DL » 深度学习(十三)——Non-local Networks, 姿态/行为检测, 花式池化
2017-08-28 :: 6486 WordsNon-local Networks
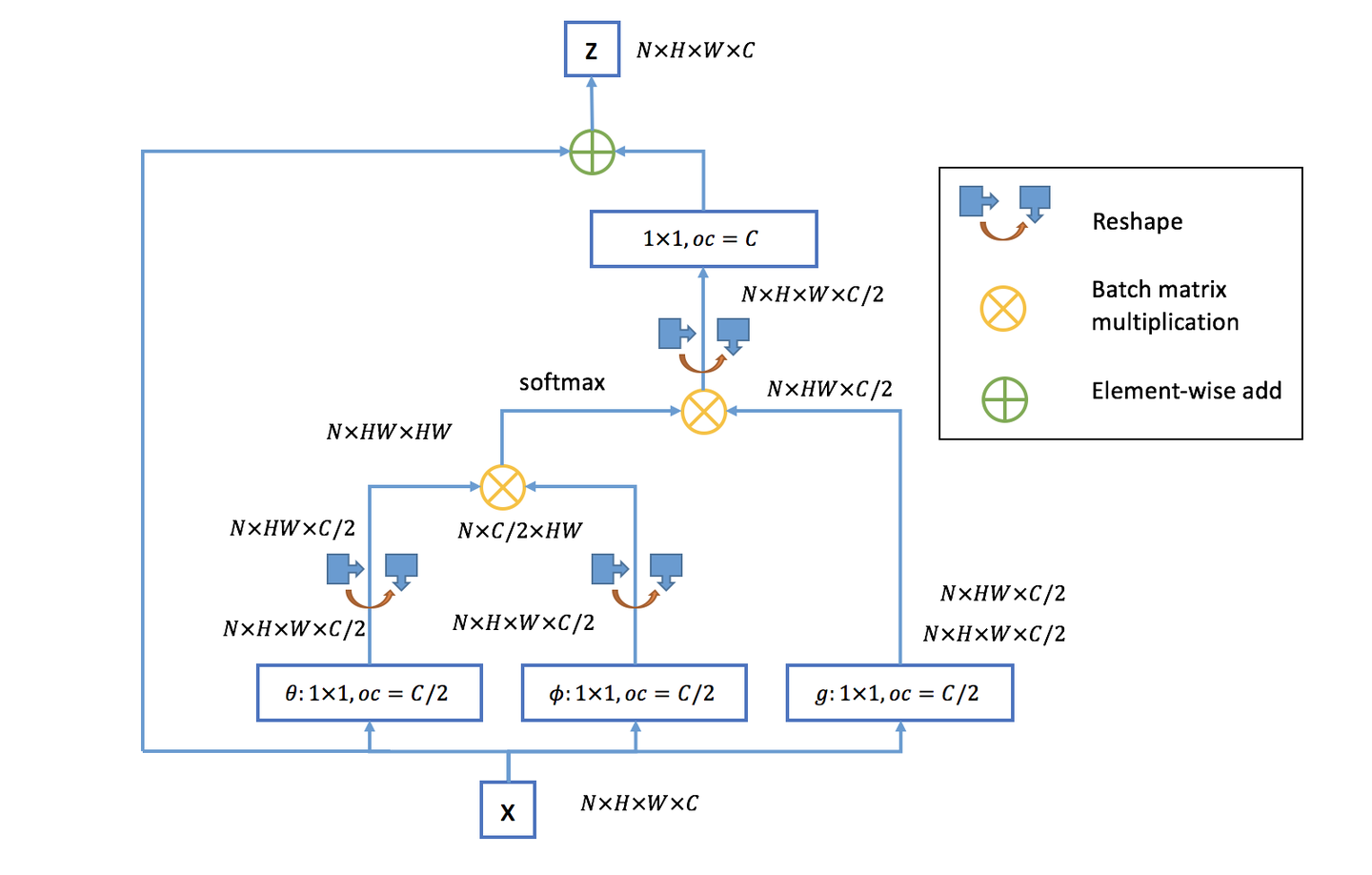
self-attention是non-local的一个特例。
https://zhuanlan.zhihu.com/p/33345791
Non-local neural networks
https://zhuanlan.zhihu.com/p/109514384
医学图像分割的Non-local U-Nets
https://mp.weixin.qq.com/s/Tox7jEFNHFHZQ-KdojMIpA
GCNet:当Non-local遇见SENet
https://zhuanlan.zhihu.com/p/48198502
Non-local Neural Networks论文笔记
https://mp.weixin.qq.com/s/zHZO1pmY8PCoI9vkDOaUgw
CCNet–于”阡陌交通”处超越恺明的Non-local
https://mp.weixin.qq.com/s/6q2q9OVhOYjk4ZrhLvAdkA
Non-local Neural Networks及自注意力机制思考
https://mp.weixin.qq.com/s/v4IK4gJvZ3J03Ikrujiyhw
视觉注意力机制:Non-local模块与Self-attention的之间的关系与区别?
https://mp.weixin.qq.com/s/EElEYaDbfdxlGWL_jBEwzQ
Non-local与SENet、CBAM模块融合:GCNet、DANet
https://mp.weixin.qq.com/s/lZxamQryotfLTKpRJKaA5Q
Non-local模块如何改进?来看CCNet、ANN
https://mp.weixin.qq.com/s/2O-T6akdPjGe2rUZKoE4Kw
Self-attention机制及其应用:Non-local网络模块
https://zhuanlan.zhihu.com/p/138444916
写写non local network
姿态/行为检测
基于CNN的2D多人姿态估计方法,通常有2个思路(Bottom-Up Approaches和Top-Down Approaches):
-
Top-Down framework,就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,缺点是受人体检测框影响较大,代表算法有RMPE。
-
Bottom-Up framework,就是先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,代表方法就是openpose。
OpenPose
OpenPose是一个实时多人关键点检测的库,基于OpenCV和Caffe编写。它是CMU的Yaser Sheikh小组的作品。
Yaser Ajmal Sheikh,巴基斯坦信德省易司哈克工程科学与技术学院本科(2001年)+中佛罗里达大学博士(2006年)。现为CMU副教授。
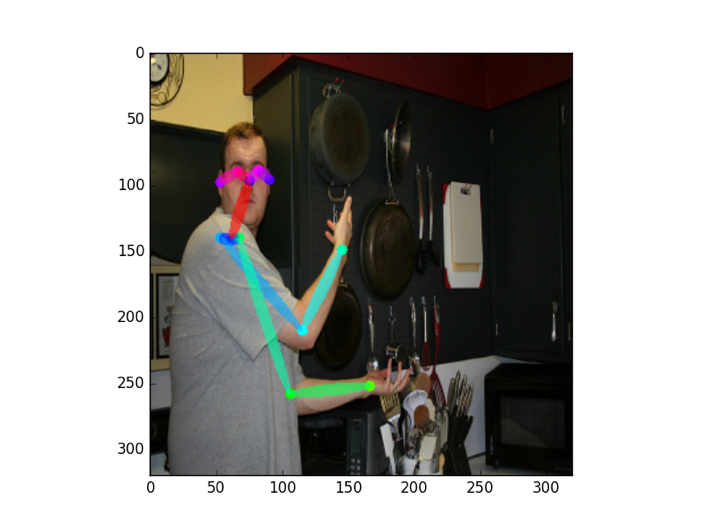
OpenPose的使用效果如上图所示。
论文:
《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》
《Hand Keypoint Detection in Single Images using Multiview Bootstrapping》
《Convolutional pose machines》
官方代码(caffe):
https://github.com/CMU-Perceptual-Computing-Lab/openpose
Tensorflow版本:
https://github.com/ildoonet/tf-pose-estimation
参考:
https://zhuanlan.zhihu.com/p/37526892
OpenPose:实时多人2D姿态估计
https://mp.weixin.qq.com/s?__biz=MzIwMTE1NjQxMQ==&mid=2247488741&idx=2&sn=93f05747f3a94a2cbfa2431901d2d97f
OpenPose升级,CMU提出首个单网络全人体姿态估计网络,速度大幅提高
https://mp.weixin.qq.com/s/jAmUscrMZ8EmG3th-3Yx3w
实战:基于OpenPose的卡通人物可视化
DensePose
与OpenPose类似的还有Facebook提出的DensePose。
论文:
《DensePose: Dense Human Pose Estimation In The Wild》
数据集:
http://densepose.org/
这里包含了一个名为DensePose-COCO的姿态数据集。
参考:
https://mp.weixin.qq.com/s/sFd9hrMrKDl5UJwlY6N7mw
Facebook提出DensePose数据集和网络架构:可实现实时的人体姿态估计
https://mp.weixin.qq.com/s/t29ITfRPD3yCmRD5wJyq7g
ICCV2017 PoseTrack challenge优异方法:基于检测和跟踪的视频中人体姿态估计
https://mp.weixin.qq.com/s/mGcKpu3BXlAGO-t2FUCxAg
基于深度模型的人脸对齐和姿态标准化
https://mp.weixin.qq.com/s/gwRD3SzTof349V8W0_lRfg
实时评估世界杯球员的正确姿势:FAIR开源DensePose
https://zhuanlan.zhihu.com/p/39219404
Dense Pose
https://blog.csdn.net/sinat_26917383/article/details/79704097
关键点定位:四款人体姿势关键点估计论文笔记
https://mp.weixin.qq.com/s/-A87-z5inWBsF1-5UYagTA
Facebook实时人体姿态估计:Dense Pose及其应用展望
Hourglass networks
Hourglass networks是University of Michigan的Alejandro Newell的作品。(2016年3月)
论文:
《Stacked hourglass networks for human pose estimation》
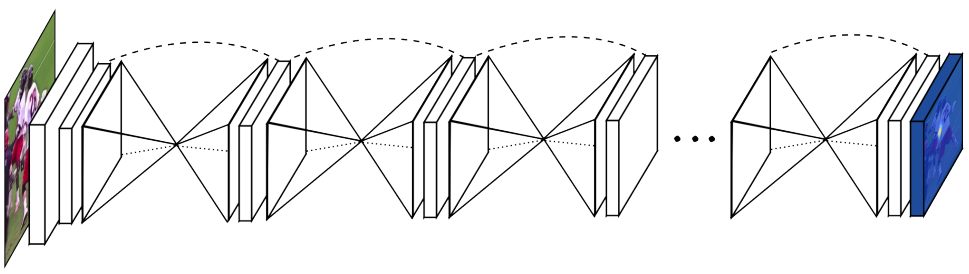
上图是Stacked Hourglass networks的网络结构图,其中的每个沙漏形状的结构,都是一个hourglass module,其结构如下图所示:
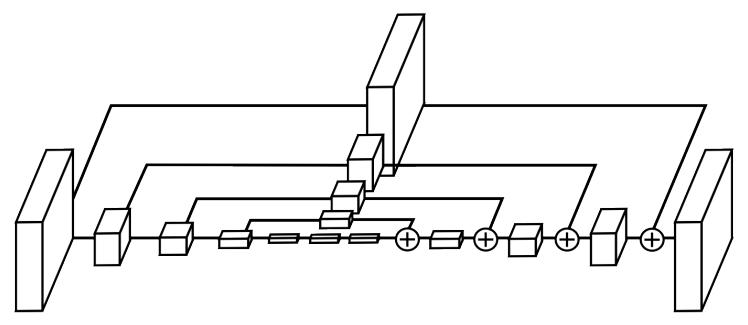
hourglass module基本可以看作是把concat换成add之后的U-NET,或者也可以看作是resnet版的U-NET。上图中一个module包含了4次add,因此也被叫做4阶hourglass module。
参考:
https://blog.csdn.net/shenxiaolu1984/article/details/51428392
Stacked Hourglass算法详解
https://mp.weixin.qq.com/s/nfPBRBLG1ThsY3DvONHYrA
CenterNet骨干网络之hourglass
https://mp.weixin.qq.com/s/lzxd9J97nkOBLXgEcbdoKA
使用Hourglass网络来理解人体姿态
评价度量
Object Keypoint Similarity(OKS):
\[\mathbf{OKS} = \frac{\sum_i exp(-\frac{d_i^2}{2s^2k_i^2}) \delta (v_i >0)}{\sum_i \delta (v_i >0)}\]其中,\(d_i\)是检测的关键点与groundtruth关键点之间的欧氏距离;\(v_i\)是groundtruth关键点的可见性标志;s是目标的尺度;\(k_i\)是控制衰减(falloff)的per-keypoint常数。
步态识别
https://mp.weixin.qq.com/s/g6032xTGEtvbsfwXboMJ4A
大阪大学副校长Yasushi Yagi:步态分析
http://mp.weixin.qq.com/s/Y-PvMz_Vz8nBGRZo9dwUCA
中科院步态识别技术:不看脸50米内在人群中认出你!
https://mp.weixin.qq.com/s/3Pe5wJ0VomzwKMF84OqcMg
步态识别的深度学习综述
https://mp.weixin.qq.com/s/afX8Y84nTS20q4Y36uOWqQ
复旦提出GaitSet算法,步态识别的重大突破!
花式池化
池化和卷积一样,都是信号采样的一种方式。
普通池化
池化的一般步骤是:选择区域P,令\(Y=f(P)\)。这里的f为池化函数。
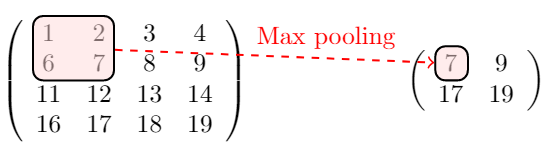
上图是Max Pool的示意图,也就是选择池子里最大的那个值。
除了max之外,常用的池化函数还有:
Min Pool:
\[Y=\min(P)\]Average Pool:
\[Y=\text{mean}(P)\]L2 Pool:
\[Y=\sqrt{\frac{\sum p^2}{n}}\]ICLR2013上,Zeiler提出了另一种pooling手段stochastic pooling。只需对Pooling区域中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大。而不像max-pooling那样,永远只取那个最大值元素。
根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。
Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
池化的反向传播
池化的反向传播比较简单。以上图的Max Pooling为例,由于取的是最大值7,因此,误差只要传递给7所在的神经元即可。
这里再次强调一下,池化只是对信号的下采样。对于图像来说,这种下采样保留了图像的某些特征,因而是有意义的。但对于另外的任务则未必如此。
比如,AlphaGo采用CNN识别棋局,但对棋局来说,下采样显然是没有什么物理意义的,因此,AlphaGo的CNN是没有Pooling的。
Adaptive pool
在实际的项目当中,我们往往预先只知道的是输入数据和输出数据的大小,而不知道核与步长的大小。
Adaptive pool只要我们给定输入数据和输出数据的大小,自适应算法就能够自动帮助我们计算核的大小和每次移动的步长。
标准的Max/AvgPooling是通过kernel_size,stride与padding来计算output_size:
output_size = ceil ( (input_size+2∗padding−kernel_size)/stride)+1
反过来的话,就有如下公式:
stride = floor ( (input_size / (output_size) )
kernel_size = input_size − (output_size−1) * stride
padding = 0
参考:
https://blog.csdn.net/xiaosongshine/article/details/89453037
AdaptivePooling与Max/AvgPooling相互转换
全局平均池化
Global Average Pool是另一类池化操作,一般用于替换FullConnection层。
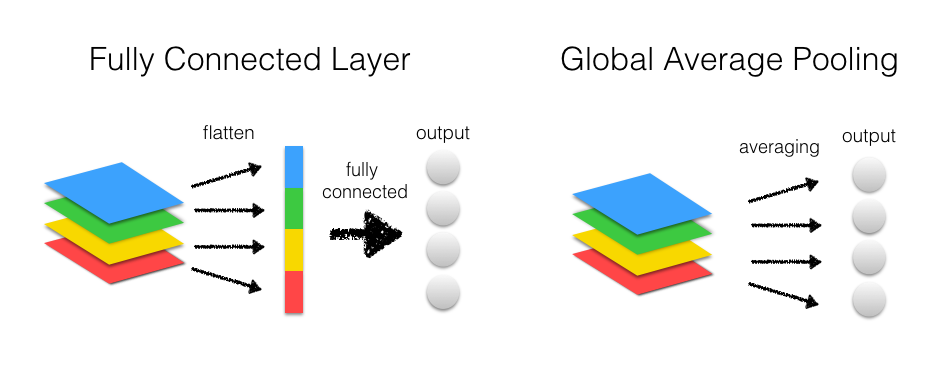
上图是FC和GAP在CNN中的使用方法图。从中可以看出Conv转换成FC,实际上进行了如下操作:
1.对每个通道的feature map进行flatten操作得到一维的tensor。
2.将不同通道的tensor连接成一个大的一维tensor。
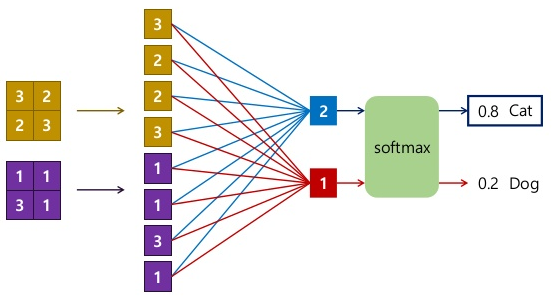
上图展示了FC与Conv、Softmax等层联动时的运算操作。
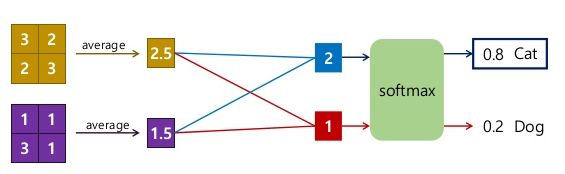
上图是GAP与Conv、Softmax等层联动时的运算操作。可以看出,GAP的实际操作如下:
1.计算每个通道的feature map的均值。
2.将不同通道的均值连接成一个一维tensor。
GAP实际上就是kernel size等于WxH的AP。类似的,还有Global Max Pool。
UnPooling
UnPooling是一种常见的上采样操作。其过程如下图所示:
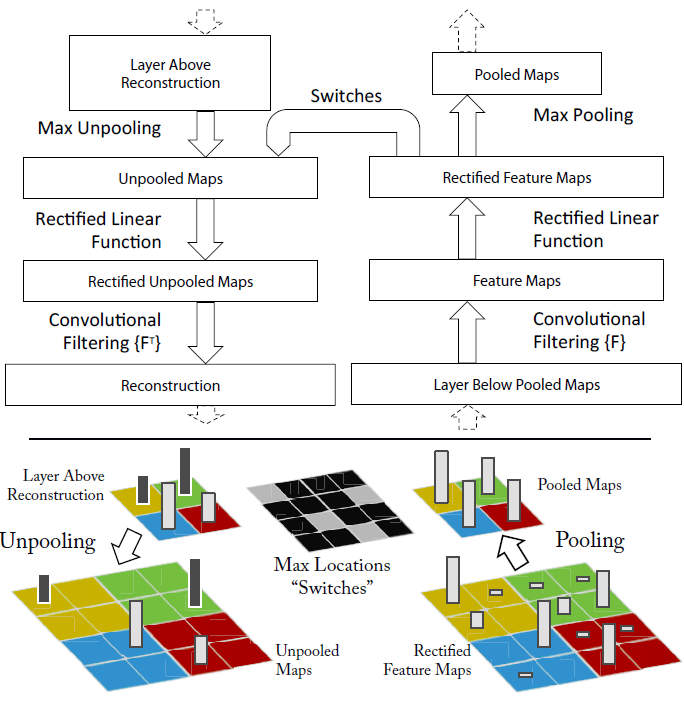
1.在Pooling(一般是Max Pooling)时,保存最大值的位置(Max Location)。
2.中间经历若干网络层的运算。
3.上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
从上面的描述可以看出,UnPooling不完全是Pooling的逆运算:
1.Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作。
2.对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
参考:
http://blog.csdn.net/u012938704/article/details/52831532
caffe反卷积
K-max Pooling
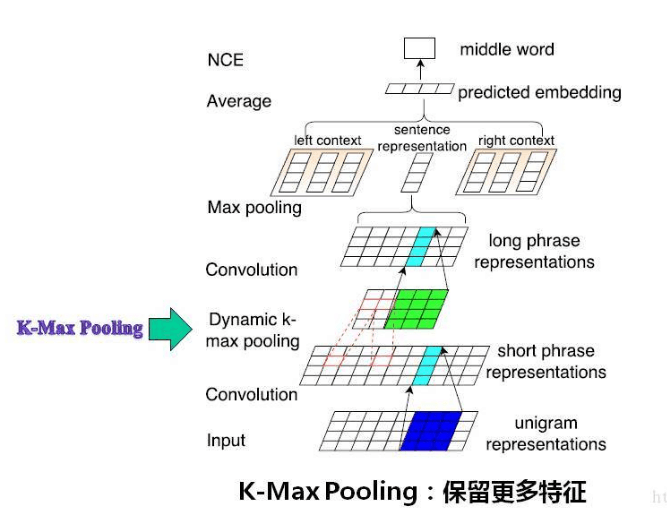
参考
http://www.cnblogs.com/tornadomeet/p/3432093.html
Stochastic Pooling简单理解
http://mp.weixin.qq.com/s/XzOri12hwyOCdI1TgGQV3w
新型池化层sort_pool2d实现更快更好的收敛:表现优于最大池化层
http://blog.csdn.net/liuchonge/article/details/67638232
CNN与句子分类之动态池化方法DCNN–模型介绍篇
https://mp.weixin.qq.com/s/K1RBux3AfxVFT8_uezYHFA
被Hinton,DeepMind和斯坦福嫌弃的池化,到底是什么?
https://mp.weixin.qq.com/s/J4opJ6NvbTxbHWAWNHEltw
自然语言处理中CNN模型几种常见的Max Pooling操作
https://mp.weixin.qq.com/s/KGFsMl3X52_T50h7Bhk65w
CNN一定需要池化层吗?
https://zhuanlan.zhihu.com/p/341820742
深度神经网络中的池化方法:全面调研(1989-2020)
https://mp.weixin.qq.com/s/1Np5KFDR1Wnbwl5Akod13g
SoftPool:基于Softmax加权的池化操作
https://mp.weixin.qq.com/s/86cOSCLWJZBs4vLHGxrjGQ
我看尽了池化

您的打赏,是对我的鼓励
