DL » 深度学习(十八)——Bi-directional RNN, Prompt Learning, 无监督/半监督/自监督深度学习(1)
2017-10-01 :: 5409 Words自动求导(续)
参考
https://mp.weixin.qq.com/s/7Z2tDhSle-9MOslYEUpq6g
从概念到实践,我们该如何构建自动微分库
https://mp.weixin.qq.com/s/bigKoR3IX_Jvo-re9UjqUA
机器学习之——自动求导
https://www.jianshu.com/p/4c2032c685dc
自动求导框架综述
http://txshi-mt.com/2018/10/04/NMT-Tutorial-3b-Autodiff/
自动微分
https://mp.weixin.qq.com/s/WiZ00mkEB7CND3VyIM5Swg
最新《自动微分手册》77页pdf
https://mp.weixin.qq.com/s/xXwbV46-kTobAMRwfKyk_w
自动求导–Deep Learning框架必备技术二三事
https://mp.weixin.qq.com/s/f0xFfA1inOVOdJnSZR4k6Q
自动微分技术
https://zhuanlan.zhihu.com/p/79801410
PyTorch的自动求导机制详细解析,PyTorch的核心魔法
https://zhuanlan.zhihu.com/p/29904755
Autograd:PyTorch中的梯度计算
https://zhuanlan.zhihu.com/p/69294347
PyTorch的Autograd
https://zhuanlan.zhihu.com/p/83172023
Pytorch autograd,backward详解
https://mp.weixin.qq.com/s/PELBuCvu-7KQ33XBtlYfYQ
深度学习中的微分
https://zhuanlan.zhihu.com/p/24709748
矩阵求导术(上)
https://zhuanlan.zhihu.com/p/24863977
矩阵求导术(下)
https://mp.weixin.qq.com/s/2hu6a0wScJedwk3a5aKbIw
自动微分到底是什么?这里有一份自我简述
https://zhuanlan.zhihu.com/p/347385418
AI框架基础技术之自动求导机制 (Autograd)
https://www.zhihu.com/question/497827630
Pytorch的自动微分机制是自动创建一个可以记录所有数据操作的计算图(有向无环图(DAG))吗?
https://www.cnblogs.com/royhoo/p/Autodiff.html
自动微分(Autodiff)
Bi-directional RNN
众所周知,RNN在处理长距离依赖关系时会出现问题。LSTM虽然改进了一些,但也只能缓解问题,而不能解决该问题。
研究人员发现将原文倒序(将其倒序输入编码器)产生了显著改善的结果,因为从解码器到编码器对应部分的路径被缩短了。同样,两次输入同一个序列似乎也有助于网络更好地记忆。
基于这样的实验结果,1997年Mike Schuster提出了Bi-directional RNN模型。
Mike Schuster,杜伊斯堡大学硕士(1993)+奈良科技大学博士。语音识别专家,尤其是日语、韩语方面。Google研究员。
论文:
《Bidirectional Recurrent Neural Networks》
下图是Bi-directional RNN的结构示意图:
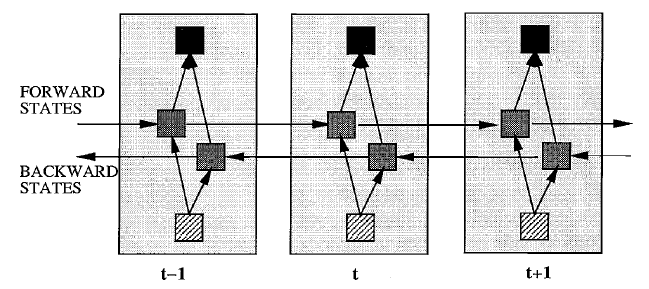
从图中可以看出,Bi-directional RNN有两个隐层,分别处理前向和后向的时序信息。
除了原始的Bi-directional RNN之外,后来还出现了Deep Bi-directional RNN。
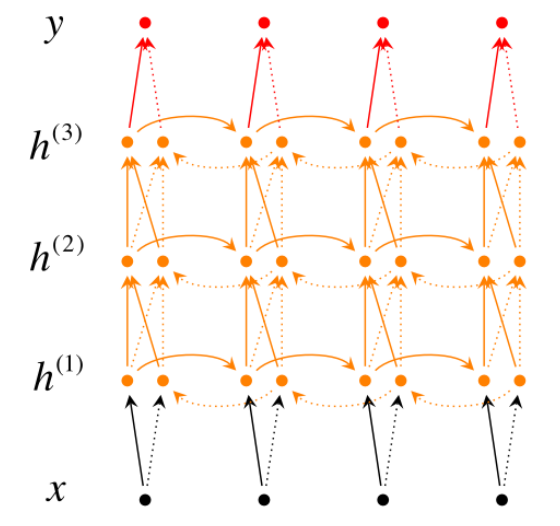
上图是包含3个隐层的Deep Bi-directional RNN。
参见:
https://mp.weixin.qq.com/s/_CENjzEK1kjsFpvX0H5gpQ
结合堆叠与深度转换的新型神经翻译架构:爱丁堡大学提出BiDeep RNN
Prompt Learning
在BERT和Word2Vec相关章节中,我们已经看到了,如何采用类似完形填空的方式,来利用大量的无标签语料,对模型进行预训练。这里的完形填空就是一种Prompt Learning。
更一般的对于输入的文本\(x\),有函数\(f_{prompt}(x)\),将\(x\)转化成prompt的形式\(x'\),即:
\[x'=f_{prompt}(x)\]该函数通常会进行两步操作:
-
使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入x的位置[X]和用于生成答案文本的位置[Z]。
-
把输入x填到的位置[X]。
例如,在文本情感分类的任务中,假设输入是:
” I love this movie.”
使用的模板是
” [X] Overall, it was a [Z] movie.”
那么得到的\(x'\)就应该是 “I love this movie. Overall it was a [Z] movie.”
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。[X]和[Z]的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
如何设计合适的[X]和[Z],就是Prompt Learning的主要议题了。
目前学术界一般将NLP任务的发展分为四个阶段即NLP四范式:
第一范式:基于传统机器学习模型的范式,如tf-idf特征+朴素贝叶斯等机器算法;
第二范式:基于深度学习模型的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
第三范式:基于预训练模型+finetuning的范式,如BERT+finetuning的NLP任务,相比于第二范式,模型准确度显著提高,但是模型也随之变得更大,但小数据集就可训练出好模型;
第四范式:基于预训练模型+Prompt+预测的范式,如BERT+Prompt的范式相比于第三范式,模型训练所需的训练数据显著减少。
不管是ChatGPT还是Stable Diffusion,对普通用户都像是黑箱,你在对话或者提供命令之前,并不能完全预知其结果。
大家在使用同样的基础模型,为什么有人能画出“赛博 Coser”,有人却只能画出“克苏鲁古神”?
prompt和instruction这俩词在LLM领域偶尔会容易被混为一谈,实际上二者虽然形式相近,都是用来解锁模型的能力,但本质思路却是截然相反的。
prompt是让人来适应模型,给模型以提示。
instruction是让模型听人指令,给模型以指令。
由于目前对LLM的认识不足、研究不深,很大程度上需要依靠prompt工程来探索LLM的能力。早期的时候,prompt-tuning火了一阵儿,一度被誉为第四范式,但最近慢慢好像不这样提了,或者说提法慢慢变成了instruction-tuning。原因可能主要就在于思路上的转变,让人工来构建prompt去适应模型属于是个经验活儿、运气活儿,费力不一定讨好,不如反过来,直接从用户数据收集用户指令。
https://www.zhihu.com/question/585294957
ChatGPT爆火带动全新职业提示工程师,提示工程有多重要?未来该职业走向如何?
https://zhuanlan.zhihu.com/p/608495853
ChatGPT火爆,最全prompt工程指南登GitHub热榜
https://zhuanlan.zhihu.com/p/663182483
快速入门Prompt
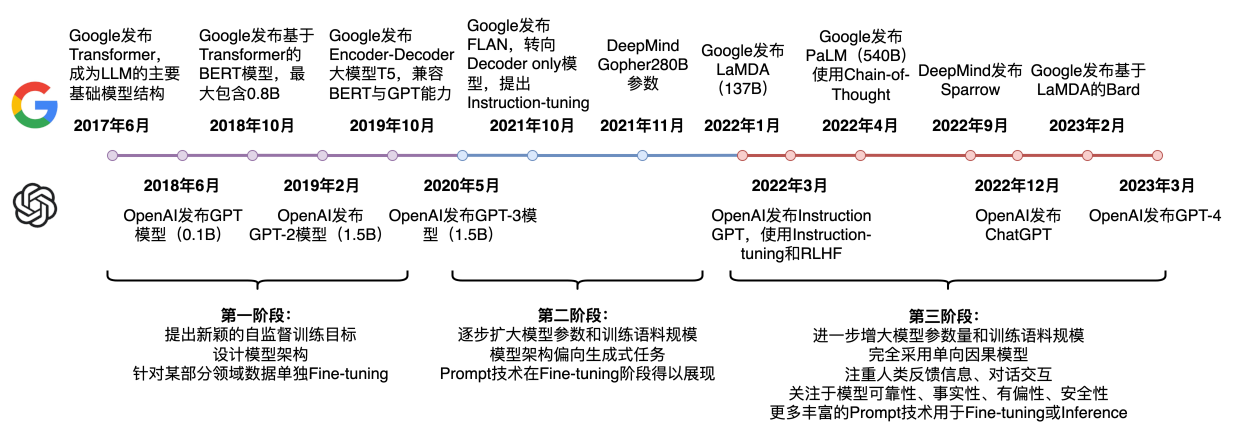
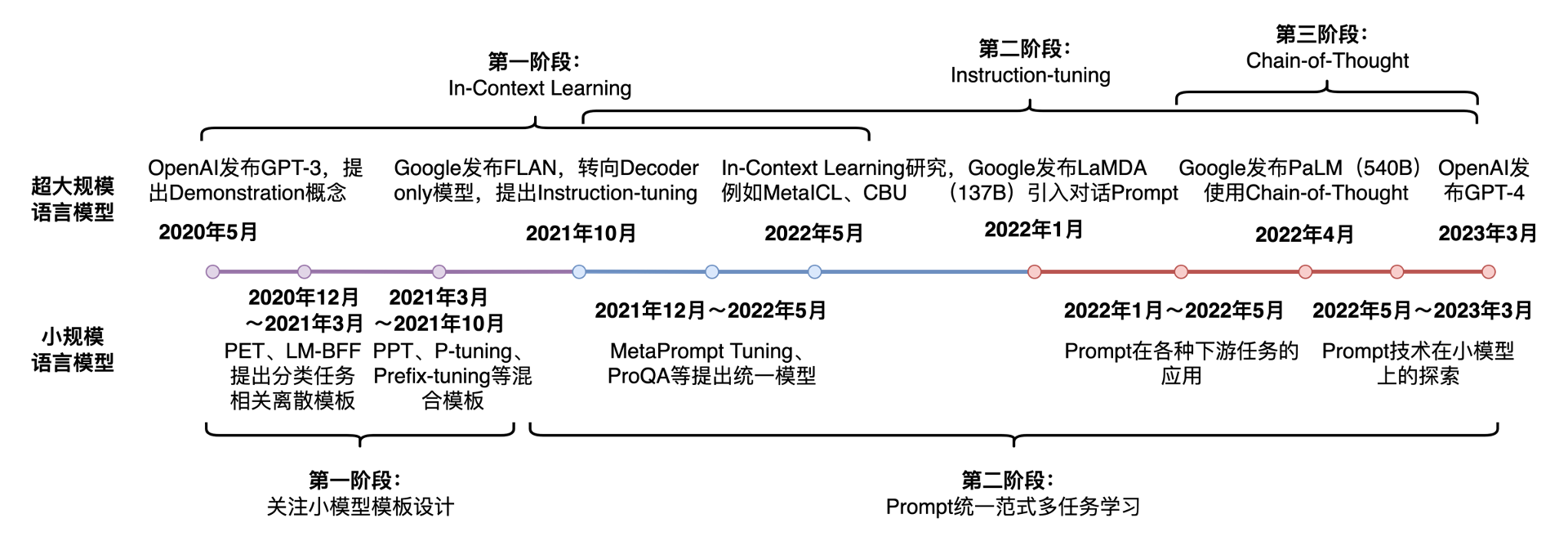
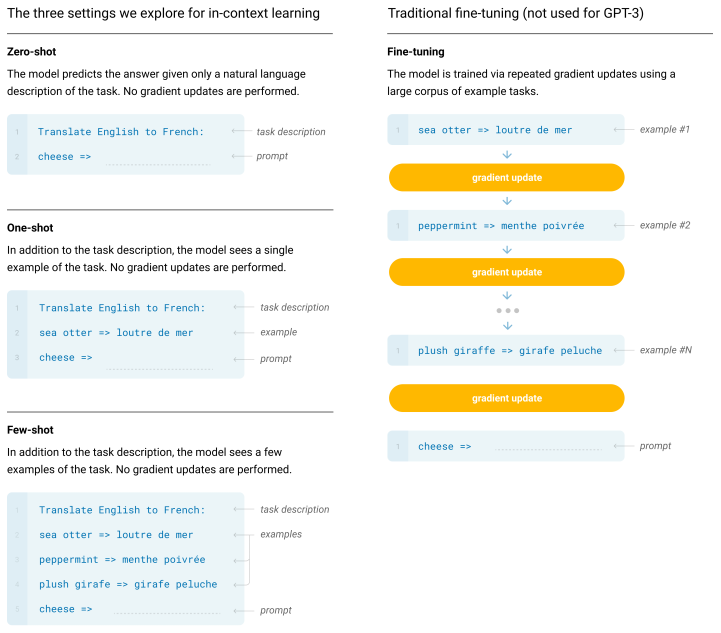
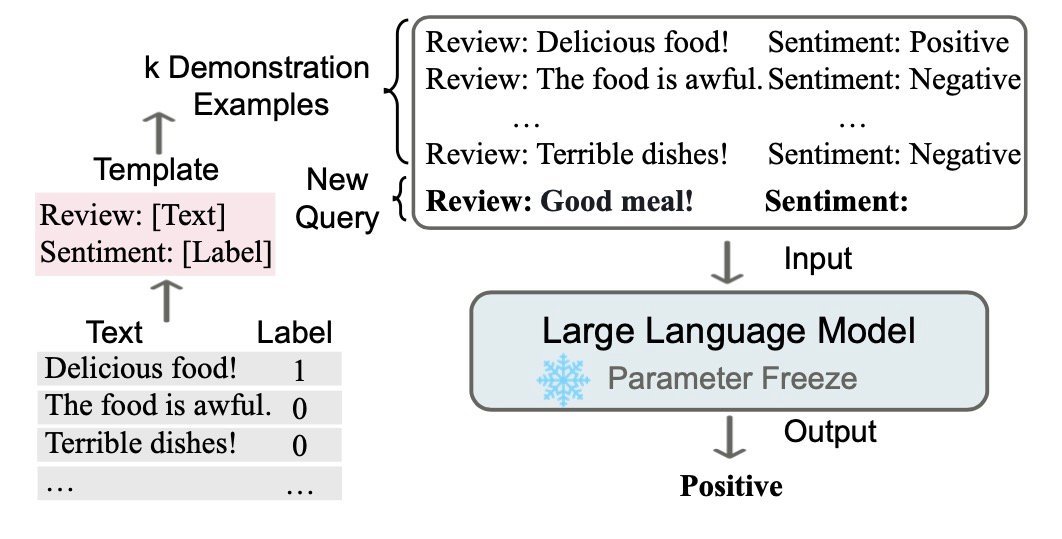
in-context learning是一种特殊的训练模式,通过设计启发式的模板,可以在无需更新模型参数的情况下,获得答案。但是只有超大模型才具有这种启发/涌现能力(emergent abilities),小模型就算了吧。
论文:
《Language Models are Few-Shot Learners》
https://zhuanlan.zhihu.com/p/597036814
如何优化大模型的In-Context Learning效果?
https://github.com/davidkimai/Context-Engineering
一个关于Context Engineering的项目
https://www.promptingguide.ai/
Prompt Engineering Guide
Prompt Engineering的进阶,就是Skill Engineering。它将特定领域的专业知识和工作流程封装成可复用、可调用、可分享的标准化指令模块。
一个标准的Skill通常包含三层定义 :
- 语义层 (Semantic Manifest):给LLM看的”说明书”,描述Skill的用途、触发场景、参数定义,让AI理解”什么时候该用这个技能”。
- 执行层 (Executor):实际执行的代码逻辑(Python/Java/Go函数、API调用等),完成具体的数据查询、文件处理等操作。
- 策略层 (SOP/Workflow):定义执行步骤、参数组合、异常处理流程,指导AI如何编排多个工具完成任务。
https://zhuanlan.zhihu.com/p/2027466594926751746
SkillReducer:为Skills瘦身,破解Token低效难题
参考:
https://mp.weixin.qq.com/s/dkNH4BLOH36B5h_UCcRLnA
NLP新宠——浅谈Prompt的前世今生
https://www.zhihu.com/question/504324484
Prompt Tuning相比于Fine Tuning在哪些场景下表现更好?
https://mp.weixin.qq.com/s/2eA4PBd-wr9tVyyuzJ66Bw
Fine-tune之后的NLP新范式:Prompt越来越火,CMU华人博士后出了篇综述文章
https://wjn1996.blog.csdn.net/article/details/120607050
Prompt-Tuning——深度解读一种新的微调范式
https://zhuanlan.zhihu.com/p/615277009
总结开源可用的Instruct/Prompt Tuning数据
https://zhuanlan.zhihu.com/p/1938967453951571269
Context Engineering,一篇就够了
https://zhuanlan.zhihu.com/p/661683573
AI高手都在用的10个提示词prompt网站
无监督/半监督/自监督深度学习
自监督学习是一种特殊目的的无监督学习。不同于传统的AutoEncoder等方法,仅仅以重构输入为目的,而是希望通过surrogate task学习到和高层语义信息相关联的特征。
MoCo
https://mp.weixin.qq.com/s/9zaTjwwGPHHzSv1ZmHf8_g
不妨试试MoCo,来替换ImageNet上pretrain模型!
https://mp.weixin.qq.com/s/GC6PGlweneYtYo7_SUr0Zw
MoCo V3:我并不是你想的那样!
https://mp.weixin.qq.com/s/sAYh3l2eab2r2KpbdxN30A
MoCo三部曲
对比学习

https://mp.weixin.qq.com/s/r1uXn2jGsHZcZ8Nk7GnGFA
语义表征的无监督对比学习:一个新理论框架
https://zhuanlan.zhihu.com/p/346686467
对比学习(Contrastive Learning)综述
https://mp.weixin.qq.com/s/SOaA9XNnymLgGgJ5JNSdBg
对比学习(Contrastive Learning)相关进展梳理
https://mp.weixin.qq.com/s/U0pTQkW55evm94iQORwGeA
图解SimCLR框架,用对比学习得到一个好的视觉预训练模型
https://mp.weixin.qq.com/s/1RJ4bbfDC5LiN2PNIxdzew
SimCLR框架的理解和代码实现以及代码讲解
https://mp.weixin.qq.com/s/-Vtl_8nND7WCPLdL5bNlMw
探索孪生神经网络:请停止你的梯度传递
https://zhuanlan.zhihu.com/p/321642265
《探索简单孪生网络表示学习》阅读笔记

您的打赏,是对我的鼓励
