DL » 深度学习(十)——CNN进化史
2017-08-25 :: 5518 WordsCNN进化史
GoogleNet(续)
原始的GoogleNet也被称作Inception-v1。在后面的几年,GoogleNet还提出了几种改进的版本,最新的一个是Inception-v4(2016.8)。
论文:
《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
代码:
https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
Inception系列的改进方向基本都集中在构建不同的Inception模型上。
GoogleNet的另一个改进是减少了全连接层(Full Connection, FC),这是减少模型参数的一个重要改进。事实上,在稍后的实践中,人们发现去掉VGG的第一个FC层,对于效果几乎没有任何影响。
参考:
https://mp.weixin.qq.com/s/ceOxFS3Iwf3iLWY73ueoNw
GoogLeNet中的inception结构,你看懂了吗
http://www.cnblogs.com/Allen-rg/p/5833919.html
GoogLeNet学习心得
SqueezeNet
GoogleNet之后,最有名的CNN模型当属何恺明的Deep Residual Network。DRN在《深度学习(六)》中已有提及,这里不再赘述。
DRN之后,学界的研究重点,由如何提升精度,转变为如何用更少的参数和计算量来达到同样的精度。SqueezeNet就是其中的代表。
论文:
《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size》
代码:
https://github.com/DeepScale/SqueezeNet
Caffe版本
https://github.com/vonclites/squeezenet
TensorFlow版本
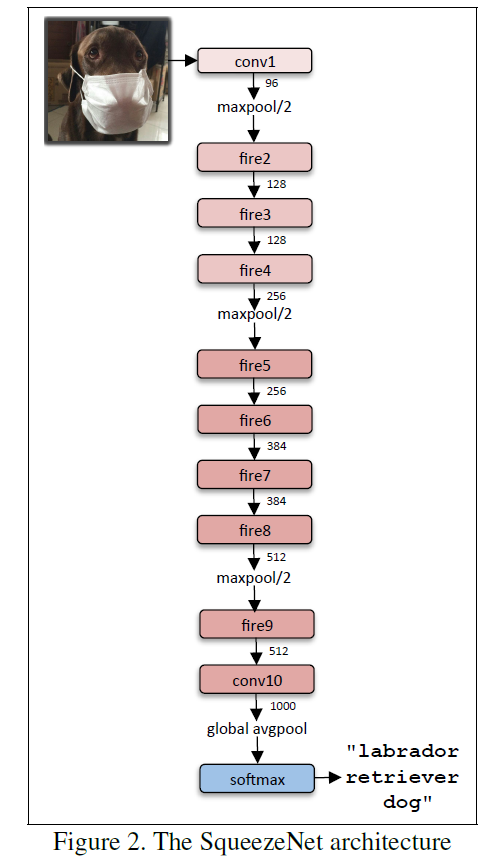
上图是SqueezeNet的网络结构图,其最大的创新点在于使用Fire Module替换大尺寸的卷积层。
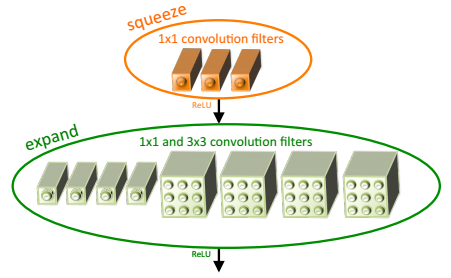
上图是Fire Module的结构示意图。它采用squeeze层+expand层两个小卷积层,替换了AlexNet的大尺寸卷积层。其中,\(N_{squeeze}<N_{expand}\),N表示每层的卷积个数。
这里需要特别指出的是:expand层采用了2种不同尺寸的卷积,这也是当前设计的一个趋势。
这个趋势在GoogleNet中已经有所体现,在ResNet中也间接隐含。
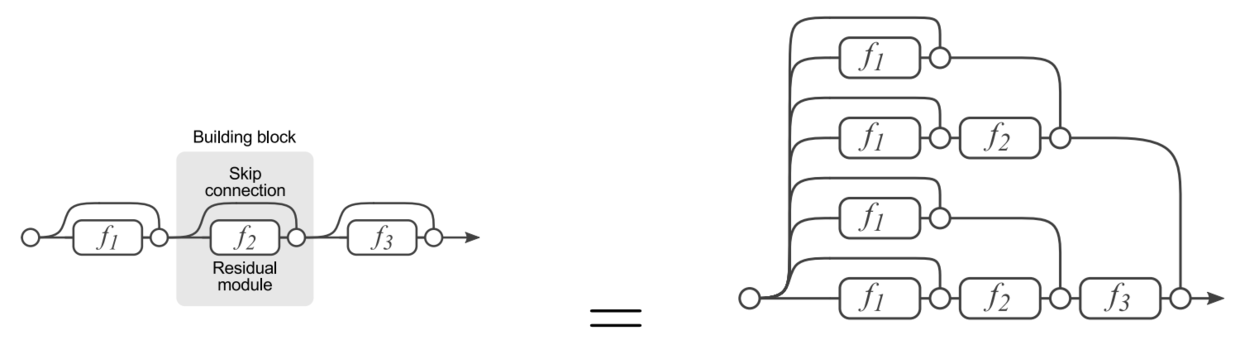
上图是ResNet的展开图,可见展开之后的ResNet,实际上等效于一个多尺寸交错混编的复杂卷积网。其思路和GoogleNet实际上是一致的。
参见:
http://blog.csdn.net/xbinworld/article/details/50897870
最新SqueezeNet模型详解,CNN模型参数降低50倍,压缩461倍!
http://www.jianshu.com/p/8e269451795d
神经网络瘦身:SqueezeNet
http://blog.csdn.net/shenxiaolu1984/article/details/51444525
超轻量级网络SqueezeNet算法详解
https://mp.weixin.qq.com/s/euppu_2rhujlWz1z5S5nYA
纵览轻量化卷积神经网络:SqueezeNet、MobileNet、ShuffleNet、Xception
https://mp.weixin.qq.com/s/rkTL1cj7tG5FaLP9cYRb4A
CNN模型之SqueezeNet
https://mp.weixin.qq.com/s/kE2WW3EaLsEoYTQdzL30RA
SqueezeNet/SqueezeNext简述
其他知名CNN
Network In Network
Network In Network是颜水成团队于2013年提出的。
论文:
《Network In Network》
颜水成,北京大学博士,新加坡国立大学副教授。奇虎360AI研究院院长。
Network In Network最重要的贡献是使用Global Average Pooling替换了Full Connection。这直接促进了之后Fully Convolutional Networks的发展。
参考:
http://blog.csdn.net/sheng_ai/article/details/41313883
Network In Network(精读)
http://blog.csdn.net/zhufenghao/article/details/52526611
Network In Network
http://www.cnblogs.com/dmzhuo/p/5868346.html
读论文“Network in Network”——ICLR 2014
https://mp.weixin.qq.com/s/H_KY_JbqiZ1q7VLwAf2EDA
致敬Network in Network,华为诺亚提出Transformer-in-Transformer
ZF Net
论文:
《Visualizing and understandingConvolutional Networks》
本文是Matthew D.Zeiler 和Rob Fergus于(纽约大学)2013年撰写的论文,主要通过Deconvnet(反卷积)来可视化卷积网络,来理解卷积网络,并调整卷积网络;本文通过Deconvnet技术,可视化Alex-net,并指出了Alex-net的一些不足,最后修改网络结构,使得分类结果提升。
参考:
http://blog.csdn.net/u011534057/article/details/51274862
论文阅读笔记
http://blog.csdn.net/whiteinblue/article/details/43312059
另一篇论文阅读笔记
总结
以下内容摘自中科视拓CEO山世光的演讲。
以让小区里的巡逻机器人学会检测狗屎为例。
在前深度学习时代,这个过程大概分三步:
第一步,花几个月时间收集和标注几百或上千张图;
第二步,观察并人为设计形状、颜色、纹理等特征;
第三步,尝试各种分类器做测试,如果测试结果不好,返回第二步不断地迭代。
人脸检测就是这样进行的,从上世纪八十年代开始做,大量研究者花了大概二十年时间,才得到了一个基本可用的模型,能较好地解决人脸检测的问题。而后在监控场景下做行人和车辆的检测,前后也花了大概十年的时间。就算基于这些经验,做出好用的狗屎检测器,至少还是需要一年左右的时间。
在深度学习时代,开发一个狗屎检测器的流程被大大缩短了。尽管深度学习需要收集大量的数据并进行标注(用矩形把图中的狗屎位置框出来),但由于众包平台的繁荣,收集一万张左右的数据可能只需要两星期。
接下来,我们只需要挑几个已经被证明有效的深度学习模型进行优化训练就可以了,训练优化大概需要一个星期,就算换几个模型再试试看。这样完成整个过程只需要一两个月而已。
而在后深度学习时代,我们期待先花几分钟时间,在网上随便收集几张狗屎照片,交给机器去完成余下所有的模型选择与优化工作,或许最终只需要一、两星期解决这个问题。
前深度学习时代的人脸识别的标准流程:
第一步是人脸检测,其结果就是在图片中的脸部区域打一个矩形框。
第二步是寻找眼睛、鼻子、嘴等特征点,目的是把脸对齐,也就是把眼鼻嘴放在近乎相同的位置,好像所有的脸都能“串成一串”一样,且只保留脸的中心区域,甚至连头发不要。
第三步是光照的预处理,通过高斯平滑、直方图均衡化等来进行亮度调节、偏光纠正等。
第四步是做Y=f(X)的变换。
第五步,是计算两张照片得到的Y的相似程度,如果超过特定的阈值,就认定是同一个人。
深度学习的到来对整个流程有一个巨大的冲击。
一开始,研究者用深度学习完成人脸检测、特征点定位、预处理、特征提取和识别等每个独立的步骤。而后首先被砍掉的是预处理,我们发现这个步骤是完全不必要的。理论上来解释,深度学习学出来的底层滤波器本身就可以完成光照的预处理,而且这个预处理是以“识别更准确”为目标进行的,而不是像原来的预处理一样,以“让人看得更清楚”为目标。人的知识和机器的知识其实是有冲突的,人类觉得好的知识不一定对机器识别有利。
而最近的一些工作就是把第二步特征点定位砍掉。因为神经网络也可以进行对齐变换,所以我们的工作通过空间变换(spatial transform),将图片自动按需进行矫正。并且我有一个猜测:传统的刻意把非正面照片转成正面照片的做法,也未必是有利于识别的。因为一个观察结果是,同一个人的两张正面照相似度可能小于一张正面、一张稍微转向的照片的相似度。最终,我们希望进行以识别为目标的对齐(recognition oriented alignment)。
在未来,或许检测和识别也可能合二为一。现在的检测是对一个通用的人脸的检测,未来或许可以实现检测和识别全部端到端完成:只有特定的某个人脸出现,才会触发检测框出现。
第五步的相似度(或距离测度)的计算方法存在一定的争议。我认为特征提取的过程已经通过损失函数暗含了距离测度的计算,所以深度特征提取与深度测度学习有一定的等价性。但也有不少学者在研究特征之间距离测度的学习,乃至于省略掉特征提取,直接学习输入两张人脸图片时的距离测度。
总体来说,深度学习的引入体现了端到端、数据驱动的思想:尽可能少地对流程进行干预、尽可能少地做人为假设。
参考
http://mp.weixin.qq.com/s/ZKMi4gRfDRcTxzKlTQb-Mw
计算机视觉识别简史:从AlexNet、ResNet到Mask RCNN
http://mp.weixin.qq.com/s/kbHzA3h-CfTRcnkViY37MQ
详解CNN五大经典模型:Lenet,Alexnet,Googlenet,VGG,DRL
https://zhuanlan.zhihu.com/p/22094600
Deep Learning回顾之LeNet、AlexNet、GoogLeNet、VGG、ResNet
https://mp.weixin.qq.com/s/28GtBOuAZkHs7JLRVLlSyg
深度卷积神经网络演化历史及结构改进脉络
http://www.leiphone.com/news/201609/303vE8MIwFC7E3DB.html
Google最新开源Inception-ResNet-v2,借助残差网络进一步提升图像分类水准
https://mp.weixin.qq.com/s/x3bSu9ecl3dldCbvS1rT1g
站在巨人的肩膀上,深度学习的9篇开山之作
http://mp.weixin.qq.com/s/2TUw_2d36uFAiJTkvaaqpA
解读Keras在ImageNet中的应用:详解5种主要的图像识别模型
https://zhuanlan.zhihu.com/p/27642620
YJango的卷积神经网络——介绍
https://www.zybuluo.com/coolwyj/note/202469
ImageNet Classification with Deep Convolutional Neural Networks
http://simtalk.cn/2016/09/20/AlexNet/
AlexNet简介
http://simtalk.cn/2016/09/12/CNNs/
CNN简介
https://mp.weixin.qq.com/s/I94gGXXW_eE5hSHIBOsJFQ
无需数学背景,读懂ResNet、Inception和Xception三大变革性架构
https://mp.weixin.qq.com/s/ToogpkDo-DpQaSoRoalnPg
没看过这5个模型,不要说你玩过CNN!
https://zhuanlan.zhihu.com/p/31006686
从LeNet-5到DenseNet
https://mp.weixin.qq.com/s/L9JY875UjXMv_slAakBrGA
从AlexNet到残差网络,理解卷积神经网络的不同架构
http://www.sohu.com/a/222873093_651893
从LeNet到SENet——卷积神经网络回顾
https://mp.weixin.qq.com/s/-d4T2hgjy6kGdd_ig_J9eg
LeCun亲授的深度学习入门课:从飞行器的发明到卷积神经网络
https://mp.weixin.qq.com/s/z26bXb8eAelrwj6Tkvm_-A
卷积神经网络常见架构AlexNet、ZFNet、VGGNet、GoogleNet和ResNet模型的理论与实践

您的打赏,是对我的鼓励
