DL » 深度学习(十六)——Style Transfer(2)
2017-09-09 :: 5563 WordsStyle Transfer
早期方法
图像风格迁移这个领域,在2015年之前,连个合适的名字都没有,因为每个风格的算法都是各管各的,互相之间并没有太多的共同之处。
比如油画风格迁移,里面用到了7种不同的步骤来描述和迁移油画的特征。又比如头像风格迁移里用到了三个步骤来把一种头像摄影风格迁移到另一种上。以上十个步骤里没一个重样的。
可以看出这时的图像风格处理的研究,基本都是各自为战,捣鼓出来的算法也没引起什么注意。
![]()
上图是一个油画风格迁移的pipe line。
在实践过程中,人们又发现图像的纹理可以在一定程度上代表图像的风格。下文如无特指,纹理/风格均为同义词。
这又引入了和风格迁移相关的另一个领域——纹理生成。这个时期,该领域虽然已经有了一些成果,但是通用性也比较差。
早期纹理生成的主要思想:纹理可以用图像局部特征的统计模型来描述。然而手工建模毕竟耗时耗力。。。
CNN的纹理特征
在进行神经风格迁移之前,我们先来从可视化的角度看一下卷积神经网络每一层到底是什么样子?它们各自学习了哪些东西。
遍历所有训练样本,找出让该层激活函数输出最大的9块图像区域;然后再找出该层的其它单元(不同的滤波器通道)激活函数输出最大的9块图像区域;最后共找9次,得到\(9 \times 9\)的图像如下所示,其中每个\(3 \times 3\)区域表示一个运算单元。
![]()
可以看出随着层数的增加,CNN捕捉的区域更大,特征更加复杂,从边缘到纹理再到具体物体。
Deep Visualization
上述的CNN可视化的方法一般被称作Deep Visualization。
论文:
《Understanding Neural Networks Through Deep Visualization》
这篇论文是Deep Visualization的经典之作。作者是Jason Yosinski。
Jason Yosinski,Caltech本科+Cornell博士。现为Uber AI Labs的科学家。
个人主页:
http://yosinski.com/
该文提出了如下公式:
\[V(F_i^l)=\mathop{\arg\max}_{X}A_i^l(X), X \leftarrow X + \eta\frac{\partial A_i^l(X)}{\partial X}\]X初始化为一张噪声图片,然后按照上述公式,优化得到激活函数输出最大的X。
Deep Visualization除了用于提取纹理之外,还可用于模型压缩。
论文:
《Demystifying Neural Network Filter Pruning》
https://github.com/yosinski/deep-visualization-toolbox
这是作者Jason Yosinski提供的Deep Visualization的工具的代码。
https://github.com/antkillerfarm/antkillerfarm_crazy/tree/master/deep-visualization-toolbox
原始版本是基于python 2编写的,这是我修改的python 3版本
https://github.com/Sunghyo/revacnn
这是另一个CNN可视化工具
参考:
https://zhuanlan.zhihu.com/p/24833574
Deep Visualization:可视化并理解CNN
http://www.cnblogs.com/jesse123/p/7101649.html
Tool-Deep Visualization
https://mp.weixin.qq.com/s/dflEAOELK0f19y4KuVd_dQ
40行Python代码,实现卷积特征可视化
https://mp.weixin.qq.com/s/fpVFpN5beJFyLW19WnBzvw
揭开黑盒一角!谷歌联合OpenAI发布“神经元显微镜”,可视化神经网络运行机制
https://mp.weixin.qq.com/s/o-MFPt6LR_5XDpacqw754Q
马里兰大学论文:可视化神经网络的损失函数
https://mp.weixin.qq.com/s/iIhiMKutVtYEUgAiErLkVQ
Deep Dream
https://mp.weixin.qq.com/s/z_n_9Z88aiFaQ35jjPMcqg
OpenAI发布“显微镜”,可视化神经网络内部结构
https://mp.weixin.qq.com/s/MFKhmHcaQvufdRawFqisjA
Distill详述“可微图像参数化“:神经网络可视化和风格迁移利器!
https://mp.weixin.qq.com/s/Tm6fTjXG_7BVc70GROPdag
TensorSpace:超酷炫3D神经网络可视化框架
https://mp.weixin.qq.com/s/dBCGxi78D3TZybRedd7XVA
最前沿的特征可视化(CAM)技术
DL方法
受到上述事实的启发,2015年德国University of Tuebingen的Leon A. Gatys写了如下两篇论文:
《Texture Synthesis Using Convolutional Neural Networks》
《A Neural Algorithm of Artistic Style》
代码:
https://github.com/jcjohnson/neural-style
torch版本
https://github.com/anishathalye/neural-style
tensorflow版本
在第一篇论文中,Gatys使用Gramian matrix从各层CNN中提取纹理信息,于是就有了一个不用手工建模就能生成纹理的方法。
Gramian matrix(由Jørgen Pedersen Gram提出)中的元素定义如下:
\[G_{ij}=\langle v_i, v_j \rangle\]这里的\(v_i\)表示向量,\(G_{ij}\)是向量的内积。可以看出Gramian matrix是一个半正定的对称矩阵。
在第二篇论文中,Gatys更进一步指出:纹理能够描述一个图像的风格。
既然第一篇论文解决了从图片B中提取纹理的任务,那么还有一个关键点就是:如何只提取图片内容而不包括图片风格?
Cost Function
神经风格迁移生成图片G的cost function由两部分组成:C与G的相似程度和S与G的相似程度。
\[J(G)=\alpha \cdot J_{content}(C,G)+\beta \cdot J_{style}(S,G)\]其中,\(\alpha, \beta\)是超参数,用来调整\(J_{content}(C,G)\)与\(J_{style}(S,G)\)的相对比重。
神经风格迁移的基本算法流程是:首先令G为随机像素点,然后使用梯度下降算法,不断修正G的所有像素点,使得J(G)不断减小,从而使G逐渐有C的内容和S的风格,如下图所示:
![]()
换句话来说就是:每次迭代只更新图片G,而不更新网络的参数。
我们先来看J(G)的第一部分\(J_{content}(C,G)\),它表示内容图片C与生成图片G之间的相似度。
使用的CNN网络是之前预训练好的模型,例如Alex-Net。C,S,G共用相同模型和参数。
首先,需要选择合适的层数l来计算\(J_{content}(C,G)\)。
如前所述,CNN的每个隐藏层分别提取原始图片的不同深度特征,由简单到复杂。如果l太小,则G与C在像素上会非常接近,没有迁移效果;如果l太深,则G上某个区域将直接会出现C中的物体。因此,l既不能太浅也不能太深,一般选择网络中间层。
若C和G在l层的激活函数输出\(a^{[l](C)}\)与\(a^{[l](G)}\),则相应的\(J_{content}(C,G)\)的表达式为:
\[J_{content}(C,G)=\frac12||a^{[l](C)}-a^{[l](G)}||^2\]接下来,我们定义图片的风格矩阵(style matrix)为:
\[G_{kk'}^{[l]}=\sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}a_{ijk}^{[l]}a_{ijk'}^{[l]}\]风格矩阵\(G_{kk'}^{[l]}\)计算第l层隐藏层不同通道对应的所有激活函数输出和。若两个通道之间相似性高,则对应的\(G_{kk'}^{[l]}\)较大。从数学的角度来说,这里的风格矩阵实际上就是两个tensor的互相关矩阵,也就是上面提到的Gram矩阵。
Gram矩阵描述的是全局特征的自相关,如果输出图与风格图的这种自相关相近,那么差不多是我们所理解的”风格”。当然,其实也可以用很多其他的统计信息进行描绘风格。比如有用直方图的, 甚至还可以直接简化成”均值+方差”的。
风格矩阵\(G_{kk'}^{[l][S]}\)表征了风格图片S第l层隐藏层的“风格”。相应地,生成图片G也有\(G_{kk'}^{[l][G]}\)。那么,\(G_{kk'}^{[l][S]}\)与\(G_{kk'}^{[l][G]}\)越相近,则表示G的风格越接近S。这样,我们就可以定义出\(J^{[l]}_{style}(S,G)\)的表达式:
\[J^{[l]}_{style}(S,G)=\frac{1}{(2n_H^{[l]}n_W^{[l]}n_C^{[l]})}\sum_{k=1}^{n_C^{[l]}}\sum_{k'=1}^{n_C^{[l]}}||G_{kk'}^{[l][S]}-G_{kk'}^{[l][G]}||^2\]为了提取的“风格”更多,也可以使用多层隐藏层,然后相加,表达式为:
\[J_{style}(S,G)=\sum_l\lambda^{[l]}\cdot J^{[l]}_{style}(S,G)\]实现细节
![]()
这是原始论文的插图,其符号表示和本文有所差异。其中的A、F、P各层的output,都是使用预训练好的Alex-Net生成的。
可以看出A和P,在整个迭代过程中,只需要进行一次Alex-Net的前向计算,因此可以事先计算好。
为了在迭代过程中,不修改Alex-Net的权重,而只修改F,我们可以使用tf.constant来创建Alex-Net的各个参数,进而建立Alex-Net。这样在backward的时候,梯度就只会修正到tf.Variable,也就是F上。
缺点
Gatys的方法虽然是里程碑式的进步,但仍然有如下缺点:
1.渲染速度缓慢。渲染一张图片需要从随机噪声开始,反复迭代若干次,才能得到最终的结果。
2.需要根据风格的不同,调整不同的超参数。换句话说,就是一个Style Transfer的模型就只能用于转换一种Style,通用型不强。
因此,之后的研究主要集中在对这两方面的改进上。针对前者的改进可称作fast style transfer,而后者可称作Universal Style Transfer。
此外,不是所有的style transfer都是DL方法,很多新特效往往还是用传统的滤镜实现的。比如最近比较火的“新海诚风格”。
参考:
https://blog.csdn.net/Trent1985
一个滤镜/美颜方面的blog
https://www.zhihu.com/question/29594460
新海诚风格的画面是手绘的还是Photoshop就可以达到的?后期过程是怎样的?
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
这篇论文属于fast style transfer类的改进。它是Skolkovo Institute of Science and Technology & Yandex的Dmitry Ulyanov的作品。
Dmitry Ulyanov的个人主页:
https://dmitryulyanov.github.io
Skolkovo位于莫斯科郊外,相当于俄国的硅谷。
代码:
https://github.com/DmitryUlyanov/texture_nets
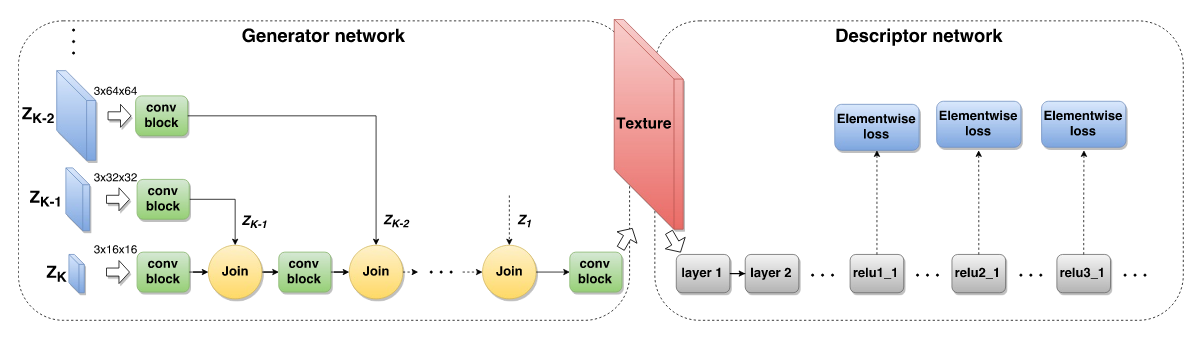
上图是该论文提出的网络结构,其中包括了两个部分:
1.descriptor network(以下简称D网络)。这部分的使用方法和Gatys方法基本一致:风格图片过一下预训练好的Alex-Net来生成纹理特征P。
2.论文的主要创新点在于generator network(以下简称G网络)。
1)假设有一批图片A,通过G网络得到了风格图片G(A)。
2)G(a)和a做比较得到content loss,G(A)和P做比较得到style loss。
3)迭代优化上述两个loss,得到训练好的G网络。
4)Inference时,直接将图片a输入G网络,就得到了风格变换后的图片G(a)。

您的打赏,是对我的鼓励
