLP),无需将AI计算offload到独立的计算管线。
https://zhuanlan.zhihu.com/p/1991557277451305725
2025年游戏技术最大变革:Neural Shader
神经元激活函数进阶
其他激活函数
hard tanh
\[\text{HardTanh}(x)=\begin{cases} -1, & x<-1 \\ x, & -1\le x \le 1 \\ 1, & x>1 \\ \end{cases}\]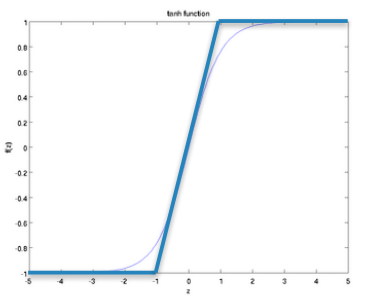
hard tanh也叫做Relu1。
hard sigmoid
\[\text{HardSigmoid}(x)=\begin{cases} 0, & x<-2.5 \\ 0.2x, & -2.5\le x \le 2.5 \\ 1, & x>2.5 \\ \end{cases}\]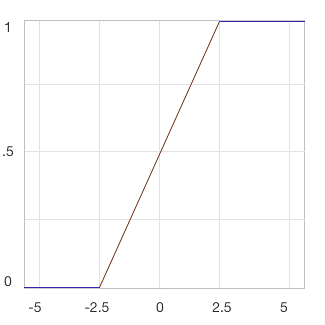
soft sign
\[\text{softsign}(x)=\frac{x}{1+\mid x\mid }\]Hardswish
\[Hardswish(x) = x\frac{RELU6(x+3)}{6} = \left\{ \begin{aligned} &0, & \text{if } x \leq -3 \\ &x, & \text{if } x \geq 3 \\ &\frac{x(x+3)}{6}, & \text{otherwise} \end{aligned} \right.\]Mish
\[Mish(x)=x\tanh (\ln(1+e^x))\]参考:
https://mp.weixin.qq.com/s/i8aShQvJhSgP7KY5Qgm36A
ReLU的继任者Mish:一个新的state of the art的激活函数
https://mp.weixin.qq.com/s/a_roXfjNX2szJMUrww0Fmg
YOLOv4中的Mish激活函数
soft relu
\[soft\_ relu(x) = \ln(1 + \exp(\max(\min(x, threshold), -threshold)))\]SELU
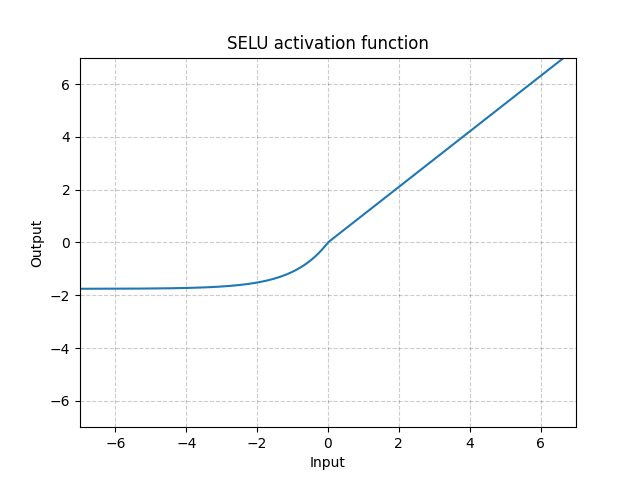
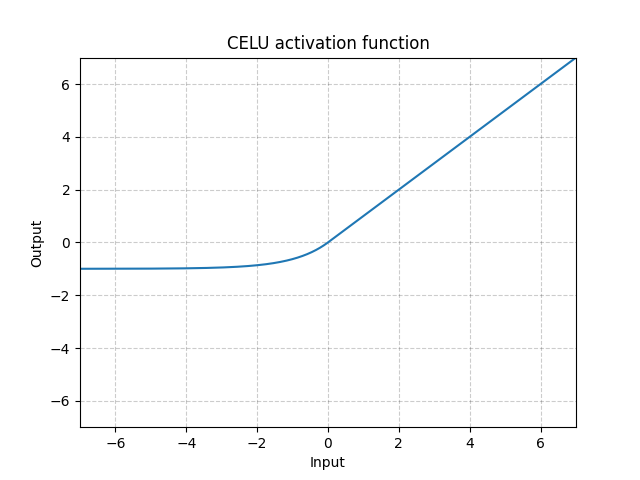
CELU
CRELU
\[CReLU(x)= Concat[ ReLU(x), ReLU(−x) ]\]参考
https://zhuanlan.zhihu.com/p/22142013
深度学习中的激活函数导引
http://blog.csdn.net/u012328159/article/details/69898137
几种常见的激活函数
https://mp.weixin.qq.com/s/Hic01RxwWT_YwnErsJaipQ
什么是激活函数?
https://mp.weixin.qq.com/s/4gElB_8AveWuDVjtLw5JUA
深度学习激活函数大全
https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ
从ReLU到Sinc,26种神经网络激活函数可视化
http://www.cnblogs.com/ymjyqsx/p/6294021.html
PReLU与ReLU
http://www.cnblogs.com/pinard/p/6437495.html
深度神经网络(DNN)损失函数和激活函数的选择
https://mp.weixin.qq.com/s/VSRtjIH1tvAVhGAByEH0bg
21种NLP任务激活函数大比拼:你一定猜不到谁赢了
https://www.cnblogs.com/makefile/p/activation-function.html
激活函数(ReLU, Swish, Maxout)
https://mp.weixin.qq.com/s/YVi9ke3VSidBvzfLPjMkZg
激活函数-从人工设计到自动搜索
https://mp.weixin.qq.com/s/XttlCNKGvGZrD7OQZOQGnw
如何发现“将死”的ReLu?
https://mp.weixin.qq.com/s/_qeqicHWnJ50BfiQpLWVVA
Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进
https://mp.weixin.qq.com/s/jMLarSpq3Wg0OIrRIW26dA
从Binary到Swish——激活函数深度详解
https://mp.weixin.qq.com/s/IuZsTKGesgTw1ATXx4OBEA
深度学习最常用的10个激活函数
https://blog.csdn.net/shuzfan/article/details/77807550
CReLU激活函数

您的打赏,是对我的鼓励
