DL » 深度学习(九)——ResNet
2017-08-06 :: 5394 Words神经元激活函数进阶(续)
参考
https://zhuanlan.zhihu.com/p/22142013
深度学习中的激活函数导引
http://blog.csdn.net/u012328159/article/details/69898137
几种常见的激活函数
https://mp.weixin.qq.com/s/Hic01RxwWT_YwnErsJaipQ
什么是激活函数?
https://mp.weixin.qq.com/s/4gElB_8AveWuDVjtLw5JUA
深度学习激活函数大全
https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ
从ReLU到Sinc,26种神经网络激活函数可视化
http://www.cnblogs.com/ymjyqsx/p/6294021.html
PReLU与ReLU
http://www.cnblogs.com/pinard/p/6437495.html
深度神经网络(DNN)损失函数和激活函数的选择
https://mp.weixin.qq.com/s/VSRtjIH1tvAVhGAByEH0bg
21种NLP任务激活函数大比拼:你一定猜不到谁赢了
https://www.cnblogs.com/makefile/p/activation-function.html
激活函数(ReLU, Swish, Maxout)
https://mp.weixin.qq.com/s/YVi9ke3VSidBvzfLPjMkZg
激活函数-从人工设计到自动搜索
https://mp.weixin.qq.com/s/XttlCNKGvGZrD7OQZOQGnw
如何发现“将死”的ReLu?
https://mp.weixin.qq.com/s/_qeqicHWnJ50BfiQpLWVVA
Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进
https://mp.weixin.qq.com/s/jMLarSpq3Wg0OIrRIW26dA
从Binary到Swish——激活函数深度详解
https://mp.weixin.qq.com/s/IuZsTKGesgTw1ATXx4OBEA
深度学习最常用的10个激活函数
https://blog.csdn.net/shuzfan/article/details/77807550
CReLU激活函数
ResNet
无论采用何种方法,可训练的神经网络的层数都不可能无限深。有的时候,即使没有梯度消失,也存在训练退化(即深层网络的效果还不如浅层网络)的问题。
最终2015年,微软亚洲研究院的何恺明等人,使用残差网络ResNet参加了当年的ILSVRC,在图像分类、目标检测等任务中的表现大幅超越前一年的比赛的性能水准,并最终取得冠军。
论文:
《Deep Residual Learning for Image Recognition》
代码:
https://github.com/KaimingHe/deep-residual-networks
残差网络的明显特征是有着相当深的深度,从32层到152层,其深度远远超过了之前提出的深度网络结构,而后又针对小数据设计了1001层的网络结构。
其简化版的结构图如下所示:
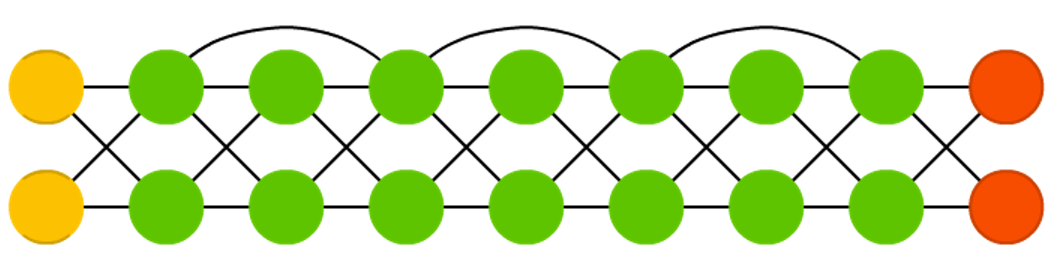
简单的说,就是把前面的层跨几层直接接到后面去,以使误差梯度能够传的更远一些。
DRN的基本思想倒不是什么新东西了,在2003年Bengio提出的词向量模型中,就已经采用了这样的思路。
DRN的实现依赖于下图所示的res block:
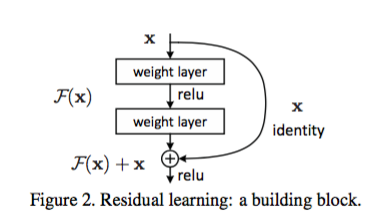
从中可以看出,所谓残差跨层传递,其实就是将本层ternsor \(\mathcal{F}(x)\)和跨层tensor x加在一起而已。
如果在网络中每个层只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应,此时整个权重矩阵的秩不高。并且随着网络层数的增加,连乘后使得整个秩变的更低,这就是我们常说的网络退化问题。
虽然权重矩阵是一个很高维的矩阵,但是大部分维度却没有信息,使得网络的表达能力没有看起来那么强大。这样的情况一定程度上来自于网络的对称性,而残差连接打破了网络的对称性。
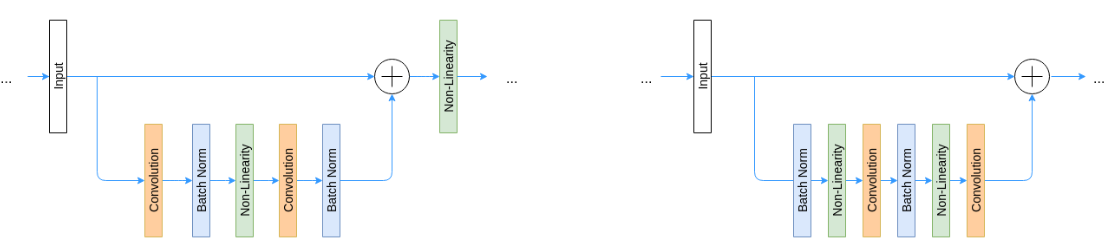
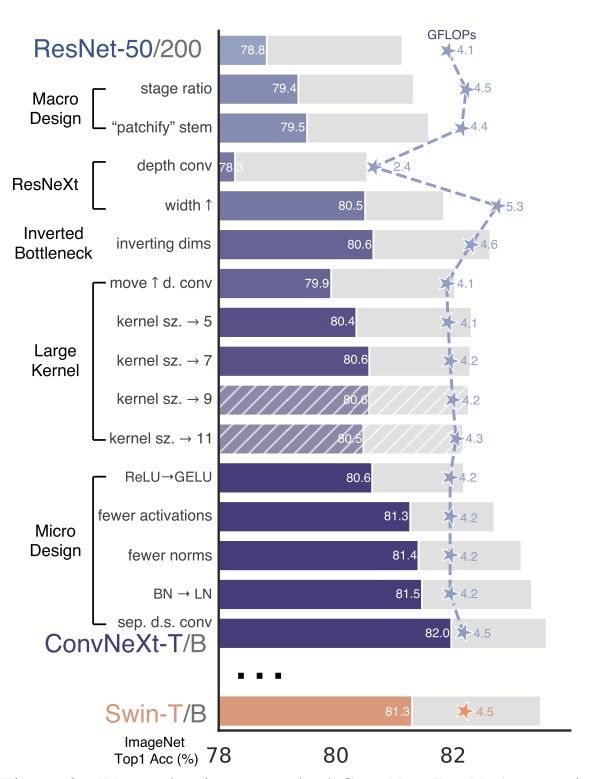
随着ResNet的应用越来越广泛,其设计也有一定的微调。上图左边是原始的ResNet结构,而右边是新的结构。
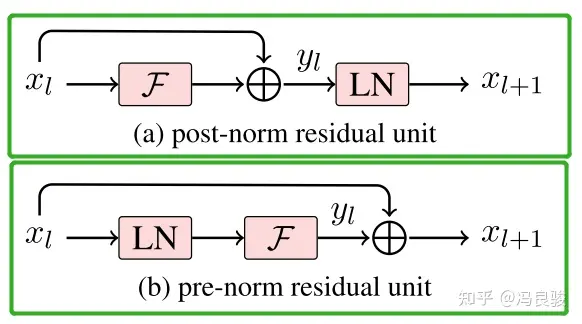
一般认为,Post-Norm在残差之后做归一化,对参数正则化的效果更强,进而模型的收敛性也会更好;而Pre-Norm有一部分参数直接加在了后面,没有对这部分参数进行正则化,可以在反向时防止梯度爆炸或者梯度消失,大模型的训练难度大,因而使用Pre-Norm较多。
参考:
https://zhuanlan.zhihu.com/p/22447440
深度残差网络
https://www.leiphone.com/news/201608/vhqwt5eWmUsLBcnv.html
何恺明的深度残差网络PPT
https://mp.weixin.qq.com/s/kcTQVesjUIPNcz2YTxVUBQ
ResNet 6大变体:何恺明,孙剑,颜水成引领计算机视觉这两年
https://mp.weixin.qq.com/s/5M3QiUVoA8QDIZsHjX5hRw
一文弄懂ResNet有多大威力?最近又有了哪些变体?
http://www.jianshu.com/p/b724411571ab
ResNet到底深不深?
https://mp.weixin.qq.com/s/Kgwwq5XOt88WW6KL8gADmQ
你必须要知道CNN模型:ResNet
https://mp.weixin.qq.com/s/7fWh2dovmfbsF8afaX9UOg
一文简述ResNet及其多种变体
https://mp.weixin.qq.com/s/fxq-H2_ZyXVd_kJx6rwEcQ
何恺明CVPR2018关于视觉深度表示学习教程
https://mp.weixin.qq.com/s/xTJr-jWMjk73TCZ8gBT4Ww
一个神经元统治一切:ResNet强大的理论证明
https://mp.weixin.qq.com/s/-SmmtqHWJjq2A4pu5KqYfQ
resnet中的残差连接,你确定真的看懂了?
https://mp.weixin.qq.com/s/AyJ_ZtNFTjkWVH3_Kw7wJg
ResNet架构可逆!多大等提出性能优越的可逆残差网络
https://mp.weixin.qq.com/s/2JwgiCuBoluBNYesYp4zAA
ResNet及其变种的结构梳理、有效性分析与代码解读
https://mp.weixin.qq.com/s/CFKRzF9WuDrNVSivMf3YNw
目标检测新突破!了解Res2Net深度多尺度目标检测架构
https://mp.weixin.qq.com/s/1R7XWPqiDBNcUjIE-sF08Q
ResNeXt深入解读与模型实现
https://zhuanlan.zhihu.com/p/100122970
基于Keras框架的深度残差收缩网络代码
https://mp.weixin.qq.com/s/scFnuqx0zOtBvFh0JYA0UA
来聊聊ResNet及其变种
https://mp.weixin.qq.com/s/W4IqXMRZJbQ-7fGEF43-sA
真正的最强ResNet改进,高性能“即插即用”金字塔卷积
CNN进化史
计算机视觉
6大关键技术:

图像分类:根据图像的主要内容进行分类。数据集:MNIST, CIFAR, ImageNet
物体定位:预测包含主要物体的图像区域,以便识别区域中的物体。数据集:ImageNet
物体识别:定位并分类图像中出现的所有物体。这一过程通常包括:划出区域然后对其中的物体进行分类。数据集:PASCAL, COCO
语义分割:把图像中的每一个像素分到其所属物体类别,在样例中如人类、绵羊和草地。数据集:PASCAL, COCO
实例分割:把图像中的每一个像素分到其所属物体实例。数据集:PASCAL, COCO
关键点检测:检测物体上一组预定义关键点的位置,例如人体上或者人脸上的关键点。数据集:COCO
参考:
https://github.com/weiaicunzai/awesome-image-classification
GitHub:图像分类最全资料集锦
https://mp.weixin.qq.com/s/nK__d-PV6DY5mDfA_UgDmQ
全解:目标检测,图像分类、分割、生成……
https://mp.weixin.qq.com/s/Go8AQay7tgykXLRtfHGLmg
改变你对世界看法的五大计算机视觉技术!
https://mp.weixin.qq.com/s/WNkzfvYtEO5zJoe_-yAPow
一文览尽计算机视觉研究方向
https://zhuanlan.zhihu.com/p/55747295
深度学习在计算机视觉领域(包括图像,视频,3-D点云,深度图)的应用一览
CNN简史

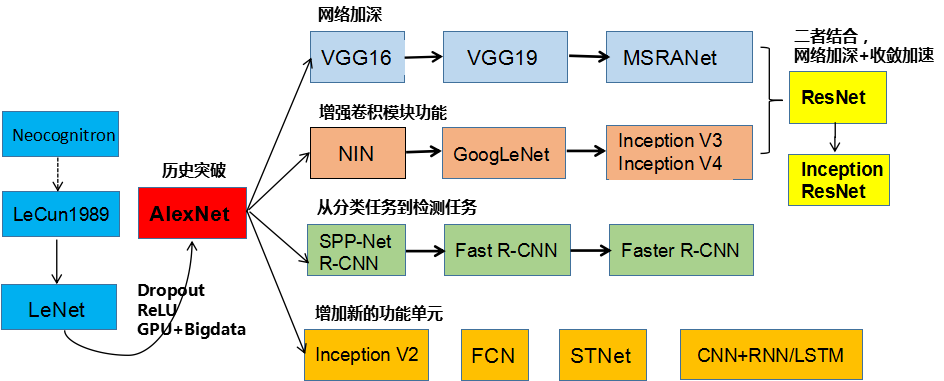
完整版本参见:
https://github.com/Nikasa1889/HistoryObjectRecognition/blob/master/HistoryOfObjectRecognition.pdf
参考:
https://mp.weixin.qq.com/s/K68CpueI4e4y7o1uZ28KMQ
从神经科学到计算机视觉:人类与计算机视觉五十年回顾
https://mp.weixin.qq.com/s/FzCrOiFuutqSQSp4VcydoQ
计算机视觉简介:历史、现状和发展趋势
AlexNet
2012年,ILSVRC比赛冠军的model——Alexnet(以第一作者Alex命名)的结构图如下:
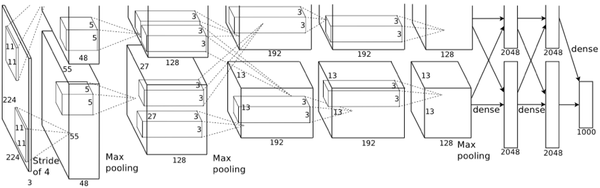
换个视角:
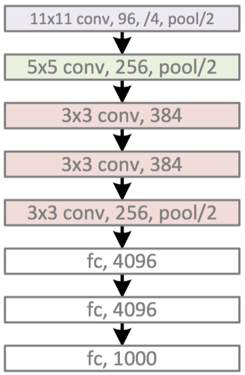
AlexNet的caffe模板:
https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/deploy.prototxt
其中的LRN(Local Response Normalization)层也是当年的遗迹,被后来的实践证明,对于最终效果和运算量没有太大帮助,因此也就慢慢废弃了。
虽然,LeNet-5是CNN的开山之作(它不是最早的CNN,但却是奠定了现代CNN理论基础的模型),但是毕竟年代久远,和现代实用的CNN相比,结构实在过于原始。
AlexNet作为第一个现代意义上的CNN,它的意义主要包括:
1.Data Augmentation。包括水平翻转、随机裁剪、平移变换、颜色、光照变换等。
2.Dropout。
3.ReLU激活函数。
4.多GPU并行计算。
5.当然最应该感谢的是李飞飞团队搞出来的标注数据集合ImageNet。
ILSVRC(Large Scale Visual Recognition Challenge)大赛,在2016年以前,一直是CV界的顶级赛事。但随着技术的成熟,目前的科研重点已经从物体识别转移到了物体理解领域。2017年将是该赛事的最后一届。WebVision有望接替该赛事,成为下一个目标。
参考:
https://zhuanlan.zhihu.com/p/22538465
运用CNN对ImageNet进行图像分类
VGG
Visual Geometry Group是牛津大学的一个科研团队。他们推出的一系列深度模型,被称作VGG模型。
代码:
http://www.robots.ox.ac.uk/~vgg/research/very_deep/
VGG的结构图如下:
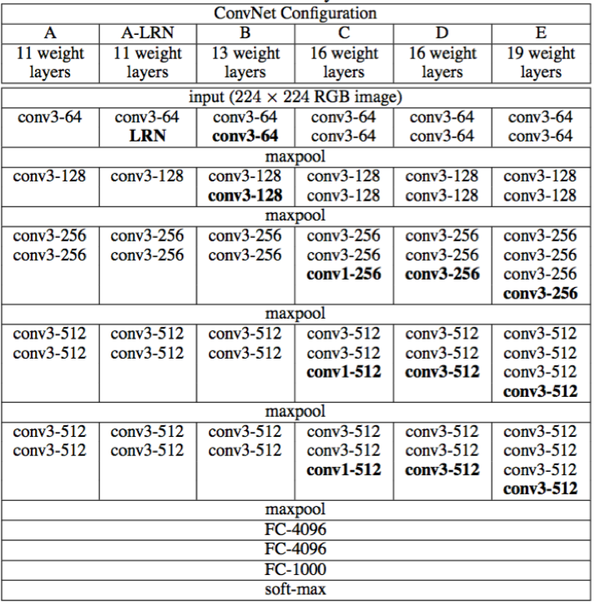
该系列包括A/A-LRN/B/C/D/E等6个不同的型号。其中的D/E,根据其神经网络的层数,也被称为VGG16/VGG19。
从原理角度,VGG相比AlexNet并没有太多的改进。其最主要的意义就是实践了“神经网络越深越好”的理念。也是自那时起,神经网络逐渐有了“深度学习”这个别名。
参考:
https://zhuanlan.zhihu.com/p/37706726
VGG论文笔记
GoogleNet
GoogleNet的进化道路和VGG有所不同。VGG实际上就是“大力出奇迹”的暴力模型,其他地方不足称道。
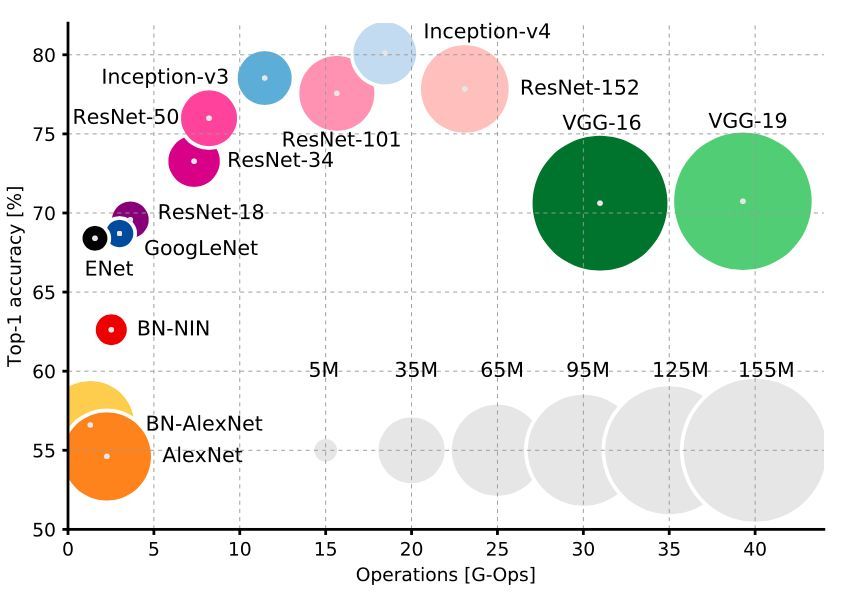
而GoogleNet不仅继承了VGG“越深越好”的理念,对于网络结构本身也作了大胆的创新。可以对比的是,AlexNet有60M个参数,而GoogleNet只有4M个参数。
因此,在ILSVRC 2014大赛中,GoogleNet获得第一名,而VGG屈居第二。
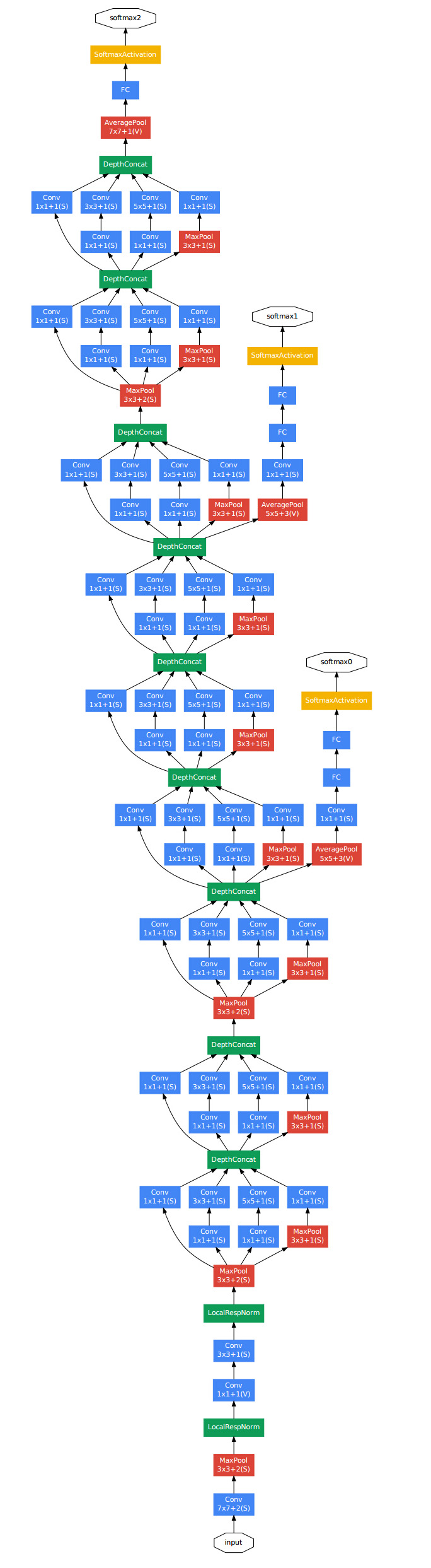
上图是GoogleNet的结构图。从中可以看出,GoogleNet除了AlexNet的基本要素之外,还有被称作Inception的结构。
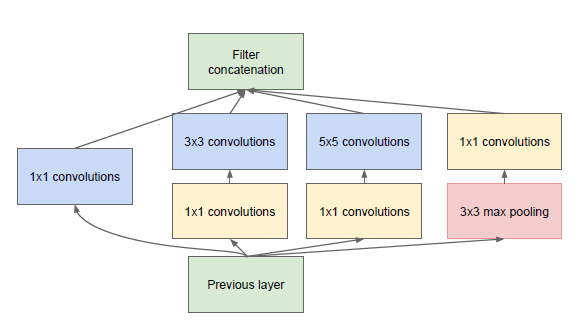
上图是Inception的结构图。它的原理实际上就是将不同尺寸的卷积组合起来,以提供不同尺寸的特征。

您的打赏,是对我的鼓励
