DRL » 深度强化学习(九)——AlphaStar, Dota 2, 王者荣耀, RLHF
2020-04-30 :: 6132 WordsStarCraft(续)
https://mp.weixin.qq.com/s/I9gfoCxEYW5lSIy5QGyt6w
2018星际AI大赛(2018.11)冠军诞生!一个个机器学习算法,都输给不会学习的韩国bot
https://github.com/TeamSAIDA/SAIDA
2018.11冠军SAIDA的github
https://github.com/TorchCraft/TorchCraft
2018.11亚军CherryPi的github
https://github.com/bmnielsen/Locutus/
2018.8冠军Locutus的github
https://mp.weixin.qq.com/s/yAYF2i-Pr84RliKrJyPaUA
伯克利星际争霸II AI“撞车”腾讯,作者:我们不一样
https://mp.weixin.qq.com/s/uC8gi4kN_muRTwRL0RCZjQ
要玩转这个星际争霸II开源AI,你只需要i5+GTX1050
https://mp.weixin.qq.com/s/wyn-V4-DcjjOKziith3pXw
开源星际争霸2多智能体挑战smac
https://mp.weixin.qq.com/s/e4iv6FJAMZACEqWFmxeSFg
让AI掌握星际争霸微操:中科院提出强化学习+课程迁移学习方法
https://mp.weixin.qq.com/s/JbCIBFDRvg5qcpZ11g58dw
DeepMind提出关系性深度强化学习:在星际争霸2任务中获得最优水平
https://mp.weixin.qq.com/s/h0be7yRQMjLFi8EteTzuMQ
腾讯AI在星际2完整对战中击败“作弊级”内建Bot
https://zhuanlan.zhihu.com/p/29222384
sc2-101: 第一个rule-base的星际二agent
https://mp.weixin.qq.com/s/pggQL5uLasJ7icnlrMs9OQ
自动化所开源星际争霸2基准AI
AlphaStar
AlphaStar是DeepMind在解决了围棋问题之后,在RTS游戏领域的尝试。
里程碑事件:
2018.12 5:0击败TLO,5:0击败MaNa。
2019.1 表演赛不敌MaNa。
论文:
《Grandmaster level in StarCraft II using multi-agent reinforcement learning》
参考:
https://mp.weixin.qq.com/s/_Y0bCjTu9UrHfnen15htqQ
AlphaStar称霸星际争霸2!AI史诗级胜利,DeepMind再度碾压人类
https://mp.weixin.qq.com/s/axr5VFbHQmYo0shW9ilBaQ
DeepMind回应一切:AlphaStar两百年相当于人类多长时间?
https://www.zhihu.com/question/310011363
如何评价DeepMind在北京时间19年1月25日2点的《星际争霸 2》项目演示?
https://mp.weixin.qq.com/s/k0l2uoik-Z9aA9zax7AoZg
中科院自动化所深度解析:Deepmind AlphaStar如何战胜人类职业玩家
https://zhuanlan.zhihu.com/p/55781614
AlphaStar背后的机器学习原理
https://mp.weixin.qq.com/s/XljE82cJZfFOgf2KrXWSKA
DeepMind首个战胜星际2职业玩家的AI为何无敌?新视角揭秘AI里程碑
https://mp.weixin.qq.com/s/_t2vLFfIG6VYAdWDalpIXQ
说人话教AI打游戏,Facebook开源迷你版星际争霸,成果登上NeurIPS 2019
https://mp.weixin.qq.com/s/X7QQn6W2dB3y_Ljii-sJ3w
Alphastar再登Nature!星际争霸任一种族,战网狂虐99.8%人类玩家
https://zhuanlan.zhihu.com/p/102749648
基于多智能体强化学习主宰星际争霸游戏
https://zhuanlan.zhihu.com/p/92543229
AlphaStar
https://zhuanlan.zhihu.com/p/97720096
浅谈AlphaStar
https://mp.weixin.qq.com/s/R4RXxLan7H2sCbBrKqyH6w
基于多智能体强化学习的《星际争霸II》中大师级水平的技术研究
https://zhuanlan.zhihu.com/p/815084333
星际争霸2 ai小结
启元世界
启元世界是国内的一家AI公司,碰巧也搞星际争霸2。研究员Flood Sung后来也加盟了该团队。
2020.6.21 启元AI 2:0 人类选手《星际争霸I/II》全国冠军黄慧明(TooDming)和中国星际最强人族选手、黄金总决赛三连冠选手李培楠(TIME)。
在WCS2012的亚洲杯锦标赛中,韩国选手包揽前8强,国内专业体育报刊《体坛周报》以《星际之差 尤甚男足》为标题发表文章,痛批国内电竞选手,令人哀叹不已。
10年后,星际已经拿到冠军了,而国足还是那个鸟样。
https://www.zhihu.com/question/583694151
李培楠夺《星际争霸 2》2023 IEM总冠军,成为中国该项目首位世界冠军,对此你有什么想说?
参考:
https://mp.weixin.qq.com/s/ev6F_prsP5nAtFKze3-zCQ
启元AI两局2:0战胜中国星际争霸冠军,仅用顶级科技巨头1%算力
https://www.zhihu.com/question/402678197
如何看待启元世界AI星际指挥官打败人族选手TIME?
Dota 2
Dota 2的AI项目主要是OpenAI来搞,算是DRL在MOBA游戏上的应用。
里程碑事件:
2017.8 1vs1击败Dendi。2:0。稍后,OpenAI将该版本放在线上,被人找出破绽,惨遭调戏。
2018.6 OpenAI Five击败半职业玩家。
2018.7 OpenAI Five在Ti8表演赛被paiN Gaming和中国退役大神队击败。
2019.4 OpenAI Five击败Ti8冠军OG。
2019.12 OpenAI开发了更强的Rerun。Rerun对OpenAI Five的胜率为98%。
论文:
《Dota 2 with Large Scale Deep Reinforcement Learning》
参考:
https://mp.weixin.qq.com/s/rPsxvzOLuoo_IRtgH94Ecw
OpenAI自学习多智能体5v5团队战击败人类玩家
https://mp.weixin.qq.com/s/VPVzXzBYD_nYO1SjTMNGVA
Dota2团战AI击败人类最全解析:能团又能gank,AI一日人间180年
https://mp.weixin.qq.com/s/5Vg9RFvyNv6T7QkIfPm1aQ
DOTA2中打败Dendi的AI如何炼出?
https://mp.weixin.qq.com/s/e4lK3UoQq-8j1YIWKALBLg
嵌入技术在Dota2人工智能战队OpenAI Five中的应用
https://mp.weixin.qq.com/s/xsoS3tvOh78rkbI0UUIkPQ
2:0!Dota2世界冠军OG被OpenAI碾压,全程人类只推掉两座外塔
https://mp.weixin.qq.com/s/X73jL5T_uZ87F3iE-uTnpw
Dota2冠军OG如何被AI碾压?OpenAI累积三年的完整论文终于放出
王者荣耀
腾讯绝悟也是DRL在MOBA游戏上的尝试。
https://mp.weixin.qq.com/s/ptgHNil1gqrH2p-x3UZoFw
紧急更新下降难度,《王者荣耀》绝悟AI难倒一片玩家
https://mp.weixin.qq.com/s/kAuzmc70NYAr9HmyioD5xA
腾讯绝悟AI完全体研究登上国际顶会与顶刊
https://mp.weixin.qq.com/s/8jkJy8ZarvpodmBccAc74A
中国AI足球队勇夺世界冠军,腾讯出品
https://mp.weixin.qq.com/s/ma2SgFuNYu50oexnfBYYLw
用AI打王者荣耀?认真谈谈强化学习的价值
https://mp.weixin.qq.com/s/IFGUXI3YXVsjIVuJ717uaw
用人工智能打王者荣耀:匹茨堡大学&腾讯AI Lab为游戏AI引入MCTS方法
https://mp.weixin.qq.com/s/Q3WWqEnUaIvnLwoFHY5lfQ
腾讯王者荣耀AI论文首次曝光:五AI王者局开黑与人类战队打成平手
https://mp.weixin.qq.com/s/Mdq9fL10Zcjs_z3PeqtN9Q
腾讯AI单挑碾压王者荣耀职业玩家:人类15场只能赢1局,坚持不到8分钟
https://mp.weixin.qq.com/s/_Ze8C8UQV9UZXnSX6qq2GA
强化学习玩王者荣耀
https://mp.weixin.qq.com/s/mj8PG-wRqSbEIR38fongHA
用自己训练的AI玩王者荣耀是什么体验?
常见问题建模方法
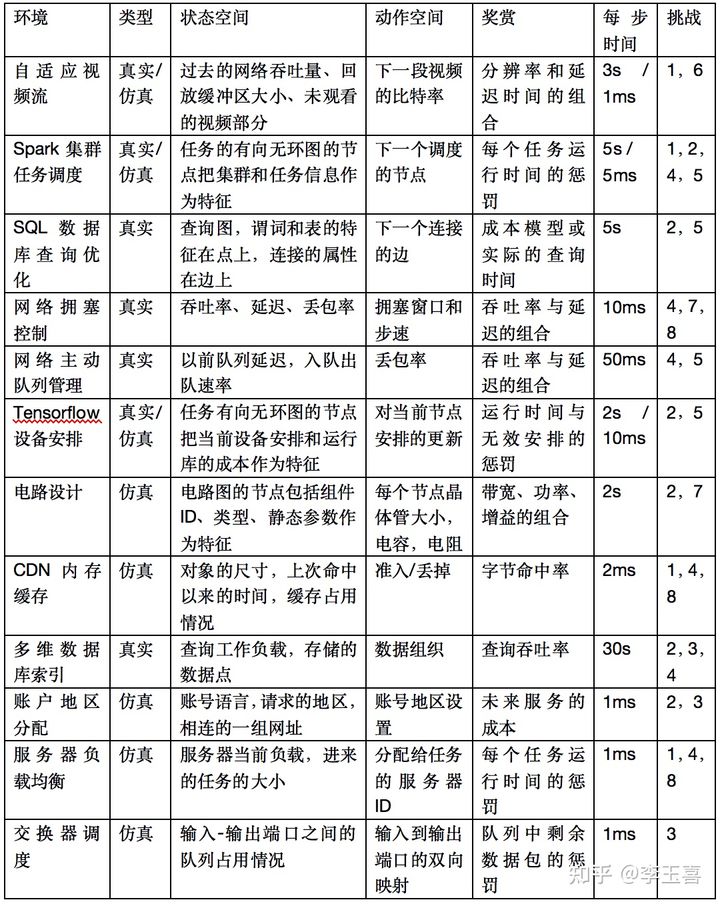
https://zhuanlan.zhihu.com/p/356166466
强化学习落地:计算机系统
RLHF
reward modeling
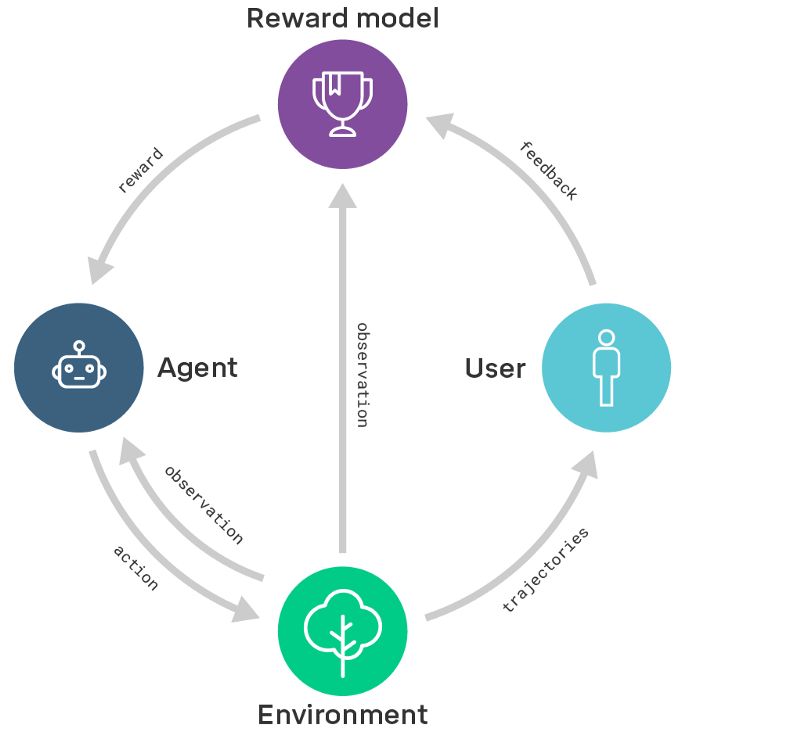
训练一个奖励模型,其中包含来自用户的反馈,从而捕捉他们的意图。与此同时,我们通过强化学习训练一个策略,使奖励模型的奖励最大化。换句话说,我们把学习做什么(奖励模型)和学习怎么做(策略)区分开来。
参考:
https://mp.weixin.qq.com/s/4yGQtHtMqWlaB7MAsr8T_g
DeepMind重磅论文:通过奖励模型,让AI按照人类意图行事
https://mp.weixin.qq.com/s/TIWnnCmVZnFQNH9Fig5aTw
DeepMind发布新奖励机制:让智能体不再“碰瓷”
https://zhuanlan.zhihu.com/p/337759337
BeBold:一种新的强化学习探索准则
RLHF in ChatGPT
TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)框架将人类标记者引入到Agents的学习循环中,可以通过人类向Agents提供奖励反馈(即指导Agents进行训练),从而快速达到训练任务目标。
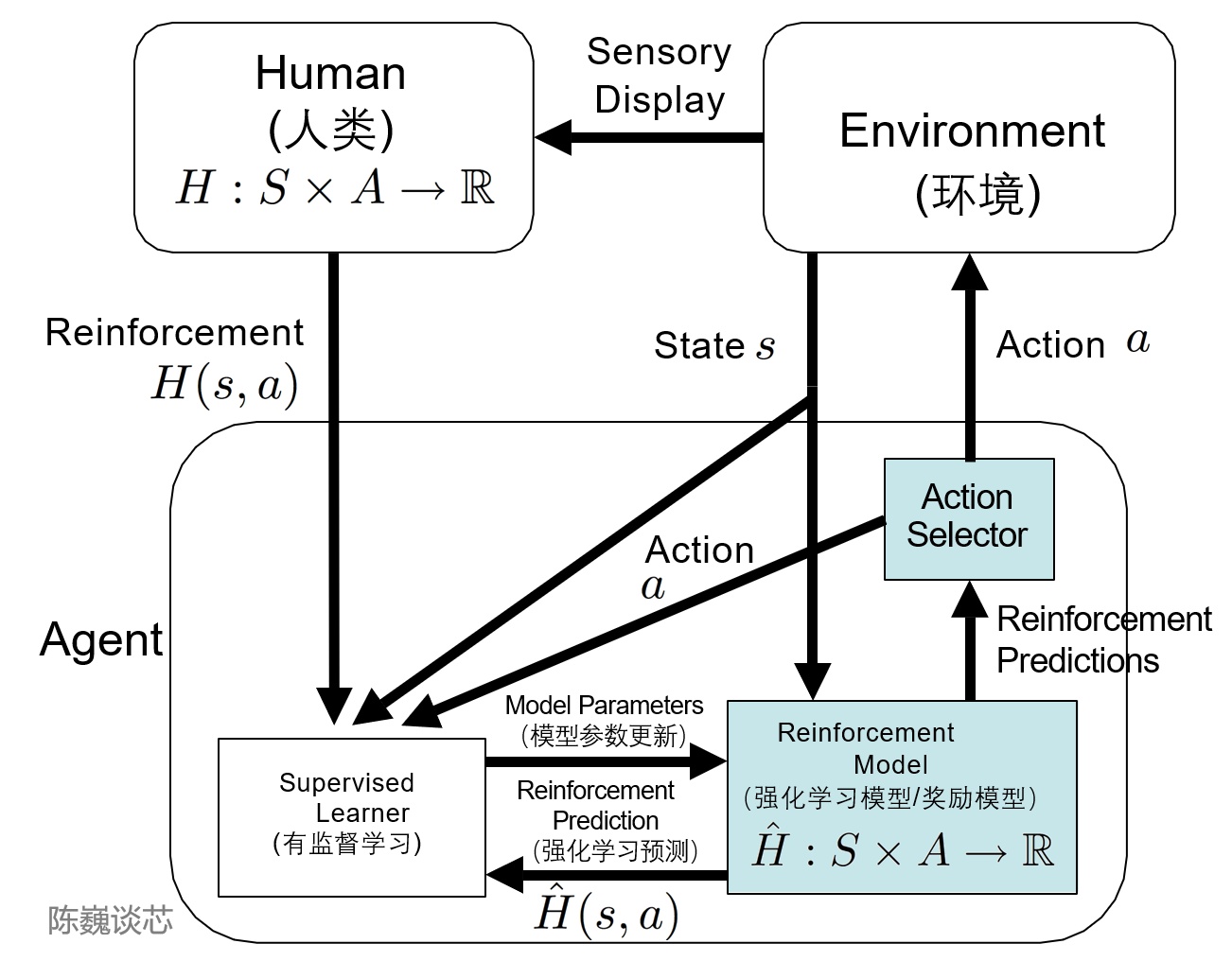
这算得上是一种有监督学习+RL了。
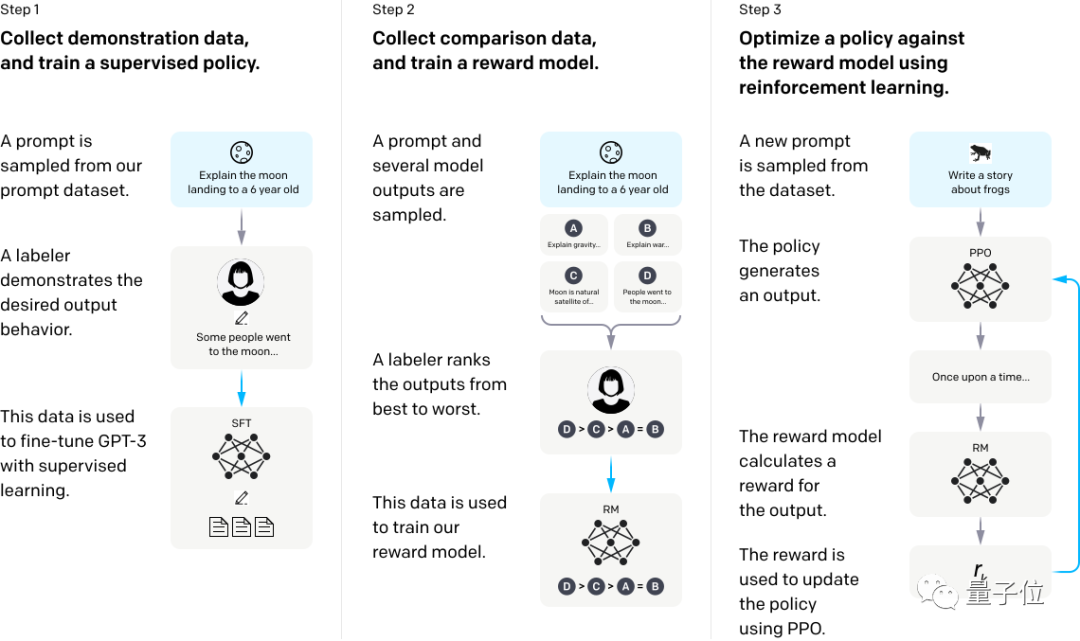
利用强化学习在大模型中注入人类的经验,所谓的Reinforcement Learning from Human Feedback(RLHF),Policy Network输出的多样性及Reward的学习是ChatGPT成功的关键。
RLHF
RLHF于2017年6月由OpenAI联合Google DeepMind推出。
论文:
《DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales》
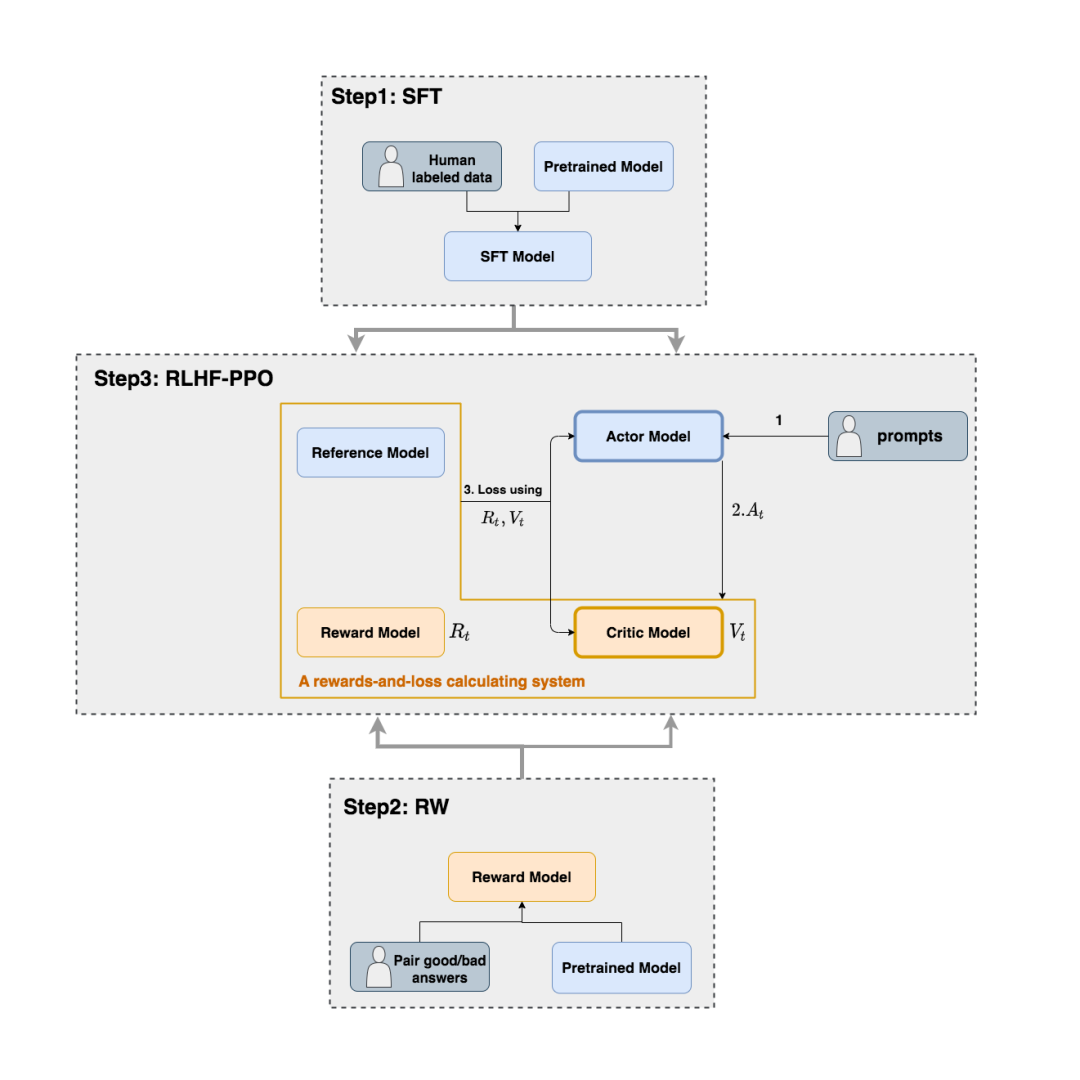
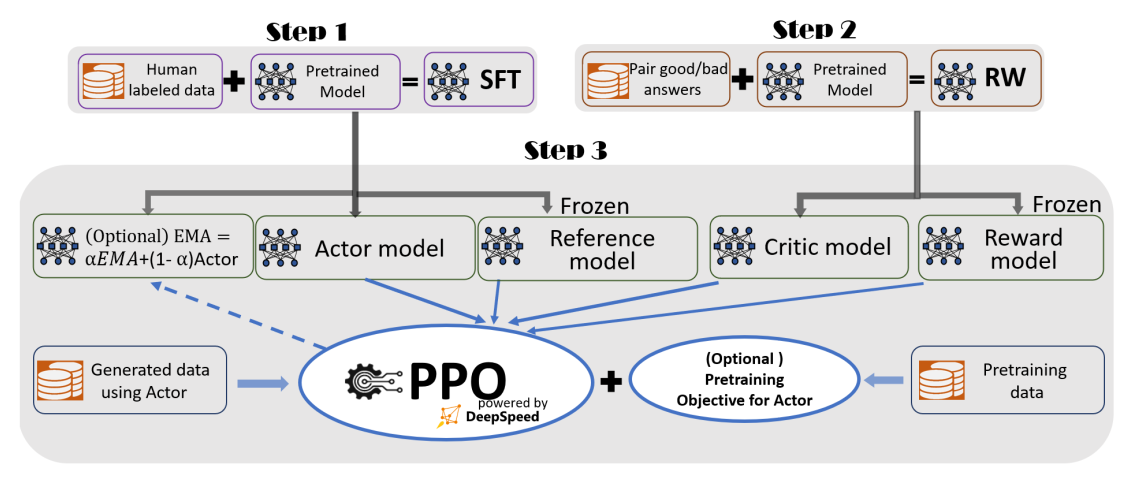
原始的PPO只有Actor-Critic两个模型,RLHF又额外引入了两个模型:Reward/Reference Model。
- Step 1
将所有语料进行无监督训练,得到Pretrained Model,然后使用标注数据(如QA pair)进行Supervised Fine-Tuning,得到SFT Model。
- Step 2
编写QA pair毕竟比较费力,打分得到好/坏信息相对简单一些,同样也对Pretrained Model进行微调,得到Reward Model。
- Step 3
Actor/Critic Model在RLHF阶段是需要训练的;而Reward/Reference Model是参数冻结的。
Reference Model一般用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。Reference模型的主要作用是防止Actor”训歪”。
Critic Model一般用Reward Model初始化,Reward模型由于已经包含了人类提供的事实数据,因此它在这里是无需训练的。
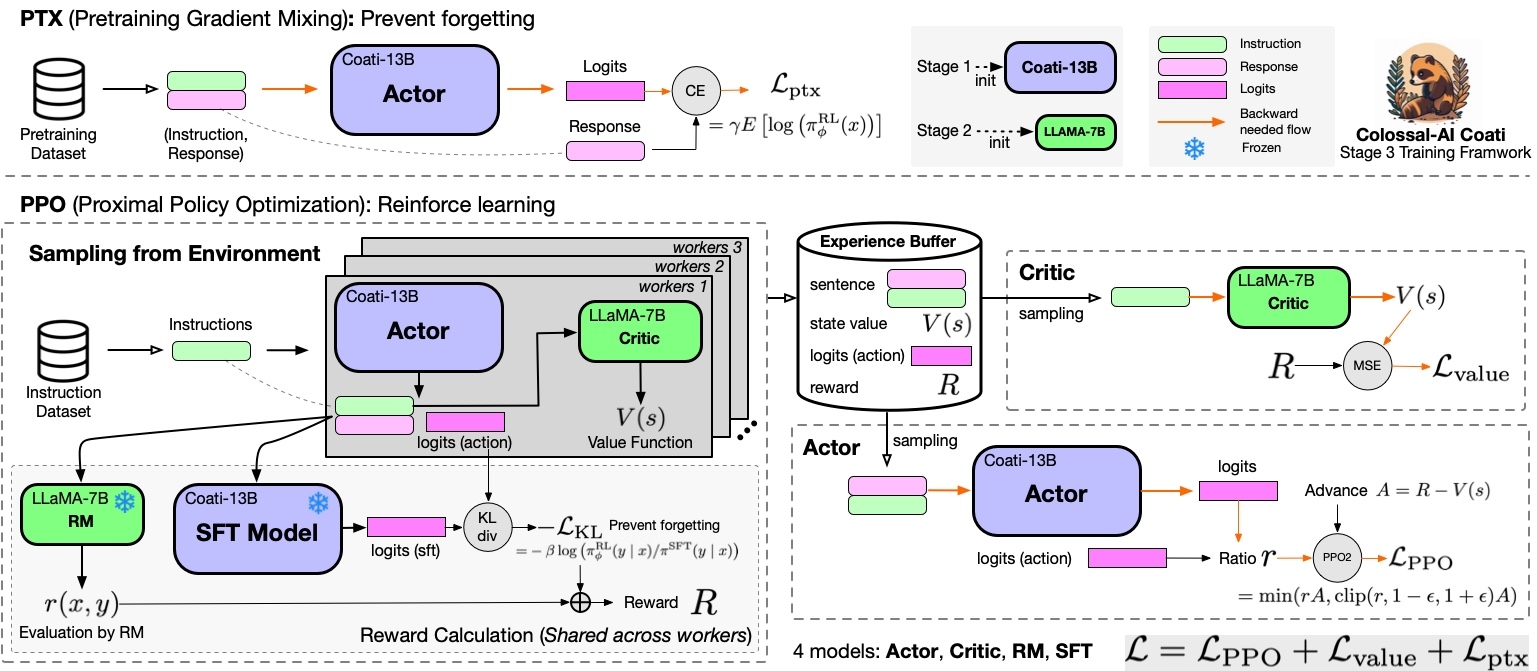
后期的RLHF还引入了Generalized Advantage Estimation(GAE)用于替代TD-error。
ReMax认为,我们可以丢掉Critic(教练),Actor不再需要受到Critic的指导,而是直接去对齐Reference Model。
Group Relative Policy Optimization(GRPO)
这类方法效果一般,通常用于没有计算资源的时候Fine-Tuning之用。
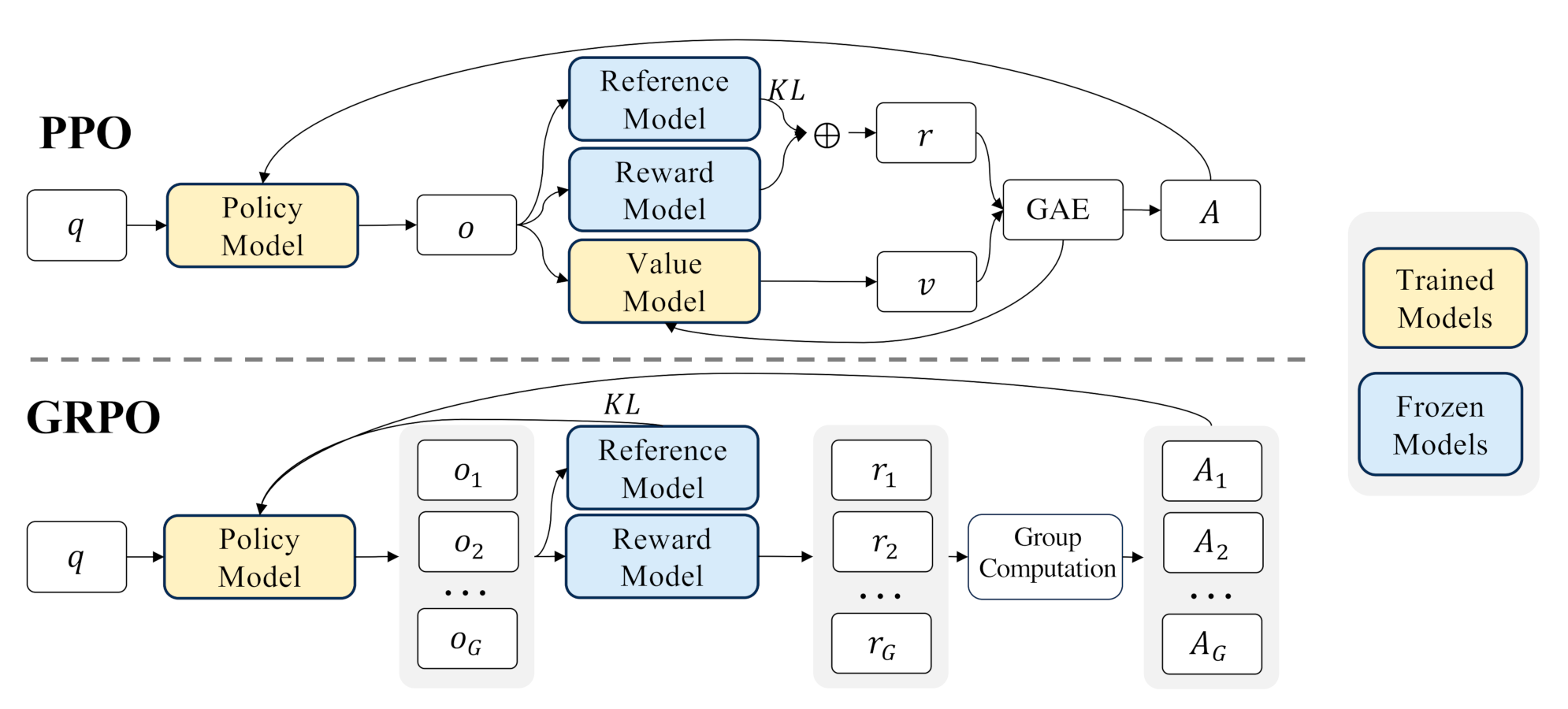
GRPO原理:
举个例子,怎么评判公司的一个员工是否优秀呢?
这个很难明确定义,谁给的定义可能都没法让所有人信服。
但至少有一个办法就是,拿他去和所有员工的平均水准去对比(每个员工平时都是有得分项、失分项的),高于平均水准的便是好员工。
如此一来,对同一问题的多个采样输出的平均奖励作为基线(说白了,直接暴力采样N次求均值),并以此为依据更新策略。这样就可以取代Critic Model了。
https://blog.csdn.net/v_JULY_v/article/details/136656918
一文通透GRPO——通俗理解群体相对策略优化GRPO及其代码实现
参考:
https://zhuanlan.zhihu.com/p/592671478
ChatGPT背后的算法——RLHF
https://zhuanlan.zhihu.com/p/612572103
RLHF的其他优化方向
https://zhuanlan.zhihu.com/p/608176805
如何看懂ChatGPT里的RLHF公式以及相关实现
https://zhuanlan.zhihu.com/p/644680366
LLaMA2 RLHF技术细节
https://zhuanlan.zhihu.com/p/645068532
大模型RLHF的trick

您的打赏,是对我的鼓励
