DL » 深度学习(十九)——LSTM进阶
2017-10-10 :: 7220 Words- 无监督/半监督/自监督深度学习(续)
- LSTM进阶
- 《Long short-term memory》
- 《LSTM Neural Networks for Language Modeling》
- 《Sequence to Sequence - Video to Text》
- 《Long-term Recurrent Convolutional Networks for Visual Recognition and Description》
- 《Training RNNs as Fast as CNNs》
- 《Neural Machine Translation in Linear Time》
- 《Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition》
- Android NN
- 《On the compression of recurrent neural networks with an application to lvcsr acoustic modeling for embedded speech recognition》
无监督/半监督/自监督深度学习(续)
https://mp.weixin.qq.com/s/6qqFAQBaOFuXtaeRSmQgsQ
一文梳理2020年大热的对比学习模型
https://mp.weixin.qq.com/s/SeAZERYdfqDbtqTLnuWfGg
盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSiam
https://mp.weixin.qq.com/s/jHVg-BMRRVNjAf6ZFEoPxQ
自监督学习的SimCLRv2框架
https://mp.weixin.qq.com/s/7iBC_n6EARW3V8bNuKUqQA
Hinton团队力作:SimCLR系列
https://mp.weixin.qq.com/s/sH-G4g0EyQLu2l91Xvdefw
Neighbor2Neighbor:无需干净图像的自监督图像降噪
https://mp.weixin.qq.com/s/xYlCAUIue_z14Or4oyaCCg
对比学习研究进展精要
https://mp.weixin.qq.com/s/VlSoMmAGDblQ2UYhLD96gA
什么是contrastive learning?
https://mp.weixin.qq.com/s/qnG0YLf0yjs4aT9URRMDyw
有监督对比学习的一个简单的例子
https://mp.weixin.qq.com/s/h8loG3enT5U-5F2a2UflJg
对比学习小综述
https://mp.weixin.qq.com/s/v5p9QA3vDl-WTF3-7shp4g
对比学习简述
https://mp.weixin.qq.com/s/CeqoXqHjfa6UTWa8mmo_Ww
Paper和陈丹琦撞车是一种怎样的体验(ConSERT vs. SimCSE)
https://mp.weixin.qq.com/s/C4KaIXO9Lp8tlqhS3b0VCw
美团提出基于对比学习的文本表示模型(ConSERT)
参考
https://mp.weixin.qq.com/s/sDkGAhnFC027XjpUImeatw
自监督、半监督、无监督学习,傻傻分不清楚?最新综述来帮你!
https://mp.weixin.qq.com/s/L4GQF0eE7MjLPrb8UygCww
无监督深度学习全景教程(193页PDF)
https://mp.weixin.qq.com/s/kbqTHIOzAj1aERl4tm-kVA
2017上半年无监督特征学习研究成果汇总
https://mp.weixin.qq.com/s/J50L6hESBROfT8IIAnofQQ
Yan LeCun109页最新报告:图嵌入, 内容理解,自监督学习
https://mp.weixin.qq.com/s/s440gdbUhLP41rLPjfgsmQ
Yann Lecun自监督学习指南(附114页Slides全文下载)
https://mp.weixin.qq.com/s/foP1xSa5G8oNtAv_pI6AqQ
深度神经网络自监督视觉特征学习综述
https://mp.weixin.qq.com/s/sEHA6fb0XIXQWsmJGf3fTA
DeepMind发布自监督学习最新教程,附122页全文资料下载
https://mp.weixin.qq.com/s/-JoB1MJ0ZpkYLlToS7-AOA
牛津大学&DeepMind:自监督学习教程,141页ppt
https://mp.weixin.qq.com/s/HfqH-b8x8SsE6zb8pcF3Og
自监督学习(Self-Supervised Learning) 2018-2020年发展综述
https://mp.weixin.qq.com/s/2Wm6eQodwlc5XkjGKqhwCg
南京大学周志华教授综述论文:弱监督学习
https://mp.weixin.qq.com/s/_3DqXBpZhstVv6BkBR4oag
自监督学习综述
https://mp.weixin.qq.com/s/aCWAU2RXk9fTzfFqOyjqUw
能自主学习的人工突触,为无监督学习开辟新的路径
https://mp.weixin.qq.com/s/qaLQK3uzaeyp68AbL0aOOQ
怎么在视频标注上省钱?这里有一个面向视频推荐的多视图主动学习
https://mp.weixin.qq.com/s/-cXOUw9zJteVUkbpRMIWtQ
何恺明一作,刷新7项检测分割任务,无监督预训练完胜有监督
https://mp.weixin.qq.com/s/wtHrHFoT2E_HLHukPdJUig
OpenAI科学家一文详解自监督学习
https://mp.weixin.qq.com/s/fy1gUElWVWcOVvzv6fGmdg
谷歌大脑推出视觉领域任务自适应基准:VTAB
https://zhuanlan.zhihu.com/p/80815225
Image-Level弱监督图像语义分割汇总简析
https://mp.weixin.qq.com/s/5czWf0xpqva5pmuvJDn5AQ
Google研究院提出FixMatch,简单粗暴却极其有效的半监督学习方法,附14页PDF下载
https://zhuanlan.zhihu.com/p/108088719
SSL:Self-Supervised Learning(自监督学习)
https://zhuanlan.zhihu.com/p/108625273
Self-Supervised Learning入门介绍
https://zhuanlan.zhihu.com/p/108906502
Self-supervised Learning再次入门
https://mp.weixin.qq.com/s/VvUj0S2OTf8BowGRjDuVag
图解自监督学习,人工智能蛋糕中最大的一块
https://mp.weixin.qq.com/s/df51T24mBVycBeI_M7QqOQ
无标记数据学习, 83ppt
https://mp.weixin.qq.com/s/2FxD6ga6b_WOdAni16wd2Q
自监督学习在计算机视觉应用最新概述,108页ppt Self-supervised learning
https://mp.weixin.qq.com/s/3kwLoojFjJoPz4pUuEVA8g
神奇的自监督场景去遮挡
https://mp.weixin.qq.com/s/eROWWPQkUs91bcv4VsQqSA
NLP中的自监督表示学习,全是动图,很过瘾的
https://mp.weixin.qq.com/s/IsLlzDWnUXe8LVp4Y1Jb_A
35亿张图像!Facebook基于弱监督学习刷新ImageNet基准测试记录
https://mp.weixin.qq.com/s/TEk_i4kEjUqmAqF8LgTVjg
FAIR提出用聚类方法结合卷积网络,实现无监督端到端图像分类
https://mp.weixin.qq.com/s/dSncg1pDHpIFOT4mXrFntA
Yan Lecun自监督学习:机器能像人一样学习吗? 110页PPT
https://mp.weixin.qq.com/s/W4zwKqkVQN4v-IKzGrkudg
通过传递不变性实现自监督视觉表征学习
https://zhuanlan.zhihu.com/p/30265894
自监督学习近期进展
https://mp.weixin.qq.com/s/qyQjKsgktWv9SihotaQX3w
从顶会看自监督学习最新研究进展
LSTM进阶
《Long short-term memory》
这是最早提出LSTM这个概念的论文。这篇论文偏重数学推导,实话说不太适合入门之用。但既然是起点,还是有列出来的必要。
《LSTM Neural Networks for Language Modeling》
这也是一篇重要的论文。
《Sequence to Sequence - Video to Text》
https://vsubhashini.github.io/s2vt.html
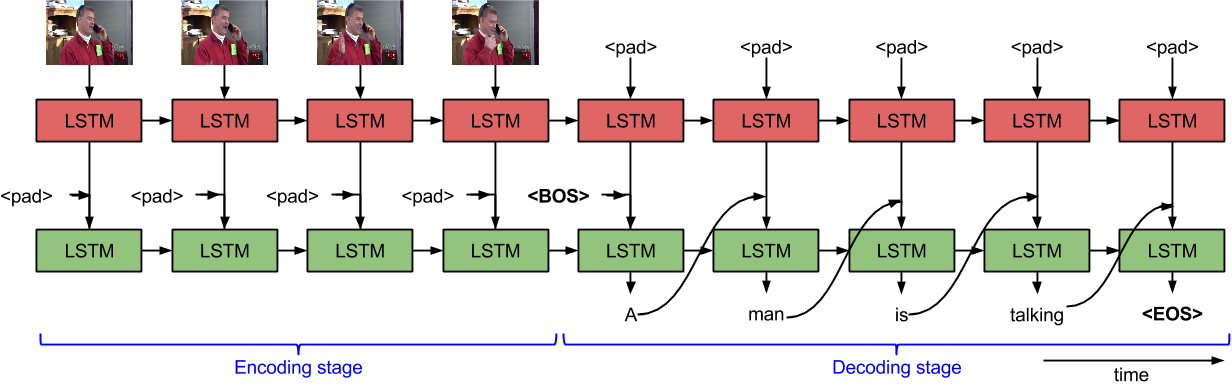
参考:
https://mp.weixin.qq.com/s/HqffHVMKJkA6H1E9ItQU4A
《sequence to sequence: video to text》视频描述的全文翻译
《Long-term Recurrent Convolutional Networks for Visual Recognition and Description》
Long-term Recurrent Convolutional Networks是LSTM的一种应用方式,它结合了LSTM、CNN、CRF等不同网络组件。
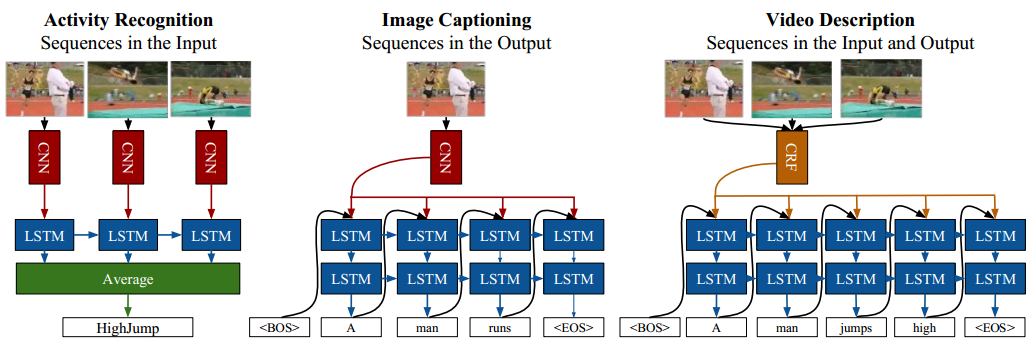
上图展示了LSTM在动作识别、图片和视频描述等任务中的网络结构。
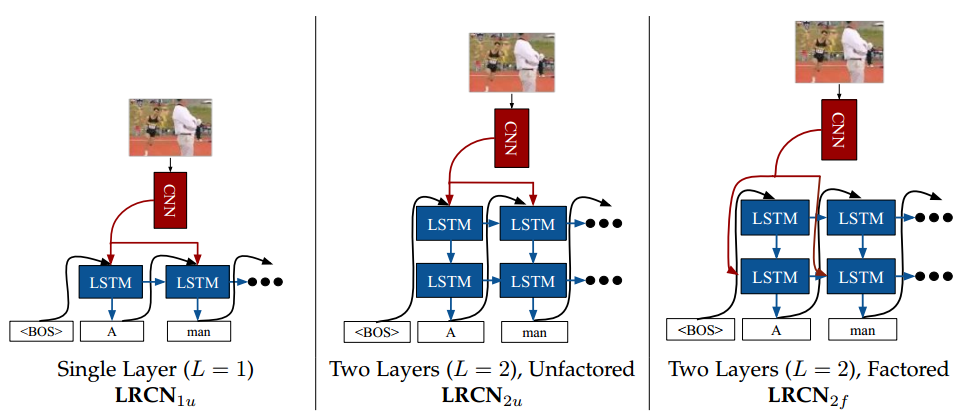
上图展示了图片描述任务中几种不同的网络连接方式:
1.单层LRCN。
2.双层LRCN。CNN连接在第一个LSTM层。传统的LSTM只有一个输入,这里的CNN是第二个输入,也就是所谓的静态输入。可参看caffe的LSTM实现。
2.双层LRCN。CNN连接在第二个LSTM层。
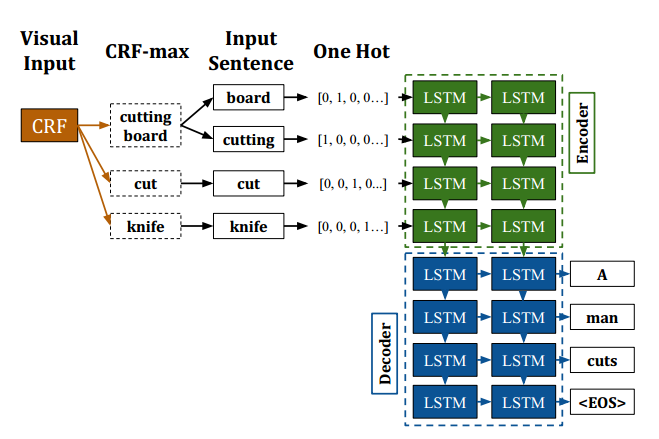
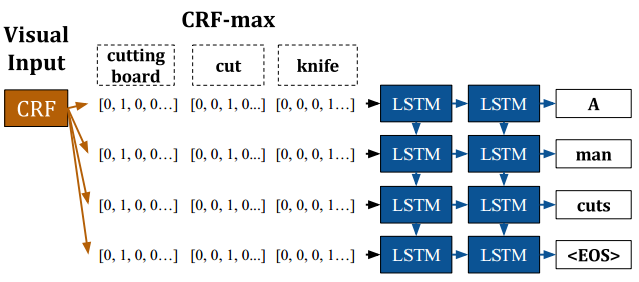
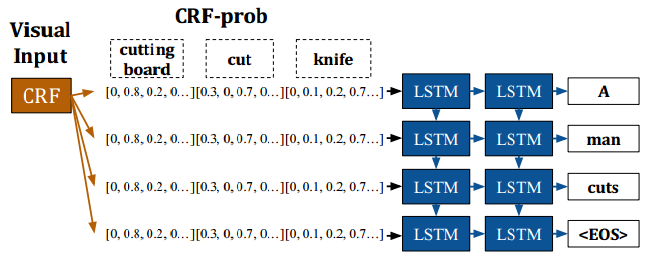
这是视频描述任务中LSTM和CRF结合的示例。
《Training RNNs as Fast as CNNs》
这篇论文提出了如下图所示的Simple Recurrent Unit(SRU)的新结构:
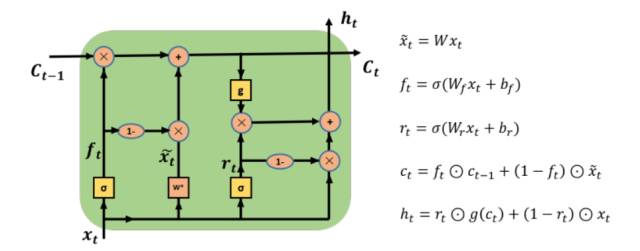
由于普通LSTM计算步骤中,很多当前时刻的计算都依赖\(h_{t-1}\)的值,导致整个网络的计算无法并行化。SRU针对这一点去掉了当前时刻计算对于\(h_{t-1}\)的依赖,而仅保留\(C_{t-1}\)(这个计算较为廉价)以记忆信息,大大改善了整个RNN网络计算的并行性。
但是SRU的精度没有LSTM高,需要通过增加layer和filter的数量来达到相同的精度,当然即使这样,计算时间仍然小于LSTM。
参考:
https://mp.weixin.qq.com/s/PsIa3XDFqZlY2tKcvqvddw
Training RNNs as Fast as CNNs
《Neural Machine Translation in Linear Time》
该论文是Deepmind的作品,它提出的ByteNet,计算复杂度为线性,也是LSTM的优化方案之一。
《Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition》
\[\begin{array}\\ i_t=\delta(W_{ix}x_t+W_{im}m_{t-1}+W_{ic}c_{t-1}+b_i) \\ f_t=\delta(W_{fx}x_t+W_{fm}m_{t-1}+W_{fc}c_{t-1}+b_i) \\ c_t=f_t\odot c_{t-1}+i_t\odot g(W_{cx}x_t+W_{cm}m_{t-1}+b_c) \\ o_t=\delta(W_{ox}x_t+W_{om}m_{t-1}+W_{oc}c_{t}+b_o) \\ m_t=o_t\odot h(c_t) \\ {\color{blue}{y_t=W_{ym}m_t+b_y}} \end{array}\]上式是LSTM的公式(其中的最后一步在多数模型中,往往直接用\(y_t=m_t\)代替。),从中可以看出类似\(W_{ix}x_t+W_{im}m_{t-1}+W_{ic}c_{t-1}+b_i\)的FC运算占据了LSTM的绝大部分运算量。其中W的参数量为:
\[W={\color{blue}{n_c\times n_c\times 4}}+n_i\times n_c\times 4+{\color{red}{n_c\times n_o}}+n_c\times 3\]为了精简相关运算,Google的Hasim Sak于2014年提出了LSTMP。
Hasim Sak,土耳其伊斯坦布尔海峡大学博士,Google研究员。
LSTMP的结构图如下:
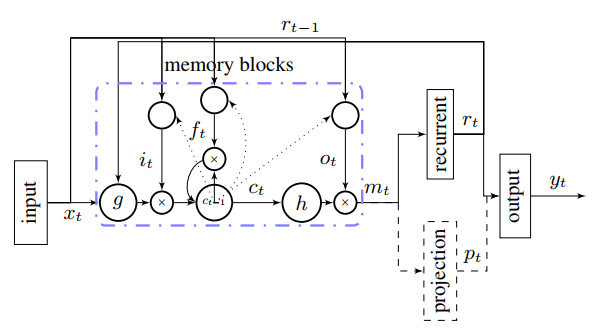
改写成数学公式就是:
\[\begin{array}\\ i_t=\delta(W_{ix}x_t+W_{im}r_{t-1}+W_{ic}c_{t-1}+b_i)\\ f_t=\delta(W_{fx}x_t+W_{fm}r_{t-1}+W_{fc}c_{t-1}+b_i)\\ c_t=f_t\odot c_{t-1}+i_t\odot g(W_{cx}x_t+W_{cm}r_{t-1}+b_c)\\ o_t=\delta(W_{ox}x_t+W_{om}r_{t-1}+W_{oc}c_{t}+b_o)\\ m_t=o_t\odot h(c_t)\\ {\color{blue}{r_t = W_{rm}m_t}}\\ {\color{blue}{p_t = W_{pm}m_t}}\\ {\color{blue}{y_t = W_{yr}r_t + W_{yp}p_t + b_y}} \end{array}\]LSTMP的主要思想是对\(m_t\)做一个映射,只有部分数据\(r_t\)参与recurrent运算,其余部分\(p_t\)直接输出即可(这一步是可选项,所以用虚框表示)。
这样W的参数量为:
\[W={\color{blue}{n_c\times n_r\times 4}}+n_i\times n_c\times 4+{\color{red}{n_r\times n_o+n_c\times n_r}}+n_c\times 3\]参数量公式用蓝色和红色标出修改前后对应的部分,可以看出计算量有了明显下降。
参考:
http://blog.csdn.net/xmdxcsj/article/details/53326109
模型压缩lstmp
Android NN
Android NN除了支持原始版本的LSTM之外,还可支持peephole、CIFG、LSTMP、Layer Normalization等变种,以及它们的组合。其公式如下:
\[\begin{eqnarray*} i_t =& \sigma(LN(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}C_{t-1})+b_i) & \\ f_t =& \sigma(LN(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}C_{t-1})+b_f) & \\ C_t =& clip(f_t \odot C_{t-1} + i_t \odot g(LN(W_{xc}x_t+W_{hc}h_{t-1})+b_c),\ t_{cell}) & \\ o_t =& \sigma(LN(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}C_t)+b_o) & \\ & & \\ & clip(W_{proj}(o_t \odot g(C_t))+b_{proj},\ t_{proj}) & if\ there\ is\ a\ projection; \\ h_t =& & \\ & o_t \odot g(C_t) & otherwise. \\ \end{eqnarray*}\]《On the compression of recurrent neural networks with an application to lvcsr acoustic modeling for embedded speech recognition》
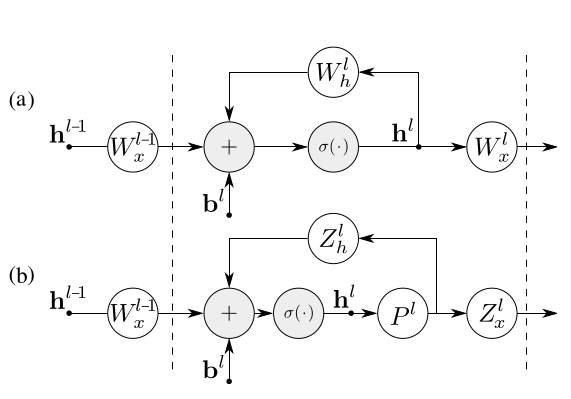
这是另一篇RNN模型压缩的论文。上图中的a是原始RNN,而b是对\(W_h^l\)使用了SVD之后的RNN。

您的打赏,是对我的鼓励
