DL Framework » Caffe, darknet
2017-08-22 :: 6633 WordsCaffe
Convolutional Architecture for Fast Feature Embedding是贾扬清写的一个深度学习框架。
贾扬清,清华的本硕(2009)+UCB的博士(2014)。先后在Google和Facebook任研究员。知乎名人。
个人主页:
http://daggerfs.com/
官网:
http://caffe.berkeleyvision.org/
代码:
https://github.com/BVLC/caffe
API:
http://caffe.berkeleyvision.org/doxygen/index.html
安装
Ubuntu 17.04以后:
sudo apt install caffe-cpu
sudo apt install caffe-cuda
不过由于DL进展比较快,自定义Layer的需求也是相当广泛,因此有必要掌握源代码编译的方法。
sudo apt install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt install --no-install-recommends libboost-all-dev
虽然Caffe支持CMake Build,但是定制化没有Make Build方便,所以我选择后者。
cp Makefile.config.example Makefile.config
make all -j 8
make test -j 8
make runtest -j 8
这里会遇到fatal error: hdf5.h的问题,解决办法:
Makefile.config文件的第90行:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
改为:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/
Makefile文件的第180行:
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5
改为:
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial
pycaffe
编译:
make pycaffe
安装:
export PYTHONPATH=/path/to/caffe/python:$PYTHONPATH
测试:
import caffe
运行方式
Caffe有两种运行方式:
1.编程式。这种模式也是TensorFlow采用的方式,即直接在main函数中调用Caffe函数。
示例:
examples/cpp_classification/classification.cpp
2.命令行式。这种模式适合于流程比较简单的情况。使用caffe工具加载模板文件进行训练或预测。
示例:
examples/mnist/train_lenet.sh
入门示例
照例,还是MNIST。
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.sh
./examples/mnist/train_lenet.sh
默认使用GPU,如果要用CPU的话,可修改lenet_solver.prototxt:
solver_mode: CPU
文件存储
prototxt:模板文件。定义NN中的层之类的结构。
从阅读习惯上,我们浏览一个NN结构,通常是从input到output。prototxt文件的组织也采用了这样的顺序。然而和通常描述访问关系的顺序(从上到下)不同,Caffe认为Layer的input是bottom,而output是top。
复杂网络的prototxt往往不止一个:
1.Solver。用于设置训练时的参数。
2.Train。用于描述训练时的网络结构。
3.Deploy。用于描述部署时的网络结构。
caffemodel:模型文件。训练好的模型可以放在模型文件中,以便于今后的预测。模型文件采用protobuf格式保存。其结构由模板文件负责描述。
除了模板文件和模型文件之外,有的时候训练样本也需要打包存储成dataset文件,以防止小文件过多导致的IO速度问题。
Caffe生成的dataset文件分为2种格式:Lmdb和Leveldb。它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。
参考:
http://www.cnblogs.com/yymn/p/4479216.html
Caffe1——Mnist数据集创建lmdb或leveldb类型的数据
https://github.com/BVLC/caffe/wiki/Model-Zoo
Caffe官网上有个Model Zoo,可从中获得一些经典模型的模板文件和模型文件。
https://github.com/soeaver/caffe-model
另一个网友版Model Zoo
http://www.cnblogs.com/hansjorn/p/4816059.html
Caffe模型读取
https://github.com/shicai/Caffe_Manual
Caffe使用教程
https://www.zhihu.com/question/37082410
用c++怎么去调用你训练好的caffe模型啊?
http://www.cnblogs.com/denny402/p/5111018.html
用训练好的caffemodel来进行分类
prototxt文件的可视化
1.使用在线工具netscope。
https://ethereon.github.io/netscope/quickstart.html
2.使用自带draw_net.py脚本。
参考:
http://www.cnblogs.com/zjutzz/p/5955218.html
caffe绘制网络结构图
http://yanglei.me/gen_proto/
另一个在线工具。
术语
blob
Caffe中用于数据操作和交换的数据结构。简单来说,就是一个4维数组,格式如下表所示:
| Name | tensor format | channel order | format |
|---|---|---|---|
| Caffe | number,channel,height,width | BGR | BBBGGGRRR |
| TensorFlow | number,height,width,channel | RGB | RGBRGBRGB |
| Darknet | number,channel,height,width | RGB | RRRGGGBBB |
| OpenVX | width,height,channel,number | ||
| OpenCV | height,width,channel | BGR | |
| PIL | height,width,channel | RGB |
在API层面,Caffe和OpenVX顺序完全相反,但是由于OpenVX是列优先存储,因此在内存存储方面,两者的格式正好完全一致。详见《多维数组的行优先和列优先》一节。
lr_mult
学习率因子。基数是solver在运行时采用的学习率。
decay_mult
衰减因子。基数含义同上。
lr_mult参数和decay_mult参数的存在,允许不同的层有不同的学习率或衰减率。
在一个卷积层中,通常会有2组lr_mult参数和decay_mult参数,其中前一组是weight参数的学习率或衰减率,而后一组是bias参数的。
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
上面这组参数被实践证明,是比较work的参数。
flatten
将n * c * h * w的blob,转换成n * (c * h * w)的结构。
crop
Crop层的输入(bottom blobs)有两个,让我们假设为A和B,输出(top)为C。
A:要进行裁切的bottom。
B:裁切的参考输入。
参数:axis=1,offset=(25,128,128)
C:C = A[: , 25: 25+B.shape[1] , 128: 128+B.shape[2] , 128: 128+B.shape[3] ]
crop在tensorflow中可用strided_slice实现。
参见:
http://www.cnblogs.com/MrLJC/p/6843626.html
tf.strided_slice用法
slice
layer {
name: "data_each"
type: "Slice"
bottom: "data_all"
top: "data_classfier"
top: "data_boundingbox"
top: "data_facialpoints"
slice_param {
axis: 0
slice_point: 150
slice_point: 200
}
}
其中slice_point的个数必须等于top的个数减一。输入的data_all维度为\((250\times 3\times 24 \times 24)\),拆分后的3个输出的维度依次为\((150\times 3\times 24 \times 24),(50\times 3\times 24 \times 24),(50\times 3\times 24 \times 24)\)。
代码
Caffe的代码相对比较简单,符合个人作品的特点。
Caffe没有计算图的概念,所有操作都聚焦于NN本身,对于实际业务的支持有限。其结构主要针对CNN进行设计,通用性无法和TensorFlow相比。但相对简单的结构,非常适合CV用途,成为了目前CV DL的事实标准。
Caffe的代码有相当一部分是由.proto文件自动生成的,最著名的当属LayerParameter。因此如果在C++代码中找不到相关实现的话,不妨到.proto文件中碰碰运气。
例如Conv的实现在src/caffe/layers/conv_layer.cpp中。
Conv Backprop
src/caffe/layers/conv_layer.cpp: ConvolutionLayer::Backward_cpu
src/caffe/layers/base_conv_layer.cpp: BaseConvolutionLayer::weight_cpu_gemm
src/caffe/util/math_functions.cpp: caffe_cpu_gemm
cblas_sgemm
Ristretto Caffe
Ristretto Caffe是一个caffe扩展,支持fp16和int8等特殊格式的数据的转换和运算。
官网:
http://lepsucd.com/?page_id=621
代码:
https://github.com/pmgysel/caffe
Caffe-MPI
Caffe-MPI是一款高性能高可扩展的深度学习计算框架,由浪潮的HPC应用开发团队进行开发。
代码:
https://github.com/Caffe-MPI/Caffe-MPI.github.io
参考:
https://mp.weixin.qq.com/s/n9b0Mf2ikBDxXgknEBTrTg
浪潮集团副总裁胡雷钧:扩展Caffe,从方案、框架、系统、平台应对AI计算挑战
LSTM
Caffe由于主要应用于图像处理领域,其对于RNN的支持实际上是不太优雅的。
RNN在计算方面的难点在于:整个计算图不再是DAG了,有计算环的存在。Caffe采用按时序展开RNN的方式,将有环的计算图展开为DAG。
Caffe的LSTM实现主要包含三个层次:
1.RecurrentLayer。这个类定义了处理时间序列的循环神经网络的通用行为。RNNLayer和LSTMLayer都是它的子类。
2.LSTMLayer。
3.LSTMUnitLayer。LSTM的核心计算部分。
下图中的方框表示了各自Layer所包含的运算。
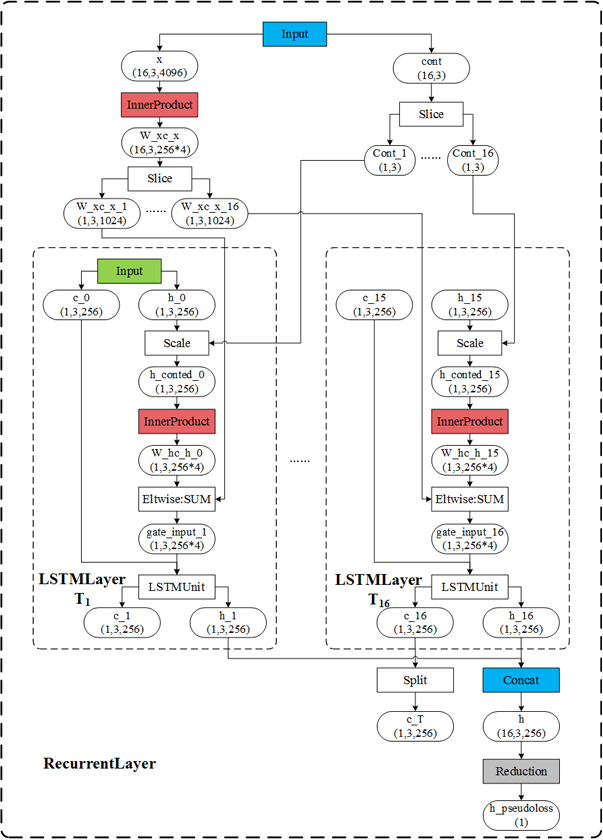
参考:
http://www.meltycriss.com/2016/07/13/caffe_2_rnn/
Caffe学习:RNN源码阅读
http://www.meltycriss.com/2016/08/05/caffe_4_lstm/
Caffe学习:LSTM源码阅读
http://blog.csdn.net/mounty_fsc/article/details/53114698
(Caffe)LSTM层分析
参考
https://mp.weixin.qq.com/s/-Jn4UbZ6EqRYceJqI1l16g
一文简短介绍Caffe
http://blog.csdn.net/haluoluo211/article/details/77918156
caffe python图片训练识别实例
https://mp.weixin.qq.com/s/XxPsbTSiE1M4hIoH0bg0lA
caffe-orc主流ocr算法:CNN+BLSTM+CTC架构实现
Caffe2
2017.4,贾扬清推出了全新设计的Caffe2。由于是全新设计,Caffe2和Caffe不兼容,完全可看为是一个新的DL框架。
官网:
https://caffe2.ai/
2018.4,Caffe2的框架代码与PyTorch合并。Caffe2将主要应用于客户端的推理过程。
感觉Caffe2属于典型的昙花一现,虽然借助Caffe的影响力,立了一个山头,但FaceBook终究精力有限,能支撑一个不被Google打倒的框架已经是颇不容易了,两个根本别想!
参考:
https://mp.weixin.qq.com/s/YYwmRwq5TN7JPah_arNyaQ
Facebook开源产业级深度学习框架Caffe2
darknet
darknet代码:
https://github.com/pjreddie/darknet/
有个叫做darkflow的项目,可以用于将darknet模型转换成tensorflow模型:
https://github.com/thtrieu/darkflow
Conv Backprop
src/convolutional_layer.c: backward_convolutional_layer
src/gemm.c: gemm

您的打赏,是对我的鼓励
