DL » 深度学习(二十三)——MemNet, RDN, ShuffleSeg, SVDF, LCNN, Image Caption Generation
2017-11-25 :: 6271 WordsDemosaicNet(续)
和之前的网络不同,DemosaicNet的输入是原始的Bayer Array数据,而输出是处理好的图片。
由于并没有那么多图片的Bayer Array数据,因此通常的做法是使用HR图片经采样得到Bayer Array数据。
注意,如果训练数据有原始的Bayer Array的Raw data,那是最好的。降采样或者Raw data的RGB化,都有一定的高频信号的损失。
DemosaicNet的设计借鉴了ResNet的Skip Connection的方案,只不过使用Concat代替了ResNet的Add操作而已。
这里再额外补充两点:
1.Demosaic处理不当,会导致如下问题:

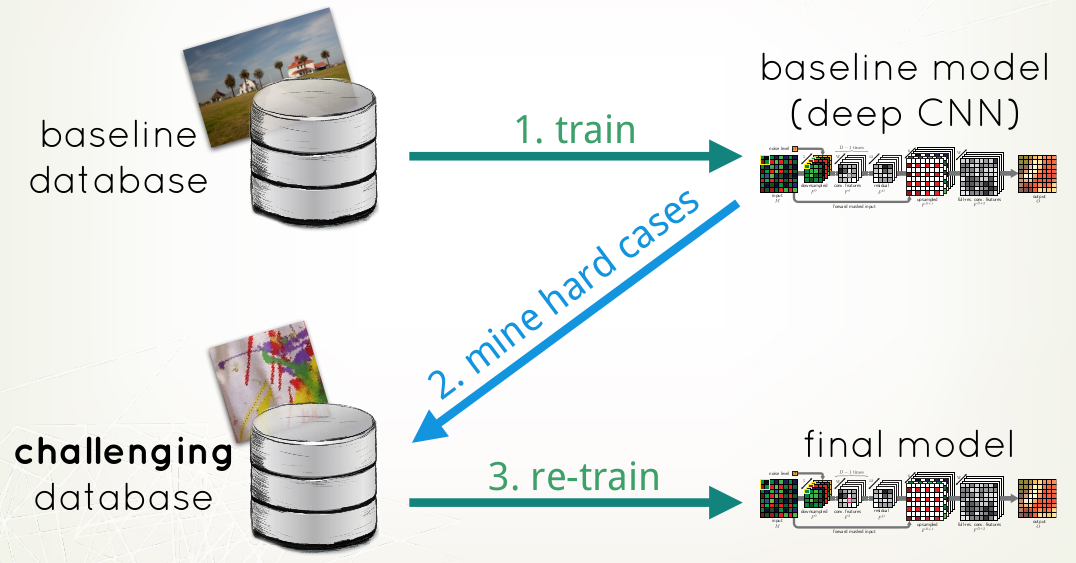
2.将出错的mine hard case,进行retrain,可以有效的提升模型的效果。
MemNet
MemNet是南京理工大学的作品。
论文:
《MemNet: A Persistent Memory Network for Image Restoration》
代码:
https://github.com/tyshiwo/MemNet
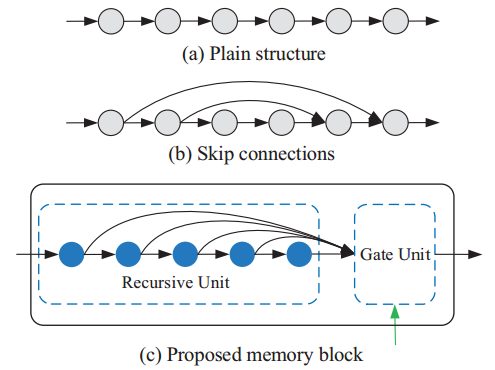
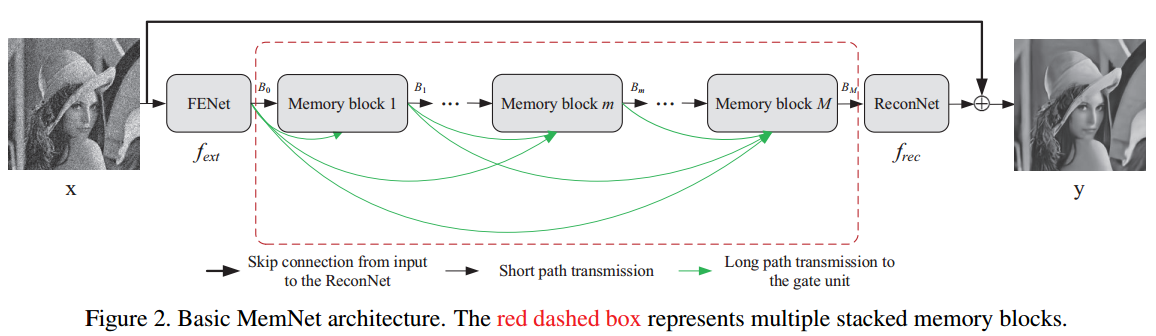
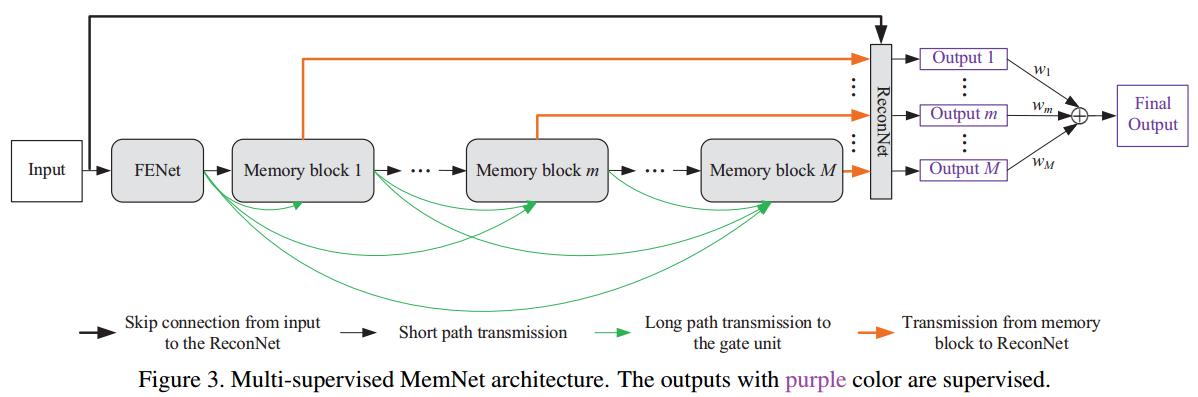
没啥好讲的,无非RNN和Resnet在原理上是等价的而已。结构上和DRCN几乎一样,不知道谁抄谁。。。
参考:
https://mp.weixin.qq.com/s/KxQ-GRnEYEdmS2H-DHIHOg
南京理工大学ICCV 2017论文:图像超分辨率模型MemNet
RDN
Residual Dense Network是美国东北大学的张宇伦的作品。
Yulun Zhang,西安电子科技大学本科(2013年)+清华硕士(2017年),现为博士一年级。
个人主页:
http://yulunzhang.com/
论文:
《Residual Dense Network for Image Super-Resolution》
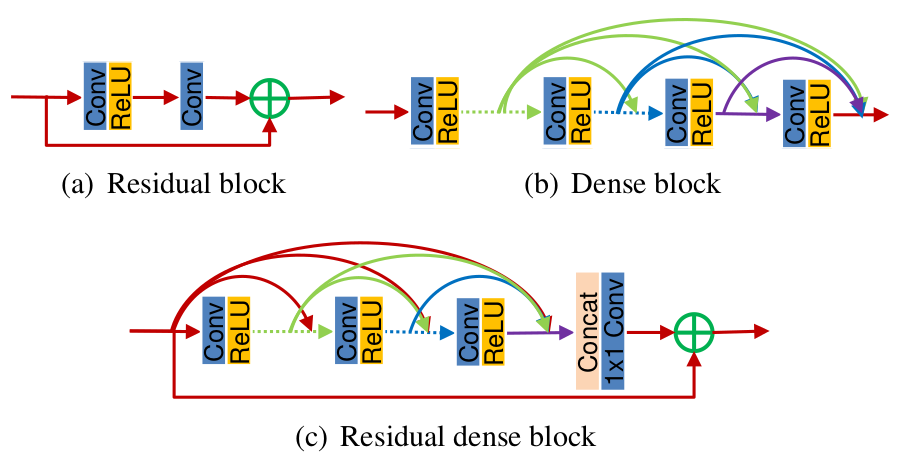
该论文在比较Residual block和Dense block的基础之上,提出了Residual dense block。
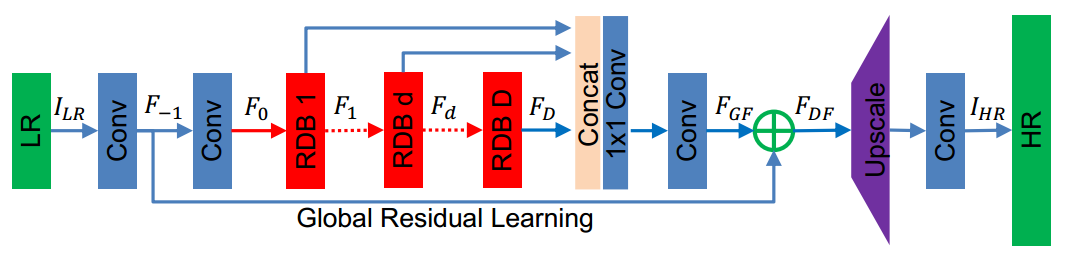
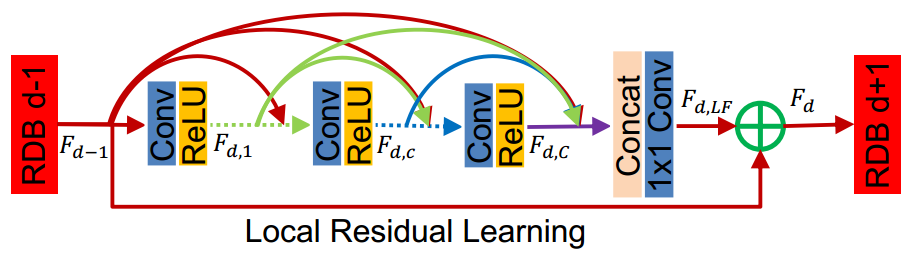
中规中矩的论文吧,熟悉Residual block和Dense block的人应该能秒懂,不多说了。
这类基本结构的SR应用除了MemNet和RDN之外,还有更早的SRResnet和SRDensenet,光听名字估计就知道是怎么回事了,灌水利器啊!
参考:
https://mp.weixin.qq.com/s/_r3MKxMTIR856ezEozFOGA
残差密集网络:利用所有分层特征的图像超分辨率网络
ShuffleSeg
ShuffleSeg是开罗大学的Mostafa Gamal和Mennatullah Siam的作品(2018.3)。看名字应该是阿拉伯人,而且一男一女。
论文:
《ShuffleSeg: Real-time Semantic Segmentation Network》
代码:
https://github.com/MSiam/TFSegmentation
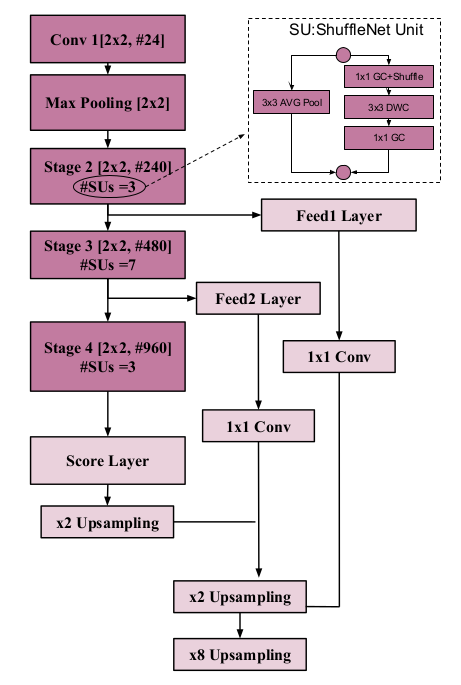
这是一个语义分割的网络,本来不该放在这里。然而既然要灌水,那就灌的更猛一些吧。ShuffleNet也难逃毒手。
参考:
https://mp.weixin.qq.com/s/W2reKR5prcf3_DMp53-2yw
新型实时形义分割网络ShuffleSeg:可用于嵌入式设备
SVDF
SVDF是UCB和Google Speech Group的作品,主要用于简化Speech模型的计算量。
论文:
《Compressing Deep Neural Networks using a Rank-Constrained Topology》
代码:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/speech_commands/models.py
音频数据通常是一个[time, frequency]的二维tensor,直接放入FC网络,会导致较大的计算量。(下图左半部分所示)
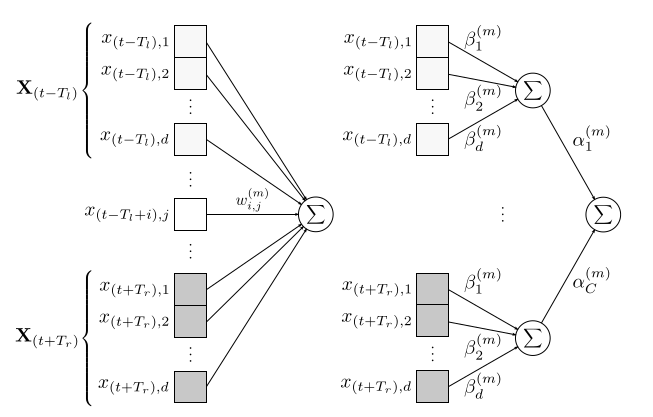
SVDF将每个time的frequency作为一组,进行FC之后,再和其他组的结果进一步FC。上图右半部分所示的是time的filters为1的时候的SVDF。当然filters也可以为其他值,和CNN类似,filters越多,提取的特征越多。
从原理来说,SVDF相当于用两层FC来拟合1层FC,即:
\[w_{i,j}^{(m)}\approx \alpha_i^{(m)}\beta_i^{(m)}\]SVDF将运算量从\(Cd\)变为\((C+d)k\),这里的k为filters numbers。
这实际上就是2维tensor的SVD,只不过SVD是线性变换,而这里是非线性变换而已。(参见《机器学习(十六)》中的ALS算法部分)
实际上,SVDF和《深度目标检测(三)》中提到的Fast R-CNN的FC加速,原理是基本一致的。
LCNN
LCNN是华盛顿大学和Allen AI研究所的作品。后者是微软创始人Paul Allen投资兴建的研究机构。
论文:
《LCNN: Lookup-based Convolutional Neural Network》
代码:
https://github.com/hessamb/lcnn
我们知道一个Conv层的weight是一个\(n\times m\times k_w \times k_h\)的tensor,这里的m,n分别是input和output的channel数,\(k_w,k_h\)则是kernel的宽和高。
LCNN将这个巨大的weight tensor拆解成若干小tensor的运算:
1.建立一个包含k个\(m\times k_w \times k_h\)大小的tensor的字典D。
2.一个用于选择字典条目的矩阵I。
3.权值矩阵C。
然后按照下图所示的方法,计算得到W:
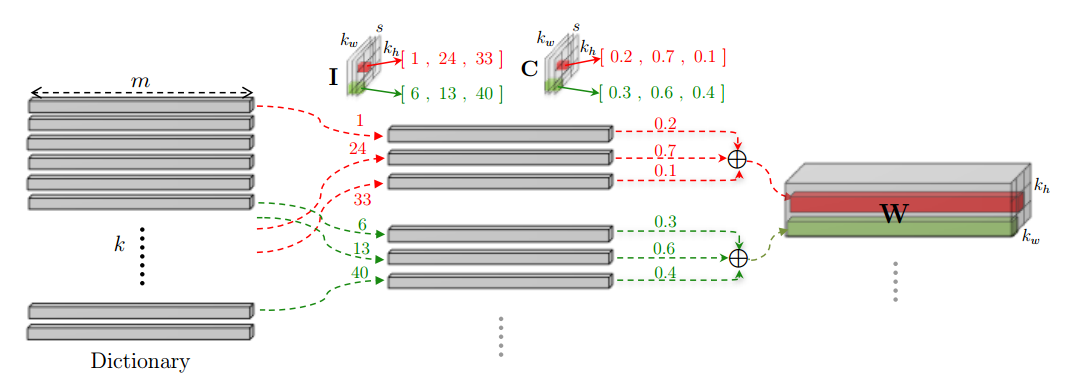
用数学公式表示,则为:
\[W_{[:,r,c]}=\sum_{t=1}^sC_{[t,r,c]}\cdot D_{[I_{[t,r,c]},:]},\forall r,c\]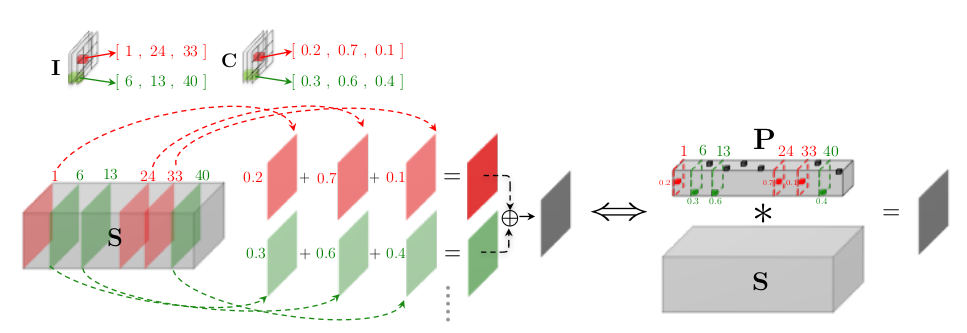
上图是LCNN的前向运算示意图,其中:
\[S_{[i,:,:]}=X*D_{[i,:]}\]这个过程实际上等效于\(S*P\),而参数P就是我们需要训练的模型参数。
可以看出LCNN和SVDF都是采用稀疏表示的方法来减少运算量,只是实现方式和用途略有不同而已。
参考:
http://blog.csdn.net/feynman233/article/details/69785592
LCNN论文阅读笔记
Image Caption Generation
Image Caption Generation的目标是:给定一张图片,让计算机用一句话来描述这张图片。如果将这里的Image换成Video,那就是Video Caption Generation了。
当然,它也有反操作:Generating Image/Videos from Captions。
参考:
http://geek.csdn.net/news/detail/97193
李理:从Image Caption Generation理解深度学习(part I)
http://geek.csdn.net/news/detail/98776
李理:从Image Caption Generation理解深度学习(part II)
https://mp.weixin.qq.com/s/i4zL-bPaPXUlwpKZzlRtcg
Image Captioning36页最新综述
https://zhuanlan.zhihu.com/p/30893160
CVPR2017 Image Caption有关论文总结
https://mp.weixin.qq.com/s/4IX6vc0Fk9TPofhTI5Gi-Q
从视觉到文本: 图像描述生成的研究进展综述
https://mp.weixin.qq.com/s/3l4mYVSVfjFS_06j3OvX8g
阿里提出新图像描述框架,解决梯度消失难题
https://mp.weixin.qq.com/s/O1LqJftEezBuuA8JHeqMzw
基于对比学习的Image Captioning
https://mp.weixin.qq.com/s/-K3WIo64_wJb9p6C49Z5fA
基于属性学习和额外知识库的图像描述生成和视觉问答
https://mp.weixin.qq.com/s/CBqDR7JEPfhIwTc8BDdeoQ
“诗画合一”的跨媒体理解与检索
https://mp.weixin.qq.com/s/vRHA3Hf1ivsgKBB2XuECNg
李飞飞论文:神经网络是怎样给一幅图增加文字描述,实现“看图说话”的?
https://mp.weixin.qq.com/s/DXRiGSI0p8u7yA9uW1hHxA
最新四篇CVPR2018 视频描述生成相关论文—双向注意力、Transformer、重构网络、层次强化学习
https://mp.weixin.qq.com/s/bDLVD_8LscgWSNp0ZNc0Pg
图像和文本的融合表示学习——Text2Image和Image2Text
https://mp.weixin.qq.com/s/oV8gcKqmp43EBYzQhr5S6w
逆视觉问答任务:一种根据回答与图像想问题的模型
https://mp.weixin.qq.com/s/YgYod-gcFZruEGtE4wF87w
牛津大学提出全新生成式模型“SQAIR”,用于移动目标的视频理解
https://mp.weixin.qq.com/s/eBNoTDOMLlVymiU3LUqSgQ
用Attention模型自动生成图像字幕
https://mp.weixin.qq.com/s/4wuYNYGDesNgsJ13y65XQA
AI都可以将文字轻松转成图像
https://mp.weixin.qq.com/s/TtU0R8P-YIq8JOJrgHP07w
Facobook开源视觉问答VQA框架:Pythia
https://mp.weixin.qq.com/s/a0Xt_hkcW2OVlEzhQFWugg
由浅及深,细致解读图像问答 VQA 2018 Challenge冠军模型Pythia
https://zhuanlan.zhihu.com/p/35305264
一文看懂深度学习中的VQA(视觉问答)技术
https://mp.weixin.qq.com/s/shBHKh2emSIL5uWV7po8cw
梅涛:“看图说话”
https://mp.weixin.qq.com/s/BQy3qpmQqeQquhf92hwcvQ
2017 VQA Challenge第一名技术报告
https://mp.weixin.qq.com/s/0yb-YRGe-q4-vpKpuE4D_w
多种注意力机制互补完成VQA(视觉问答)
https://mp.weixin.qq.com/s/YBaELQlBHOZTGEqc2WI9NQ
MIT等提出NS-VQA:结合深度学习与符号推理的视觉问答
https://mp.weixin.qq.com/s/gaNSQ_8JGqX4a3lGuf-9fA
如何让电脑成为看图说话的高手?
https://mp.weixin.qq.com/s/-b8FuEQlpEb5G0L0QAxVEA
如何使用深度学习为照片自动生成文本描述
https://zhuanlan.zhihu.com/p/50784504
《Reconstruction Network for Video Captioning》阅读笔记
https://mp.weixin.qq.com/s/tEzZ770T1NpYLAxUK-MwIg
综述:Image Caption 任务之语句多样性
https://zhuanlan.zhihu.com/p/53220566
《Adaptive Co-Attention Network for NER in Tweet》阅读笔记
https://mp.weixin.qq.com/s/sQoqt-7EqZmy5gvIWTtMKQ
更有智慧的眼睛:图像描述(Image Caption)&视觉问答(VQA)综述(上)
https://mp.weixin.qq.com/s/3Y5f7JsxsmmuCjAX625h1Q
MirrorGAN出世!浙大等提出文本-图像新框架
https://mp.weixin.qq.com/s/1rtONnhwEc3Osf9gP5fBCQ
李飞飞CVPR最新论文“文本转图”效果优化可多一步:物体关系描述
https://mp.weixin.qq.com/s/9XiAJzC2_vmZturE9ELVLA
多级语言与视觉集成用于文本-剪辑检索
https://mp.weixin.qq.com/s/UehKCDiBRnjZWLEcx_iU-g
微软最新提出ObjGAN,输入一句话秒生成图片
https://mp.weixin.qq.com/s/p8K4eixOwCiUkhzntKYa-Q
视觉问答:VQA经典模型Up-Down以及VQA 2017challenge 冠军方案解读
https://mp.weixin.qq.com/s/hGaX4I_WsPv9P_WAHaDuog
NLP+CV《桥接视觉与语言的研究综述》,带你全面了解视觉+语言最新应用和方法
https://mp.weixin.qq.com/s/XrElAz67uxEo-1zEea9dxA
Video Description视频描述综述论文-方法、数据集和评估指标,UWA
https://mp.weixin.qq.com/s/rbqsBrVBs374GipQ2QXUwg
看图说话之随心所欲
https://mp.weixin.qq.com/s/St6ndWeW9P1vvnhNBF4Nyw
使用神经网络为图像生成标题
https://mp.weixin.qq.com/s/-g5opYPyM488Fit5fP5Y_Q
图像描述生成研究进展
https://mp.weixin.qq.com/s/7mr6nGaADsc450Q0iHauxw
最新《图像描述Image Captioning》综述论文,22页pdf
LSM
liquid state machine (LSM)
http://www.docin.com/p-390935406.html
基于液体状态机的脑运动神经系统的建模研究
DNC
https://zhuanlan.zhihu.com/p/27773709
浅析至强RNN可微分神经计算机(DNC)
https://zhuanlan.zhihu.com/p/27964341
浅析至强RNN可微分神经计算机(DNC)-2
https://zhuanlan.zhihu.com/p/28209628
DNC-3滚动分类的模式识别
https://zhuanlan.zhihu.com/p/28433712
DNC4广义线性回归

您的打赏,是对我的鼓励
