DL » 深度学习(十七)——自动求导
2017-09-23 :: 6457 WordsStyle Transfer(续)
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
这篇论文是李飞飞组的Justin Johnson的作品。
Justin Johnson的个人主页:
https://cs.stanford.edu/people/jcjohns/
代码:
https://github.com/OlavHN/fast-neural-style
https://github.com/lengstrom/fast-style-transfer/
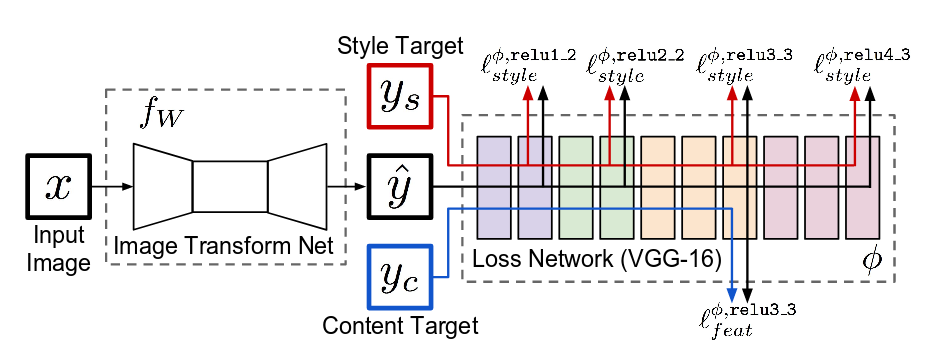
可以看出该论文的方法和Texture Networks基本一致,差别仅在于generator network和descriptor network的结构,略有不同而已。这里不再赘述。
参考:
https://blog.csdn.net/Hungryof/article/details/61195783
超越fast style transfer—任意风格图和内容图0.1秒出结果
https://zhuanlan.zhihu.com/p/35798776
快速风格迁移(fast-style-transfer)
其他
原版的neural style是用Gram矩阵来进行匹配风格,但是也有用其他的。例如:
MRF loss(ombining markov random fields and convolutional neural networks for image synthesis.)
Adversarial loss(C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. In ECCV,2016)
梯度直方图(P. Wilmot, E. Risser, and C. Barnes. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv preprint arXiv:1701.08893 , 2017)
ResNet + Style transfer
Style transfer的CNN bone也是有讲究的,除了AlexNet之外,还可以使用VGG,但是它在ResNet上效果不佳。直到最近的论文才对这一现象有所解释。
参考:
https://mp.weixin.qq.com/s/Pub83W6nMM02lEIrsBe49Q
谁说只有VGG才能做风格迁移,ResNet也可以!
Style transfer的其他用法
使用VGG抽取的所谓纹理信息,也可以用于图像增强领域。具体的做法是将纹理信息作为Loss的一部分。(注意不是Loss的全部,否则就只是Style transfer了)。
文本风格迁移
不光图像、语音有风格迁移,文本也有。
下面是一个金庸风格的例子
Input:谢谢
Output(金庸):多谢之至
Input:再见
Output(金庸):别过!
Input:请问您贵性?
Output(金庸):请教阁下尊姓大名?
https://mp.weixin.qq.com/s/7nvqifY_J34mWEUM5IUsLQ
NLP文本风格迁移
参考
https://zhuanlan.zhihu.com/p/26746283
图像风格迁移(Neural Style)简史
https://mp.weixin.qq.com/s/64H2dDcaTcKdKaOnwdsoEg
基于深度学习的艺术风格化研究
https://blog.csdn.net/red_stone1/article/details/79055467
人脸识别与神经风格迁移
https://blog.csdn.net/cicibabe/article/details/70885715
卷积神经网络图像风格转移
https://blog.csdn.net/stdcoutzyx/article/details/53771471
图像风格转换(Image style transfer)
https://blog.csdn.net/u011534057/article/details/78935202
风格迁移学习笔记(1):Multimodal Transfer: A Hierarchical Deep Convolutional Neural Network for Fast
https://blog.csdn.net/u011534057/article/details/78935230
风格迁移学习笔记(2):Universal Style Transfer via Feature Transforms
https://mp.weixin.qq.com/s/l3hQCQWh5NgihzTs2A049w
风格迁移原理及tensorflow实现
https://mp.weixin.qq.com/s/5Omfj-fYRDt9j2VZH1XXkQ
如何用Keras打造出“风格迁移”的AI艺术作品
https://mp.weixin.qq.com/s/4q-9QsXD04mD-f2ke7ql8A
tensorflow风格迁移网络训练与使用
https://blog.csdn.net/hungryof/article/details/53981959
谈谈图像的Style Transfer(一)
https://blog.csdn.net/Hungryof/article/details/71512406
谈谈图像的style transfer(二)
https://mp.weixin.qq.com/s/8Fz6Q-6VgJsAko0K7HDsow
一个模型搞定所有风格转换,直接在浏览器实现(demo+代码)
https://github.com/cysmith/neural-style-tf
TensorFlow (Python API) implementation of Neural Style.这个项目实现了两张图片的画风融合,非常牛。
https://github.com/jinfagang/pytorch_style_transfer
这个和上面的一样,不过是用pytorch实现的。
https://mp.weixin.qq.com/s/g1hpuzH36j_rbYR23Mwx0w
开源图像风格迁移,快看看大画家的潜力股
https://mp.weixin.qq.com/s/OzancX-44Si13ZtZiONnpQ
基于感知损失的实时风格迁移与超分辨率重建
https://mp.weixin.qq.com/s/yr9fNyzpOBt7dLsnh2T2xg
使用TFLite在移动设备上优化与部署风格转化模型
https://mp.weixin.qq.com/s/9AEYcY04lAl3dCRK9LPBeQ
人脸风格化核心技术与数据集总结
https://mp.weixin.qq.com/s/ylfeWiOrftCB823_gjQNmA
图像风格迁移也有框架了:使用Python编写,与PyTorch完美兼容,外行也能用
自动求导
DL发展到现在,其基本运算单元早就不止CNN、RNN之类的简单模块了。针对新运算层出不穷的现状,各大DL框架基本都实现了自动求导的功能。
论文:
《Automatic Differentiation in Machine Learning: a Survey》
Manual differentiation
手动推出导数是什么样,然后硬编码。这种做法既耗时也容易出错,还没有灵活性。
Numerical differentiation
数值微分最大的特点就是很直观,好计算,它直接利用了导数定义:
\[f'(x)=\lim_{h\to 0}{f(x+h)-f(x)\over h}\]不过这里有一个很大的问题:h怎么选择?选大了,误差会很大;选小了,不小心就陷进了浮点数的精度极限里,造成舍入误差。
第二个问题是对于参数比较多时,对深度学习模型来说,上面的计算是不够高效的,因为每计算一个参数的导数,你都需要重新计算\(f(x+h)\)。
因此,这种方法并不常用,而主要用于做梯度检查(Gradient check),你可以用这种不高效但简单的方法去检查其他方法得到的梯度是否正确。
Symbolic differentiation
符号微分的主要步骤如下:
1.需要预置基本运算单元的求导公式。
2.遍历计算图,得到运算表达式。
3.根据导数的代入法则和四则运算法则,求出复杂运算的求导公式。
这种方法没有误差,是目前的主流,但遍历比较费时间。
符号微分最大的弊病在于其对表达式的严格展开和变换也导致了所谓的表达式膨胀(expression swell)问题。
Automatic Differentiation
自动微分是介于数值微分和符号微分之间的方法。首先对基本算子(函数)应用符号微分方法,其次带入数值进行计算,保留中间结果,最后通过链式求导法将中间结果应用于整个函数。
简单来说就是,layer内部采用符号微分,layer之间采用数值微分。
优点:精度高,无表达式膨胀问题。
缺点:需要存储一些中间求导结果,内存占用会增加。
Automatic Differentiation主要包括Forward-Mode Autodiff和Reverse-Mode Autodiff两种方法。
Forward-Mode Autodiff
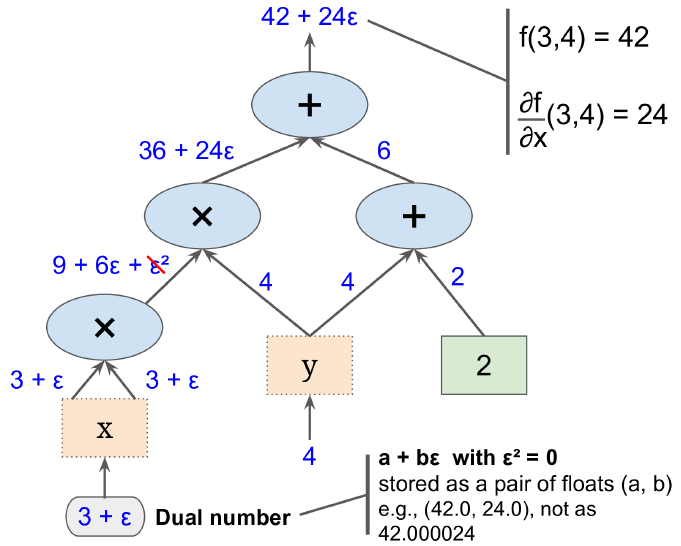
Forward-Mode Autodiff依赖于dual numbers。
类比复数的概念:
\[x = a + bi \quad (i^2 = -1)\]我们定义Dual number:
\[x \mapsto x = x + \dot{x} d \quad (d^2=0)\]定义Dual number的运算法则:
\[(x + \dot{x}d) + ( y + \dot{y}d) = x + y + (\dot{x} + \dot{y})d\] \[(x + \dot{x}d) ( y + \dot{y}d) = xy + \dot{x}yd + x\dot{y}d + \dot{x}\dot{y}d^2 = xy + (\dot{x}y+ x\dot{y})d\] \[-(x + \dot{x}d) = - x - \dot{x}d\] \[\frac{1}{x + \dot{x}d} = \frac{1}{x} - \frac{\dot{x}}{x^2}d\]dual number有很多非常不错的性质。以下面的指数运算多项式为例:
\[f(x) = p_0 + p_1x + p_2x^2 + ... + p_nx^n\]用\(x + \dot{x}d\)替换x,则有:
\[\begin{array}\\ f(x + \dot{x}d) = p_0 + p_1(x + \dot{x}d) + ... + p_n(x + \dot{x}d)^n \\ = p_0 + p_1x + p_2x^2 + ... + p_nx^n + \\ p_1\dot{x}d + 2p_2x\dot{x}d + ... + np_{n-1}x\dot{x}d\\ = f(x) + f'(x)\dot{x}d \end{array}\]可以看出d的系数就是\(f'(x)\)。
Reverse-Mode Autodiff
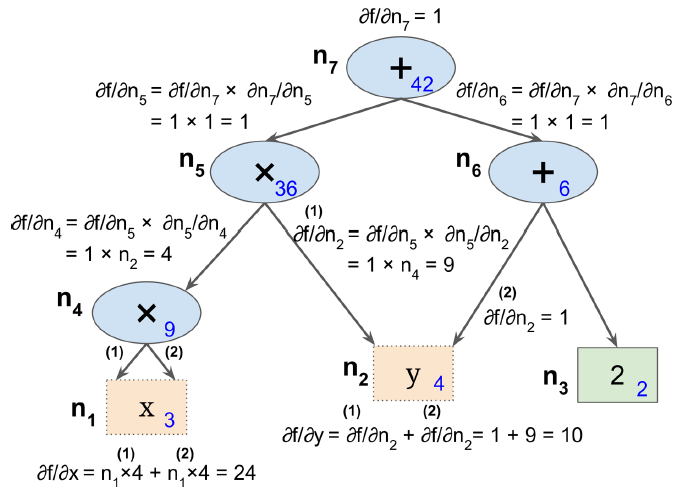
该算法首先前向(也就是从输入到输出)计算每个节点的值,然后反向(从输出到输入)计算所有的偏导数。
当输出的维度大于输入的时候,适宜使用前向模式微分;当输出维度远远小于输入的时候,适宜使用反向模式微分。
考虑到大多数应用的特点是输出维度远远小于输入,因此目前大部分AI框架都会优先采用反向模式。
实现方式
虽然自动微分的数学原理已经明确,包括正向和反向的数学逻辑和模式。但具体的实现方法则可以有很大的差异。
目前主要有三类方案:
基本表达式:基本表达式或者称元素库(Elemental Libraries),基于元素库中封装一系列基本的表达式(如:加减乘除等)及其对应的微分结果表达式,作为库函数。用户通过调用库函数构建需要被微分的程序。
操作符重载:操作符重载或者称运算重载(Operator Overloading,OO),利用现代语言的多态特性(例如C++/JAVA/Python等高级语言),使用操作符重载对语言中基本运算表达式的微分规则进行封装。
源代码变换(Source Code Transformation,SCT):源代码变换或者叫做源码转换(Source Code Transformation,SCT)则是通过对语言预处理器、编译器或解释器的扩展,将其中程序表达(如:源码、AST抽象语法树 或 编译过程中的中间表达 IR)的基本表达式微分规则进行预定义,再对程序表达进行分析得到基本表达式的组合关系,最后使用链式法则对上述基本表达式的微分结果进行组合生成对应微分结果的新程序表达,完成自动微分。
不可导函数的求导
不可导函数的求导,一般采用泰勒展开的方式。典型的算法有PGD(Proximal Gradient Descent)。
参考:
https://blog.csdn.net/bingecuilab/article/details/50628634
Proximal Gradient Descent for L1 Regularization
Tape
无论前向还是后向求导,都需要记录前向传播的所有计算过程以及中间结果。这种记录和调用的过程类似于磁带的读写,是一种顺序访问,而非随机访问,故名为Tape方法。
针对动态图的自动求导,TF提出了GradientTape方法。
https://zhuanlan.zhihu.com/p/102207302
tensorflow计算图与自动求导——tf.GradientTape
其他
Jacobian-vector product function,JVP
vector-Jacobian product function,VJP
Hessian Vector Product,HVP
https://blog.csdn.net/apache/article/details/113925886
Pytorch,Tensorflow Autograd/AutoDiff nutshells: Jacobian,Gradient,Hessian,JVP,VJP,etc

您的打赏,是对我的鼓励
