DL » 深度学习(十一)——花式卷积
2017-08-26 :: 5595 WordsCNN进化史(续)
https://mp.weixin.qq.com/s/MlEGnUPhomQn0oGGEpF9ig
通俗易懂:图解10大CNN网络架构
https://mp.weixin.qq.com/s/acvpHt4zVQPI0H5nHcg3Bw
67页综述深度卷积神经网络架构:从基本组件到结构创新
https://zhuanlan.zhihu.com/p/66215918
CNN系列模型发展简述
https://zhuanlan.zhihu.com/p/68411179
CNN网络结构的发展
花式卷积
在DL中,卷积实际上是一大类计算的总称。除了原始的卷积、反卷积(Deconvolution)之外,还有各种各样的花式卷积。
卷积在CNN和数学领域中的概念差异
首先需要明确一点,CNN中的卷积和反卷积,实际上和数学意义上的卷积、反卷积是有差异的。
数学上的卷积主要用于傅立叶变换,在计算的过程中,有一个时域上的反向操作,并不是简单的向量内积运算。在信号处理领域,卷积主要用作信号的采样。
数学上的反卷积主要作为卷积的逆运算,相当于信号的重建,或者解微分方程。因此,它的难度远远大于卷积运算,常见的有Wiener deconvolution、Richardson–Lucy deconvolution等。
CNN的反卷积就简单多了,它只是误差的反向算法而已。因此,也有人用back convolution, transpose convolution, Fractionally Strided Convolution这样更精确的说法,来描述CNN的误差反向算法。
Deconvolution
在《深度学习(三)》中,我们已经给出了Deconvolution的推导公式,但是并不直观。这里补充说明一下。
![]()
上图是transpose convolution的操作。或者也可以看下图:
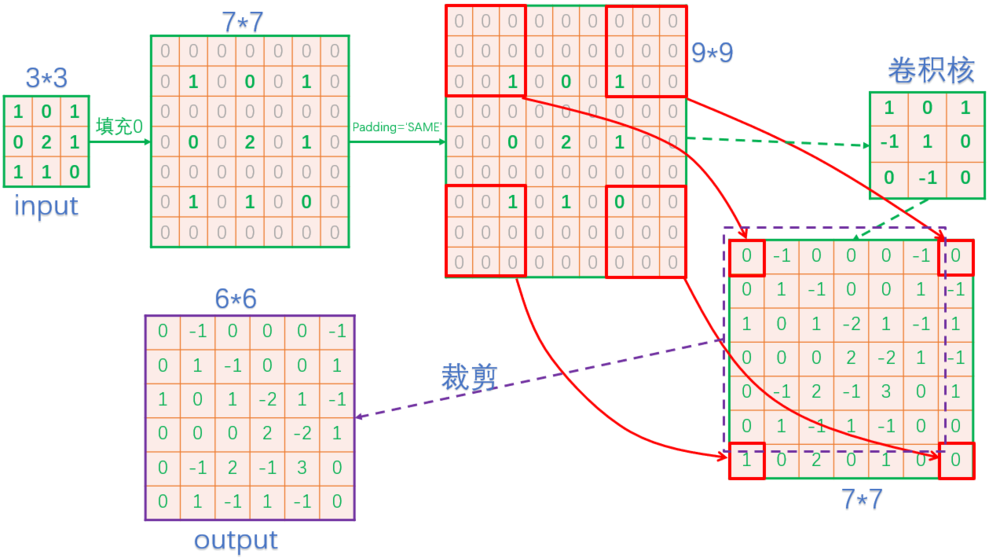
上面的图主要是直观理解。实际计算中,除了使用GEMM之外,更常见的方法不是input padding,而是采用下图的办法:
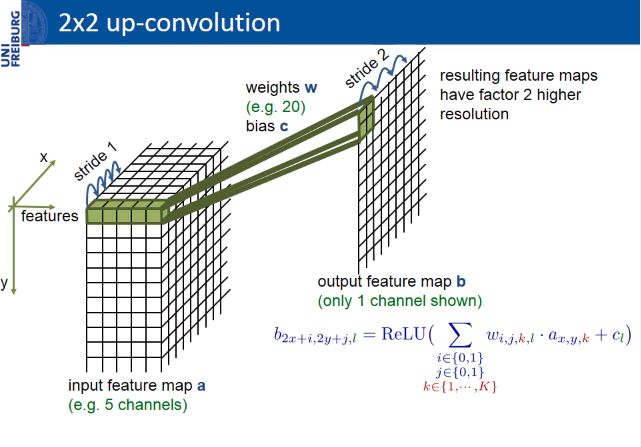
这个方法的步骤如下:
1.kernel padding。把[2, 2, Input, Output]的kernel,pad成[1, 1, Input, Output x 4]。
2.正常的conv运算,得到[W, H, Output x 4]大小的output tensor。
3.使用depth_to_space操作,将output tensor的大小变为[W x 2, H x 2, Output]。
显然,kernel padding只用算一次,且可预计算,因此计算效率上比input padding高得多。
Deconvolution & Image Resize
Deconvolution提供了比普通的Image Resize更丰富的上采样方式。因此,常规的Image Resize操作,实际上都可用Deconvolution来做。这在某些拥有NN硬件加速的设备上是很有用的。
参考:
https://cv-tricks.com/image-segmentation/transpose-convolution-in-tensorflow/
Image Segmentation using deconvolution layer in Tensorflow
https://zhuanlan.zhihu.com/p/32414293
双线性插值的两种实现方法
http://warmspringwinds.github.io/tensorflow/tf-slim/2016/11/22/upsampling-and-image-segmentation-with-tensorflow-and-tf-slim/
Upsampling and Image Segmentation with Tensorflow and TF-Slim
Dilated convolution
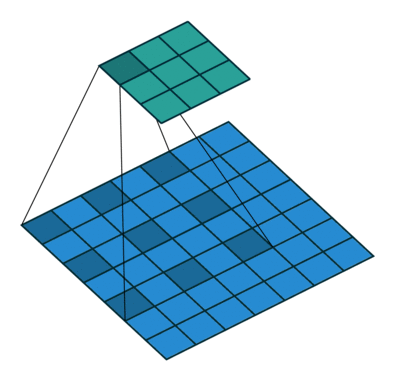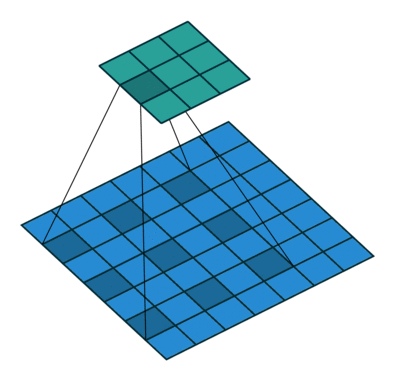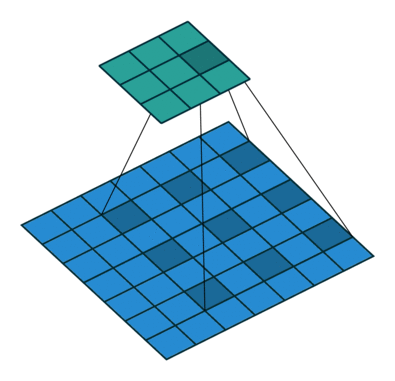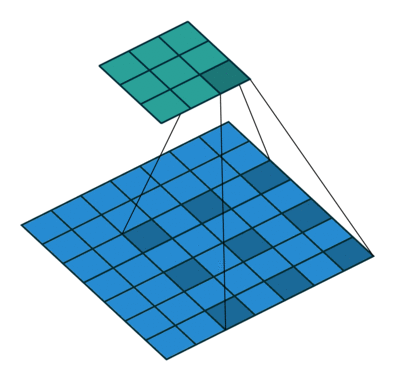
上图是Dilated convolution的操作。又叫做多孔卷积(atrous convolution)。
可以看出,它和Deconvolution的差别在于,前者是kernel上有洞,而后者是Input上有洞。
和池化相比,Dilated convolution实际上也是一种下采样,只不过采样的位置是固定的,因而能够更好的保持空间结构信息。
Dilated convolution在CNN方面的应用主要是Fisher Yu的贡献。
论文:
《Multi-Scale Context Aggregation by Dilated Convolutions》
《Dilated Residual Networks》
代码:
https://github.com/fyu/dilation
https://github.com/fyu/drn
Fisher Yu,密歇根大学本硕+普林斯顿大学博士。
个人主页:
http://www.yf.io/
渣男叫Fisher Yu,原名于夫,前任叫宋舒然,读博期间被老板睡了,跟他分手导致黑化,在ETH任教后年年睡女学生。死者刘伊凡就是受害者,被勾引得离婚+跳槽(连带的学生都不要了),结果一年不到被赶回之前读博任教的澳洲,绝望自杀。
这位宋舒然,显然也是有故事的人。
https://www.zhihu.com/question/621950525
如何看待网传华人助理教授Fisher Yu诱骗PUA阿德莱德女性AP,导致其自杀身亡?
和Deconvolution类似,Dilated convolution也可以采用space_to_batch和batch_to_space操作,将之转换为普通卷积。
参考:
https://zhuanlan.zhihu.com/p/28822428
Paper笔记:Dilated Residual Networks
https://mp.weixin.qq.com/s/1lMlSMS5xKc8k0QMAou45g
重新思考扩张卷积!中科院&深睿提出新型上采样模块JPU
https://mp.weixin.qq.com/s/NjFdu6iP3Sn9GbDhrbpisQ
感受野与分辨率的控制术—空洞卷积
https://zhuanlan.zhihu.com/p/94477174
CNN真的需要下采样(上采样)吗?
分组卷积
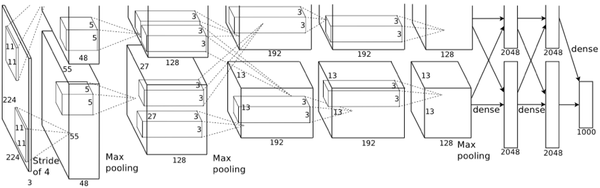
Grouped Convolution最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给2个GPU分别进行处理,最后把2个GPU的结果进行融合。
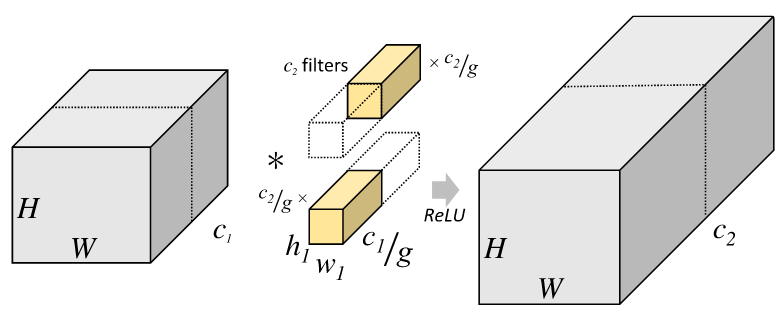
上图是Grouped Convolution的具体运算图:
-
input分成了g组。每组的channel数只有全部的1/g。(上图中g=2)
-
weight和bias也分成了g组。每组weight的input_num和output_num都只有普通卷积的1/g。也就是每组weight的尺寸只有原来的\(1/g^2\),g组weight的总尺寸就是原来的1/g。
-
每组input和相应的weight/bias进行普通的conv运算得到一个结果。g组结果合并在一起得到一个最终结果。
可以看出,Grouped Convolution和普通Convolution的input/output的尺寸是完全一致的,只是运算方式有差异。由于group之间没有数据交换,总的计算量只有普通Convolution的1/g。
在AlexNet的Group Convolution当中,特征的通道被平均分到不同组里面,最后再通过两个全连接层来融合特征,这样一来,就只能在最后时刻才融合不同组之间的特征,对模型的泛化性是相当不利的。
为了解决这个问题,ShuffleNet在每一次层叠这种Group conv层前,都进行一次channel shuffle,shuffle过的通道被分配到不同组当中。进行完一次group conv之后,再一次channel shuffle,然后分到下一层组卷积当中,以此循环。
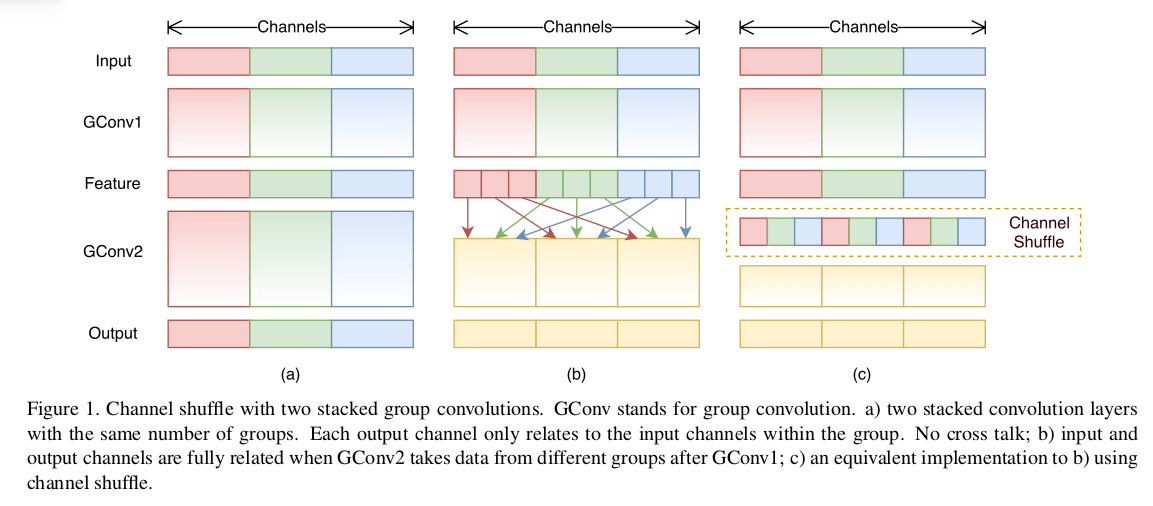
论文:
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
代码:
https://github.com/megvii-model/ShuffleNet-Series
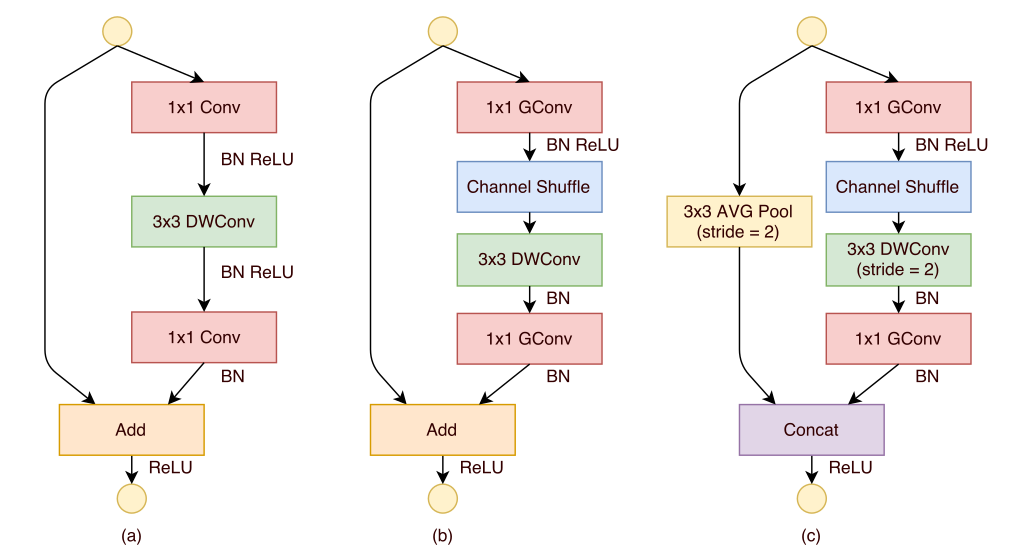
上图是ShuffleNet的Unit结构图,DWConv表示depthwise convolution,GConv表示pointwise group convolution。a是普通的Deep Residual Unit,b的进化用以提高精度,c的进一步进化用以减少计算量。
参考:
https://blog.yani.io/filter-group-tutorial/
A Tutorial on Filter Groups (Grouped Convolution)
https://mp.weixin.qq.com/s/b0dRvkMKSkq6ZPm3liiXxg
旷视科技提出新型卷积网络ShuffleNet,专为移动端设计
https://mp.weixin.qq.com/s/0MvCnm46pgeMGEw-EdNv_w
CNN模型之ShuffleNet
https://mp.weixin.qq.com/s/tceLrEalafgL8R44DZYP9g
旷视科技提出新型轻量架构ShuffleNet V2:从理论复杂度到实用设计准则
https://mp.weixin.qq.com/s/Yhvuog6NZOlVWEZURyqWxA
ShuffleNetV2:轻量级CNN网络中的桂冠
https://mp.weixin.qq.com/s/zLf0aKeMYwqMwC1TymMxgQ
移动端高效网络,卷积拆分和分组的精髓
https://zhuanlan.zhihu.com/p/86095608
Learnable Group Convolutions:可以学习的分组卷积
https://mp.weixin.qq.com/s/liCS3JoRj1scpc0jXFA4-w
分组卷积最新进展,全自动学习的分组有哪些经典模型?
Separable convolution
前面介绍的都是正方形的卷积核,实际上长条形的卷积核也是很常用的。比如可分离卷积。
我们知道卷积的计算量和卷积核的面积成正比。对于k x k的卷积核K来说,计算复杂度就是\(O(k^2)\)。
如果我们能找到1 x k的卷积核H和k x 1的卷积核V,且\(K = V * H\),则称K是可分离的卷积核。
根据卷积运算满足结合律,可得:
\[f * K = f * (V * H) = f * V * H\]这样就将一个k x k的卷积运算,转换成1 x k + k x 1的卷积运算,从而大大节省了参数和计算量。
虽然,并不是所有的卷积核都满足可分离条件。但是深度网络本来也不需要每一层都能精确表示。
1x1卷积
1、升维或降维。
如果卷积的输出输入都只是一个平面,那么1x1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。 但卷积的输出输入是长方体,所以1x1卷积实际上是对每个像素点,在不同的channels上进行线性组合(信息整合),且保留了图片的原有平面结构,调控depth,从而完成升维或降维的功能。
![]()
2、加入非线性。卷积层之后经过激励层,1x1的卷积在前一层的学习表示上添加了非线性激励(non-linear activation),提升网络的表达能力;
3.促进不同通道之间的信息交换。
参考:
https://www.zhihu.com/question/56024942
卷积神经网络中用1x1卷积有什么作用或者好处呢?
depthwise separable convolution
在传统的卷积网络中,卷积层会同时寻找跨空间和跨深度的相关性。
然而Xception指出:跨通道的相关性和空间相关性是完全可分离的,最好不要联合映射它们。
Xception是Francois Chollet于2016年提出的。
Francois Chollet,法国人。现为Google研究员。Keras的作者。
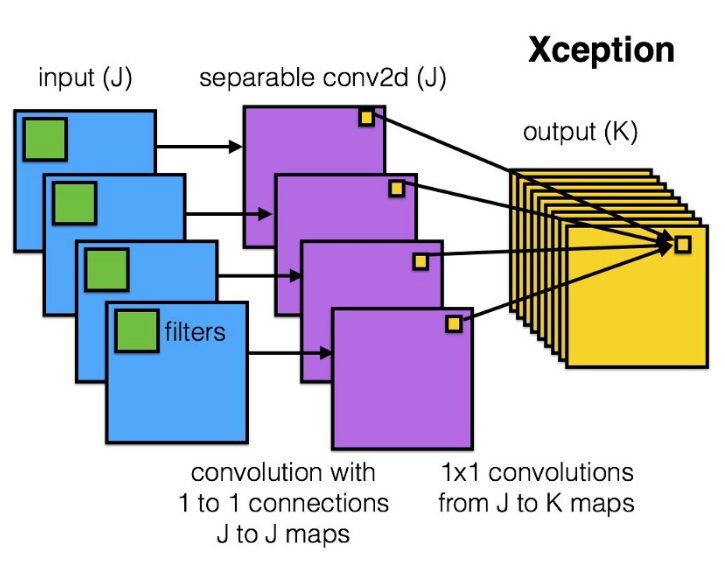
上图是Xception中的卷积运算depthwise separable convolution的示意图。
它包含一个深度方面的卷积(一个为每个通道单独执行的空间卷积,depthwise convolution),后面跟着一个逐点的卷积(一个跨通道的1×1卷积,pointwise convolution)。我们可以将其看作是首先求跨一个2D空间的相关性,然后再求跨一个1D空间的相关性。可以看出,这种2D+1D映射学起来比全 3D 映射更加简单。
在ImageNet数据集上,Xception的表现稍稍优于Inception v3,而且在一个有17000类的更大规模的图像分类数据集上的表现更是好得多。而它的模型参数的数量仅和Inception一样多。

您的打赏,是对我的鼓励
