DL Framework » Tensor2Tensor, MXNet, DL框架怀古
2018-09-20 :: 5864 WordsTensor2Tensor
T2T库利用TensorFlow工具来开发,定义了一个深度学习系统中需要的多个部分:数据集、模型架构、优化工具、学习速率衰减计划,以及超参数等等。
最重要的是,T2T在所有这些部分之间实现了标准接口,并配置了当前机器学习的最佳行为方式。
因此,你可以选择任意数据集、模型、优化工具,以及一套超参数,随后运行训练,看看效果如何。
论文:
《Tensor2Tensor for Neural Machine Translation》
代码:
https://github.com/tensorflow/tensor2tensor
参考:
https://cloud.tencent.com/developer/article/1153079
“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统
这篇blog不仅对Tensor2Tensor的基本结构做了介绍,也对transformer模型进行了介绍。transformer模型的详解参见《Attention(二)》。
mesh tensorflow
T2T不仅支持单机,还支持网格(Mesh)计算,推出了所谓的mesh tensorflow,简称MTF。
参考
https://blog.csdn.net/hpulfc/article/details/81172498
如何使用tensor2tensor自定义数据并训练模型
https://blog.csdn.net/hpulfc/article/details/82625217
tensor2tensor自定义问题,训练模型(bpe篇)
https://mp.weixin.qq.com/s/YRDZ8inqaxmdD5g_SR1MLg
四种常见NLP框架使用总结
Tensor2Tensor transformer实战
准备数据
tensor2tensor/data_generators/translate_enzh.py
这个脚本包含了很多数据集的下载地址。
我们这里使用的是官方提供英汉翻译数据集:
http://data.statmt.org/wmt18/translation-task/training-parallel-nc-v13.tgz
这个数据集中,中英文是分开的:
training-parallel-nc-v13/news-commentary-v13.zh-en.en
training-parallel-nc-v13/news-commentary-v13.zh-en.zh
上面是训练集,测试集也是类似的。
数据预处理
这个过程比较漫长,大约1小时左右,期间CPU全满,而GPU全空,一度让我以为我的GPU相关配置不对。
数据预处理主要完成如下数据转换:
token(文字)->id(词典中的index)
它主要由T2T中的Problem模块进行配置。
例如,英汉翻译的设置一般为:--problem=translate_enzh_wmt32k。
Problem可以是一条继承链,比如上例中的继承链为:
TranslateEnzhWmt32k->TranslateProblem->Text2TextProblem->Problem
Problem类是所有Problem的基类。
由于中文符号表中,不仅有字还有词,让我一度以为使用了什么分词工具,后来才发现只是简单的词频统计相关的处理而已。相关代码在:
tensor2tensor/data_generators/text_encoder.py:SubwordTextEncoder.build_from_token_counts
T2T默认使用谷歌内部的subword分词法。这个分词法还有个独立的入口在:
tensor2tensor/data_generators/text_encoder_build_subword.py
除此之外,网上也有人使用Byte Pair Encoding(BPE)分词法进行分词。
tensor2tensor/layers/common_layers.py:embedding
导入词向量:
transformer模型的input/output都是单词在词典中的index,需要通过查询词向量表,将其替换为词向量。
tensor2tensor/layers/modalities.py:SymbolModality
encoder导入:input_emb
decoder导入:target_emb
模型
transformer模型定义文件如下:
tensor2tensor/models/transformer.py
这里我采用的是transformer_base_single_gpu的超参,loss可降至0.4左右。如果采用transformer_base的话,就只能降到2.0左右。
num_encoder_layers/num_decoder_layers控制transformer的层数,如果为0,就使用num_hidden_layers的值。
位置信息的函数:
get_timing_signal_1d
MXNet
https://mp.weixin.qq.com/s/50uGupiwU2UVuVeMm_bTag
李沐介绍MXNet新接口Gluon:高效支持命令式与符号式编程
https://mp.weixin.qq.com/s/VRmhAluhKWxyPbStmMoWtg
一张速查表实现Apache MXNet深度学习框架五大特征的开发利用
http://zh.gluon.ai/index.html
李沐:《动手学深度学习》(使用Gluon)
https://zhuanlan.zhihu.com/p/30966663
用Gluon炼丹体验
https://mp.weixin.qq.com/s/B8TYVG5WjDJ4NX-wirS2Fg
Alex Smola:深度学习触手可及,架构Gluon高中生就能用
https://mp.weixin.qq.com/s/wdDYUOLpi0l2mRirQhHjPQ
Apache MXNet助力数字营销,检测社交网络照片中的商标品牌
http://mp.weixin.qq.com/s/Z5X7Vamuw1BwtienhOrSvQ
解构TensorFlow, 学习MXNet–新一代深度学习系统的核心思想
https://mp.weixin.qq.com/s/_PAzff6V9UgwLCos05B4rg
十分钟从PyTorch转MXNet
https://mp.weixin.qq.com/s/2ulMPGEHYkOqWhT2XY449w
TensorFlow、MXNet、PaddlePaddle三个开源库对比
https://mp.weixin.qq.com/s/-BlBm3ZTZ32ijORJux7rTA
DMLC团队发布GluonCV和GluonNLP:两种简单易用的DL工具箱
https://mp.weixin.qq.com/s/Vb-7hGw7UOx4jP3lwW3Leg
从VGG到ResNet,你想要的MXNet预训练模型轻松学
https://mp.weixin.qq.com/s/CgxrvNfyu35SMvWBAt-5kg
MXNet开放支持Keras,高效实现CNN与RNN的分布式训练
https://mp.weixin.qq.com/s/qLax1Jb0OOfFOU68wn_2PA
从三大神经网络,测试对比TensorFlow、MXNet、CNTK、Theano四个框架
https://mp.weixin.qq.com/s/hRH7hVsaQBqf0vhD_BqBgg
五大深度学习框架三类神经网络全面测评
https://zhuanlan.zhihu.com/p/42345854
如何基于gluon训练一个强有力的Reid Baseline
DMLC
Distributed (Deep) Machine Learning Community是陈天奇发起的一个社区。
它的核心库,被称为dmlc-core。目前已被TVM、MXNet等项目所采用。
代码:
https://github.com/dmlc/dmlc-core
DL框架怀古
2017.9
http://deeplearning.net/
这个网站是Theano的主站,也是我最早接触DL时浏览的网站。其时,我虽然对DL有浓厚的兴趣,但尚未以此作为工作内容。
从该网站提供的招聘信息来看,Caffe、Theano、Torch是当时主流的三大框架库。
岂料时隔一年半载之后,这三大框架都渐趋式微。
Caffe被Caffe 2替代,但使用的广泛度仍超过后者。
Theano被同样基于计算图的TensorFlow淘汰。2017年9月停止更新。
Torch相对变动最小,它被PyTorch替代。这更可以看作是python对于lua的胜利。
2020.12
又是三年过去了。
生命力超强的Caffe终于过气了,大约从2019年下半年开始,即使是新入行的客户,也没人用它了。但是Caffe 2从来没火过。不知道是Caffe 2不行,让贾扬清去阿里,还是贾扬清去阿里了,导致的Caffe 2被放弃。
遗弃列表还有CNTK和Chainer。
mxnet一直半死不活,虽然李沐并未放弃,但是手下已经有些离开的了。
倒是国内,一堆原先私有的框架,纷纷开源。比如清华Jittor,旷视MegEngine,华为Mindspore在2020.3扎堆开源。但是根本溅不起丝毫的水花。你不开源,是自己用;你开源了,还是自己用。反正我是没兴趣用。
参考:
https://www.zhihu.com/question/392035070
如何看待亚马逊AI李沐团队大批人员离职?
https://zhuanlan.zhihu.com/p/121834310
深度学习框架的灵魂
https://mp.weixin.qq.com/s/DxV7mm7xCXWFy_KTIDh_-Q
深度学习框架简史:TF和PyTorch双头垄断
https://mp.weixin.qq.com/s/_-z2d1GE_3FElzAwPyJZ8A
十大流行AI框架和库的优缺点比较
https://mp.weixin.qq.com/s/gWdeevVYctxjDDw9SOWe_Q
PyTorch深度学习技术生态
Jittor
https://mp.weixin.qq.com/s/ZwP1H-efHK1dp2X2ElEs8g
清华开源Jittor:首个国内高校自研深度学习框架,一键转换PyTorch
chainer
chainer是一个日本公司Preferred Networks写的基于python的深度学习框架。
官网:
https://chainer.org/
代码:
https://github.com/chainer/chainer
Preferred Networks是日本目前最强的AI创业公司,估值已经超过20亿美元。在工业机器人领域具有很强的实力。
它推出的PaintsChainer是一个给黑白线稿上色的App。
官网:
https://github.com/pfnet/PaintsChainer
MegEngine
MegEngine是旷视提出的深度学习框架。
官网:
https://megengine.org.cn/
X-Deep Learning
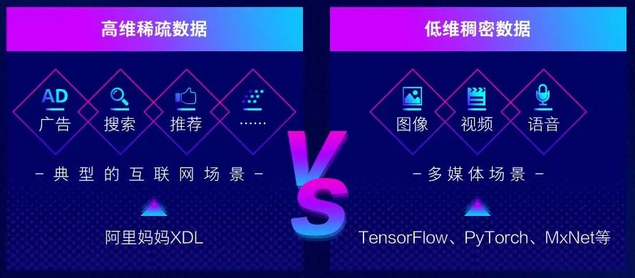
TensorFlow、MXNet、PyTorch等框架大都是面向图像、语音等领域的稠密数据设计,对广告、推荐等场景的高维稀疏数据上的深度学习计算考虑不足。
为此,阿里妈妈启动了XDL框架的研发,希望能够在复用已有开源框架对稠密数据的计算能力基础上,重点打造面向工业级应用的分布式规模能力。
参考:
https://mp.weixin.qq.com/s/kdCk_twY_czQo58y3x_yyA
阿里深度学习框架开源了!无缝对接TensorFlow、PyTorch
Git+
参考
https://mp.weixin.qq.com/s/z_zFveiiLu9vLvWuBcsaIg
Git从入门到进阶
https://mp.weixin.qq.com/s/0Cv968LpSSYKJpAbW1MlMA
手把手教你git全操作
https://mp.weixin.qq.com/s/DbvRbaH7BJKeTCT4LVXUoA
Git的4个阶段的撤销更改
https://mp.weixin.qq.com/s/nUqvSnnPjYqk2O8u0tQEtQ
Git内部原理揭秘
https://mp.weixin.qq.com/s/nmi1HYkKD8QX0phbvOko2Q
Git居然还有这么高级用法,你一定需要
https://mp.weixin.qq.com/s/PUUL913fig6cFfqy4OKcGA
工作流一目了然,看小姐姐用动图展示10大Git命令
https://blog.csdn.net/mocoe/article/details/84344411
修改git commit的author信息
https://mp.weixin.qq.com/s/9Ey04P5Xv4W95N2FEioZ1g
如何选择Git分支模式?
https://mp.weixin.qq.com/s/GZkGfwrfMTzrMfki8LKbIw
腾讯广告3000+万行大代码库主干开发实战
https://mp.weixin.qq.com/s/KEu6qCl-En6HiKGo2pgEQg
TensorBay:一款易用的像Git一样数据版本管理工具!
https://6xyun.cn/article/191
Repo报错 No module named ‘formatter’

您的打赏,是对我的鼓励
