Chip » AI Chip(四)——参考资源
2024-04-03 :: 5976 WordsAI Chip
车载芯片
Qualcomm:SA8775P
小鹏:图灵AI芯片
蔚来:神玑NX9031
参考
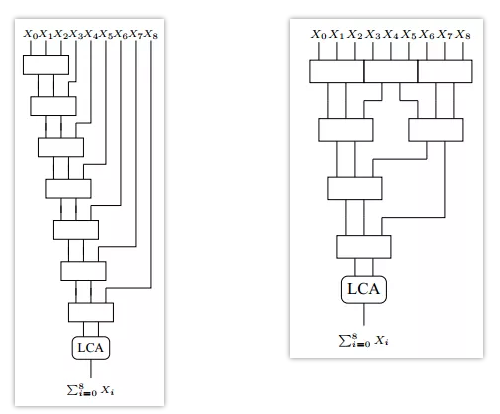
https://mp.weixin.qq.com/s/_n1FA7H5q4AwXqeBg9tekA
硬件实现快速累加
Christopher Stewart “Chris” Wallace,1933~2004,澳大利亚计算机科学家和物理学家。University of Sydney博士(1959)。Monash University教授。ACM fellow。在早期计算机的软件/硬件方面皆有重大贡献。
几乎每一个概述的AI加速解决方案都是从一个已经有几十年历史的学术思想开始的:脉动阵列起源于1978;VLIW架构起源于1983;数据流编程的概念可以追溯到1975;早期的内存内处理(processing-in-memory)出现在20世纪70年代。
https://www.thepaper.cn/newsDetail_forward_16268882
详解AI加速器(一):2012年的AlexNet到底做对了什么?
https://www.thepaper.cn/newsDetail_forward_16641034
详解AI加速器(二):为什么说现在是AI加速器的黄金时代?
https://www.thepaper.cn/newsDetail_forward_16681105
详解AI加速器(三):架构基础离不开ISA、可重构处理器
https://www.thepaper.cn/newsDetail_forward_16787134
详解AI加速器(四):GPU、DPU、IPU、TPU…AI加速方案有无限种可能
https://www.thepaper.cn/newsDetail_forward_16869908
详解AI加速器(最终篇):给想进入赛道的玩家一些建议
Intel制订的游戏规则就是它自己的产品CPU作为“中央”处理器,通过PCIe扩展的形式,让围绕CPU的整个计算机系统变得非常具有可扩展性,可以围绕CPU打造各行各业的解决方案。而这套游戏规则的残酷之处在于,一旦一种PCIe设备的需求变得稳定,Intel就在CPU里增加一些专用指令,于是这种PCIe设备就从历史长河中抹去了,这种方式消失的各类PCIe扩展卡不计其数,显卡在这套游戏规则下也并不例外。
老黄当时意识到这个问题后,提出了Intel的摩尔定律是十八个月翻一番,NVidia要做到六个月翻一番。用更快的性能提升曲线快速拉高需求,让Intel的集显变成落后的产品。
过去十年,大家甚至在做产品规划的时候,也是对标着自己产品上市的时间点,去预估NVidia的产品规格。本质上是沿着和老黄一样的曲线去走,自然也不可能把老黄的产品搞成落后的产品,更不可能争取到独立的生态位了,实际上大家产品迭代的曲线甚至比不过NVidia。
NVidia基本2年一代产品,性能提升3~5倍,挑战者如果能每代相比自己上一代提升10~20倍,和NVidia的性能优势越拉越大。这才是NVidia当年挑战Intel时所作的壮举。
既然transformer is all you need,我们先不管软件的各种麻烦,让你去完全硬化地设计一个transformer加速指令,能不能实打实做出一个包含矩阵和向量单元的GPGPU完全无法企及的性能壁垒?你很难沿着DSA的逻辑持续比上一代DSA硬件做出巨大的性能提升。
https://zhuanlan.zhihu.com/p/672689713
芯片生态的竞争逻辑
https://zhuanlan.zhihu.com/p/619717622
DSA已死
架构的收益其实更多是工艺演进时,新约束下新tradeoff带来的超额收益。如果约束保持不变,其实最佳的tradeoff很快就收敛了,后面想继续靠arch压榨出更多性能就非常困难了。
arch领域需要的不是天才式的创新,而是能持续数十年稳定提升算力的方法论。
第一代芯片你可以用一个systolic array专门处理矩阵乘,当然可以吊打通过SIMD+SMT实现SIMT的GPU芯片,第二代芯片你如何进一步用一种新的电路结构吊打上一代的专用电路呢?针对一个特定功能的专用电路,最佳数据通路其实一两代产品肯定收敛了。
算力提升的方法论可以粗略分解成三个阶段:80年代以前是超标量、80年代到15年左右是并行,15年往后是专用架构。
并行做起来之后多核就成为了主流,比单核提升轻松,当然把代码难写(相比串行代码)的锅丢给了软件,慢慢也积累了大量并行代码的生态。此时多核的路就相对好走多了,也就没必要死扣单核性能了,毕竟要花更多的力气。而且在并行阶段还孕育出了SIMT和GPGPU这种为并行而生的编程模型与架构,软件也就朝着并行化的方向一路狂奔了,而CPU的单核架构已经很多年没有大的革新了。
https://zhuanlan.zhihu.com/p/387269513
专用架构与AI软件栈(1)
https://zhuanlan.zhihu.com/p/58971347
深度学习的芯片加速器
https://mp.weixin.qq.com/s/S5Kjt4tuf_o6o3Qag8sukQ
Google Jeff Dean独自署名论文:深度学习革命及其对计算机架构和芯片设计的影响,讲述AI芯片发展历程与未来
https://cloud.tencent.com/community/article/244743
深度学习的异构加速技术(一):AI需要一个多大的“心脏”?
https://cloud.tencent.com/community/article/581797
深度学习的异构加速技术(二):螺狮壳里做道场
https://cloud.tencent.com/community/article/446425
深度学习的异构加速技术(三):互联网巨头们“心水”这些AI计算平台
https://zhuanlan.zhihu.com/p/25382177
AI芯片怎么降功耗?
https://mp.weixin.qq.com/s/2aE5fzGZeyX-oFyWbcbA5A
揭开神经网络加速器的神秘面纱之DianNao
https://mp.weixin.qq.com/s/VAFb0DAZAUyDnjE6SlNcXw
如何对比评价各种深度神经网络硬件?不妨给它们跑个分
https://zhuanlan.zhihu.com/p/26594188
浅析Yann LeCun提到的两款Dataflow Chip
https://zhuanlan.zhihu.com/p/25728988
AI芯片的几种选择,你更看好哪个?
https://zhuanlan.zhihu.com/p/25510056
ISSCC 2017看AI芯片的四大趋势
https://zhuanlan.zhihu.com/p/26404565
AI芯片四大流派论剑,中国能否弯道超车?
https://zhuanlan.zhihu.com/p/27472524
从AI芯片说起,一起来看芯片门类
https://mp.weixin.qq.com/s/RKRDBiBzG5u2P2eaqNAFbg
机器学习的处理器列表
https://mp.weixin.qq.com/s/uzeeZiaAFdA0C_zAcX756w
深度学习架构之争
https://mp.weixin.qq.com/s/VM-KiIJHA2gXLVu0WRIzwA
王中风教授:如何满足不同应用场景下深度神经网络模型算力和能效需求
https://mp.weixin.qq.com/s/f5mQkWxPYc77t2we1Y306Q
深度学习引领AI芯片大战
https://mp.weixin.qq.com/s/6ksL9p1Gmnrd2HahU3KniQ
ARM攒机指南——AI篇:5大千万级设备市场技术拆解
https://zhuanlan.zhihu.com/p/32953957
浅析图像视频类AI芯片的灵活度
https://mp.weixin.qq.com/s/cfqnLYZSxJhtsgtrydx02A
语音及文本类AI芯片的需求分析
https://mp.weixin.qq.com/s/31SBgTXfIcwkmIzujBLxOA
深度学习引擎的终极形态是什么?
https://zhuanlan.zhihu.com/p/35103140
“传说中”的异步电路能否在AI芯片界异军突起?
https://mp.weixin.qq.com/s/PDe8O5zskxD_mycwH0_3lg
AI是如何影响计算机内存系统的?
https://blog.csdn.net/lien0906/article/details/78863118
深度学习中GPU和显存分析
http://eyeriss.mit.edu/
Eyeriss是MIT设计的一款NN加速器。
https://zhuanlan.zhihu.com/p/37520172
一窥ARM的AI处理器
https://mp.weixin.qq.com/s/UpnkYfhaEsYhze8GdpZ8Dg
Arm的NPU究竟什么水平?
https://mp.weixin.qq.com/s/QPuOmv7-agrcgnchgs3Hkg
清华大学提出AI计算芯片的存储优化新方法
https://mp.weixin.qq.com/s/eyzzeYOKdah-9WGUrhbAkg
非冯诺依曼新架构:IBM100万忆阻器大规模神经网络加速AI
https://mp.weixin.qq.com/s/oOYGa4Mti6KpkpI4TtpitQ
地平线杨铭:从无形视觉到有形芯片
https://mp.weixin.qq.com/s/_8lbTU0GFEXQr_4pdQ6XPw
同步SGD等现有分布式训练方式将过时,Yoshua Bengio谈迈向硬件友好的深度学习
https://mp.weixin.qq.com/s/5MyuZf_TBm2NV47CRAz5Dw
2017图灵奖得主:通用芯片每年仅提升3%,神经专用架构才是未来
https://zhuanlan.zhihu.com/p/57808378
AI芯片0.5与2.0
https://mp.weixin.qq.com/s/XDwTI-gnnFMLjVBbOGKL9w
清华大学团队研制高能效通用神经网络处理器芯片STICKER-T
https://mp.weixin.qq.com/s/xbHP1RFn7F7BbimxgWaKqg
Facebook把服务27亿人的AI硬件系统开源了
https://mp.weixin.qq.com/s/BD-HAILp3TPvBFlIy6QC4w
一文看懂机器视觉芯片
https://mp.weixin.qq.com/s/PMnNay4CRgVghA4fU9oLqg
牛津大学研发类脑光子芯片,运算速度超人脑1000倍
https://mp.weixin.qq.com/s/e333KjLavEvvpNIL3u1Y4Q
NovuMind异构智能核心技术引领智联网
https://mp.weixin.qq.com/s/fSSyOs4-NXbPTbDjpfJBNQ
Google IPU:互联网巨头纷纷进军芯片行业是为何?
https://mp.weixin.qq.com/s/S1y4NEx4_Mgwf68S2pexqA
拿着锤子找钉子,数字芯片领导者比特大陆进军人工智能
https://mp.weixin.qq.com/s/gtgPYf939uYRzxAab_LZLQ
谢源:计算存储一体化,在存储里做深度学习,架构创新实现下一代AI芯片
https://mp.weixin.qq.com/s/s-fYxv4z5kkJUFueU2IR7w
BP表达式与硬件架构:相似性构建更高效的计算单元
https://mp.weixin.qq.com/s/1r7G84les7FihqPbSiS0Ng
华为首款手机端AI芯片麒麟970
https://mp.weixin.qq.com/s/z68hk1yqg60QCjgTyzgG2w
GPU深度学习的“加速神器”
https://mp.weixin.qq.com/s/O-NDsFs6AOwl43LyevXtzg
OpenAI发布“块稀疏”GPU内核:实现文本情感分析与图像生成建模当前最优水平
https://mp.weixin.qq.com/s/XXef4F9HEZizoWRYXwHitw
如何配置一台深度学习工作站?
https://mp.weixin.qq.com/s/_xFRRkVyN9qevLeek7bFxQ
深度学习中GPU和显存分析
https://mp.weixin.qq.com/s/k5Xx-nnaf-yfWqGLIY3LEg
特斯拉的芯片究竟多强
https://zhuanlan.zhihu.com/p/88927564
窥探神经网络加速器的数据复用(一)
https://mp.weixin.qq.com/s/YARcCzQXqnJmWRtV2zd_FQ
国内外AI芯片发展现状
https://mp.weixin.qq.com/s/b_Hy0JSZ5ZGT9AsczCkp9Q
ISSCC 2020:AI芯片架构的转变
https://zhuanlan.zhihu.com/p/115219461
张量在神经网络加速器中的应用
https://pan.baidu.com/s/1zcXdXTaN3dbJ9VGplViHZw 提取码:ews4
AI芯片体系架构和软件专题报告会2020论文下载
https://mp.weixin.qq.com/s/cBVio3W64np8fXwUQs2wIw
机器学习如何用于芯片系统设计?Jeff Dean推荐Google最新《机器学习系统芯片设计》70页ppt为你讲解
https://zhuanlan.zhihu.com/p/150656419
AI芯片技术发展
https://mp.weixin.qq.com/s/9fBe6MsUOCDhtp4MSfP2jg
AI处理器热潮正在消退
https://mp.weixin.qq.com/s/JYTqJDlGw6Q2gNLaYIGLcQ
特斯拉芯片究竟怎么样?
https://mp.weixin.qq.com/s/cA1AXfpV3ZcMNX9k5XKlww
面向深度神经网络的芯片布图规划问题简介

您的打赏,是对我的鼓励
