DL » 深度学习(二十二)——VDSR, ESPCN, FSRCNN, VESPCN, SRGAN, DemosaicNet
2017-10-22 :: 5369 WordsDRCN(续)
其中的\(H_1\)到\(H_D\)是D个共享参数的卷积层。DRCN将每一层的卷积结果都通过同一个Reconstruction Net得到一个重建结果,从而共得到D个重建结果,再把它们加权平均得到最终的输出。另外,受到ResNet的启发,DRCN通过skip connection将输入图像与H_d的输出相加后再作为Reconstruction Net的输入,相当于使Inference Net去学习高分辨率图像与低分辨率图像的差,即恢复图像的高频部分。
参考:
http://blog.csdn.net/u011692048/article/details/77500764
超分辨率重建之DRCN
VDSR
VDSR是DRCN的原班人马的新作。
论文:
《Accurate Image Super-Resolution Using Very Deep Convolutional Networks》
代码:
code:https://github.com/huangzehao/caffe-vdsr
SRCNN存在三个问题需要进行改进:
1、依赖于小图像区域的内容;
2、训练收敛太慢;
3、网络只对于某一个比例有效。
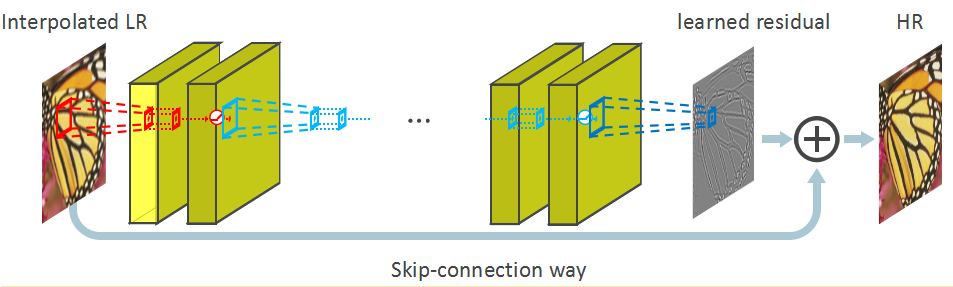
VDSR模型主要有以下几点贡献:
1、增加了感受野,在处理大图像上有优势,由SRCNN的13x13变为41x41。(20层的3x3卷积)
2、采用残差图像进行训练,收敛速度变快,因为残差图像更加稀疏,更加容易收敛(换种理解就是LR携带者低频信息,这些信息依然被训练到HR图像,然而HR图像和LR图像的低频信息相近,这部分花费了大量时间进行训练)。
3、考虑多个尺度,一个卷积网络可以处理多尺度问题。
训练的策略:
1、采用残差的方式进行训练,避免训练过长的时间。
2、使用大的学习进行训练。
3、自适应梯度裁剪,将梯度限制在某一个范围。
4、多尺度,多种尺度样本一起训练可以提高大尺度的准确率。
对于边界问题,由于卷积的操作导致图像变小的问题,本文作者提出一个新的策略,就是每次卷积后,图像的size变小,但是,在下一次卷积前,对图像进行补0操作,恢复到原来大小,这样不仅解决了网络深度的问题,同时,实验证明对边界像素的预测结果也得到了提升。
参考:
http://blog.csdn.net/u011692048/article/details/77512310
超分辨率重建之VDSR
ESPCN
ESPCN(efficient sub-pixel convolutional neural network)是创业公司Magic Pony Technology的Wenzhe Shi和Jose Caballero作品。该创业团队主要来自Imperial College London,目前已被Twitter收购。
论文:
《Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network》
代码:
https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
在SRCNN和DRCN中,低分辨率图像都是先通过上采样插值得到与高分辨率图像同样的大小,再作为网络输入,意味着卷积操作在较高的分辨率上进行,相比于在低分辨率的图像上计算卷积,会降低效率。
ESPCN提出一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率方法。
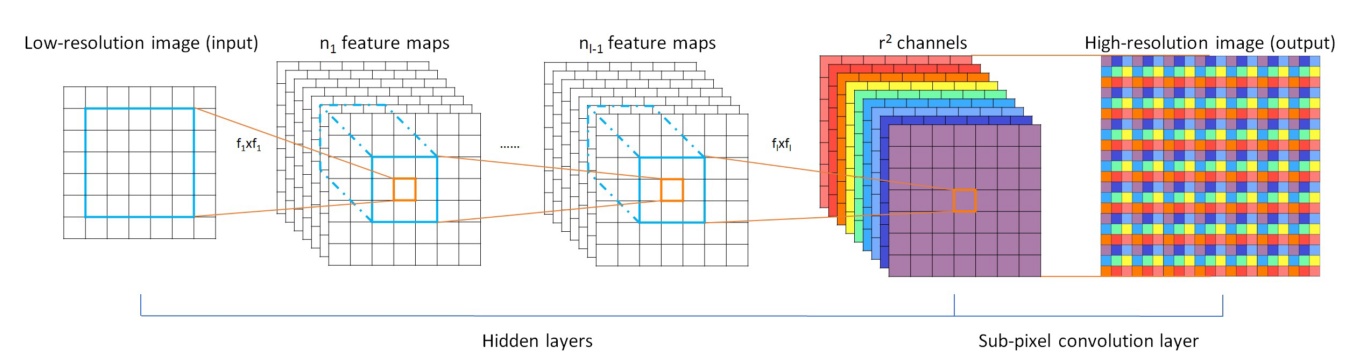
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。如上图所示,网络的输入是原始低分辨率图像,通过两个卷积层以后,得到的特征图像大小与输入图像一样,但是特征通道为\(r^2\)(r是图像的目标放大倍数)。将每个像素的\(r^2\)个通道重新排列成一个\(r \times r\)的区域,对应于高分辨率图像中的一个\(r \times r\)大小的子块,从而大小为\(r^2 \times H \times W\)的特征图像被重新排列成\(1 \times rH \times rW\)大小的高分辨率图像。这个变换虽然被称作sub-pixel convolution, 但实际上并没有卷积操作。
通过使用sub-pixel convolution, 图像从低分辨率到高分辨率放大的过程,插值函数被隐含地包含在前面的卷积层中,可以自动学习到。只在最后一层对图像大小做变换,前面的卷积运算由于在低分辨率图像上进行,因此效率会较高。
参考:
http://blog.csdn.net/zuolunqiang/article/details/52401802
super-resolution技术日记——ESPCN
FSRCNN
FSRCNN(Fast Super-Resolution CNN)是Chao Dong继SRCNN之后的又一作品。
论文:
《Accelerating the Super-Resolution Convolutional Neural Network》
代码:
https://github.com/66wangxuewen99/Super-Resolution/tree/master/FSRCNN
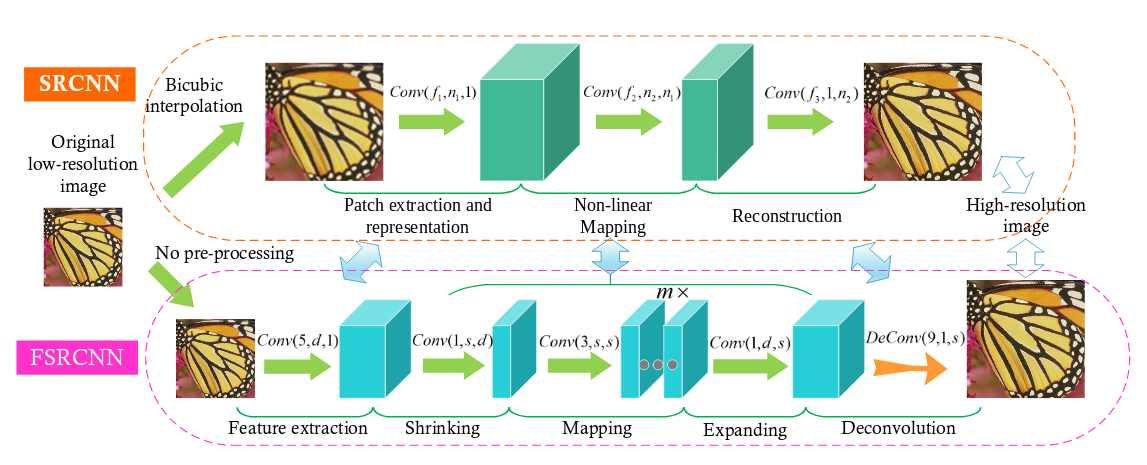
上图是FSRCNN和SRCNN的网络结构对比图。其中的\(Conv(f_i,n_i,c_i)\)中的\(f_i,n_i,c_i\)分别表示filter的大小、数量和通道的个数。
FSRCNN主要做了如下改进:
1.直接输入LR的图片。这和ESPCN思路一致。
2.将SRCNN中的Non-linear mapping分为Shrinking、Mapping、Expanding三个阶段。
3.使用Deconv重建HR图像。
ESPCN的论文中指出他们的sub-pixel convolution效果优于Deconv。但由于ESPCN和FSRCNN出来的时间都差不多,尚未有他们两个正式PK的成绩。
参考:
http://blog.csdn.net/zuolunqiang/article/details/52411673
super-resolution技术日记——FSRCNN
VESPCN
看名字就知道,VESPCN(Video ESPCN)仍然是ESPCN原班人马Wenzhe Shi和Jose Caballero作品。
论文:
《Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation》
在视频图像的SR问题中,相邻几帧具有很强的关联性,上述几种方法都只在单幅图像上进行处理,而VESPCN提出使用视频中的时间序列图像进行高分辨率重建,并且能达到实时处理的效率要求。其方法示意图如下,主要包括三个方面:
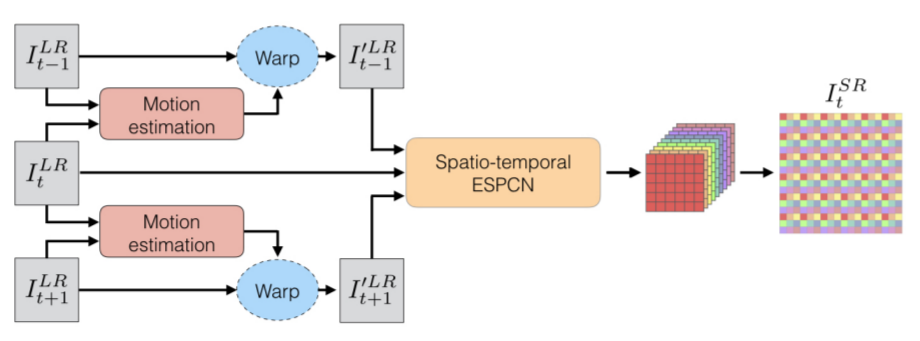
一是纠正相邻帧的位移偏差,即先通过Motion estimation估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐。二是把对齐后的相邻若干帧叠放在一起,当做一个三维数据,在低分辨率的三维数据上使用三维卷积,得到的结果大小为\(r^2\times H\times W\)。三是利用ESPCN的思想将该卷积结果重新排列得到大小为\(1\times rH\times rW\)的高分辨率图像。
Motion estimation这个过程可以通过传统的光流算法来计算,DeepMind提出了一个Spatial Transformer Networks, 通过CNN来估计空间变换参数。VESPCN使用了这个方法,并且使用多尺度的Motion estimation:先在比输入图像低的分辨率上得到一个初始变换,再在与输入图像相同的分辨率上得到更精确的结果,如下图所示:
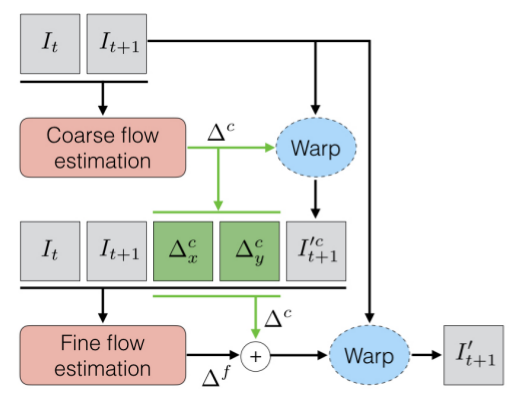
由于SR重建和相邻帧之间的位移估计都通过神经网路来实现,它们可以融合在一起进行端到端的联合训练。为此,VESPCN使用的损失函数如下:
\[(\theta^*,\theta_\Delta^*)=\mathop{\arg\min}_{\theta,\theta_\Delta}\|I_t^{HR}-f(I_{t-1:t+1}^{'LR};\theta)\|_2^2 \\+\sum_{i=\pm 1}[\beta\|I_{t+i}^{'LR}-I_t^{LR}\|_2^2+\lambda\mathcal{H}(\partial_{x,y}\Delta_{t+i})]\]第一项是衡量重建结果和Golden标准之间的差异,第二项是衡量相邻输入帧在空间对齐后的差异,第三项是平滑化空间位移场。
SRGAN
SRGAN还是ESPCN原班人马的作品。
论文:
《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
SRGAN将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
传统的方法使用的代价函数一般是最小均方差(MSE),即:
\[l_{MSE}^{SR}=\frac{1}{r^2WH}\sum_{x=1}^{rW}\sum_{y=1}^{rH}(I_{x,y}^{HR}-G_{\theta_G}(I^{LR})_{x,y})^2\]该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。SRGAN认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。
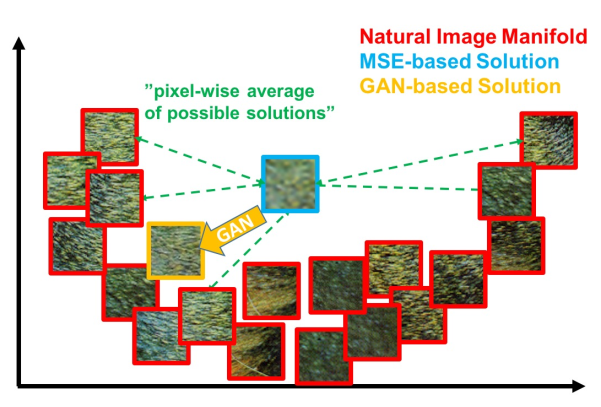
上图展示了MSE和GAN方法的区别。
整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为:
\[l^{SR}=l_X^{SR}+10^{-3}l_{Gen}^{SR}\]第一部分是基于内容的代价函数(content loss),第二部分是基于对抗学习的代价函数(adversarial loss)。
论文中以VGG作为基础网络,因此content loss又可表述为:
\[l_{VGG/i,j}^{SR}=\frac{1}{W_{i,j}H_{i,j}}\sum_{x=1}^{W_{i,j}}\sum_{y=1}^{H_{i,j}}(\phi_{i,j}(I^{HR})_{x,y}-\phi_{i,j}(G_{\theta_G}(I^{LR}))_{x,y})^2\]adversarial loss为:
\[l_{Gen}^{SR}=\sum_{n=1}^N-\log D_{\theta_D}(G_{\theta_G}(I^{LR}))\]SRGAN的网络结构如下图所示:
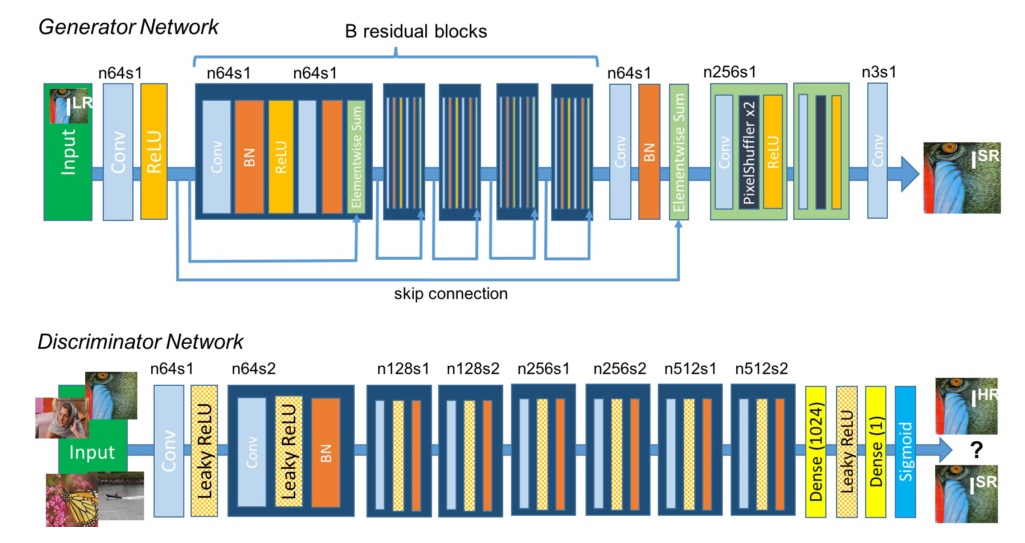
由于SRGAN的目标不在于最小化MSE,因此通常情况下,它的PSNR和SSIM都不是太好,但的确能提供一些其它方法无法提供的细节。
2018年一项发表于CVPR的研究成果表明,SR技术存在一个有趣的“悖论”,即还原或重建后的高分辨率图像与原图相似度越高,则肉眼观察清晰度越差;反之,若肉眼观察清晰度越好,则图像的失真度越高。导致这一现象的原因在于畸变(Distortion)参数和感知(Perception)参数之间侧重点选择的不同。
参考:
https://mp.weixin.qq.com/s/YPdIfrCQrWGYqtREIl3OaA
SRGAN With WGAN:让超分辨率算法训练更稳定
https://mp.weixin.qq.com/s/x1teE6tKZpump_N2-u-jUg
SRGAN-超分辨率图像复原
https://mp.weixin.qq.com/s/zw72I9FTiKq3ZA4gcd5K3A
ESRGAN:基于GAN的增强超分辨率方法
https://mp.weixin.qq.com/s/47NVJGaB60S5Soeg5s7K7g
ESRGAN-进击的超分辨率复原
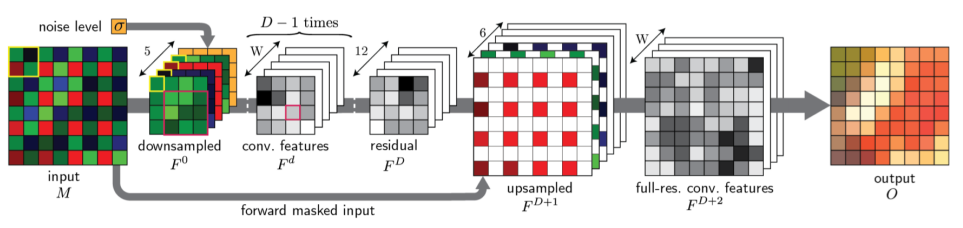
DemosaicNet
DemosaicNet是MIT CSAIL的在读博士生Michaël Gharbi的作品。
论文:
《Deep Joint Demosaicking and Denoising》
代码:
https://github.com/mgharbi/demosaicnet
在《图像处理理论(五)》中,我们提到了ISP处理的一般流程。而SR的一大用途就在于ISP。
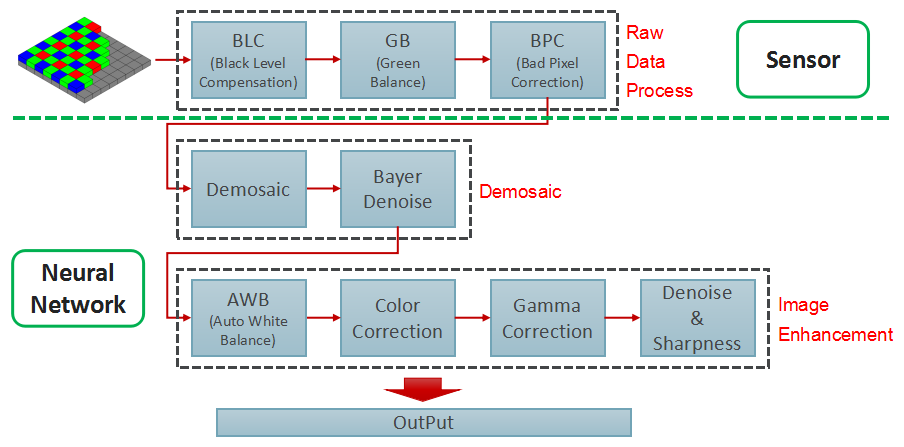
上图是ISP处理的一般流程,其中的Demosaic和Image Enhancement,都可以通过NN的端到端学习一次性完成。DemosaicNet就是其中的代表,它的网络结构如下:

您的打赏,是对我的鼓励
