DL » 深度学习(二十一)——Ultra Deep Network(2)
2017-10-18 :: 7502 WordsUltra Deep Network
Dual Path Networks
DPN是冯佳时和颜水成团队的Yunpeng Chen的作品。
冯佳时,中国科学技术大学自动化系学士,新加坡国立大学电子与计算机工程系博士。现任新加坡国立大学电子与计算机工程系助理教授。
论文:
《Dual Path Networks》
代码:
https://github.com/cypw/DPNs
这篇论文首先从拓扑关系的角度分析了ResNet、DenseNet和HORNN(Higher Order RNN)之间的联系。
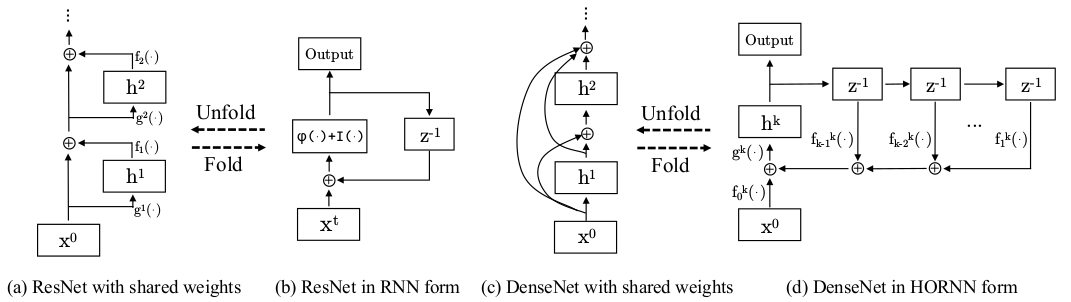
如上所示,RNN相当于共享权值的串联的ResNet,而DenseNet则相当于并联的RNN。
更进一步的,上述三者都可表述为以下通式:
\[h^k=g^k\left[\sum_{t=0}^{k-1}f_t^k(h^t)\right]\]其中,\(h^t\)表示t时刻的隐层状态;索引k表示当前时刻;\(x^t\)表示t时刻的输入;\(f_t^k(⋅)\)表示特征提取;\(g^k\)表示对提取特征做输出前的变换。
如果\(f_t^k(\cdot)\)和\(g^k(\cdot)\)每个Step都共享,那么就是HORNN,如果只有\(f_t^k(\cdot)\)共享,那么就是ResNet,两者都不共享,那就是DenseNet。
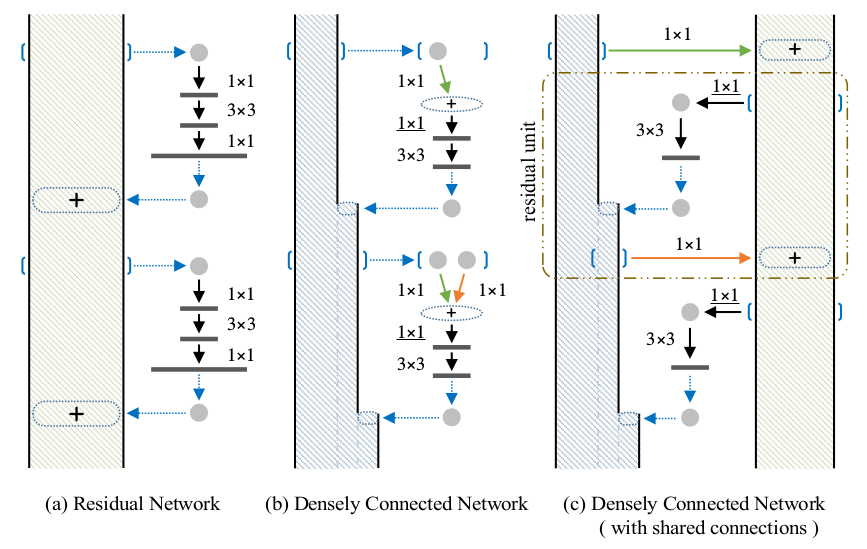
上图展示的是ResNet和DenseNet的示意图。图中用线填充的柱状体,表示的是主干结点的tensor的大小。
ResNet由于跨层和主干之间是element-wise的加法运算,因此每个主干结点的tensor都是一样大的。
而DenseNet的跨层和主干之间是Concatenation运算,因此主干越往下,tensor越大。
通过上面的分析,我们可以认识到 :
ResNet: 侧重于特征的再利用,但不善于发掘新的特征;
DenseNet: 侧重于新特征的发掘,但又会产生很多冗余;
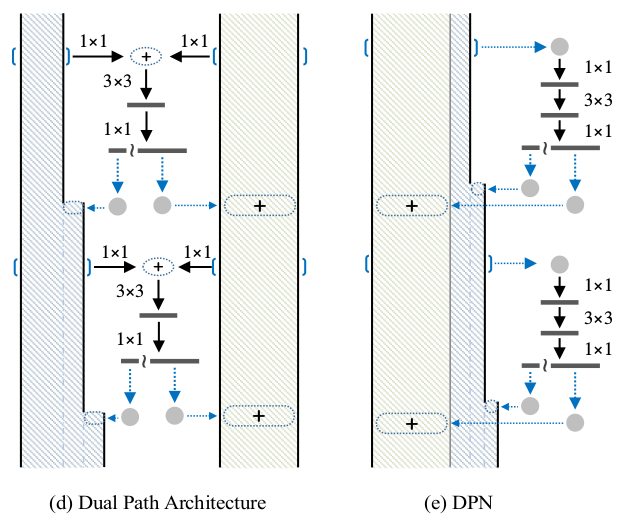
为了综合二者的优点,作者设计了DPN网络:
参考:
http://blog.csdn.net/scutlihaoyu/article/details/75645551
《Dual Path Networks》笔记
http://www.cnblogs.com/mrxsc/p/7693316.html
Dual Path Networks
http://blog.csdn.net/u014380165/article/details/75676216
DPN(Dual Path Network)算法详解
https://mp.weixin.qq.com/s/m4cRV9yX-8r4BI0EkVRYig
残差网络家族10多个变种学习卡片,请收下!
CSPNet
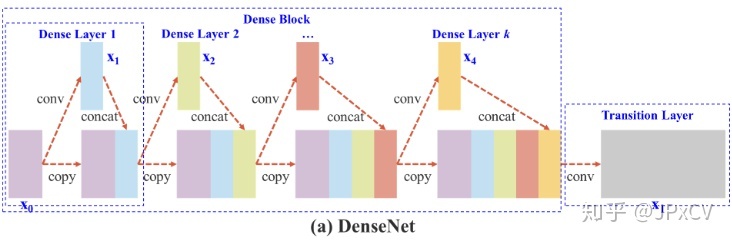
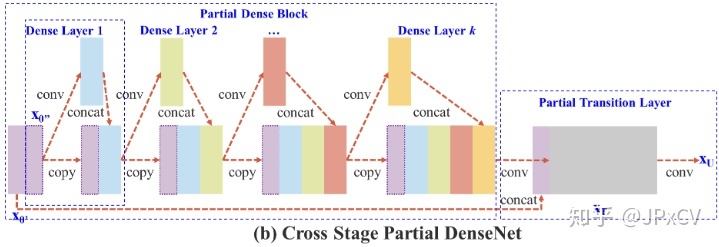
https://zhuanlan.zhihu.com/p/124838243
CSPNet论文笔记
mHC
标准残差连接是每一个现代Transformer的脊梁。其思路很简单:
\[x_{l+1} = x_l + F(x_l)\]其输入原封不动地流过,加上该层的输出。这是一条单一的信息流。进去是什么,出来的就是什么,加上一个学习到的更新量。这就是为什么Transformer可以深达数百层:梯度有一条干净的向后路径。简单,稳定。自2016年以来未曾改变。
超连接(Hyper-Connections)采取了不同的方法。它不再是单一流,而是扩展到n条并行流,并带有可学习的混合矩阵:
\[x_{l+1} = H^{res}_l x_l + H^{post,T}_l F(H^{pre}_l x_l, W_l)\]
但问题是什么?那些混合矩阵是不受约束的。它们不仅能路由信号,还能放大信号。
DeepSeek的修复方案很干净:使用Sinkhorn-Knopp算法将混合矩阵约束为双重随机(doubly stochastic)矩阵。
一个双重随机矩阵具有以下特性:
- 所有条目非负。
- 行之和为1。
- 列之和为1。
https://taylorkolasinski.com/notes/mhc-reproduction/
DeepSeek’s mHC: When Residual Connections Explode
https://taylorkolasinski.com/notes/mhc-reproduction-part2/
10,924x: The Instability Bomb at 1.7B Scale
Attention Residuals
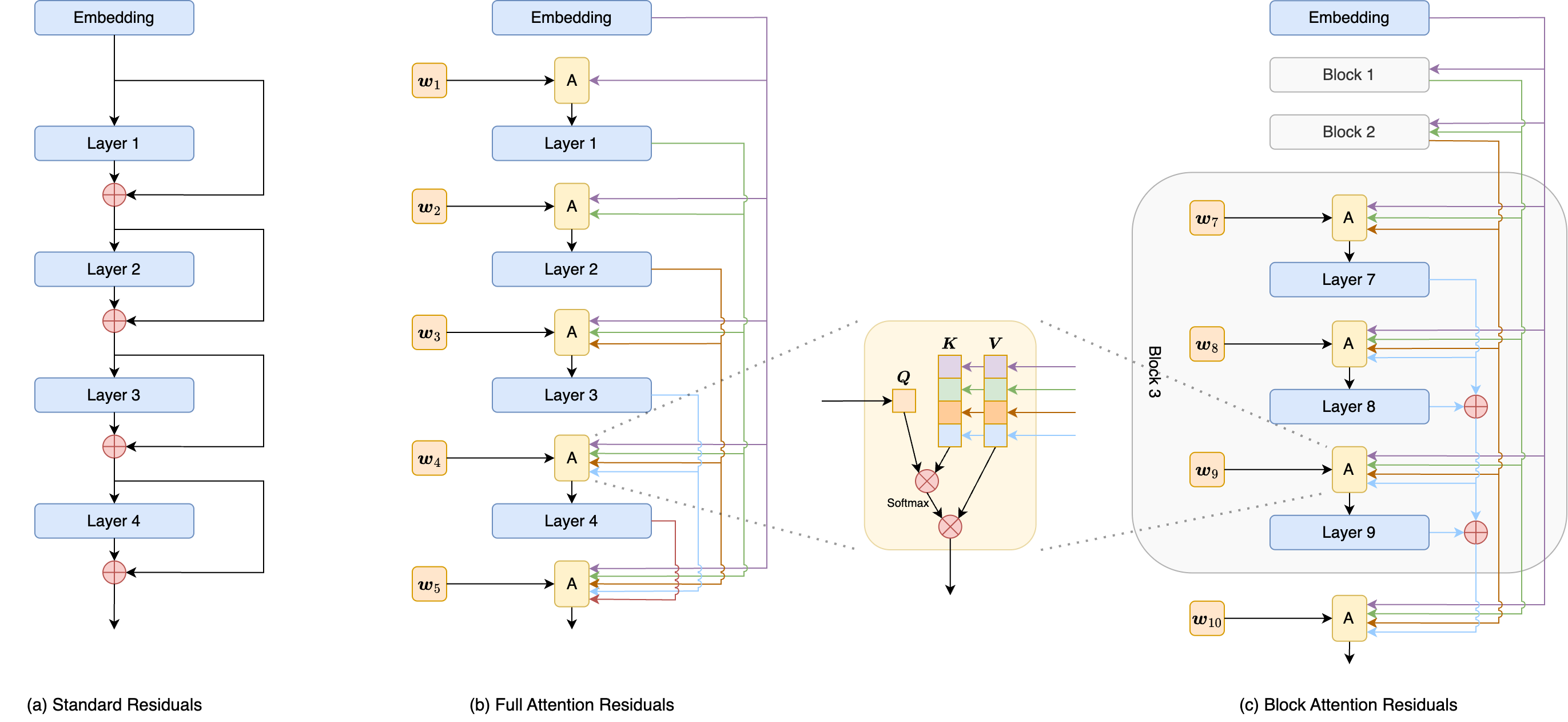
Residuals本身已经是一个非常强的Baseline,它对应于所有状态向量的等权求和,任何新设计想要超越它,那么至少在形式上要能够覆盖它。
Residuals:
\[\boldsymbol{A}=\left(\begin{array}{c} 1 \\ 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ \end{array}\right)\]HC/mHC:
\[\boldsymbol{A}=\left(\begin{array}{c} \boldsymbol{H}_1^{pre} \boldsymbol{H}_0^{post} \\ \boldsymbol{H}_2^{pre}\boldsymbol{H}_{1\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_2^{pre}\boldsymbol{H}_1^{post} \\ \boldsymbol{H}_3^{pre}\boldsymbol{H}_{2\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_3^{pre}\boldsymbol{H}_{2\leftarrow 2}^{res}\boldsymbol{H}_1^{post} & \boldsymbol{H}_3^{pre}\boldsymbol{H}_2^{post} \\ \boldsymbol{H}_4^{pre}\boldsymbol{H}_{3\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_4^{pre}\boldsymbol{H}_{3\leftarrow 2}^{res}\boldsymbol{H}_1^{post} & \boldsymbol{H}_4^{pre}\boldsymbol{H}_{3\leftarrow 3}^{res}\boldsymbol{H}_2^{post} & \boldsymbol{H}_4^{pre}\boldsymbol{H}_3^{post} \\ \boldsymbol{H}_5^{pre}\boldsymbol{H}_{4\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_5^{pre}\boldsymbol{H}_{4\leftarrow 2}^{res}\boldsymbol{H}_1^{post} & \boldsymbol{H}_5^{pre}\boldsymbol{H}_{4\leftarrow 3}^{res}\boldsymbol{H}_2^{post} & \boldsymbol{H}_5^{pre}\boldsymbol{H}_{4\leftarrow 4}^{res}\boldsymbol{H}_3^{post} & \boldsymbol{H}_5^{pre}\boldsymbol{H}_4^{post} \\ \boldsymbol{H}_6^{pre}\boldsymbol{H}_{5\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_6^{pre}\boldsymbol{H}_{5\leftarrow 2}^{res}\boldsymbol{H}_1^{post} & \boldsymbol{H}_6^{pre}\boldsymbol{H}_{5\leftarrow 3}^{res}\boldsymbol{H}_2^{post} & \boldsymbol{H}_6^{pre}\boldsymbol{H}_{5\leftarrow 4}^{res}\boldsymbol{H}_3^{post} & \boldsymbol{H}_6^{pre}\boldsymbol{H}_{5\leftarrow 4}^{res}\boldsymbol{H}_4^{post} & \boldsymbol{H}_6^{pre}\boldsymbol{H}_5^{post} \\ \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 1}^{res}\boldsymbol{H}_0^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 2}^{res}\boldsymbol{H}_1^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 3}^{res}\boldsymbol{H}_2^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 4}^{res}\boldsymbol{H}_3^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 5}^{res}\boldsymbol{H}_4^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_{6\leftarrow 6}^{res}\boldsymbol{H}_5^{post} & \boldsymbol{H}_7^{pre}\boldsymbol{H}_6^{post} \\ \end{array}\right)\]Full AttnRes:
\[\boldsymbol{A}=\left(\begin{array}{c} \phi(\boldsymbol{w}_1, \boldsymbol{y}_0) \\ \phi(\boldsymbol{w}_2, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_2, \boldsymbol{y}_1) \\ \phi(\boldsymbol{w}_3, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_3, \boldsymbol{y}_1) & \phi(\boldsymbol{w}_3, \boldsymbol{y}_2) \\ \phi(\boldsymbol{w}_4, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_1) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_2) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_3) \\ \phi(\boldsymbol{w}_5, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_1) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_2) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_3) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_4) \\ \phi(\boldsymbol{w}_6, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_1) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_2) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_3) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_4) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_5) \\ \phi(\boldsymbol{w}_7, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_1) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_2) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_3) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_4) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_5) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_6) \\ \end{array}\right)\]Block AttnRes:
\[\boldsymbol{A}=\left(\begin{array}{c:ccc:ccc} \phi(\boldsymbol{w}_1, \boldsymbol{y}_0) \\ \hdashline \phi(\boldsymbol{w}_2, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_2, \boldsymbol{y}_1) \\ \phi(\boldsymbol{w}_3, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_3, \boldsymbol{y}_{1:2}) & \phi(\boldsymbol{w}_3, \boldsymbol{y}_{1:2}) \\ \phi(\boldsymbol{w}_4, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_4, \boldsymbol{y}_{1:3}) \\ \hdashline \phi(\boldsymbol{w}_5, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_5, \boldsymbol{y}_4)\\ \phi(\boldsymbol{w}_6, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_{4:5}) & \phi(\boldsymbol{w}_6, \boldsymbol{y}_{4:5}) \\ \phi(\boldsymbol{w}_7, \boldsymbol{y}_0) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{1:3}) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{4:6}) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{4:6}) & \phi(\boldsymbol{w}_7, \boldsymbol{y}_{4:6}) \\ \end{array}\right)\]https://kexue.fm/archives/11664
Attention Residuals回忆录
https://www.zhihu.com/question/2016993095078684011
Kimi新发布的“注意力残差”有什么亮点?

您的打赏,是对我的鼓励
