DL » 深度学习(二十七)——问答系统, 李飞飞, RBM & DBM & DBN & Deep Autoencoder
2018-01-04 :: 5142 Words问答系统
GA-Reader
Match-LSTM
Bi-DAF
R-Net
QA-Net
S-Net
R3
参考
https://mp.weixin.qq.com/s/IahvlkiACOAjicX68teA0A
套路深深深几许?管窥问答系统、阅读理解的小江湖
https://mp.weixin.qq.com/s/h51gh-9LISEBdJx8X–Lsg
近期有哪些值得读的QA论文?
https://mp.weixin.qq.com/s/lB44D_RFBqbNB6YX5gEULg
近期值得读的QA论文!专题论文解读
http://www.taodocs.com/p-4795349.html
基于大规模问答语料的问题检索系统
https://mp.weixin.qq.com/s/5ajhhc4mpIhoqkl5VkGnaw
深度学习实现问答机器人
https://mp.weixin.qq.com/s/2aKoOx18RB0GGQTzb3Tjzg
Facebook开源DrQA的PyTorch实现:基于维基百科的问答系统
https://mp.weixin.qq.com/s/4TC7180LmD7V6u1CdVYRFw
漫谈机器阅读理解之Facebook提出的DrQA系统
https://mp.weixin.qq.com/s/SYUq1Qd-IOmVjgs7Kp4OAg
如何打造智能问答引擎
https://mp.weixin.qq.com/s/Mzycy0chQUNWjJYdpERBOw
一文详解维基百科的开放性问答系统
https://www.cnblogs.com/combfish/p/6708667.html
(QA-LSTM)自然语言处理:智能问答IBM保险QA QA-LSTM实现笔记
https://mp.weixin.qq.com/s/BhDy55Mj5oMArO0MKwvnKw
基于异构社交网络学习的社区问答方法,同时建模问题、回答和回答者
https://mp.weixin.qq.com/s/bZgis3dxMbv6AnLNyk04Og
用数据做酷的事!手把手教你搭建问答系统
https://mp.weixin.qq.com/s/nIMk-xl8Wzy1ANcT3ApAng
百度提出问答模型GNR:检索速度提高25倍
https://mp.weixin.qq.com/s/eDA6-BqPmjGBOPsOom0VIw
自动组合神经网络做问答系统!
https://mp.weixin.qq.com/s/vazeuiFvCC8aIhP2uAXoew
达观数据智能问答技术研究
https://mp.weixin.qq.com/s/eaxyhk93PbEFzHk-qiniOQ
ReQuest: 使用问答数据产生实体关系抽取的间接监督
https://mp.weixin.qq.com/s/1VYdCLw6q4rS91_YV4SclA
理解智能问答系统(Ⅰ)
https://mp.weixin.qq.com/s/x4yXjl0YXytAgp8a64ebXg
智能问答开源项目之YodaQA(Ⅱ)
https://mp.weixin.qq.com/s/2VPfk7jX0eBP2NZMB9igBg
智能问答之使用UIMA进行文本挖掘(Ⅲ)
https://mp.weixin.qq.com/s/NohUxQKHw8Z3kX_riGM10g
智能问答之答案抽取(Ⅳ)
https://mp.weixin.qq.com/s/EU0O-WR0ynI04NsPZ-bn2g
无从下手落地问答系统?实用百度开源框架了解一下
https://mp.weixin.qq.com/s/F1z7evNDqghEzSD-_Xbgfw
基于卷积深度相关性计算的社区问答方法,建模问题和回答的匹配关系
https://mp.weixin.qq.com/s/_klvAhH-K8tcYmamlr6FcA
Logistic Regression Models分析交互式问答
https://mp.weixin.qq.com/s/_XyqNPkInWfy-gUQtHjNIg
基于深度神经网络的自动问答系统概述
https://mp.weixin.qq.com/s/GyE9qdXPGvrq12dMAf4nrQ
论文推荐:QA,增强学习,知识图谱,机器阅读理解
https://mp.weixin.qq.com/s/6dKticG2I2zqlxnZ3W0ZgQ
“猜你所想,答你所问”,携程智能客服算法实践
https://mp.weixin.qq.com/s/yiAC6SddIFFo3bR351b_0Q
Embodied Question Answering
https://mp.weixin.qq.com/s/L227SZXQPinNOkKJjwr58w
85页《基于神经方法的人机对话系统》,微软+谷歌出品
https://mp.weixin.qq.com/s/_R9LUJhAb0eDCs14BJsoDA
平安人寿资深算法工程师谢舒翼:智能问答系统探索与实践
https://mp.weixin.qq.com/s/wH-YYzifsEqMCD_4n8B-Kw
12张图看懂Gartner《智能客服机器人行业最佳实践》报告
https://mp.weixin.qq.com/s/tntgiltyHfbIBktgdL3peA
15年研发经验博士手把手教学:从零开始搭建智能客服
https://mp.weixin.qq.com/s/hhWRhBeRCmxjr9Lh8aE_Ww
如何用20万条客服咨询消息“喂”出定制化聊天机器人
https://mp.weixin.qq.com/s/LFmZMcunhJ-9ey9_igrTZA
行业智能客服构建探索
https://mp.weixin.qq.com/s/OHSqHNo7vjLGaTKyzjZjyg
基于智能客服的用户日志研究
https://mp.weixin.qq.com/s/Dp4rlR3Znwv_2gbYCJu8cg
美团智能客服技术实践
李飞飞
AI大佬
李飞飞是吴恩达之后的华裔AI新大佬。巧合的是,他们都是斯坦福AP+AI lab的主任,只不过吴是李的前任而已。
李飞飞(Fei-Fei Li),1976年生,成都人,16岁移民美国。普林斯顿大学本科(1995~1999)+加州理工学院博士(2001~2005)。先后执教于UIUC、普林斯顿、斯坦福等学校。
个人主页:
http://vision.stanford.edu/feifeili/
她的老公Silvio Savarese,斯坦福的AP,互联网巨头salesforce的首席科学家。
李飞飞不做具体技术,早年她老公给她做,后来学生给她做,但是她的学术方向感很好,属于左右逢缘,啥年代都混的好。
所以李飞飞当谷歌云ai总裁,干不了几天,就干不下去了。她不是王坚,王坚不会写代码,但是有马云的坚决支持,但也正因为王坚不会写代码,所以阿里云在技术上一言难尽,出了众多世界级灾难事故,严重败坏了阿里的技术形象。
飞飞的爷爷在她爸14岁那一年就去世了。而且飞飞这段写的过于高情商,估计很多接受大陆正统教育的人,很难理解“那是1961年,父亲当时只有14岁。”是什么意思,“极度营养不良,extreme malnourishment”是什么意思。
从以上的证据来看,飞飞和李井泉唯一可能产生的关系是,李井泉欠他们家一条人命(假设她爸和爷爷1961年在四川)。
大佬的门徒
比如可爱的妹子Serena Yeung。这个妹子是斯坦福的本硕博。出身不详,但从姓名的英文拼法来看,应该是美国土生的华裔。Yeung是杨、阳、羊等姓的传统英文拼法,但显然不是大陆推行的拼音拼法。(可以对比的是Fei-Fei Li和Bruce Lee,对于同一个姓的不同拼法。)
个人主页:
http://ai.stanford.edu/~syyeung/
还有当红的“辣子鸡”:Andrej Karpathy,多伦多大学本科(2009)+英属不列颠哥伦比亚大学硕士(2011)+斯坦福博士(2015)。现任特斯拉AI总监。
吐槽一下:英属不列颠哥伦比亚大学其实是加拿大的一所大学。
个人主页:
http://cs.stanford.edu/people/karpathy/
Andrej Karpathy建了一个检索arxiv的网站,主要搜集了近3年来的ML/DL领域的论文。网址:
http://www.arxiv-sanity.com/
李佳(Jia Li),李飞飞的开山大弟子,追随她从UIUC、普林斯顿到斯坦福。目前又追随其到Google。大约是知道自己的名字是个大路货,她的笔名叫做Li-Jia Li。
个人主页:
http://vision.stanford.edu/lijiali/
学神
应该说李飞飞和吴恩达都是万里挑一的超卓人物,但是和学神还是有所差距。下面是两个80后的华裔学神,他们都已经是正教授了:
尹希,1983年生,哈佛大学物理系教授。
张锋,1982年生,MIT教授,生物学家。
这两个人都是有机会挑战诺奖的人,而李和吴暂时还没有这个可能性。
2020.10
2020年的诺贝尔化学奖给了CRISPR,但是没有给张锋。除非张再做出什么新贡献,否则诺奖估计是没戏了。
网红
这里收录了一些非李飞飞门下的AI网红。
Zachary Chase Lipton,1985年生,哥伦比亚大学本科+UCSD博士,CMU的AP。他的另一身份——Jazz歌手,可比他的学术成就知名多了。
个人主页:
http://zacklipton.com/
RBM & DBM & DBN & Deep Autoencoder
RBM
Restricted Boltzmann Machines由Hinton发明,是一种用于降维、分类、回归、协同过滤、特征学习和主题建模的算法。
RBM一般分为输入和重构两个阶段。
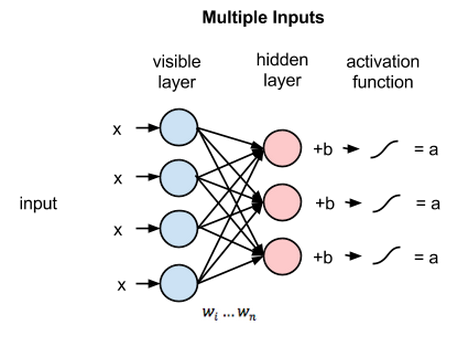
上图是输入阶段的计算流程,和一般的神经网络没有区别。
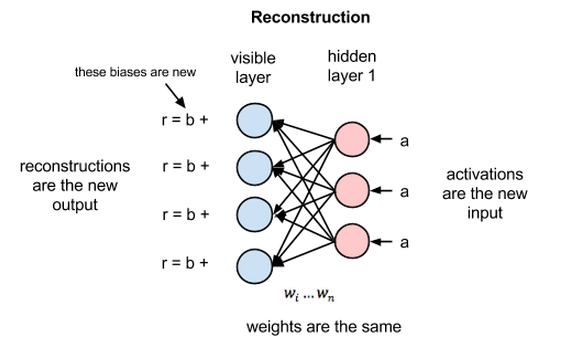
在重构阶段,第一隐藏层的激活值成为反向传递中的输入。这些输入值与同样的权重相乘,每两个相连的节点之间各有一个权重,就像正向传递中输入x的加权运算一样。这些乘积的和再与每个可见层的偏差相加,所得结果就是重构值,亦即原始输入的近似值。
由于RBM权重初始值是随机决定的,重构值与原始输入之间的差别通常很大。可以将r值与输入值之差视为重构误差,此误差值随后经由反向传播来修正RBM的权重,如此不断反复,直至误差达到最小。
由此可见,RBM在正向传递中使用输入值来预测节点的激活值,亦即输入为加权的x时输出的概率:\(p(a\mid x; w)\)。
但在反向传递时,激活值成为输入,输出的是对于原始数据的重构值,或者说猜测值。此时RBM则是在尝试估计激活值为a时输入为x的概率,激活值的加权系数与正向传递中的权重相同。 第二个阶段可以表示为\(p(x\mid a; w)\)。
上述两种预测值相结合,可以得到输入x和激活值a的联合概率分布,即\(p(x, a)\)。
重构与回归、分类运算不同。回归运算根据许多输入值估测一个连续值,分类运算是猜测应当为一个特定的输入样例添加哪种具体的标签。
而重构则是在猜测原始输入的概率分布,亦即同时预测许多不同的点的值。这被称为生成学习,必须和分类器所进行的判别学习区分开来,后者是将输入值映射至标签,用直线将数据点划分为不同的组。
RBM用KL散度来衡量预测的概率分布与输入值的基准分布之间的距离。
最后一点:你会发现RBM有两个偏差值。这是RBM与其他自动编码器的区别所在。隐藏的偏差值帮助RBM在正向传递中生成激活值(因为偏差设定了下限,所以无论数据有多稀疏,至少有一部分节点会被激活),而可见层的偏差则帮助RBM通过反向传递学习重构数据。
权重能够近似模拟出数据的特征后,也就为下一步的学习奠定了良好基础,比如可以在随后的有监督学习阶段使用深度置信网络来对图像进行分类。
RBM有许多用途,其中最强的功能之一就是对权重进行合理的初始化,为之后的学习和分类做好准备。从某种意义上来说,RBM的作用与反向传播相似:让权重能够有效地模拟数据。可以认为预训练和反向传播是实现同一个目的的不同方法,二者可以相互替代。

您的打赏,是对我的鼓励
