DL » 深度学习(二十)——Ultra Deep Network(1)
2017-10-12 :: 5407 WordsLSTM进阶(续)
《Video Summarization with Long Short-term Memory》
这是一篇用于提取视频关键帧(也叫静态视频摘要)的论文,是南加州大学沙飞小组的作品。
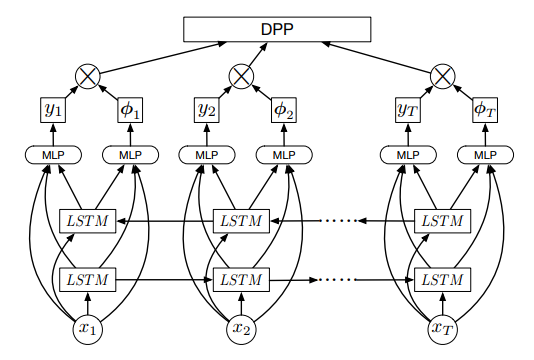
上图是该文提出的DPP LSTM的网络结构图。它的主体是一个BiLSTM,算是中规中矩吧。
该文的创新点在于提出了DPP loss的概念。上图中的\(y_t\)表示帧的分值(越大表示越重要),\(\phi_t\)表示帧之间的相似度。该文的实验表明,将两个特征分开抽取,有助于提升模型的准确度。
这篇论文主要用到了3个数据集:
TVSum dataset:
https://github.com/yalesong/tvsum
这个需要Yahoo账号和一个高校的邮件地址才行。
SumMe dataset:
https://people.ee.ethz.ch/~gyglim/vsum/#benchmark
OVP and YouTube datasets:
https://sites.google.com/site/vsummsite/
需要翻墙。
LSTM运算加速技巧
LSTM的主要运算量集中在\(W[h_{t-1},x_t]\)上,这里实际上可以用\(W[(h_{t-2}+\Delta h_{t-1}),x_t]\)代替。
由于时间序列通常具有惯性,因此\(\Delta h_{t-1}\)一般包含了大量的0,这对于某些具有跳0功能的硬件来说,是非常有利的。
Convolutional LSTM Network
论文:
《Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting》
参考
https://mp.weixin.qq.com/s/4IHzOAvNhHG9c8GP0zXVkQ
Simple Recurrent Unit For Sentence Classification
https://mp.weixin.qq.com/s/fCzHbOi7aJ8-W9GzctUFNg
LSTM文本分类实战
http://mp.weixin.qq.com/s/3nwgft9c27ih172ANwHzvg
从零开始:如何使用LSTM预测汇率变化趋势
https://mp.weixin.qq.com/s/M18c3sgvjV2b2ksCsyOxbQ
Nested LSTM:一种能处理更长期信息的新型LSTM扩展
https://mp.weixin.qq.com/s/XAbzaMXP3QOret_vxqVF9A
用深度学习LSTM炒股:对冲基金案例分析
https://mp.weixin.qq.com/s/eeA5RZh35BvlFt45ywVvFg
可视化LSTM网络:探索“记忆”的形成
https://mp.weixin.qq.com/s/h-MYTNTLy7ToPPEZ2JVHpw
阿里巴巴论文提出Advanced LSTM:关于更优时间依赖性刻画在情感识别方面的应用
https://mp.weixin.qq.com/s/pv3gQfCayGmsmGKLbMIFpA
神奇!只有遗忘门的LSTM性能优于标准LSTM
https://mp.weixin.qq.com/s/8BPZ_M8EGk3KxkSleYWSNw
训练可解释、可压缩、高准确率的LSTM
https://hanxiao.github.io/2018/06/24/4-Encoding-Blocks-You-Need-to-Know-Besides-LSTM-RNN-in-Tensorflow/
4 Sequence Encoding Blocks You Must Know Besides RNN/LSTM in Tensorflow
https://mp.weixin.qq.com/s/zMCBQ2D21HoDcDgDolmGMA
上海交大:基于近似随机Dropout的LSTM训练加速
https://mp.weixin.qq.com/s/wPYd2jLUPzlPwIZkb_wSbA
深度递归LSTM-LRP非线性时变多因子模型
https://mp.weixin.qq.com/s/3djAWJs6ecDdPSpQMxqmrg
清华、李飞飞团队等提出强记忆力E3D-LSTM网络
https://mp.weixin.qq.com/s/__qC6Wzy4jaGNGzWr3eOIg
引入额外门控运算,LSTM稍做修改,性能便堪比Transformer-XL
Ultra Deep Network
FractalNet
论文:
《FractalNet: Ultra-Deep Neural Networks without Residuals》
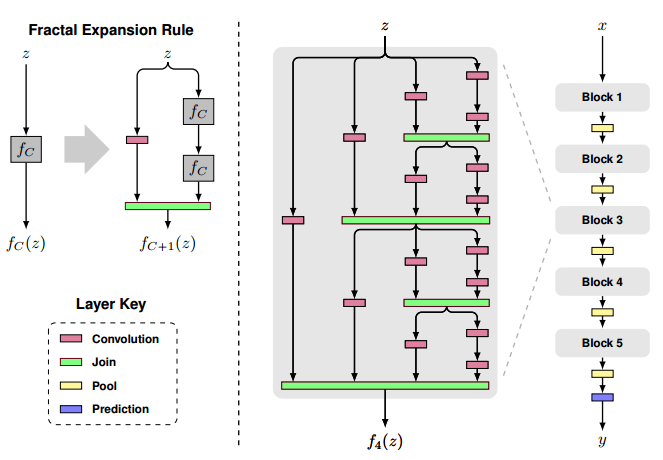
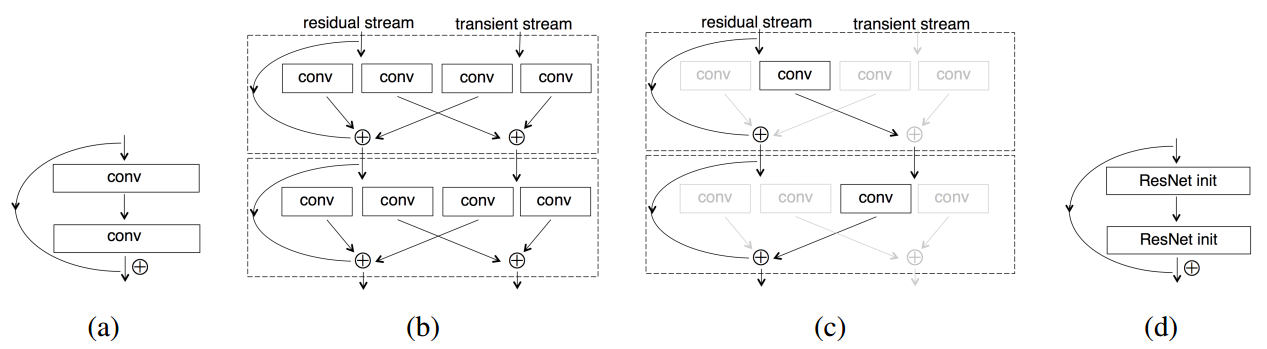
Resnet in Resnet
论文:
《Resnet in Resnet: Generalizing Residual Architectures》
Highway
论文:
《Training Very Deep Networks》
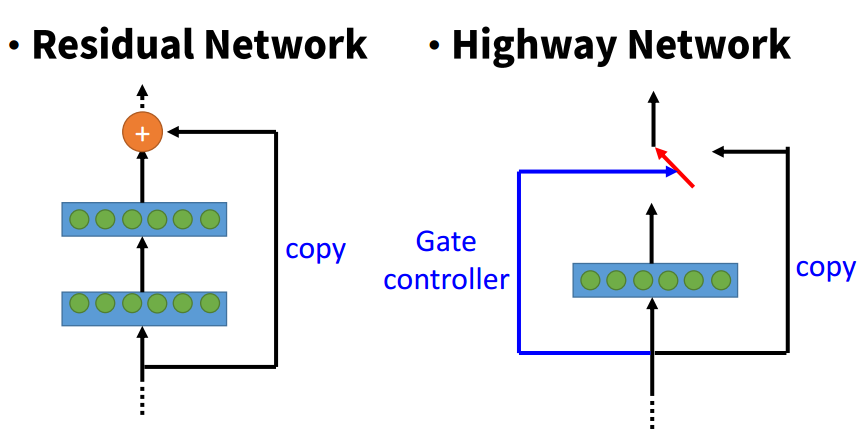
Resnet对于残差的跨层传递是无条件的,而Highway则是有条件的。这种条件开关被称为gate,它也是由网络训练得到的。
ResNet可以被认为是Highway Network的一种特殊情况。然而,实验结果表明Highway Network的性能并不比ResNet好,这有点奇怪。Highway Network的解空间包含ResNet,因此它的性能至少应该和ResNet一样好。这表明,保持这些“梯度高速路”(gradient highway)的畅通比获取更大的解空间更为重要。
注意:Highway实际上比Resnet发表的更早。
DenseNet
DenseNet是康奈尔大学博士后黄高(Gao Huang)、清华大学本科生刘壮(Zhuang Liu)、Facebook人工智能研究院研究科学家Laurens van der Maaten及康奈尔大学计算机系教授Kilian Q. Weinberger于2016年提出的。论文当选CVPR 2017最佳论文。
论文:
《Densely Connected Convolutional Networks》
代码:
https://github.com/liuzhuang13/DenseNet
原始版本是Torch写的,官网上列出了其他框架的实现代码的网址。
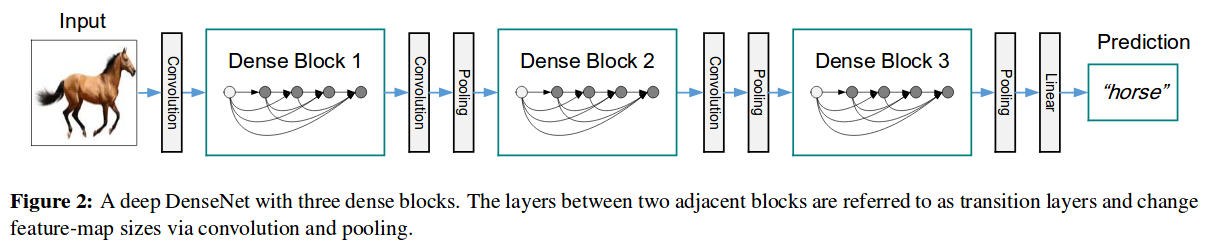
上图是DenseNet的整体网络结构图。从整体层面来看,DenseNet主要由3个dense block组成。
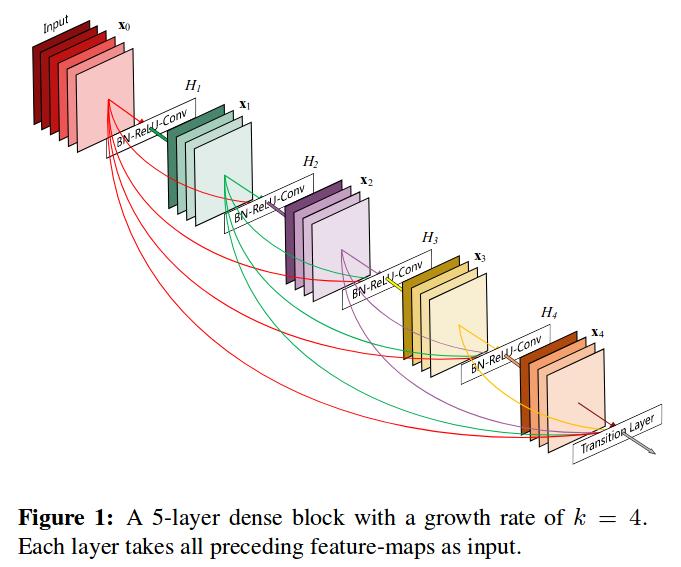
上图就是dense block的结构图。与Resnet的跨层加法不同,这里采用的是Concatenation,也就是将不同层的几个tensor组合成一个大的tensor。
这里的Concatenation是作用在channel上的,即dense block中的所有层的feature map都是等大的,只不过在channel数上,不仅包含本层生成的channel,还包含上层的channel。
这实际上带来了两个问题:
1.feature map的缩小问题。检测网络最后的FC是一定无法接收原始尺寸的feature map的。
2.channel数只增不减显然也是问题。
因此,在两个dense block之间,DenseNet还定义了一个transition layer。该layer包含两个操作:
1.1x1的conv用于降维。
2.avg pool用于缩小feature map。
DenseNet的设计思想
以下是原作者的访谈片段:
DenseNet的想法很大程度上源于我们去年发表在ECCV上的一个叫做随机深度网络(Deep networks with stochastic depth)工作。当时我们提出了一种类似于Dropout的方法来改进ResNet。我们发现在训练过程中的每一步都随机地“扔掉”(drop)一些层,可以显著的提高ResNet的泛化性能。这个方法的成功至少带给我们两点启发:
首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第l层被扔掉之后,第l+1层就被直接连到了第l-1层;当第2到了第l层都被扔掉之后,第l+1层就直接用到了第1层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的DenseNet。
其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了ResNet具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的ResNet随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet的设计正是基于以上两点观察。我们让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别“窄”,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是DenseNet与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使ResNet也是如此。
DenseNet的优点
省参数。在ImageNet分类数据集上达到同样的准确率,DenseNet所需的参数量不到ResNet的一半。对于工业界而言,小模型可以显著地节省带宽,降低存储开销。
省计算。达到与ResNet相当的精度,DenseNet所需的计算量也只有ResNet的一半左右。
抗过拟合。DenseNet具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的应用。这一点从论文中DenseNet在不做数据增强的CIFAR数据集上的表现就能看出来。
由于DenseNet不容易过拟合,在数据集不是很大的时候表现尤其突出。在一些图像分割和物体检测的任务上,基于DenseNet的模型往往可以省略在ImageNet上的预训练,直接从随机初始化的模型开始训练,最终达到相同甚至更好的效果。由于在很多应用中实际数据跟预训练的ImageNet自然图像存在明显的差别,这种不需要预训练的方法在医学图像,卫星图像等任务上都具有非常广阔的应用前景。
DenseNet的优化问题
当前的深度学习框架对DenseNet的密集连接没有很好的支持,我们只能借助于反复的拼接(Concatenation)操作,将之前层的输出与当前层的输出拼接在一起,然后传给下一层。对于大多数框架(如Torch和TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个L层的网络,要消耗相当于L(L+1)/2层网络的内存(第l层的输出在内存里被存了(L-l+1)份)。
解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样DenseNet对内存的消耗便从平方级别降到了线性级别。
参考
https://www.leiphone.com/news/201708/0MNOwwfvWiAu43WO.html
CVPR 2017最佳论文作者解读:DenseNet 的“what”、“why”和“how”
https://zhuanlan.zhihu.com/p/28124810
为什么ResNet和DenseNet可以这么深?一文详解残差块为何有助于解决梯度弥散问题
https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651988934&idx=2&sn=0e5ffa195ef67a1371f3b5b223519121
ResNets、HighwayNets、DenseNets:用TensorFlow实现超深度神经网络
https://mp.weixin.qq.com/s/okx0jZR6PmFm3ikCCUbNkg
从DensNet到CliqueNet,解读北大在卷积架构上的探索
https://mp.weixin.qq.com/s/geANIVbd4C0qpSig0IB2zA
梯形DenseNets结构实现语义分割新高度!

您的打赏,是对我的鼓励
