DL » 深度学习(二十八)——SOM, Recursive NN
2018-01-08 :: 5448 WordsRBM & DBM & DBN & Deep Autoencoder(续)
DBM & DBN
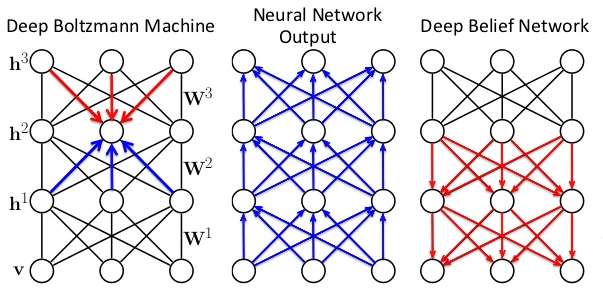
RBM不仅可以单独使用,也可以堆叠起来形成Deep Boltzmann Machine(DBM)和Deep Belief Nets(DBN),其中每个RBM层都与其前后的层进行通信。单个层中的节点之间不会横向通信。
DBM是直接是拟合一个joint分布,而DBN是RBM叠加了很多bayes net。
DBN可以直接用于处理无监督学习中的未标记数据聚类问题,也可以在RBM层的堆叠结构最后加上一个Softmax层来构成分类器。
除了第一个和最后一个层,DBN中的每一层都扮演着双重角色:既是前一层节点的隐藏层,也是后一层节点的输入(或“可见”)层。DBN是由多个单层网络组成的。
DBN常用于图像、视频序列和动作捕捉数据的识别、聚类与生成。
参考:
https://mp.weixin.qq.com/s/7V0GSWcKZGyXeLeMPhE9fQ
神经网络简史:BP算法后的又一突破—信念网络
https://zhuanlan.zhihu.com/p/40100223
深度学习与TensorFlow:关于DBN的一些认识
https://mp.weixin.qq.com/s/Qs-rg25B7hACzw6uEqRQbg
深度信念网络研究现状与展望
Deep Autoencoder
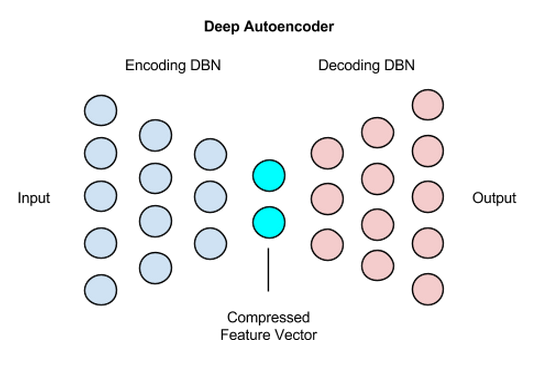
Deep Autoencoder由两个对称的DBN组成,其中一个DBN通常有四到五个浅层,构成负责编码的部分,另一个四到五层的网络则是解码部分。
让我们用以下的示例来描绘一个编码器的大致结构:
784 (输入) —> 1000 —> 500 —> 250 —> 100 —-> 30
假设进入网络的输入是784个像素(MNIST数据集中28x28像素的图像),那么深度自动编码器的第一层应当有1000个参数,即相对较大。
这可能会显得有违常理,因为参数多于输入往往会导致神经网络过拟合。
在这个例子当中, 增加参数从某种意义上来看也就是增加输入本身的特征,而这将使经过自动编码的数据最终能被解码。
其原因在于每个层中用于变换的sigmoid置信单元的表示能力。sigmoid置信单元无法表示与实数数据等量的信息和差异,而补偿方法之一就是扩张第一个层。
各个层将分别有1000、500、250、100个节点,直至网络最终生成一个30个数值长的向量。这一30个数值的向量是深度自动编码器负责预定型的前半部分的最后一层,由一个普通的RBM生成,而不是一个通常会出现在深度置信网络末端的Softmax或逻辑回归分类输出层。
解码的DBN是一个完全相反的结构。
相比Autoencoder,Deep Autoencoder显然能够“消化”更复杂的数据。
参考
https://deeplearning4j.org/cn/restrictedboltzmannmachine
受限玻尔兹曼机基础教程
http://txshi-mt.com/2018/02/04/UTNN-11-Hopfield-Nets-and-Boltzmann-Machines/
Hopfield网和玻尔兹曼机
https://mp.weixin.qq.com/s/hnmKM-_zgb5m80NTd_b8gw
能量学习之Hopfield Networks
John Joseph Hopfield,1933年生,美国科学家。Cornell University博士(1958),先后执教于UCB、Princeton和Caltech。美国艺术科学院、美国科学院院士。
他爸也叫John Joseph Hopfield,波兰物理学家。
2024.10.8 Hopfield被授予诺贝尔物理学奖。
http://txshi-mt.com/2018/02/10/UTNN-12-Restricted-Boltzmann-Machines/
受限玻尔兹曼机
https://mp.weixin.qq.com/s/pWhJR6_6lRtDBl1MnYSIiw
深度学习来一波,受限玻尔兹曼机原理及在推荐系统中的应用
http://www.cnblogs.com/kemaswill/p/3269138.html
基于受限玻尔兹曼机(RBM)的协同过滤
http://www.cnblogs.com/kemaswill/p/3203605.html
受限波尔兹曼机简介
https://mp.weixin.qq.com/s/MqnJ39GPrzP4xJWDZi9gnQ
博士生开源深度学习C++库DLL:快速构建卷积受限玻尔兹曼机
http://www.cs.toronto.edu/~fritz/absps/cogscibm.pdf
A Learning Algorithm for Boltzmann Machines
http://www.cs.toronto.edu/~hinton/absps/dbm.pdf
Deep Boltzmann Machines
http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf
A Practical Guide to Training Restricted Boltzmann Machines
http://www.taodocs.com/p-62206829.html
《受限波尔兹曼机简介》张春霞著
https://mp.weixin.qq.com/s/mXJthyETebtww5TvEljuoQ
预测电影偏好?如何利用自编码器实现协同过滤方法
https://blog.csdn.net/hanlin_tan/article/details/62078935
机器学习中的玻尔兹曼分布——最小代价和极大似然
https://mp.weixin.qq.com/s/yodpXMGAoBpEa20_PkFA0w
浅析玻尔兹曼机的原理和实践
SOM
Self Organizing Maps (SOM)(也叫kohonen network)是一种无监督算法,主要用于聚类和可视化。
Teuvo Kohonen,1934年生,芬兰科学家。Helsinki University of Technology博士和教授。
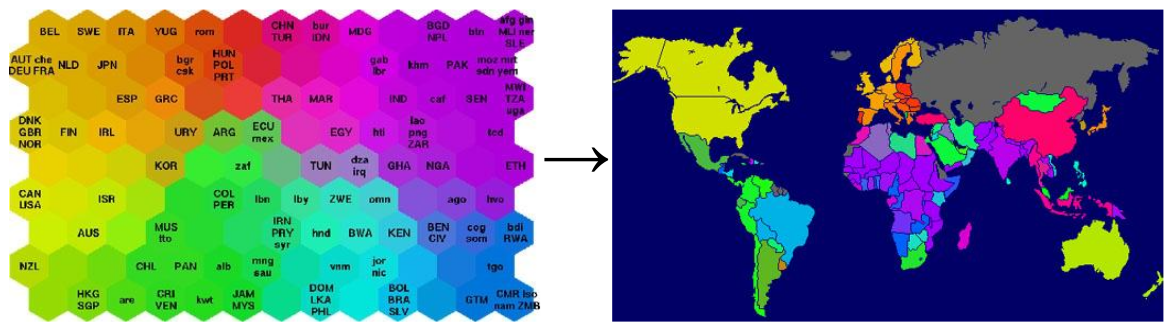
上图是一个SOM可视化的案例。左边的六角形网格被称作SOM的map space。其中,越相似的国家,在map space上的颜色和位置越接近。
下面来说一下SOM的具体训练方法。
构建map space
首先,map space是有拓扑关系的。这个拓扑关系需要我们确定,如果想要一维的模型,那么隐藏节点依次连成一条线;如果想要二维的拓扑关系,那么就组成一个平面网格。换句话说,SOM的目标就是将任意维度的输入离散化到一维或者二维(更高维度的不常见)的离散空间上。
网格的形状一般是矩形或六角形。网格中的每个node关联一个weight vector,其中的值表示一个input space中的点,因此weight vector和input vector的维度是相同的。
初始化weight vector
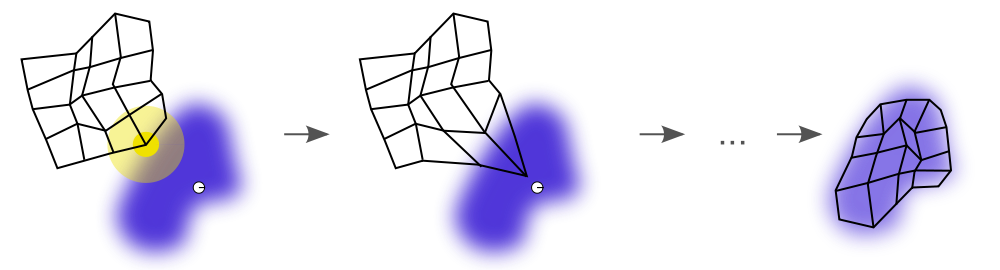
上图展示了SOM的训练过程。SOM训练的目的就是使map space尽量贴合样本分布。
因此,通常有两种初始化weight vector的方法:
1.用小的随机值初始化。
2.从最大的两个主特征向量上进行采样。
显然,第2种训练起来要快的多。因为它已经是SOM weights的一个很好的近似了。
训练SOM
1.对于每一个输入数据,找到与它最相配的node,这个node一般被称作best matching unit(BMU)。这里一般使用Euclidean distance作为相似度的度量。
2.更新BMU的weight,使之更接近输入数据。同时也要更新BMU周围的node的weight,离BMU越近,更新幅度越大。更新公式为:
\[W_{v}(s + 1) = W_{v}(s) + \theta(u, v, s) \cdot \alpha(s) \cdot (D(t) - W_{v}(s))\]其中,D(t)是输入数据,u表示BMU的index,v是被更新node的index,s是迭代的次数,\(\alpha(s)\)是更新率,一般为一个单调递减函数。\(\theta(u, v, s)\)是时空衰减因子,公式通常为:
\[\theta(u, v, s)=\exp \left(-\frac{dist(u,v)}{2\sigma^2(s)}\right)\]反复多次进行以上2步的迭代之后,SOM会趋于收敛。
与K-Means的比较
同样是无监督的聚类方法,SOM与K-Means有什么不同呢?
1.K-Means需要事先定下类的个数,也就是K的值。SOM则不用,隐藏层中的某些节点可以没有任何输入数据属于它。所以,K-Means受初始化的影响要比较大。
2.K-means为每个输入数据找到一个最相似的类后,只更新这个类的参数。SOM则会更新临近的节点。所以K-mean受noise data的影响比较大,SOM的准确性可能会比k-means低(因为也更新了临近节点)。
3.SOM的可视化比较好。优雅的拓扑关系图。
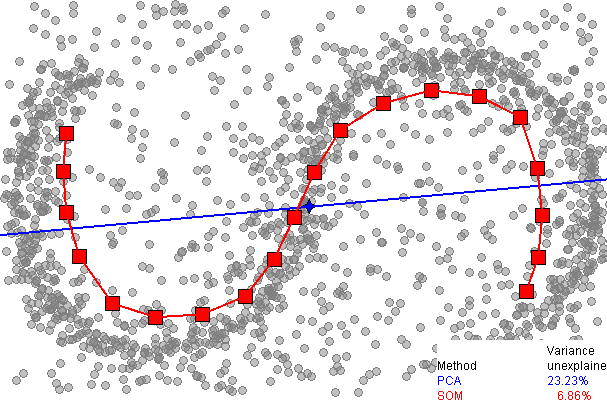
上图中蓝线表示PCA的主轴,而红点是SOM的node结点,可见SOM对数据的贴合程度要高于PCA。
参考
http://chem-eng.utoronto.ca/~datamining/Presentations/SOM.pdf
Self-Organizing Maps
http://www.cnblogs.com/sylvanas2012/p/5117056.html
Self Organizing Maps (SOM): 一种基于神经网络的聚类算法
http://blog.csdn.net/Loyal2M/article/details/11225987
聚类算法实践(3)——PCCA、SOM、Affinity Propagation
http://www.ai-junkie.com/ann/som/som1.html
Kohonen’s Self Organizing Feature Maps
Recursive NN
http://blog.csdn.net/qq_26609915/article/details/52119512
递归神经网络(recursive NN)结合自编码(Autoencode)实现句子建模
http://blog.csdn.net/mengmengz07/article/details/51348554
recursive neural network梳理
https://mp.weixin.qq.com/s/DwaSF76uvqFKkybaTUpl3w
空间序列递归神经网络用于高光谱图像分类
迁移学习+
https://zhuanlan.zhihu.com/p/57656210
Deep Domain Adaptation论文集(五):基于数据重构的迁移方法
https://zhuanlan.zhihu.com/p/57930557
Deep Domain Adaptation论文集(六):源域与目标域特征空间不一致的处理方法
https://zhuanlan.zhihu.com/p/58514431
Domain Adaptation:不用深度网络,如何处理源域和目标域异构问题?
https://zhuanlan.zhihu.com/p/272508224
Domain Adaptation基础概念与相关文章解读
https://mp.weixin.qq.com/s/7QrIfNXQgSqYC1SOFUOlgQ
对迁移学习中域适应的理解和3种技术的介绍
https://mp.weixin.qq.com/s/e_ltoKzqBhmicwb7vcFcoQ
迁移学习-该做的和不该做的
https://mp.weixin.qq.com/s/Yzbn8B9DsBErt9VbAQTY3w
深度迁移学习方法的基本思路
https://mp.weixin.qq.com/s/CWoKwJ0tyMm10ffgRXLXvg
机器学习模型如何泛化到未知领域?微软亚研“领域泛化 (Domain Generalization)”综述论文概述理论、算法等
https://mp.weixin.qq.com/s/ZuiKVan3EqOQDR1wjH01WA
基于小样本学习的图像分类技术综述
https://mp.weixin.qq.com/s/MdmB4lzSjSYrhc07Gwe8mQ
基于PyTorch,集合17种方法,南京大学等提出小样本算法库LibFewShot

您的打赏,是对我的鼓励
