DL » 深度学习(四十八)——深度信息检索
2018-10-26 :: 6366 Words深度信息检索
Information Retrieval是用户进行信息查询和获取的主要方式,是查找信息的方法和手段。狭义的信息检索仅指信息查询(Information Search)。即用户根据需要,采用一定的方法,借助检索工具,从信息集合中找出所需要信息的查找过程。广义的信息检索是信息按一定的方式进行加工、整理、组织并存储起来,再根据信息用户特定的需要将相关信息准确的查找出来的过程。
这方面的DL应用可参见以下的综述文章:
《MatchZoo: A Toolkit for Deep Text Matching》
教程
http://web.stanford.edu/class/cs276/
CS 276 / LING 286: Information Retrieval and Web Search
度量学习
度量学习(Metric Learning)是机器学习里面的一个研究方向,主要是用来度量数据间距离。
一般来说,对于可度量的数据,我们可以直接通过欧式距离,cosine等方法来做。但对于更广泛的数据我们就很难这样操作,如测量一个视频和一首音乐的距离。
参考:
https://zhuanlan.zhihu.com/p/80656461
Metric Learning科普文
https://mp.weixin.qq.com/s/mvbyddpgxBFQSxC1zZZmFw
如何通过距离度量学习解决Street-to-Shop问题
https://mp.weixin.qq.com/s/iuOmxW0OAhSA7xSoIIn1dw
鲁继文:面向视觉内容理解的深度度量学习
https://zhuanlan.zhihu.com/p/100553403
Deep Metric Learning及其形式
https://mp.weixin.qq.com/s/_1szOUVaTKZBytHPHqCGRA
如何用深度学习来做检索:度量学习中关于排序损失函数的综述
ARC-I & ARC-II
《Convolutional neural network architectures for matching natural language sentences》
DSSM
论文:
《Learning deep structured semantic models for web search using clickthrough data》
Word Hashing
DSSM已经意识到one-hot是一种低效的词向量表示方式,因此,它转而采用了一种叫做Word Hashing的技术。
Word Hashing是非常重要的一个trick,以英文单词来说,比如good,它可以写成#good#,然后按tri-grams来进行分解为#go goo ood od#,再将这个tri-grams灌入到bag-of-word中,这种方式可以非常有效的解决vocabulary太大的问题(因为在真实的web search中vocabulary就是异常的大),另外也不会出现oov问题,因此英文单词才26个,3个字母的组合都是有限的,很容易枚举光。
那么问题就来了,这样两个不同的单词会不会产出相同的tri-grams,paper里面做了统计,说了这个冲突的概率非常的低,500K个word可以降到30k维,冲突的概率为0.0044%。
但是在中文场景下,这个Word Hashing估计没有这么有效了。
上面讲述了Word Hashing的词向量的构建方法,这种方法也可以扩展到句子:统计一下句子中每个tri-grams出现的次数,然后用次数组成句子向量即可。
网络结构
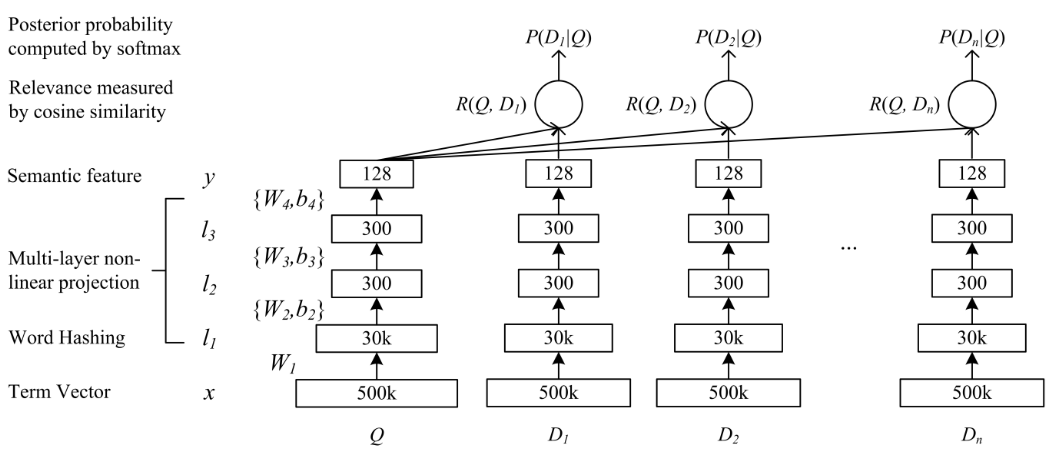
上图是DSSM的网络结构:句子向量经过若干层的神经网络之后,得到了语义向量(semantic concept vectors)。计算两个语义向量的cos相似度,得到两个句子的匹配程度。
参考
https://www.microsoft.com/en-us/research/project/dssm/
微软的DSSM模型
https://www.cnblogs.com/baiting/p/7195998.html
深度语义匹配模型-DSSM及其变种
https://blog.csdn.net/u013074302/article/details/76422551
语义相似度计算——DSSM
https://mp.weixin.qq.com/s/U2r4qDLh4WZFgAIoF_SRPg
金融客服AI新玩法:语言学运用、LSTM+DSSM算法、多模态情感交互
https://mp.weixin.qq.com/s/HMhvcAYRatN0n5EiiNVoXQ
详解深度语义匹配模型DSSM
https://www.cnblogs.com/guoyaohua/p/9229190.html
DSSM:深度语义匹配模型(及其变体CLSM、LSTM-DSSM)
https://zhuanlan.zhihu.com/p/141545370
深度学习语义相似度系列:Ranking Similarity
https://mp.weixin.qq.com/s/2UJQkPuhvFYT2jmuxLJ8VA
实践篇:语义匹配在贝壳找房智能客服中的应用
https://mp.weixin.qq.com/s/6cTG9347dOLxiUs_-tdpnQ
百度开源:语义匹配应用介绍和源代码
https://mp.weixin.qq.com/s/PxyazOPKV3eB-qat8hM9ZQ
神经网络语义匹配技术
https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650749368&idx=3&sn=fc20d9e6682c74227282df3133cea06c
基于IR-transformer、IRGAN模型,解读搜狗语义匹配技术
https://mp.weixin.qq.com/s/Xnea50Eisq9rzhGFa1iTFA
DRr-Net:基于动态重读机制的句子语义匹配方法
https://mp.weixin.qq.com/s/VlZVAhg7shPLQM6D_3b2vQ
漫谈语义相似度
https://mp.weixin.qq.com/s/JrvdQuN99xaikcSltOqz5Q
推荐系统中不得不说的DSSM双塔模型
表示型和交互型
从模型的本质来看可以分为两种类型:表示型和交互型。表示型的模型会在最后一层对待匹配的两个句子进行相似度计算,交互型模型会尽早的让两个句子交互,充分应用交互特征。
https://mp.weixin.qq.com/s/5_QqP3CIBpM4zM5CWIxYuA
深度语义匹配模型原理篇一:表示型
CDSSM
《Learning semantic representations using convolutional neural networks for web search》
MV-LSTM
《A deep architecture for semantic matching with multiple positional sentence representations》
CNTN
《Convolutional Neural Tensor Network Architecture for Community-Based Question Answering》
DRMM
《A deep relevance matching model for ad-hoc retrieval》
MatchPyramid
《Text Matching as Image Recognition》
Match-SRNN
《Match-SRNN: Modeling the Recursive Matching Structure with Spatial RNN》
K-NRM
《End-to-End Neural Ad-hoc Ranking with Kernel Pooling》
代码搜索
https://mp.weixin.qq.com/s/B3Uv-dhB5VYJnu06N4lYBg
深度学习遇见代码搜索,一篇论文概览神经代码搜索
https://mp.weixin.qq.com/s/GFIxA9kEGNJ9rg96mRw0PQ
自然语言语义代码搜索之路
ANN
随着DL的发展,出现了很多神经网络架构的聚类算法,这些算法一般统称ANN。
常见的有:
Spotify’s ANNOY
Google’s ScaNN
Facebook’s Faiss
HNSW(Hierarchical Navigable Small World graphs)
https://zhuanlan.zhihu.com/p/78561555
KNN的实现方式有哪些?
https://mp.weixin.qq.com/s/92Dld5zg5vLtpkdnhmSldg
K近邻算法哪家强?KDTree、Annoy、HNSW原理和使用方法介绍
https://mp.weixin.qq.com/s/pStfyM9o8jnBz_mleecrJQ
盘点高效的KNN实现算法
https://mp.weixin.qq.com/s/Gxgm8r5wqZn-oUS13HC5Xg
如何选择最佳的最近邻算法
https://mp.weixin.qq.com/s/Vzj0xxpW-xBceOpiwy0WPw
Facebook工程实践:语义向量召回之ANN检索
https://mp.weixin.qq.com/s/dsxyQLHcOsNIlNAIf8FQfw
Facebook开源相似性搜索类库Faiss,超越已知最快算法8.5倍
https://mp.weixin.qq.com/s/zLBq2VVSAr0AUtozK7qqVA
浅析Faiss在推荐系统中的应用及原理
https://mp.weixin.qq.com/s/l015FcoP-P2z5BmaTNXpvg
使用Sentence Transformers和Faiss构建语义搜索引擎
https://zhuanlan.zhihu.com/p/210736523
使用Faiss进行海量特征的相似度匹配
https://mp.weixin.qq.com/s/YAIpLbCNp9BTKwa4HIBgGQ
相似搜索百宝箱,文本匹配入门必备!
https://mp.weixin.qq.com/s/fu5t1e57VsFc12IW1ZcC-g
如果KNN淘汰了,那么取而代之的将是ANN
https://mp.weixin.qq.com/s/Cgq5c4UzqfRGprqx2CBYsA
基于Milvus的向量搜索实践(一)
https://mp.weixin.qq.com/s/WP3o4uqWZqqQ4FCla_zB5Q
基于Milvus的向量搜索实践(二)
https://mp.weixin.qq.com/s/JS4Th2lzqJMFqHlRzeE38g
基于Milvus的向量搜索实践(三)
参考
https://github.com/harpribot/awesome-information-retrieval
信息检索优质资源汇总
https://mp.weixin.qq.com/s/5ba3EM6e9R-i3UpzUhm49w
神经信息检索导论,微软研究员129页最新书册
https://mp.weixin.qq.com/s/vE1HnYH5UcKWfxiG8_b3Dw
深度图像检索: 2012到2020大综述论文,荷兰莱登大学等学者详述深度学习图像检索进展
https://mp.weixin.qq.com/s/NJf5e25tvT_xKXLD7UY1AQ
MySQL智能调度系统。这篇blog其实和MySQL关系不大,算是DL在负载均衡方面的应用吧。
https://mp.weixin.qq.com/s/fzdK4YPTUgiW0D0aeH7WlQ
用于跨模态检索的综合距离保持自编码器
https://mp.weixin.qq.com/s/AWsiAYyVWY83s5uJ01Lg6Q
千亿级照片,毫秒间匹配最佳结果,微软开源Bing搜索背后的关键算法
https://mp.weixin.qq.com/s/fw5dRWmvZ17lqzxjKFrCtQ
相关性特征在图片搜索中的实践
https://mp.weixin.qq.com/s/jjbiUkmJ71rM9BYs5yKFSA
从算法原理到应用部署!微信“扫一扫”识物的背后技术揭秘
https://mp.weixin.qq.com/s/38d90XC2DjMHRoWnKEeVIw
基于图像查询的视频检索
https://mp.weixin.qq.com/s/fDaZ2HU7W6LnIY_8n-Zg_A
视频版权检测算法
https://mp.weixin.qq.com/s/_iTmh4vPnL78HPA-0wY95g
阿里文娱搜索算法实践和思考
https://zhuanlan.zhihu.com/p/113244063
搜索中的深度匹配模型
https://zhuanlan.zhihu.com/p/118183738
搜索中的深度匹配模型(下)
https://mp.weixin.qq.com/s/FSpVcTM9BcyraQwuaJ833Q
服装局部抄袭怎么解决? 阿里推出区域检索算法
https://mp.weixin.qq.com/s/SMAHf7od8ygNIP6Zh9za3w
KDD Cup 2020多模态检索赛道:数据分析
https://mp.weixin.qq.com/s/W8YlrSyM7K84-_jwiD6E7g
微信扫一扫识物的技术揭秘:抠图与检索
https://mp.weixin.qq.com/s/ivl_IWXsDon4oXr0oDe1ZA
打造万物识别之利器——微信扫一扫植物识别篇
https://mp.weixin.qq.com/s/Y5-HytenpcMUyh7z3VLOFQ
打造万物识别之利器——微信扫一扫名画识别篇
https://mp.weixin.qq.com/s/Oi_bRbp-z56EsWOfoTIDnQ
打造万物识别之利器——微信扫一扫地标识别篇
https://zhuanlan.zhihu.com/p/112719984
全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么?
https://mp.weixin.qq.com/s/kS-FPeuz0nMN2YvbwAjbIw
线上搜索结果大幅提升!亚马逊提出对抗式query-doc相关性模型
https://mp.weixin.qq.com/s/4UBehc0eikVqcsFP7xL_Zw
京东电商搜索中的语义检索与商品排序

您的打赏,是对我的鼓励
