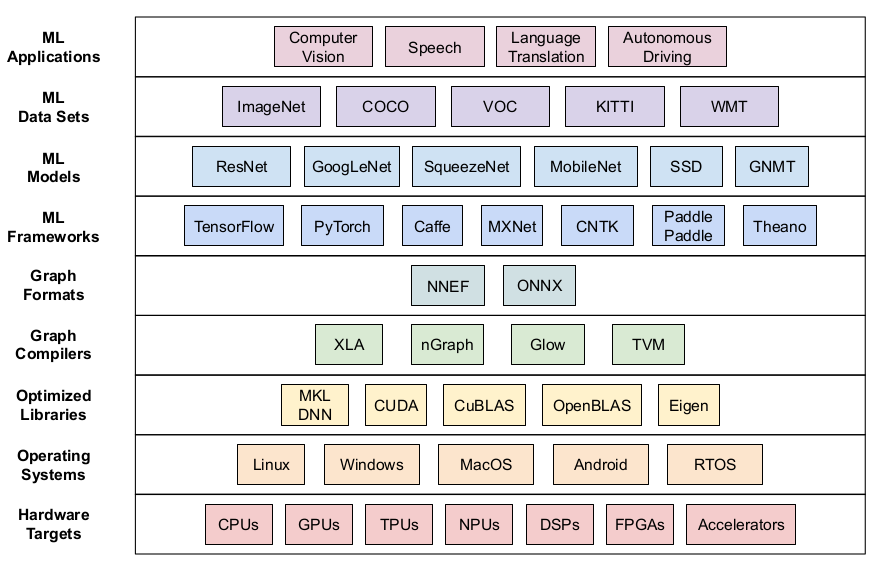
DL Framework » MLPerf, 移动端推理框架, DL Backend, DRL实战
2019-06-30 :: 6673 WordsMLPerf
MLPerf是谷歌、百度、斯坦福等联手打造的基准测量工具,用于测量机器学习软件与硬件的执行速度。
它的到来代表着原本市场规模较为有限的AI性能比较方案正式踏上发展正轨。简而言之就是:以后各大公司发布的AI性能对比不能再王婆卖瓜自卖自夸了。
官网:
https://mlperf.org/
论文:
《MLPerf Inference Benchmark》
2022.7
官网改名为:
https://mlcommons.org
https://github.com/mlcommons
参考:
https://www.nvidia.com/en-us/data-center/resources/mlperf-benchmarks/
MLPerf Benchmarks
移动端推理框架
最知名的移动端推理框架毫无疑问是Google的Tensorflow Lite和Android NN。这两个框架在本blog的Tensorflow章节已有描述。
TensorRT亦有专门章节描述。
SNPE
Snapdragon Neural Processing Engine SDK是Qualcomm推出的NN加速包。
官网:
https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
和它配套的还有Qualcomm Math Library。
https://developer.qualcomm.com/software/qualcomm-math-library
NCNN
NCNN是腾讯的作品。
代码:
https://github.com/Tencent/ncnn
TNN
TNN是腾讯2020.6推出的作品。
代码:
https://github.com/Tencent/TNN
参考:
https://mp.weixin.qq.com/s/6V5ccGLAGcKwM3pi1nonZQ
腾讯优图移动端推理框架TNN开源啦!
https://mp.weixin.qq.com/s/31gFtdMqfv-IfmHAuAXTvg
深度学习推理引擎:MNN pk TNN
MACE
MACE是小米的作品。
代码:
https://github.com/XiaoMi/mace
XNNPACK
XNNPACK是Google开发的一个高性能、低级别的深度学习推理库,专注于手机和嵌入式设备上的神经网络运算。它充分利用了现代移动处理器的向量指令集,如ARM NEON和Intel AVX。
代码:
https://github.com/google/XNNPACK
百度系
百度的Inference-engine以多变且不兼容著称。
2017年9月底,baidu发布移动端深度学习框架mobile-deep-learning(MDL)。
2018年5月底,baidu发布跨平台AI推理加速引擎anakin。
2018年5月底,baidu移动端深度学习框架完全重构为paddle-mobile。
2018年8月,baidu为ARM移动端开发精简版anakin引擎anakin-lite。
2019年8月中,baidu发布纯自研的移动端框架paddle-lite。
MNN
MNN是阿里的作品。
代码:
https://github.com/alibaba/MNN
参考:
https://mp.weixin.qq.com/s/yDvTDTk8VtGZjA3RK4dLMQ
阿里巴巴开源轻量级深度神经网络推理引擎MNN
https://mp.weixin.qq.com/s/EcwmGKpCfVy22BWTB0Ro2g
淘宝开源深度学习推理引擎MNN,移动AI的挑战与应对全面解读
https://mp.weixin.qq.com/s/1ynCqcFJTmxeo8lwKVm-XA
谈谈MNN GPU性能优化策略
DL Backend
DL Backend是框架和硬件驱动之间的一层软件,用于向上提供AI硬件加速的能力。在AI芯片层出不穷的当下,相应的DL Backend也同样丰富。
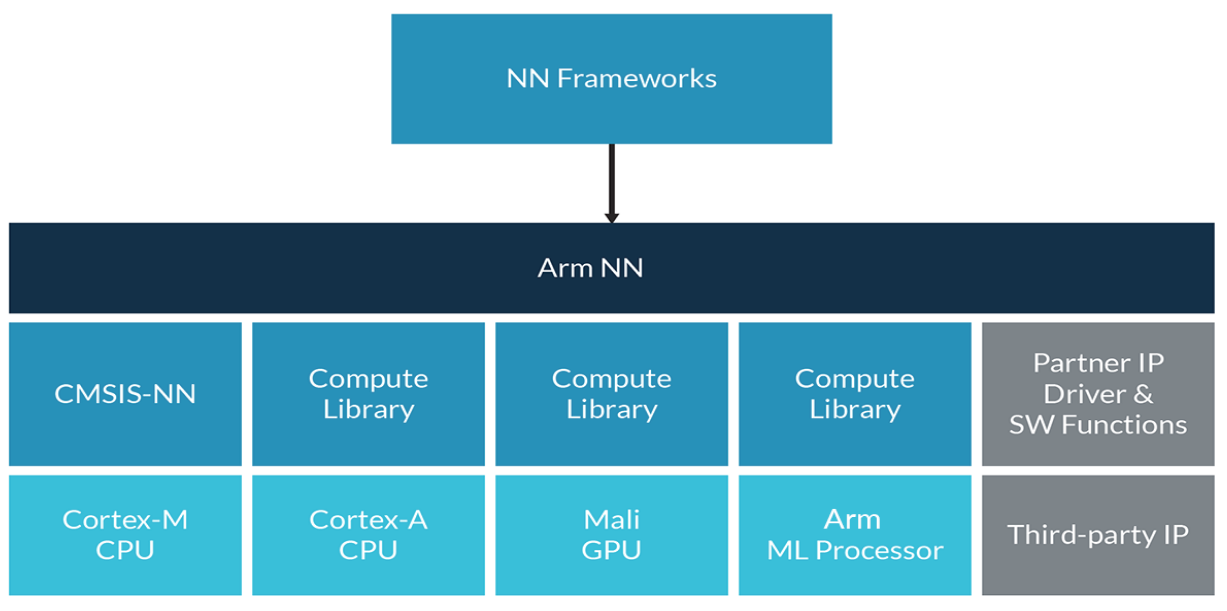
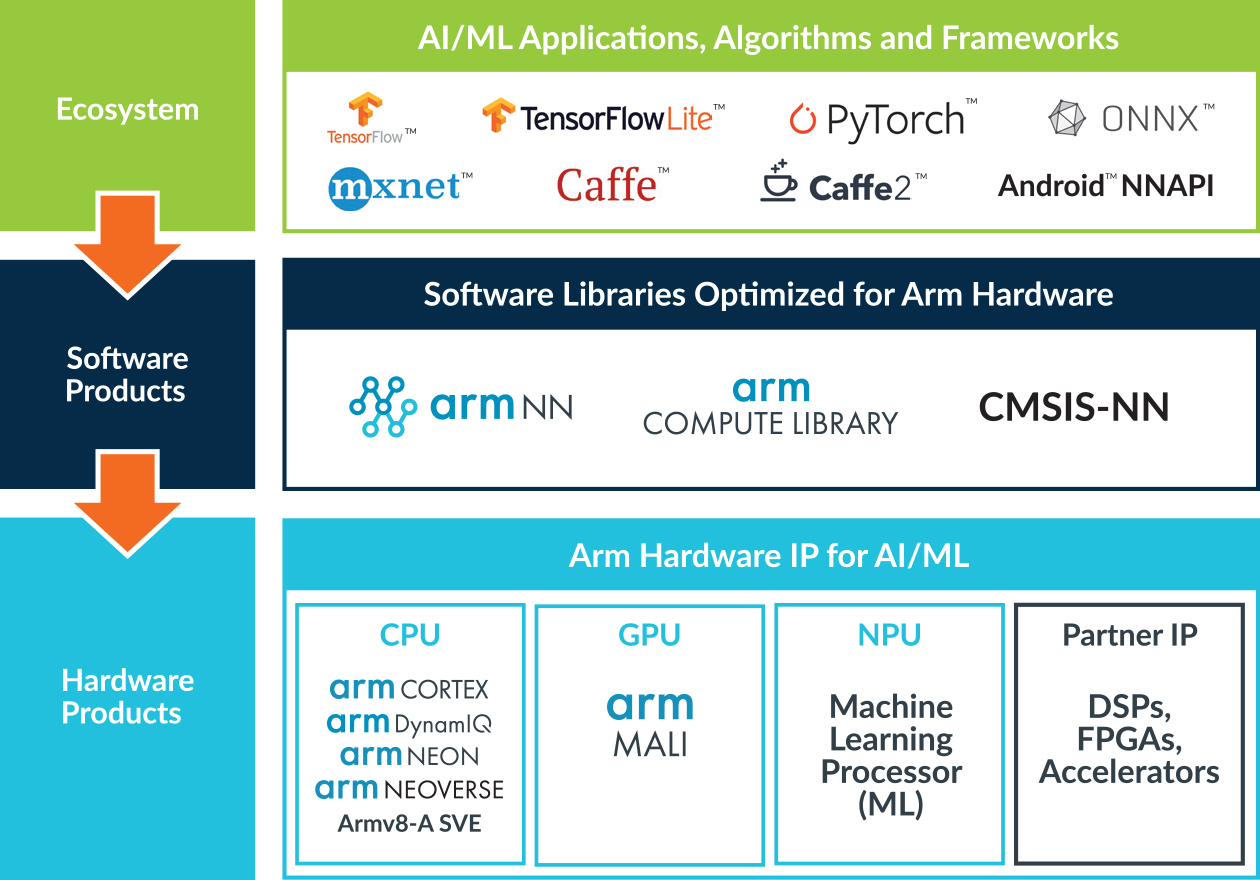
Arm ML
Arm ML是Arm的作品。它包括了两部分:Arm NN和Arm Compute Library。
官网:
https://mlplatform.org/
Arm NN
官网:
https://developer.arm.com/ip-products/processors/machine-learning/arm-nn
代码:
https://github.com/Arm-software/armnn
Arm Compute Library
官网:
https://developer.arm.com/ip-products/processors/machine-learning/compute-library
代码:
https://github.com/ARM-software/ComputeLibrary
CMSIS NN
CMSIS NN是ARM提供的一个针对Cortex-M CPU的NN计算库。
论文:
《CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs》
官网:
http://www.keil.com/pack/doc/CMSIS_Dev/NN/html/index.html
代码:
https://github.com/ARM-software/CMSIS_5
概述
其他
https://www.veryarm.com/872.html
armel、armhf和arm64区别选择
Intel
和ARM类似,Intel的方案包括了高层库nGraph和低层库DNNL。
nGraph
nGraph是Intel推出的一款能兼容所有框架的深度神经网络(DNN)模型编译器,可用于多种硬件设备(其实主要还是Intel家的硬件)。
官网:
https://ngraph.nervanasys.com/docs/latest/
参考:
https://www.zhihu.com/question/269332944
如何评价英特尔开源的nGraph编译器?
MKL
Intel Math Kernel Library是一套经过高度优化和广泛线程化的数学例程,专为需要极致性能的科学、工程及金融等领域的应用而设计。
官网:
https://software.intel.com/zh-cn/mkl
针对DNN加速,Intel推出了MKL-DNN库,后改名DNNL,又改名oneDNN。
官网:
https://github.com/intel/mkl-dnn
参考:
https://zhuanlan.zhihu.com/p/483936837
深入了解英特尔深度学习编译器-GraphCompiler
MS
MS也是一样:高层库WinML+中层库ONNX Runtime+低层库DirectML。
ONNX Runtime
官网:
https://microsoft.github.io/onnxruntime/
代码:
https://github.com/microsoft/onnxruntime
build + run test:
./build.sh --config RelWithDebInfo --build_shared_lib --parallel --cmake_path /home/ubuser/my/setup/cmake-3.16.4-Linux-x86_64/bin/cmake
build only:
./build.sh --config RelWithDebInfo --build_shared_lib --parallel --cmake_path /home/ubuser/my/setup/cmake-3.16.4-Linux-x86_64/bin/cmake --skip_tests
test:
cd onnxruntime/build/Linux/RelWithDebInfo
/home/ubuser/my/opensource/onnxruntime/build/Linux/RelWithDebInfo/onnxruntime_test_all --gtest_output=xml:/home/ubuser/my/opensource/onnxruntime/build/Linux/RelWithDebInfo/onnxruntime_test_all.RelWithDebInfo.results.xml --gtest_filter=ActivationOpTest.Relu
log:
LOGS_DEFAULT(WARNING) << "Hello!";
performance test:
onnxruntime_perf_test -m times -r 3 -e cpu model.onnx ./result.txt
backend的代码在onnxruntime/core/providers下。
其中,openvino的fused graph代理是写的比较好的。关键函数有:
GetUnsupportedNodeIndices:上报op是否支持。
GetPartitionedClusters:根据支持列表分割计算图
AppendClusterToSubGraph:将切割好的图打包发给backend。
ORT model format是ONNX Runtime提出的一种压缩模型格式。
https://onnxruntime.ai/docs/performance/model-optimizations/ort-format-models.html
ORT model format
onnxruntime-genai是onnxruntime针对LLM的扩展。
代码:
https://github.com/microsoft/onnxruntime-genai
DirectML
基于DirectX 12提出的加速方案。
GLOW
代码:
https://github.com/pytorch/glow
参考:
https://zhuanlan.zhihu.com/p/102127047
Glow: Graph Lowering Compiler for Neural Networks
NNFusion
代码:
https://github.com/microsoft/nnfusion
参考:
https://mp.weixin.qq.com/s/CMTOW3cYQkkECpPuzZl0nQ
RAMMER如何进一步“压榨”加速器性能
DRL实战
FlappyBird
Flappy Bird的action只有两种:动/不动,算是非常简单的游戏了。正好可以作为DQN的入门教程。
参考代码:
https://github.com/floodsung/DRL-FlappyBird
这个代码参考了:
https://github.com/yenchenlin/DeepLearningFlappyBird
Flappy Bird的python版本基于pygame,代码:
https://github.com/sourabhv/FlapPyBird
安装:
pip3 install opencv-python pygame tensorflow
实战心得:
- 奖励的设计:
通过柱子成功:+1
死亡:-1
活着,但未通过柱子:+0.1
这个游戏每50个time step通过一根柱子,也就是说,每50个time step才有一次大的奖励(无论正负)。
-
开始的时候,由于Agent没有什么经验,所以INITIAL_EPSILON不能太小。然而这个游戏和下棋不一样,下棋的每一步都有差不多的奖励,而这个游戏,多数的时间只是在飞而已,也就是说大奖励是很稀疏的。所以,INITIAL_EPSILON也不能太大,随机运动未必收敛最快。因此,INITIAL_EPSILON设置为0.5似乎是个不错的选择。(纯经验之谈)
-
为了快速收敛,忽略其他无关要素,例如把背景换成纯黑色、不显示得分等。图片的处理过程中,采用了二值化的方法,将彩色图片转换为黑白图片,以便于后面的机器学习。
-
REPLAY_MEMORY是一个实用的DQN技巧,但在教程中往往被忽略。它可用来消除训练数据间的相关性。
-
作者创建两个Q网络,以及交换权值的代码,非常优雅。(copyTargetQNetworkOperation)
实战效果:
-
训练5W个time step:有60%的概率能通过第1根柱子。
-
训练40W个time step:平均能通过10根柱子。
-
训练140W个time step:平均能通过100根柱子。
-
为了验证模型的泛化性能,我将两根之间柱子的横向间隔随机化,性能立马掉到10根柱子的水平,但继续训练之后,性能提升速度比原先快的多。
如果嫌原始代码太大的话(140MB+),也可以下载本人的魔改版本:
https://github.com/antkillerfarm/antkillerfarm_crazy/tree/master/python/ml/RL/DRL-FlappyBird
参考:
http://blog.csdn.net/songrotek/article/details/50951537
用Tensorflow基于DQN玩Flappy Bird
https://zhuanlan.zhihu.com/p/21434933
DQN实战篇 从零开始安装Ubuntu, Cuda, Cudnn, Tensorflow, OpenAI Gym
https://zhuanlan.zhihu.com/p/21477488
150行代码实现DQN算法玩CartPole。这是参考代码的作者本人写的另一个blog,其中的框架部分沿用到了Flappy Bird上。
https://mp.weixin.qq.com/s/nmqX05c2qS3Jeg66W5NOzA
尝试用强化学习算法来玩下FlappyBird?这篇blog只用Q-Learning算法,而不是DQN来玩FlappyBird。
CartPole
这是Google官方的教程,使用的是A3C算法:
https://github.com/tensorflow/models/tree/master/research/a3c_blogpost
安装依赖:
pip3 install gym pyglet tensorflow matplotlib
首先是训练:
python3 ./a3c_cartpole.py --train
这里用的是Gym环境,不需要渲染游戏画面,而直接就可以训练。这个的训练速度很快,即使CPU也就是十分钟的事情。
展示效果:
python3 ./a3c_cartpole.py
果然稳如狗。。。
参考:
https://mp.weixin.qq.com/s/atQHJ5U2pJpSG6PguN7J4Q
如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏

您的打赏,是对我的鼓励
