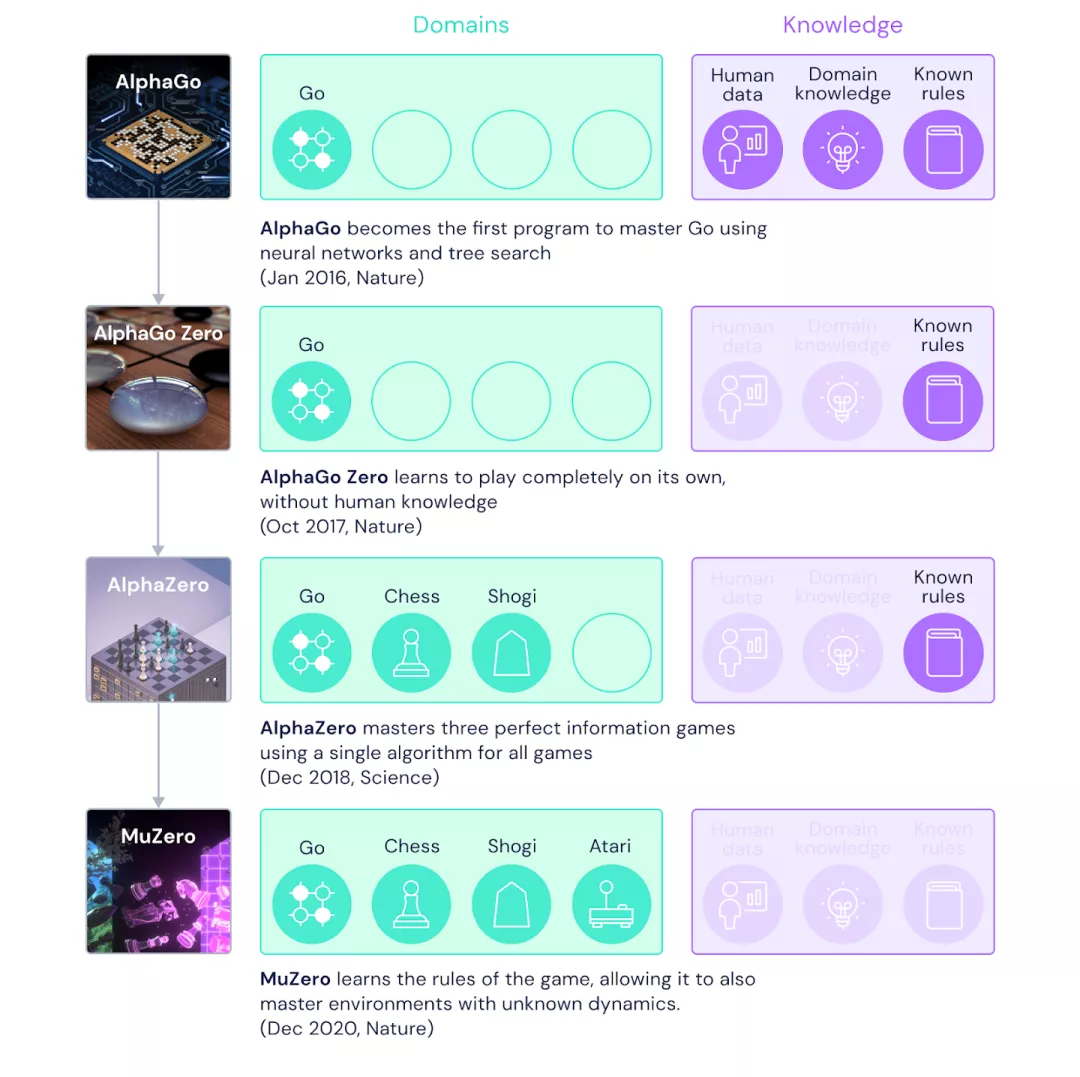
DRL » 深度强化学习(六)——AlphaGo(2)
2019-10-08 :: 5501 WordsAlphaGo
AlphaGo(续)
Policy Network
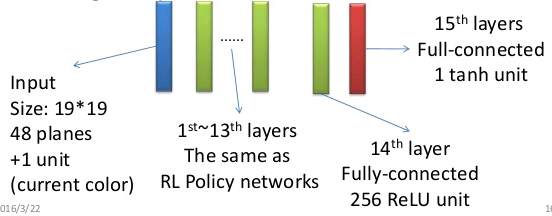
上图是AlphaGo的Policy Network的网络结构图。
从结构来看,它与DarkForestGo是十分类似的:
-
都是1层5x5的conv+k层3x3的conv。
-
两者的input plane都是手工构建的特征。
-
由于棋子的精确位置很重要,这些CNN中都没有pooling。
它们的差异在于:
- DarkForestGo训练时,会预测三步而非一步,提高了策略输出的质量。
Policy Network摆脱了之前的基于规则的围棋软件,长于局部,但大局较差的弱点,它的大局观非常强,不会陷入局部战斗中。例如,DarkForestGo的走棋网络直接放上KGS就有3d的水平。
它的缺点是:会不顾大小无谓争劫,会无谓脱先,不顾局部死活,对杀出错,等等。有点像高手不经认真思考的随手棋——只有“棋感”,而没有计算。(其实更类似于计算力衰退的老棋手,比如聂棋圣。)
Value Network
AlphaGo的Value Network是一个和Policy Network几乎一样的深度卷积网络。
Fast rollout
有了走棋网络,为什么还要做快速走子呢?
-
走棋网络的运行速度是比较慢的(3毫秒),而快速走子能做到几微秒级别,差了1000倍。
-
快速走子可以用来评估盘面。由于天文数字般的可能局面数,围棋的搜索是毫无希望走到底的,搜索到一定程度就要对现有局面做个估分。在没有估值网络的时候,不像国象可以通过算棋子的分数来对盘面做比较精确的估值,围棋盘面的估计得要通过模拟走子来进行,从当前盘面一路走到底,不考虑岔路地算出胜负,然后把胜负值作为当前盘面价值的一个估计。显然,如果一步棋在快速走子之后,生成的N个结果中的胜率较大的话,那它本身是步好棋的概率也较大。
为了速度快,Fast rollout没有使用神经网络,而是使用传统的局部特征匹配(local pattern matching)加线性回归(logistic regression)的方法。
这种方法虽然没有NN这么强,但还是比更为传统的基于规则的方案适应性好。毕竟规则是死的,而传统的机器学习,再怎么说也是可以自动学习规则的。当然,这更比随机走子的效率高了。
DarkForestGo的走子基于规则模板,且没有快速走子,个人以为这才是它棋力差的主要原因。
由于Fast rollout既可以提供策略,又有一定的价值评估的手段,因此单独使用它,比单独使用Policy Network或者Value Network都要好。相当于是一个劣化版本的AlphaGo。
MCTS
AlphaGo的MCTS使用的是传统的UCT算法,没太多好讲的。一个细节是Game Tree的结点并不是立即展开,而是要等到路过该结点的次数超过一定阈值,才进行展开,从而大大减小了搜索空间。
其他关键点
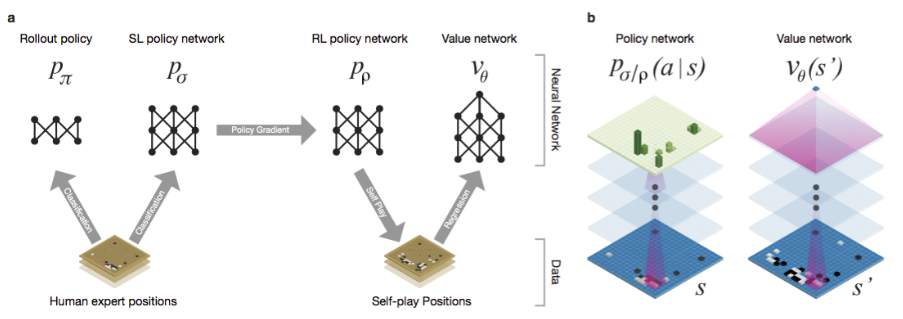
AlphaGo不是一个纯粹的DRL,它还是使用了人类棋谱的先验数据。
-
首先,从人类棋谱中学习rollout策略,并初始化Policy Network。
-
然后,使用自我博弈的方式,训练Policy Network和Value Network。
由于很多人类的棋局都是因为中间偶然的失误导致了全盘覆灭(所谓“一着不慎满盘皆输”),其中的偶然性非常大,局部的优劣往往和棋局的最终结果无关,因此Value Network并没有用人类棋谱来训练。
AlphaGo每更新一个“小版本”后,都要将这个版本和迄今最好的版本对比,如果新的版本胜率超过55%,才会用来取代以前最好的版本。这样做显然是为了防止AlphaGo自我博弈得“走火入魔”,陷入局部最优。
AlphaGo Zero
论文:
《Mastering the game of Go without human knowledge》

AlphaGo Zero对AlphaGo进行了全面提升:
-
input plane去掉了手工特征,基本全由历史信息组成。
-
Policy Network和Value Network不再是两个同构的独立网络,而是合并成了一个网络,只是该网络有两个输出——Policy Head和Value Head。
-
骨干结构采用了Resnet,层数大大增加。
-
完全采用自我博弈,去掉了人类棋谱。
-
取消了Fast rollout。AlphaGo Zero的实践表明,如果有足够好的Value函数的话,MCTS的采样效率要远远高于传统的alpha-beta剪枝。因此,rollout也不是必须的。
稍后的AlphaZero的实践表明:AlphaZero搜索80000个节点的棋力,已经超过了Stockfish搜索70000000个节点的棋力。
- Policy Gradient vs. Policy Iteration
AlphaGo依赖快速走子的结果,获得最终的结果信息。因此,它的奖励来源比较单一:只有对局的最终结果。这种做法实际上就是通常说的Policy Gradient。
但正如之前指出的:棋下输了,不意味着每步棋都是臭棋。因此,只使用最终结果,既会导致奖励稀疏,也不利于实时评估走子的价值。
AlphaGo Zero转而采用Policy Iteration方法,实时对盘面进行估计,不再依赖终局结果。
AlphaZero
论文:
《Mastering Chess and Shogi by Self-Play with aGeneral Reinforcement Learning Algorithm》
AlphaZero相对于AlphaGo Zero的改进不算大,毕竟也就只差2个月。它的贡献在于,证明了DRL对于很多棋类都是有效的。
MuZero
MuZero是DeepMind 2019年11月的作品。
论文:
《Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model》
参考代码:
https://github.com/AppliedDataSciencePartners/DeepReinforcementLearning
2020.12,MuZero登上了Nature,算是炒了回冷饭。。。
基本结构
MuZero在不具备任何底层动态知识的情况下,通过结合基于树的搜索和学得模型,在Atari 2600游戏中达到了SOTA表现,在国际象棋、日本将棋和围棋的精确规划任务中可以匹敌AlphaZero,甚至超过了提前得知规则的围棋版AlphaZero。
传统方法的局限:
-
Model-based RL在Atari 2600游戏上表现不佳。这类游戏的Model很难刻画,规则比较抽象。
-
Model-Free RL在棋类游戏上表现不佳。棋类的规则十分明确。
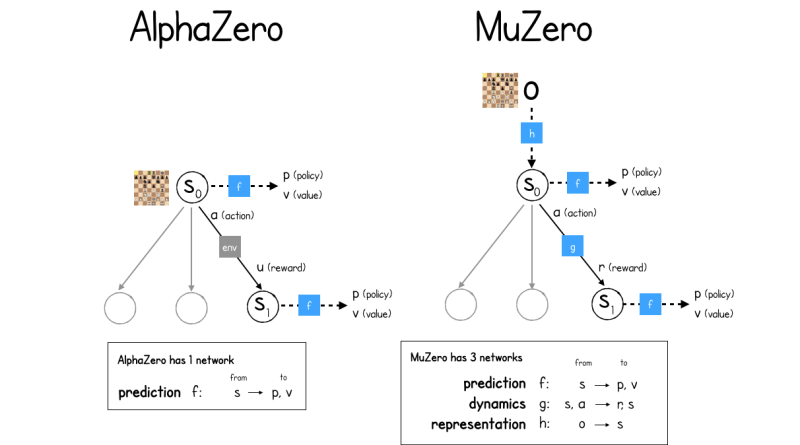
上图是MuZero和AlphaZero的网络结构对比图。从中可以看出:
1.AlphaZero只有一个网络。(虽然有两个用途:Policy和Value)
2.MuZero有三个网络:
-
Prediction Network。这个和AlphaZero相同。
-
Dynamics Network。
-
Representation Network。
Representation & Dynamics Network
Representation & Dynamics Network的主要思想来自如下论文:
1.《The Predictron: End-To-End Learning and Planning》
2.《Value Prediction Network》
上文已经指出Model-based方法的困难在于:有的时候Model是很难刻画的,而环境本身也许并不如模拟器那么纯粹、简单。
一个很自然的思路就是:既然NN能表示Policy和Value,那么能不能表示Model呢?
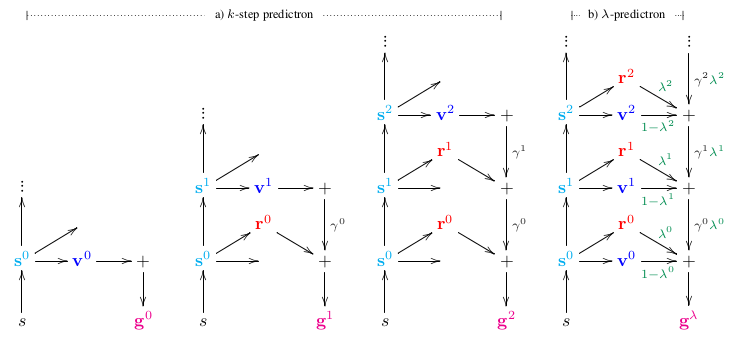
参考论文1提出了Predictron框架,它的主要思路是:
-
构建一个abstract MDP model。虽然我们并不知道它的state,更不清楚它的transition,但是不要紧,假设它存在就好。
-
状态表示。(即上图中的\(s^0,s^1,\dots\))
这里用\(\vec{s}\)表示系统的抽象状态以区别其实际状态s。也就是说,在系统模型中,预测的不是实际的状态s, 而是抽象的状态。即:建立real state space到abstract state space的映射。
- 模型预测,不只是状态流的预测,还包括立即回报和折扣因子的预测。
- 抽象状态\(\vec{s}\)处的值函数:
- 由回报、折扣因子和值函数计算得到估计值。这里可以对这个abstract MDP model应用TD(n)和TD(\(\lambda\))算法,得到如上图所示的k-step和\(\lambda\)-weighted的预测值。其中的g表示累计奖励值。
这里的套路其实和DQN非常像,都是让预测值(这里是g)尽可能接近真实值。区别在于:这里既然是Model-based方法,那么自然有利用Model生成模拟样本的步骤,而DQN没有这样的步骤。
参考论文2的做法也是类似的。
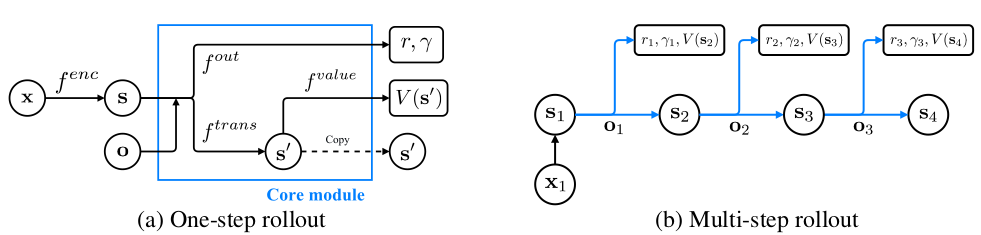
x:观测值(observation)。
s:abstract state。
o:abstract state上的option。
s’:下一个abstract state。
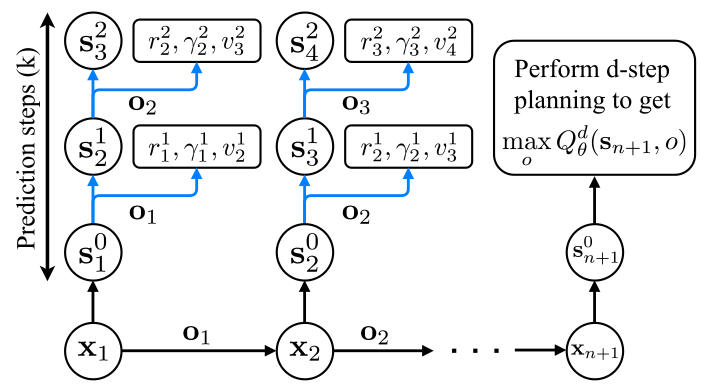
也是预测若干步的奖励值。
实现细节
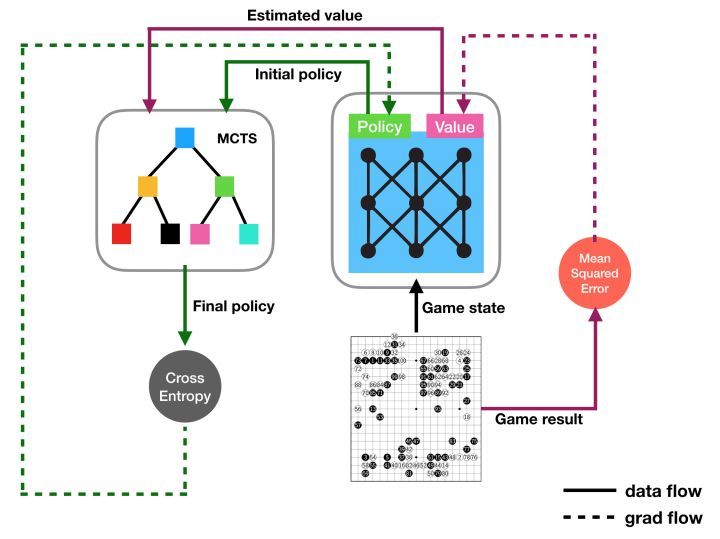
重新回到MuZero,下图是MuZero的关键步骤图。
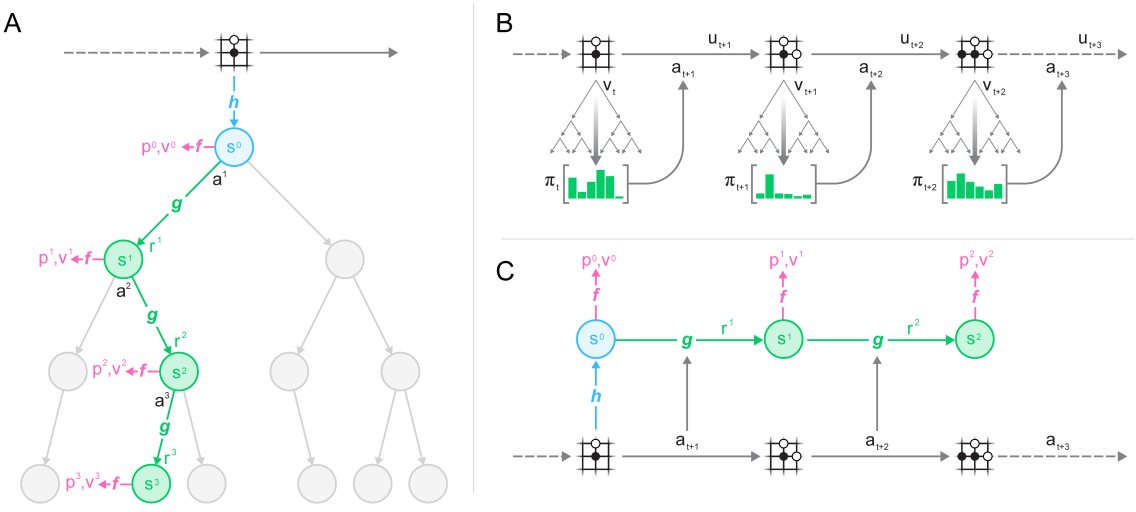
A部分:Representation Network + Dynamics Network + MCTS
B部分:从policy:\(\pi_t\)中采样得到action:\(a_{t+1}\),环境根据\(a_{t+1}\)得到observation:\(o_{t+1}\)、h和reward:\(u_{t+1}\)。这些样本在用过后,被存入replay buffer。
C部分:训练时,从replay buffer中,采样得到\(o_t\),通过h函数,得到\(s_t\),然后执行K-step展开,得到p,v,r。
loss公式为:
\[l_t(\theta)=\sum_{k=0}^K l^r(u_{t+k},r_t^k)+l^v(z_{t+k},v_t^k)+l^p(\pi_{t+k},p_t^k)+c\|\theta\|^2\]其中,p,v,r分别是policy、value、reward的预测值。而\(\pi\)、z、u则是对应的target值。(参见《深度强化学习(二)》中DQN一节中的current Q-value和target Q-value的定义)
MuZero和VPN一样,都是在abstract state space中用dynamics model做planning。MuZero的改进在于增加了对每个abstract state上policy的预测,因此效率比VPN要高一些。
最后需要澄清一点的是:模拟的Model永远比不上确定的规则。MuZero在棋类上的表现并不如AlphaZero。对比数据中,围棋项目的优势,更多的在于MuZero使用了更宽的网络。
参考
https://mp.weixin.qq.com/s/BLQF8WNsIe4a_rDeGWo_Vg
通用AlphaGo诞生?DeepMind的MuZero在多种棋类游戏中超越人类
https://www.zhihu.com/question/356976342
如何评价DeepMind新提出的MuZero算法?
https://zhuanlan.zhihu.com/p/31344949
联合模型的强化学习算法(三)

您的打赏,是对我的鼓励
