DL » 深度学习(三十一)——依存分析, Siamese network, SENet
2018-01-17 :: 5280 Words依存分析
概况
Dependency Parsing是NLP领域的一项重要工作。
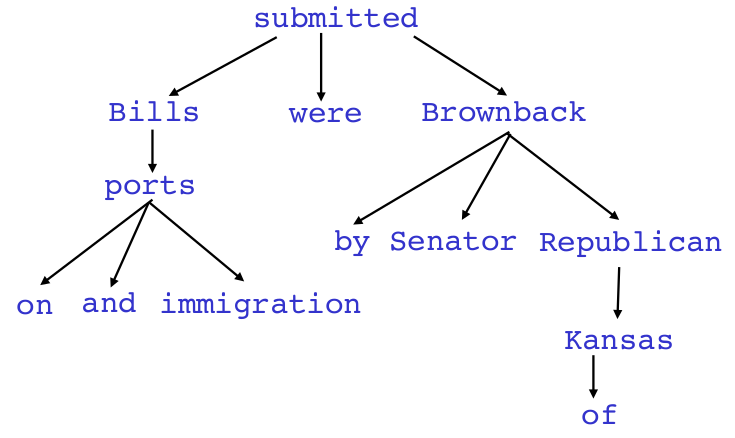
依存分析的基本目标是对一句话构建一个表达词与词之间依赖关系的语法树,如上图所示。
传统方法
这里以2003年提出的Greedy transition-based parsing算法为例,介绍一下依存分析的传统做法。
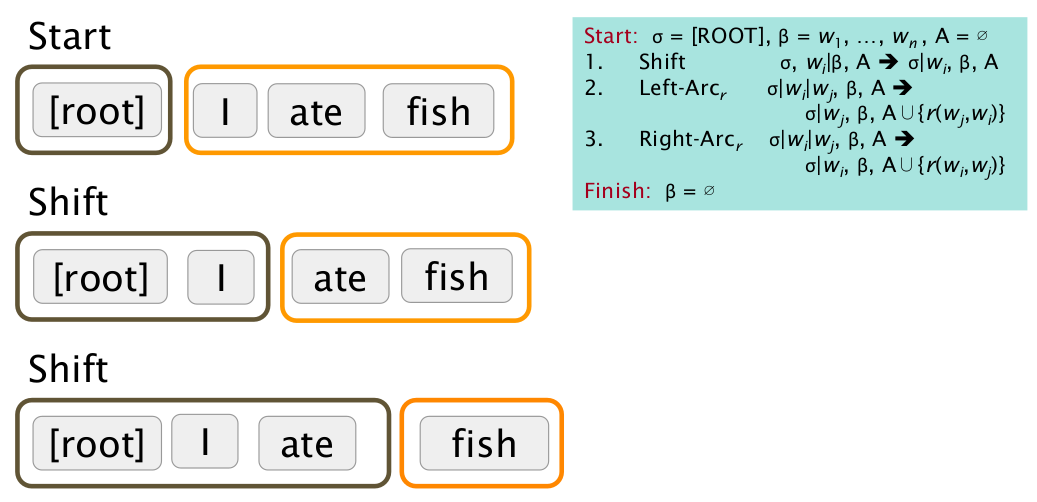
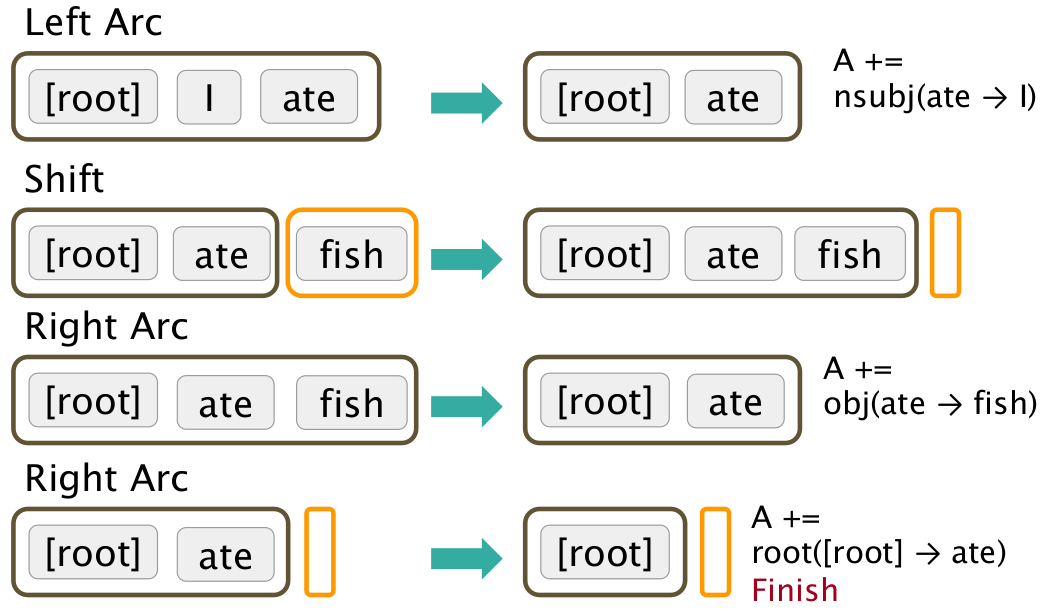
上图演示了ROOT结点是如何一步步“吃”进词语(即Shift操作),并生成依存分析树的过程。
这里的每一步被称作transition。
transition中箭头左边的部分是以ROOT为栈底的stack,右边的部分是待处理文本的buffer,A表示依赖关系树。
stack+buffer+A构成了一个configuration。GTBP算法的难点,在于如何根据configuration,确定下一步的transition。这在传统做法中,通常是一堆文法规则,或者特征的分类。
依存分析的准确度指标

依存分析的准确度指标主要有UAS和LAS两种。
上图是某句话的依存分析结果。其中Gold表示正确答案,而Parsed表示算法的计算结果。结果的第二列是依存结点,0表示ROOT;第4列是单词的词性。
Unlabeled attachment score是指依存结点是否正确。以上图中的例子为例,就是4/5=80%。
Labeled attachment score不仅考虑依存结点是否正确,还考虑词性是否正确。用样以上图为例,则是2/5=40%。
深度方法
深度方法的开山之作是陈丹琦2014年的论文:
《A Fast and Accurate Dependency Parser using Neural Networks》
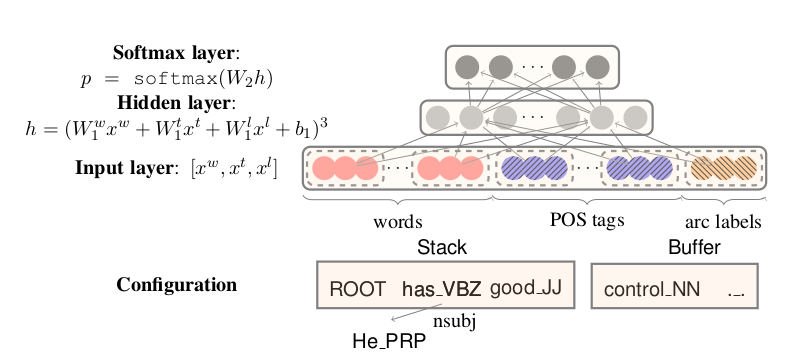
上图是该方案的结构图。
我们之前已经指出,在传统方法中,transition是由单词、词性和依赖关系树所确定的。只是这种确定的规则比较复杂,不易提炼出有效特征。
参照我们在CNN中的作为,特征提取这一步骤可以由神经网络来完成。因此,在这里我们将configuration的各个组成部分分别向量化,然后合成为一个长向量,作为Input layer。
这里采用以下的Cube函数作为激活函数,这也是该文的一大创见:
\[h=(W_1^w x^w + W_1^t x^t + W_1^l x^l + b_1)^3\]Output layer是一个softmax的多分类层,每个分类对应一个transition。
SyntaxNet
2015年David Weiss在陈丹琦方案的基础上,做了一些改进。
论文:
《Structured Training for Neural Network Transition-Based Parsing》
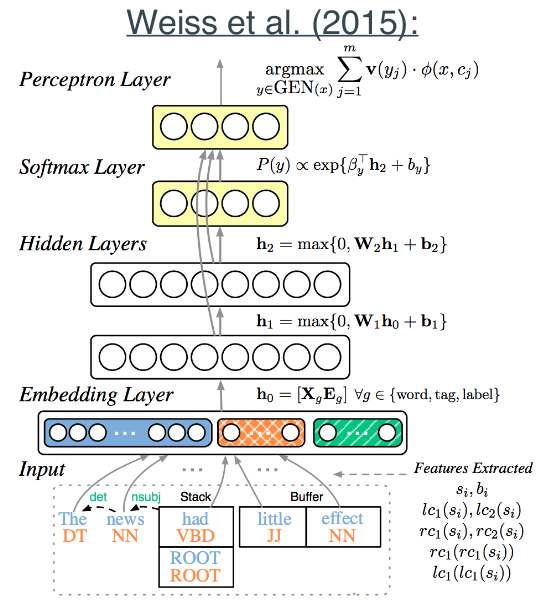
上图是Weiss方案的结构图。该方案相比陈丹琦方案的改进如下:
1.由1个隐层改为两个隐层。
2.添加Perceptron Layer作为输出层。(Perceptron Layer的含义参见《机器学习(二十五)》中对于Beam Search的解释)
3.全局使用Tri-training算法作为半监督的集成学习算法。(Tri-training算法参见《机器学习(二十四)》)
《Opinion Mining with Deep Recurrent Neural Networks》
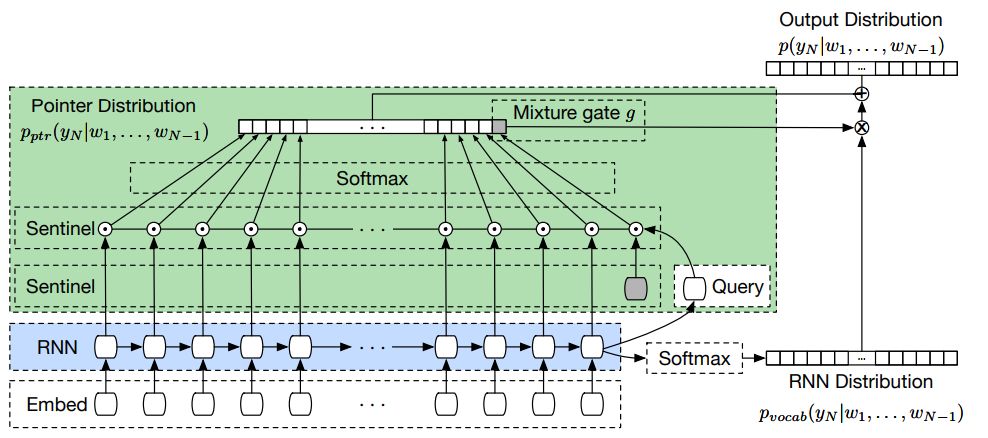
《Pointer Sentinel Mixture Models》
https://www.zhihu.com/question/46272554
如何评价SyntaxNet?
http://mp.weixin.qq.com/s/IWagHP0MSQFAJ50NeoyOjw
基于神经网络的高性能依存句法分析器
陈丹琦
https://www.cs.princeton.edu/~danqic/
陈丹琦,清华本科(姚班)(2012)+斯坦福博士(2018)。Princeton AP。
http://theory.stanford.edu/~yuhch123/
陈丹琦的老公俞华程也是个学霸。而且从高中就和陈丹琦同校,直到博士毕业。

左二陈丹琦,右一俞华程。两者同为IOI2008金牌得主。
CNN在NLP中的应用
虽然基本上,CV界是CNN的天下,NLP界是RNN的地盘。然而,两者的界限并不是泾渭分明的。比如下图就是一个CNN在NLP中的应用示例:
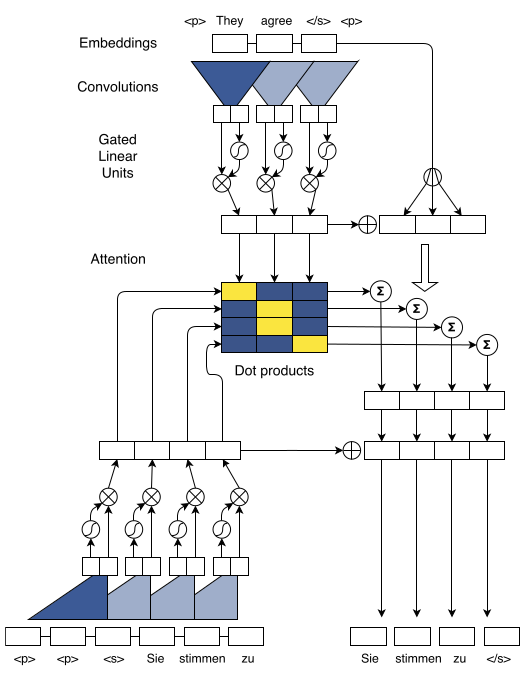
卷积本质上是一个局部运算。对词向量的卷积,实际上等效于n-gram的词袋模型。
论文:
《Convolutional Sequence to Sequence Learning》
参见:
http://www.jeyzhang.com/cnn-apply-on-modelling-sentence.html
卷积神经网络(CNN)在句子建模上的应用
http://blog.csdn.net/malefactor/article/details/51078135
自然语言处理中CNN模型几种常见的Max Pooling操作
http://www.jianshu.com/p/1267072ee8f8
CNN在NLP中的应用
TWE
http://nlp.csai.tsinghua.edu.cn/~lzy/publications/aaai2015_twe.pdf
Topical Word Embeddings
TWE的代码:
https://github.com/largelymfs/topical_word_embeddings
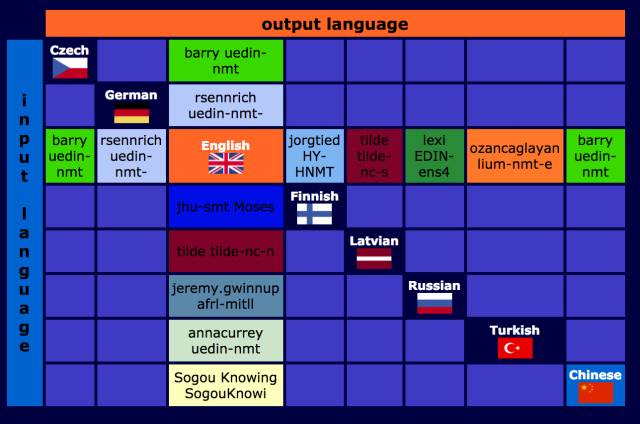
上图可以看出英语的确是世界语言啊。
无监督的机器翻译
无监督的机器翻译,其要点主要在于比较两种语言语料的词向量空间,以找出词语间的对应关系。
由word2vec的原理可知,由于训练时神经元是随机初始化的,因此即使是同样的语料,两次训练得到的词向量一般也不会相同,更不用说不同语料了。因此直接比较两个词向量空间中的词向量,是行不通的。
参见:
https://zmlarry.github.io
张檬,清华本科(2013)+博士(2018)。
ESN
Echo State Network
https://blog.csdn.net/zwqhehe/article/details/77025035
回声状态网络(ESN)原理详解
https://mp.weixin.qq.com/s/tjawT2-bhPrit0Fd4knSgA
基于回声状态网络预测股票价格
Siamese network
Siamese和Chinese有点像。Siam是古时候泰国的称呼,中文译作暹罗。Siamese也就是“暹罗”人或“泰国”人。Siamese在英语中是“孪生”、“连体”的意思,这是为什么呢?
十九世纪泰国出生了一对连体婴儿,当时的医学技术无法使两人分离出来,于是两人顽强地生活了一生,1829年被英国商人发现,进入马戏团,在全世界各地表演,1839年他们访问美国北卡罗莱那州,后来成为“玲玲马戏团” 的台柱,最后成为美国公民。1843年4月13日跟英国一对姐妹结婚,恩生了10个小孩,昌生了12个,姐妹吵架时,兄弟就要轮流到每个老婆家住三天。1874年恩因肺病去世,另一位不久也去世,两人均于63岁离开人间。两人的肝至今仍保存在费城的马特博物馆内。从此之后“暹罗双胞胎”(Siamese twins)就成了连体人的代名词,也因为这对双胞胎让全世界都重视到这项特殊疾病。
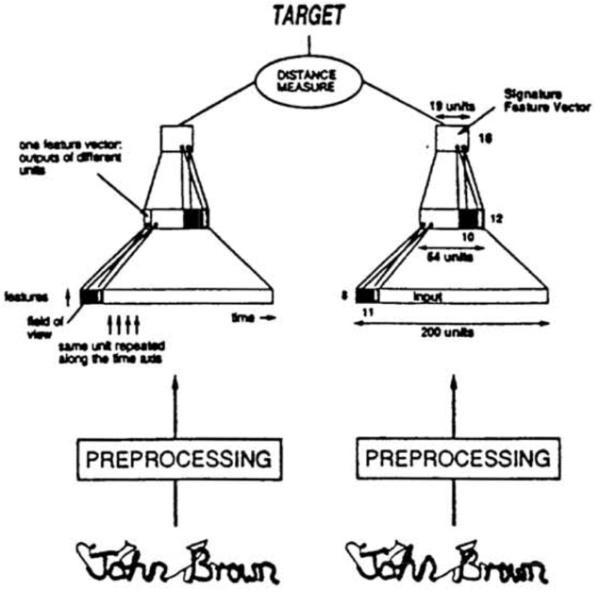
上图摘自LeCun 1993年的论文:
《Signature Verification using a ‘Siamese’ Time Delay Neural Network》
Siamese network有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
在上图中,两个输入分别是支票上的签名与银行预留签名。我们可以使用Siamese network来验证两者是否一致。
Siamese network也可进一步细分:
-
如果Network1和Network2的结构和参数都相同,则称为Siamese network。
-
如果两个网络不共享参数,则称为pseudo-siamese network。对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
除了Siamese network之外,类似的还有三胞胎连体——Triplet network。
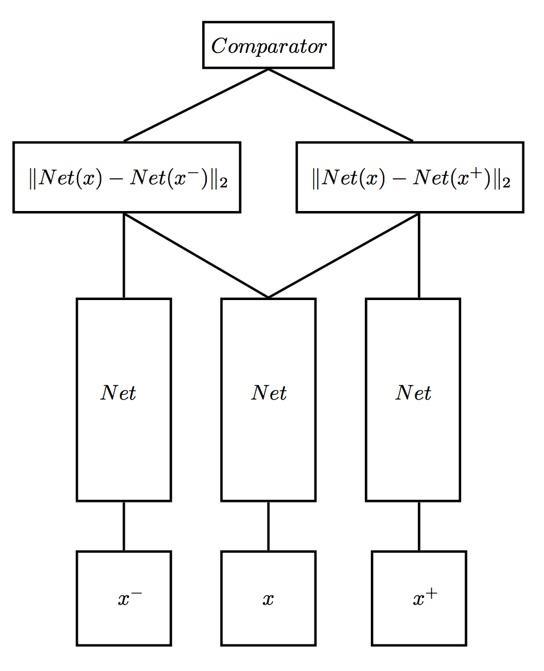
输入是三个,一个正例+两个负例,或者一个负例+两个正例,训练的目标是让相同类别间的距离尽可能的小,让不同类别间的距离尽可能的大。
Siamese network由于输入是一对样本,因此它更能理解样本间的差异,使得数据量相对较小的数据集也能用深度网络训练出不错的效果。
对Siamese network的进一步发展,引出了2020年比较火的对比学习。
参考:
https://blog.csdn.net/shenziheng1/article/details/81213668
Siamese Network(原理篇)
https://www.jianshu.com/p/92d7f6eaacf5
Siamese network孪生神经网络–一个简单神奇的结构
https://blog.csdn.net/sxf1061926959/article/details/54836696
Siamese Network理解
https://vra.github.io/2016/12/13/siamese-caffe/
Caffe中的Siamese网络
https://mp.weixin.qq.com/s/rPC542OcO8B4bjxn7JRFrw
深度学习网络只能有一个输入吗
https://mp.weixin.qq.com/s/GlS2VJdX7Y_nfBOEnUt2NQ
使用Siamese神经网络进行人脸识别
https://mp.weixin.qq.com/s/lDlijjIUGmzNzcP89IzJnw
张志鹏:基于siamese网络的单目标跟踪
https://mp.weixin.qq.com/s/WYL43CEhVmsvjZDY7afMrA
孪生网络:使用双头神经网络进行元学习
https://mp.weixin.qq.com/s/bgZbIi4BvAFmVoAakciYGQ
如何训练孪生神经网络
SENet
无论是在Inception、DenseNet或者ShuffleNet里面,我们对所有通道产生的特征都是不分权重直接结合的,那为什么要认为所有通道的特征对模型的作用就是相等的呢?这是一个好问题,于是,ImageNet2017冠军SEnet就出来了。
论文:
《Squeeze-and-Excitation Networks》
代码:
https://github.com/hujie-frank/SENet
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。
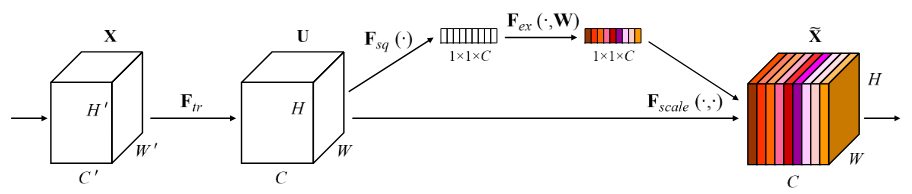
上图就是SE block的示意图。其步骤如下:
1.转换操作\(F_{tr}\)。这一步就是普通的卷积操作,将输入tensor的shape由\(W'\times H'\times C'\)变为\(W\times H\times C\)。
2.Squeeze操作。
\[z_c = F_{sq}(u_c) = \frac{1}{H\times W}\sum_{i=1}^H \sum_{j=1}^W u_c(i,j)\]这实际上就是一个global average pooling。
3.Excitation操作。
\[s=F_{ex}(z,W) = \sigma(g(z,W)) = \sigma(W_2 \sigma(W_1 z))\]其中,\(W_1\)的维度是\(C/r \times C\),这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量。
\(W_2\)的维度是\(C \times C/r\),这样s的维度就恢复到\(1 \times 1 \times C\),正好和z一致。
4.channel-wise multiplication。
\[\tilde{x_c} = F_{scale}(u_c, s_c)=s_c \cdot u_c\]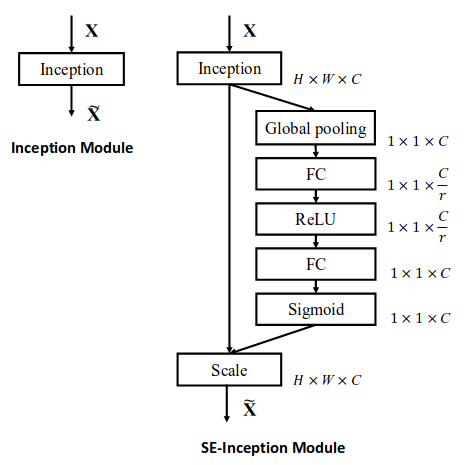
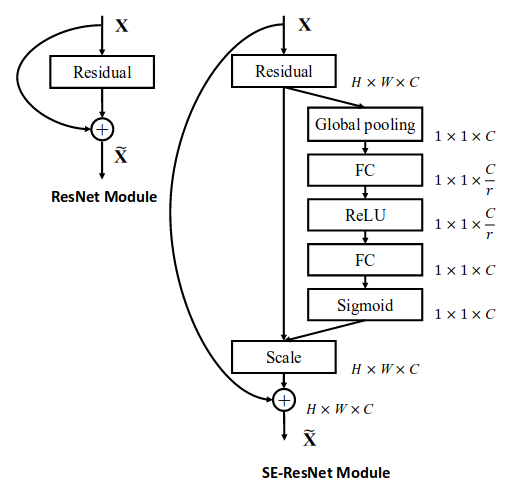
上面两图演示了如何将SE block嵌入网络的办法。

您的打赏,是对我的鼓励
